论文小综 | 知识图谱表示学习中的零样本实体研究
转载公众号 | 浙大KG
本文作者| 耿玉霞,浙江大学在读博士,主要研究方向为知识图谱、零样本学习及可解释性
前言
随着知识图谱表示学习算法的蓬勃发展,在各个领域中都得到了广泛的应用,如推荐系统、知识问答等,以及知识图谱自身的补全等任务。表示学习算法将知识图谱中的实体和关系都映射到低维向量空间,获取实体和关系的向量表示,同时保留图谱中的结构信息和语义信息。然而,现有的表示学习算法只能对出现在训练集中的实体及关系进行表示,对于测试时新出现的实体/关系,模型可能需要重新进行训练。但知识图谱的增长是快速的,随时都会有一些新增的实体/关系,每次都重新训练显然是不现实的。
近年来,不少工作将注意力投放在利用实体/关系的一些外部特征帮助学习新实体/新关系的表示,因此,本文对一些处理新实体(即zero-shot entity)的工作进行了梳理,根据其外部特征的不同,主要分为基于文本描述的方法和基于邻居连接的方法,下面将分别对这些方法进行介绍。
注意的是,本综述中的文章主要面向知识图谱中新出现的实体,也有不少工作关注图谱中新出现的关系,但不在此文中赘述。如果各位读者感兴趣可在留言区留言,后续会考虑对相关工作进行梳理和介绍。
基于文本描述
基于文本描述的学习方法主要依赖自然语言层面表达的相似性建立实体之间的联系。这类方法通常要求三元组中的每个实体都有各自的描述文本,如下图所示,并且考虑如何在原本知识图谱表示学习的模型中融入实体的文本信息,代表性的文章有以下3篇。

知识图谱中的三元组及实体描述文本
DKRL: Representation Learning of Knowledge Graphs with Entity Descriptions
发表会议:AAAI 2016
论文链接:
https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/download/12216/12004
这篇论文的出发点是考虑如何在知识图谱的表示学习算法如TransE等中融入实体的文本描述信息,以此增强实体的表示能力,使得实体的表示在保留结构信息的同时,更好地融入实体的文本信息。同时,该文本信息可以帮助泛化到zero-shot 实体,学习这些新实体的表示。
具体地,模型主要包含四个损失函数:第一个损失函数 Es 主要学习实体结构层面的表示,以TransE为例,Es=||h_s+r-t_s||;第二个损失函数ED主要学习实体文本层面的表示,ED= ||h_d+r-t_d|| 使其文本层面的表示也满足TransE的约束。另外,作者也设计了两个交叉的损失函数:EDS = ||h_d+r-t_s|| 和 ESD = ||h_s +r - t_d|| ,使得结构层面的表示和文本层面的表示互补。
实验时,结构层面的表示可以通过TransE等预训练获得,得到的表示可用于监督文本表示的学习。具体的,作者提出了两个文本编码的方法。一是通过抽取文本关键词并结合词向量得到文本的表示,另一个是使用CNN模型捕获文本中更丰富的特征信息。作者在后续的实验中也对比了两种方法的优缺点。
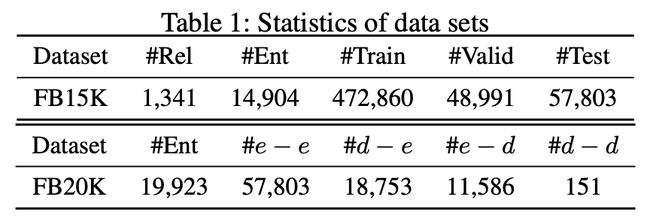
数据集统计
作者基于FB15K构造了一个包含zero-shot entity的数据集FB20K,数据集中涉及4种类型的测试数据,如上图所示,其中,e-e表示头尾实体均出现在训练集中,d-e、e-d分别表示测试三元组中的头实体、尾实体为新实体(即没有出现在训训练集中),d-d表示头尾实体均为新实体。实验结果如下表所示,相比部分出现在训练集中的实体仍然使用基于结构学到的表示(Partial-CBOW/CNN),基于文本得到的表示更能提升模型在zero-shot场景中的预测能力。
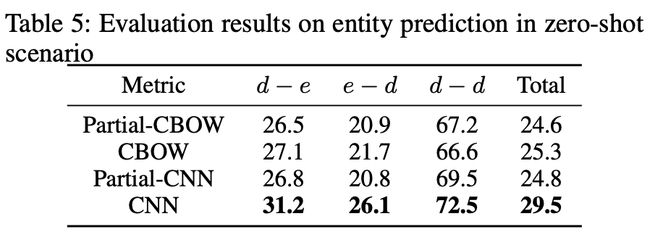
在FB20K上的实验结果
ConMask: Open-World Knowledge Graph Completion
发表会议:AAAI 2018
论文链接:
https://arxiv.org/pdf/1711.03438.pdf
这篇论文主要考虑引入文本时带来的噪声问题,作者基于预测三元组中的关系信息,提出了关系特定的内容掩码机制,用于衡量给定当前预测关系,实体的文本中哪些词是重要的,哪些词是不重要的,以此滤除文本中不相关的单词。
作者首先提出了基于词的内容掩码机制(Maximal Word-Relationship Similarly, MWRW),采用attention机制,通过计算文本中的词和给定关系的相似度,确定文本中每个词的权重;随后,作者观察发现,目标预测实体有时候会出现在权重高的词附近(indicator word),比如下图中,对于三元组
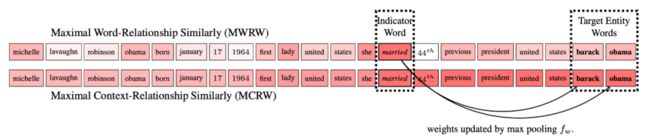
两种权重求解方法图示
基于上述掩码机制再结合CNN模型可得到实体基于文本的表示,随后,通过计算KG中候选目标实体和源实体表示之间的相似性,预测最终的预测结果。作者提出了两个数据集DBpedia50k和DBpedia500k验证模型的能力,可以看到,作者提出的ConMask在各个指标上达到了最好的结果,且击败了上面的DKRL模型。
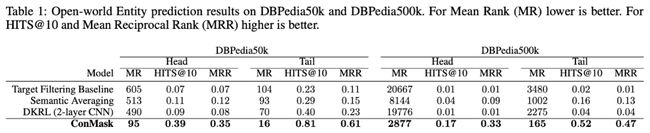
模型实验结果
注意的是,相比于DKRL在预测三元组时同时考虑结构特征和文本语义特征,本文中提出的Conmask完全依赖实体的文本特征对三元组进行补全,并进行迁移,处理预测时出现新实体的问题。
OWE: An open-world extension to knowledge graph completion models
发表会议:AAAI 2019
论文链接:
https://arxiv.org/pdf/1906.08382.pdf
上述两篇论文,DKRL在考虑文本信息时,依赖实体结构层面的特征,而ConMask在三元组预测时仅考虑文本层面的特征。因此,本文提出了基于映射的思想,通过将文本描述映射到图结构空间,对文本语义信息和结构信息进行融合。其中,文本特征的学习和结构特征的学习是独立的,在保留图谱结构特征的同时,模型自身对文本资源的稀疏问题有一定的容忍性。模型结构图如下图所示。
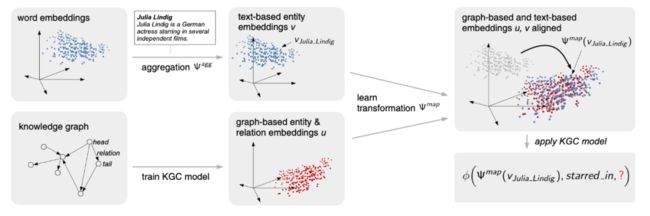
两种权重求解方法图示
作者首先通过TransE等表示学习方法预训练得到实体的结构特征表示,以此监督映射函数的学习。在测试时,对于一个新加入的实体,可直接通过学习好的映射函数得到新实体的表示,进而进行进一步的预测。
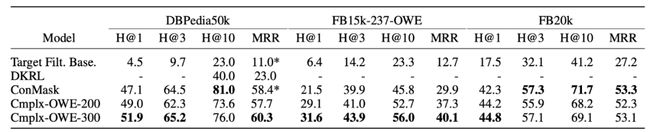
模型实验结果
本文同样也在DBpedia50k和FB20k上进行了实验,同时也提出了自己的数据集FB15k-237-OWE。可以看到本文提出的模型OWE在DBpedia50k和FB20k两个数据集的部分指标上均有提升,在DBpedia50k和FB20k数据集上均达到了最优。这是因为DBpedia50k和FB20k数据集中的文本通常较长,可能更适合使用CNN等模型进行特征捕获,而FB15k-237-OWE的文本相对较短,可能更适合本文提出的使用预训练词向量对文本进行表示。
基于邻居连接
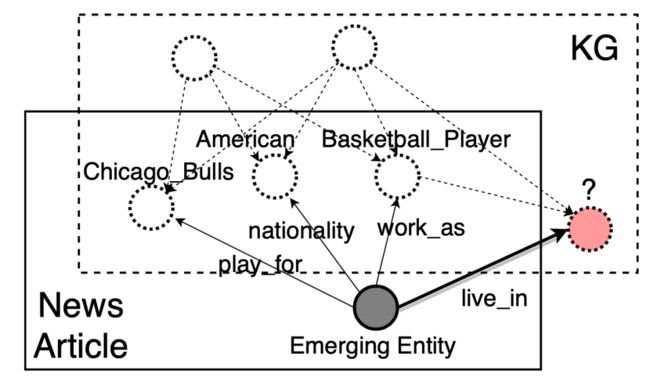
相比于上述基于文本描述的方法,要求每个实体都有文本描述信息,基于邻居连接的方法主要依赖新实体与知识图谱中已经存在的实体存在既定的连接关系(如下图中的红色双实线),即依赖这些附加的邻居三元组,学习新出现的实体的表示。具体地,如下图所示,在训练时,模型只能见到灰色区域中的实体和关系并为它们学到表示(黑色实现),在测试时,对于新出现的实体(即OOKG entity),可以基于该实体与训练好的实体之间的邻居连接状态(红色双实线)得到新实体的表示,从而预测新实体与其他实体之间是否存在某关系(绿色虚线)。相关论文介绍如下。
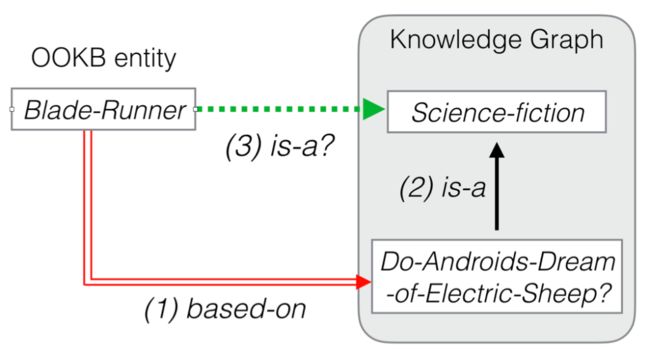
基于邻居三元组学习新实体的表示
Knowledge Transfer for Out-of-Knowledge-Base Entities - A Graph Neural Network Approach
发表会议:IJCAI 2017
论文链接:
https://www.ijcai.org/Proceedings/2017/0250.pdf
本文主要提出利用图神经网络学习实体的表示。受图神经网络通过聚合邻居节点的特征以学习节点的特征表示的启发,本文同样使用图神经网络聚合实体周围的三元组以得到实体的表示,从而在测试时为新实体学到表示。具体地,每个实体的表示为:
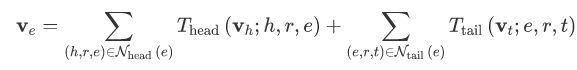
其中, N_head和 N_tail 分别表示当前实体作为尾实体和头实体的邻居三元组集合,通过转换函数T首先对邻居实体及关系的表示进行融合,随后通过均值池化/最大值池化/求和池化等聚合周围所有的邻居表示,最终得到实体的表示。对于转换函数T,本文中采用了Batch Normalization 操作。最后,模型通过TransE等打分函数对学习到的实体表示进行训练。
作者采用一定的策略,基于WordNet11构造了测试数据集。在数据集构造的过程中,保证测试集中的新实体有一些邻居三元组作为辅助帮助建立邻居连接关系。后续论文中一些数据集构造的思路也基本延续了本文中的思路,读者如有兴趣,可阅读原文进一步了解。下表是本文的实验结果,相比baseline中用sum/max/avg等直接聚合邻居实体的表示得到当前实体的表示,本文提出的方法具有一定的优越性。
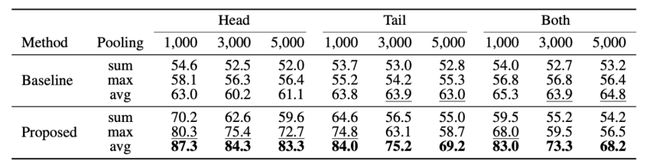
模型实验结果
LAN: Logic Attention Based Neighborhood Aggregation for Inductive Knowledge Graph Embedding
发表会议:AAAI 2019
论文链接:
https://arxiv.org/pdf/1811.01399.pdf
本文同样也是通过聚合实体周围邻居的特征得到当前实体的表示,不同的是,作者考虑在聚合时,对于当前预测的关系,不同的邻居关系所发挥的重要性不同,以及在所有的邻居关系中,可能存在一定的冗余。如下图中,当预测当前实体(emerging entity)通过关系live_in连接的尾实体时,其周围邻居关系中,play_for可能有着更重要的作用。而在所有的邻居关系中,某些关系可能表达的知识非常重复,比如play_for和work_as,当知道某一运动员供职于芝加哥公牛时,可以很容易地推理出他是一位篮球运动员。因此,本文提出了一个Logic Attention Network (LAN),基于关系之间的逻辑约束和attention机制为不同的邻居指定不同的权重,进行加权聚合。
模型实验结果
在LAN中,作者首先提出了一个粗粒度的、基于logic的权重计算方式,通过计算关系在KG中的共现情况,挖掘单个关系之间的联系:
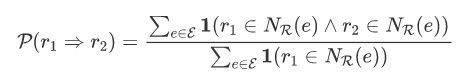
当关系 r1、r2 所连接的实体存在较大的重叠时,认为两个关系之间存在一条规则。因此,给定当前预测关系q,若邻居关系中某一关系r与q存在关联时,赋予关系r较大的权重,而其他关系若 r' 与关系r存在较大的关联(即存在冗余)时,将赋予关系r较小的权重,作者通过这种方式,同时将关系的不同权重以及冗余均考虑在内。基于logic的权重计算如下:
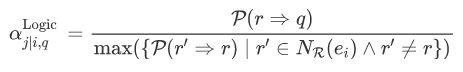
基于此,作者进一步提出了一个更细粒度的、基于attention机制的权重计算方式,通过神经网络模型计算在给定关系时不同邻居实体的权重,权重计算如下:
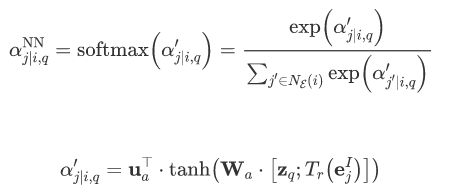
融合上述两种权重计算,模型在融合邻居三元组特征时,为不同的邻居关系和实体分配不同的权重。作者也在WordNet11上进行了实验,同时借鉴上述论文中数据集构造的思路基于FB15k构造了新的数据集,下表是在FB15k上的实验结果。相比于均值聚合邻居特征或使用LSTM聚合周围邻居表示,本文中提出的LAN网络能更有效地捕获邻居关系及实体的特征信息,从而提升模型的预测能力。

模型实验结果
Inductively Representing Out-of-Knowledge-Graph Entities by Optimal Estimation Under Translational Assumptions
论文出处:arXiv 2020
论文链接:
https://arxiv.org/pdf/2009.12765.pdf
相比于前面两篇文章中,通过网络聚合周围邻居的特征,本文提出了一种更简洁、有效的聚合思路——基于TransE等的假设通过预训练的周围节点的表示直接计算得到当前节点的表示,如在TransE的假设下,作为头实体,其表示通常由尾实体和关系相减得到,而作为尾实体,其表示通常由头实体和关系相加得到,其余类似的算法如RotatE也是如此。
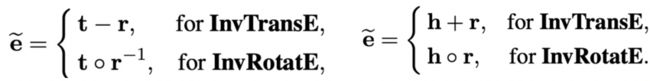
基于此设定可以很容易求得当前实体的表示,考虑到当前实体的周围邻居有多个,作者同样考虑对周围邻居进行加权聚合,权重的计算既有基于规则考虑不同邻居关系的重要性,也有基于邻居实体的连接度考虑不同邻居实体的重要性。
作者同样在LAN提出的FB15k的数据集上验证了模型的性能,可以看到,相比于前面论文中提到的聚合方法,本文提出的聚合思路虽然简单但却有着不错的效果。
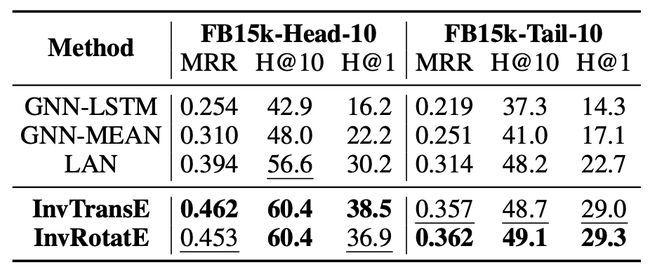
模型实验结果
此外,还有一些基于邻居连接的方法处理预测时新出现的zero-shot entity的问题,但方法基本与上述方法类似,感兴趣的读者可以自行阅读。
Attention-Based Aggregation Graph Networks for Knowledge Graph Information Transfer. PAKDD 2020.
Explainable Link Prediction for Emerging Entities in Knowledge Graphs. ISWC 2020.
其他
上述两种思路更偏向于借鉴图表示学习方面对新加入节点的处理,即考虑利用节点的特征以及节点周围的连接关系。除此之外,也有一些方法利用KG本身的特性,如通过学习KG中与实体无关的子图/关系结构,从而避免实体表示对知识图谱补全等任务的影响,对于新出现的实体也能很好地处理 [1]。此外,其余也有一些工作如面向常识知识图谱这类更容易出现zero-shot entity的图谱进行研究 [2]。
上述文章展示了知识图谱表示学习领域针对新出现的实体的一些主要研究思路和研究内容,可见的是,可能存在相当一部分特征还未被充分挖掘,以及当图谱中同时存在新实体和新关系时,该利用哪些特征学习这些新实体和新关系的表示,也是值得探究的问题。也欢迎大家补充和交流。
[1] Inductive Relation Prediction by Subgraph Reasoning. ICML 2020.
[2] Inductive Learning on Commonsense Knowledge Graph Completion. arXiv 2020.
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。