【论文精读】DeepFirearm: Learning Discriminative Feature Representation for Fine-grained Firearm Retrieval
DeepFirearm: Learning Discriminative Feature Representation for Fine-grained Firearm Retrieval
INTRODUCTION
这是最近看的一篇文章,论文并没有太多方法上的创新点,但是将神经网络用于现代武器的检索,方向挺新奇的。所以记录一下。论文之初作者就指出现在CNN发展得很好,网络上像Facebook这一类的社交巨头都使用CNN来进行图像内容的筛选,去黄去暴。比如说用户上传一些现代武器,这在社区中是被禁止的。所以作者维护了一个数据集,叫做Firearm 14k。可以用来做图像分类和检索。同时在本文中,作者基于传统的Contrastive Loss存在正负样本对优化不均衡的问题提出了可以使用一种叫做double margin contrastive loss的方法去监督网络学习,同时作者对于大部分预训练模型都使用ImageNet进行预训练,但是其实实际使用中目标数据集和ImageNet之间是有一定gap的问题,指出在本文可以使用Firearm数据集的分类子集先对网络进行预训练,然后再进行检索训练two-stage训练方法去完成任务。
目前在武器检索这一块,大家的研究都比较少,一方面是数据难以采集,另一方面是通常网络上的武器图像都是不对齐的,并且同一种武器会有不同的尺度和位置朝向等干扰,属于细粒度任务。但同时将武器图像从海量数据中找出并筛选是目前的急迫且重要的需求。基于这些原因,作者构建了一个高质量数据集Firearm 14k,总共包含了14755张图像,总共167类武器,图像存在朝向不一,遮挡,光照分布不一和背景干扰等问题。下图是数据集的一部分展示:

随着CNN的发展和ImageNet比赛的影响,现在出现了很多优秀的CNN结构和预训练模型,可以用来对图像特征进行提取,但是在实际生活中,我们需要处理的数据在分布上和ImageNet存在一定的差异,所以没法直接使用ImageNet预训练模型完成大部分实际需求实验,需要在特定数据集上进行fine-tune才行。同时在检索任务中,我们需要考量的是两张图像的相似度,往往使用CNN进行分类训练时只能是将样本进行可分性训练,无法达到检索任务中相互距离考量的要求,所以后来更多的loss比如contrastive loss被提出用于检索模型的训练,但是在传统的contrastive loss中存在训练不均衡的问题,正样本对(positive pairs)受到的惩罚会更深。
为了解决上述问题,首先作者提出使用一种double margin contrastive loss的损失函数,给正样本对和负样本对单独分配 margin m a r g i n 用于距离约束和平衡两种pairs在优化过程中的惩罚均衡。对于正负样本对各自的 margin m a r g i n ,论文使用多个实验进行论证选择了跟正负样本对各自样本对距离相关的 margin m a r g i n 值。而对于ImageNet数据集和实际环境数据集之间的ggap问题,论文作者使用two-stage的训练方法去解决,首先使用ImageNet预训练模型在Firearm 14k的分类子集上fine-tune,然后再使用剩余的数据去训练检索网络。
总的来说,论文的共享点有如下三个地方:
- 维护了一个叫做Firearm 14k的数据集,包含14000多张武器样本,总共167类;
- 提出了一种loss叫做double margin contrastive loss用来解决传统contrastive loss中正负样本对惩罚不均衡的问题;
- 使用了two-stage的方法来训练一个检索模型,消除现实数据集和ImageNet的gap问题;
RELATED WORK
感兴趣的同学可以看看论文原文
THE FIREARM 14K DATASET
这部分主要介绍了如何去采集Firearm 14k这个数据集,然后如何去清洗它。最终数据集的统计情况如下:
| class | images | queries | database images |
|---|---|---|---|
| Train set | 107 | 9628 | - |
| Validation set | 20 | 1478 | 39 |
| Test set | 40 | 3649 | 80 |
| Total | 167 | 14755 | - |
OUR APPROACH
下图是论文所使用方法的一个结构图:

Feature Representation
其实就是个标准的Siamese Network,然后对于每张输入样本,最后使用MAC进行特征处理,其实就是在feature map后面接一个Global Max Pooling,然后对特征矢量进行l2-norm归一化处理,基本上在contrastive loss和triplet loss中,都需要对输入特征进行归一化处理,不然可能会因为特征值太大导致网络梯度爆炸。
Double Margin Contrastive Loss
论文首先分析了传统的contrastive loss,首先我们来看它的公式:
L(Ip,Iq)=12[yd2+(1−y)max(α−d,0)2] L ( I p , I q ) = 1 2 [ y d 2 + ( 1 − y ) max ( α − d , 0 ) 2 ]
其中 (Ip,Iq) ( I p , I q ) 表示的是图像对,当 y=1 y = 1 时表示两张图像属于同一类,当 y=0 y = 0 时则不是同一类,我们将图像 I I 的特征提取抽象为f(I) f ( I ) ,则特征之间的距离表示为 d=||f(Ip)−f(Iq)||2 d = | | f ( I p ) − f ( I q ) | | 2 ,其中 α α 表示的是contrastive loss中的 margin m a r g i n 。通过观察公式我们可以得知,正样本对和负样本对的优化情况是不一样的,loss计算过程中是不均衡的。负样本对仅在 α α 大于 d d 的时候才会对最终的额loss有贡献,而正样本对则随时都会对最终的loss产生贡献,换言之就是正样本对随时再被惩罚、优化。
为了缓解这个问题作者提出了double margin contrastive loss的方法,公式如下所示:
L(Ip,Iq)=12[ymax(d−α1,0)2+(1−y)max(α2−d,0)2] L ( I p , I q ) = 1 2 [ y max ( d − α 1 , 0 ) 2 + ( 1 − y ) max ( α 2 − d , 0 ) 2 ]
观察公式可以知道,现在不管是正样本对还是负样本对,距离都是收到 margin m a r g i n 的约束的,也就是规避了传统contrastive loss中正负样本对对最终loss贡献不均衡的问题。唯一的问题就是, α1 α 1 和 α2 α 2 属于两个超参需要用户去设置。
Two-stage Training
这个部分没啥创新性,就是先用ImageNet初始化模型在Firearm上进行分类fine-tune,然后使用另一部分数据集结合该网络+contrastive loss进行检索模型训练。这样做的目的是为了解决ImageNet数据集和Firearm之间的gap问题。
EXPERIMENTS
Settings and Implementation Details
首先作者介绍了本文的实现细节,作者使用了PyTorch作为训练框架,模型采用了VGG16作为主网络,去掉最后的所有全连接层,将其改造为一个全卷积的网络。
Firearm中用于训练分类任务的数据集总共有127类,14000多张样本。将其按7:3的比例划分为训练集和验证集。因为数据集存在较大的不均衡问题,所以作者使用了一个权重相关的交叉熵函数作为训练分类器的损失函数。之后选着分类器中验证准确率最高的模型去进行第二步训练。
在训练检索模型中,作者对于每一个类别的样本都要构建180对正样本对和负样本对进行训练,每隔5个epoch就重新构建一轮正负样本。在训练过程中,数据增强部分为对输入样本的最大边进行[256, 384]随机值等比例缩放。模型使用带有momentum的SGD优化方法,初始学习率为0.001,每隔10个epoch下降10倍,momentum为0.9,weight decay为0.0001,模型总的训练不超过30个epochs。
Single VS Double Margin Contrastive Loss
为了证明本文提出的double margin contrastive loss对比传统contrastive loss的优越性,作者做了实验,retr-d表示double margin contrastive loss,retr-s表示传统的contrastive loss。统计指标使用了mAP和CMC的rank-k值。实验结果如下:

VGG表示的是直接使用ImageNet预训练模型,将全连接层替代为MAC之后得到特征编码,进一步进行检索之后的结果。从上图可以看出retr-d的mAP为47.1%,而retr-s为35.1%,对比之后可得知double margin contrastive loss较传统contrastive loss有将近34.2%的mAP相对提升。
The Benefit of Two-stage Training
首先在Firearm上进行分类的fine-tune,然后以该模型作权值初始化,增加double margin contrastive loss完成two-stage的训练,主要观察上图中cls和cls+retr-d的实验结果。单独使用VGG模型在Firearm上进行分类训练之后可以看到mAP为65.4,相对直接使用ImageNet预训练的VGG模型,mAP的相对提升有110.2%,对比cls和cls+retr-d可以看出增加了double margin contrastive loss之后mAP有4.6%的相对提升。论文作者也做了将double margin contrastive loss替换为传统contrastive loss的对比实验,结果是不理想的,所以这里并没有将其结果放上来。
Impact of the Margins
这部分作者做了多组实验,证明正负样本对在double margin contrastive loss的超参 α α 的选择,结果如下所示:
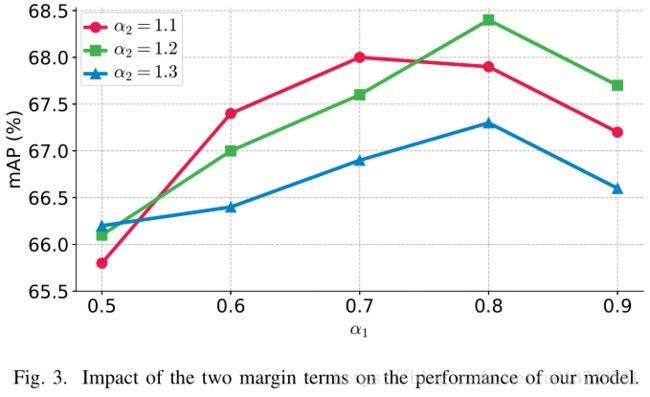
可以看出 α1=0.8 α 1 = 0.8 和 α1=1.2 α 1 = 1.2 的时候能缺德最好的实验结果。
Visualizations and Qualitative Results
这一部分实验中,作者展示了经过不同策略训练之后正负样本对的样本对距离分布,实验结果如下图所示:
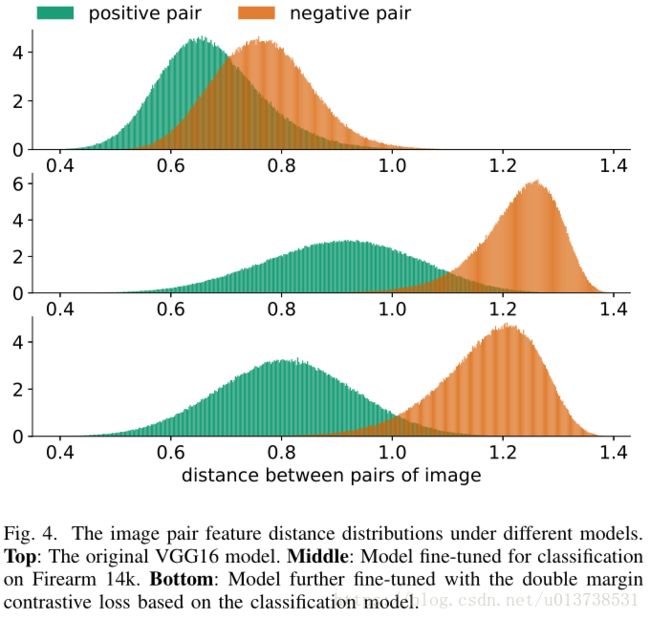
上图中第一行表示的是直接使用ImageNet预训练的VGG16模型对随机取的一部分正负样本对进行样本对之间距离统计的结果,可以看出不管是正样本对还是负样本对,其距离分布都是差不多的,重合度较高,说明该预训练模型没法较好的去做检索任务。第二行表示的是使用VGG16模型在Firearm上fine-tune之后的统计结果,很明显,距离分布已经开始有一定的区分性了;之后加上double margin contrastive loss得到了第三行的实验结果,总体趋势不变,但是正样本对之间的距离收得更拢,说明增加的double margin contrastive loss能增加类内的聚集能力。
Comparison with State of the Art
接下来是和当前的一些SOTA方法的对比,为了保证对比的公平性,实验全都使用了VGG16作为模型的backbone。对比实验如下:

总的来看,作者的方法取得了目前的最优成绩,最优竞争力的成绩为Triplet Loss,这也印证了一般情况下,Triplet Network要好于Siamese Network的结论。
CONCLUSION
总结一下,本文中作者提出了double margin contrastive loss,解决了传统contrastive loss中正负样本对对于loss的贡献不均匀问题。同时使用了two-stage训练的方法去规避了实际数据集和ImageNet数据集的gap问题。最后维护了一个公开的武器数据集Firearm 14k。笔者认为,这篇论文创新性可能还是略有不够,不过之前将CNN用于武器检索的论文也比较少,这篇文章更重要的是贡献了一个完整的武器数据集,对于之后在相关领域的研究作用更重要。