Ubuntu18.04 搭建模型YOLOV4
环境:ubuntu18.04 cuda11.0.3 cudnn8.0.2 python3.7
一、安装YOLOV4
官网:https://github.com/AlexeyAB/darknet
1、克隆darknet
git clone https://github.com/AlexeyAB/darknet2、编译项目
cd darknetmake3、使用预训练权重文件yolov4.weights 安装测试
./darknet detector test ./cfg/coco.data ./cfg/yolov4.cfg ./yolov4.weights data/dog.jpg测试结果如下:
目录darknet下的predictions.jpg是产生的预测结果图像文件

4、安装opencv3.4.6
安装参考官网:https://docs.opencv.org/3.4.4/d7/d9f/tutorial_linux_install.html
下载opencv和opencv_contrib:https://github.com/opencv https://blog.csdn.net/weixin_38621214/article/details/93723272
安装链接:https://blog.csdn.net/weixin_38621214/article/details/93723272
因为这次安装下载花了很长时间,所以相关安装包也上传到百度网盘了,方便下次安装。
链接: https://pan.baidu.com/s/1VQqUubKK-3dZmQpC1ZcNPw 密码: 09ae
make时出现了如下问题:
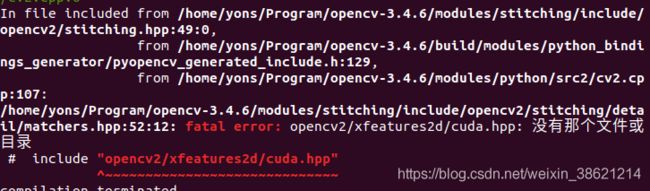
参考链接:https://blog.csdn.net/weixin_44152895/article/details/102882502
解决办法:
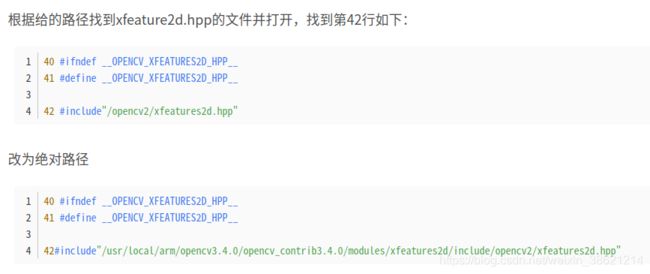

注意:改完路径之后,一定要重新cmake,重要重要!!!!!!!!!
5、修改darknet目录下的Makefile文件
GPU = 1
CUDNN = 1
OPENCV = 1
#显卡为RTX2080Ti,不同的显卡型号对应不同的算力
ARCH= -gencode arch=compute_75,code=[sm_75,compute_75]注意:算力一定要要和显卡型号匹配,不然在make时会报以下错误。

6、执行编译命令
make clean
make注意:make时出现以下错误:

解决办法:
使用如下命令在系统内查看libcuda的路径。
locate libcuda查找结果如下:
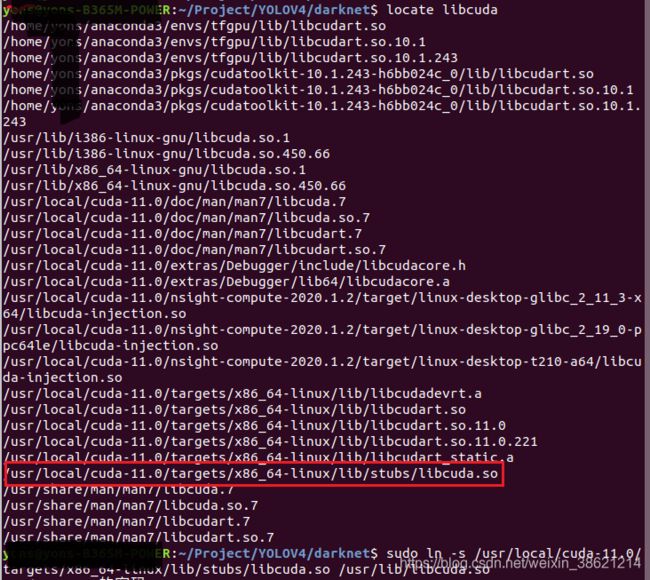
使用下面的命令建立软连接:
sudo ln -s /usr/local/cuda-11.0/targets/x86_64-linux/lib/stubs/libcuda.so /usr/lib/libcuda.so重新make,成功。
此类问题都可以通过这种方法解决。
7、测试GPU版本的YOLOV4
测试图片
./darknet detector test ./cfg/coco.data ./cfg/yolov4.cfg ./yolov4.weights data/dog.jpg测试结果如下:
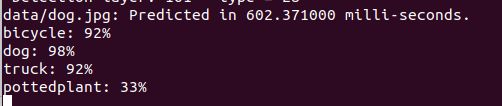

测试opencv
./darknet imtest data/eagle.jpg测试结果如下:

二、准备自己的数据集
1、标注图像
2、修改配置文件
2.1 修改存储类别的文件data/voc.names
复制data/voc.names,重命名为data/voc-ball.names,根据实际类别作出修改。
2.2 修改存储训练集信息的文件cfg/voc.data
复制cfg/voc.data,重命名为cfg/voc-ball.data,添加类别数classes、类别名称文件data/voc.names路径、训练集train.txt和测试集test.txt路径等。
2.3 修改网络框架参数cfg/yolov4-custom.cfg
复制cfg/yolov4-custom.cfg,重新命名cfg/yolov4-voc-ball.cfg,主要修改网络框架参数。
(1) batch=16 subdivisions=8
max_batches = 6000
steps=4800, 5400
(2)在cfg/yolov4-voc-ball.cfg文件中,三个yolo层和各自前面的convolutional层的参数需要修改:
三个yolo层都要改:yolo层中的classes为类别数,每一个yolo层前的convolutional层中的filters =(类别+5)* 3
例如:
yolo层 classes=1, convolutional层 filters=18
yolo层 classes=2, convolutional层 filters=21
yolo层 classes=4,convolutional层 filters=27
三、训练自己的数据集
1、在darknet目录下添加预训练权重
yolov4.conv.137
这里的训练使用迁移学习,所以下载的yolov4在coco数据集上的预训练权重文件(不含全连接层)。
2、训练
./darknet detector train cfg/voc-ball.data cfg/yolov4-voc-ball.cfg yolov4.conv.137 -map第一次训练的时候报错:CUDA status Error: file: ./src/dark_cuda.c : ():line:373 CUDA Error:out of memory CUDA Error:out of memory。
解决办法:batch和subdivisions都设为4,然后把cfg文件中的width和height减小,但要是32的倍数,直到能训练。
3、训练建议
batch=16
subdivisions=8
把max_batches设置为 (classes*2000);但最小为4000。例如如果训练3个目标类别,max_batches=6000
把steps改为max_batches的80% and 90%;例如steps=4800, 5400。
为增加网络分辨率可增大height和width的值,但必须是32的倍数 (height=608, width=608 or 32的整数倍) 。这有助于提高检测精度。四、测试训练出的网络模型
训练好后可以在backup目录下看到权重文件。
尝试test前要修改cfg文件,切换到test模式。可以重新建立一个测试cfg文件, 如yolov4-voc-ball-test.cfg
设置:
batch=1 subdivisions=1
测试图片:
#检测单张图,并且加上-ext_output输出框的坐标值
./darknet detector test cfg/voc-ball.data cfg/yolov4-voc-ball-test.cfg backup/yolov4-voc-ball_final.weights -ext_output /home/yons/Project/test_img/ball/img00001.jpg
#recall
./darknet detector recall cfg/voc-ball.data cfg/yolov4-voc-ball-test.cfg backup/yolov4-voc-ball_final.weights -ext_output /home/yons/Project/test_img/ball/img00001.jpg#检测列表test.txt中图像,并将结果保存在result.json
./darknet detector test cfg/voc-ball.data cfg/yolov4-voc-ball-test.cfg backup/yolov4-voc-ball_final.weights -ext_output -dont_show -out result.json < /home/yons/Project/test_img/test.txt# 检测列表test.txt中图像,并将结果保存在result.txt
./darknet detector test cfg/voc-ball.data cfg/yolov4-voc-ball-test.cfg backup/yolov4-voc-ball_final.weights -dont_show -ext_output < /home/yons/Project/test_img/test.txt > result.txt