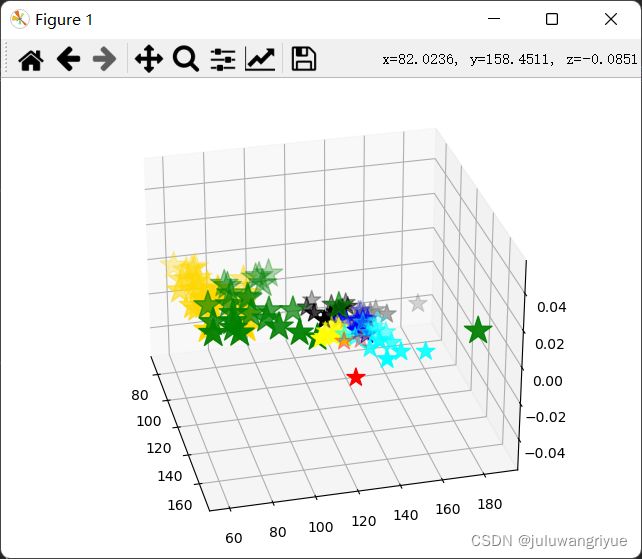
kmean对3d点聚类
kmean对3d点聚类
效果一般
# -*- coding : UTF-8 -*-
# @file : clustering_3d.py
# @Time : 2021-12-22 10:01
# @Author : wmz
import random
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import pandas as pd
import os
# 正规化数据集 X
def normalize(X, axis=-1, p=2):
lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))
lp_norm[lp_norm == 0] = 1
return X / np.expand_dims(lp_norm, axis)
# 计算一个样本与数据集中所有样本的欧氏距离的平方
def euclidean_distance(one_sample, X):
one_sample = one_sample.reshape(1, -1)
X = X.reshape(X.shape[0], -1)
distances = np.power(np.tile(one_sample, (X.shape[0], 1)) - X, 2).sum(axis=1)
return distances
class Kmeans():
"""Kmeans聚类算法.
Parameters:
-----------
k: int
聚类的数目.
max_iterations: int
最大迭代次数.
varepsilon: float
判断是否收敛, 如果上一次的所有k个聚类中心与本次的所有k个聚类中心的差都小于varepsilon,
则说明算法已经收敛
"""
def __init__(self, k=2, max_iterations=500, varepsilon=0.0001):
self.k = k
self.max_iterations = max_iterations
self.varepsilon = varepsilon
# 从所有样本中随机选取self.k样本作为初始的聚类中心
def init_random_centroids(self, X):
n_samples, n_features = np.shape(X)
centroids = np.zeros((self.k, n_features))
for i in range(self.k):
centroid = X[np.random.choice(range(n_samples))]
centroids[i] = centroid
return centroids
# 返回距离该样本最近的一个中心索引[0, self.k)
def _closest_centroid(self, sample, centroids):
distances = euclidean_distance(sample, centroids)
closest_i = np.argmin(distances)
return closest_i
# 将所有样本进行归类,归类规则就是将该样本归类到与其最近的中心
def create_clusters(self, centroids, X):
n_samples = np.shape(X)[0]
clusters = [[] for _ in range(self.k)]
for sample_i, sample in enumerate(X):
centroid_i = self._closest_centroid(sample, centroids)
clusters[centroid_i].append(sample_i)
return clusters
# 对中心进行更新
def update_centroids(self, clusters, X):
n_features = np.shape(X)[1]
centroids = np.zeros((self.k, n_features))
for i, cluster in enumerate(clusters):
centroid = np.mean(X[cluster], axis=0)
centroids[i] = centroid
return centroids
# 将所有样本进行归类,其所在的类别的索引就是其类别标签
def get_cluster_labels(self, clusters, X):
y_pred = np.zeros(np.shape(X)[0])
for cluster_i, cluster in enumerate(clusters):
for sample_i in cluster:
y_pred[sample_i] = cluster_i
return y_pred
# 对整个数据集X进行Kmeans聚类,返回其聚类的标签
def predict(self, X):
# 从所有样本中随机选取self.k样本作为初始的聚类中心
centroids = self.init_random_centroids(X)
# 迭代,直到算法收敛(上一次的聚类中心和这一次的聚类中心几乎重合)或者达到最大迭代次数
for _ in range(self.max_iterations):
# 将所有进行归类,归类规则就是将该样本归类到与其最近的中心
clusters = self.create_clusters(centroids, X)
former_centroids = centroids
# 计算新的聚类中心
centroids = self.update_centroids(clusters, X)
# 如果聚类中心几乎没有变化,说明算法已经收敛,退出迭代
diff = centroids - former_centroids
if diff.any() < self.varepsilon:
break
return self.get_cluster_labels(clusters, X)
def getFiles(path, suffix):
return [os.path.join(root, file) for root, dirs, files in os.walk(path) for file in files if file.endswith(suffix)]
def read_info_from_csv(file):
print(file)
df = pd.read_csv(file)
# print(df.head())
anchors = []
for v in df.values:
# print(v)
fid = v[0]
if "Avg" in fid:
continue
anchors.append(v[1:].tolist())
return anchors
def main():
# Load the dataset
lwh_list = []
csv_folder = r"D:\Work\Data\Patient_Data\bbox_bfresample_spacing1mm\bone_info_statisitic"
file_list = getFiles(csv_folder, '.csv')
anchors_all = []
for file in file_list:
if not'femur' in file:
continue
anchors = read_info_from_csv(file)
anchors_all.append(anchors)
print(anchors)
anchor_reshape1 = np.array(anchors_all).reshape(-1, 3)
print(anchor_reshape1)
# np.savetxt('anchor_reshape.txt', anchor_reshape)
anchor_reshape = np.loadtxt('anchor_reshape.txt')
# 用Kmeans算法进行聚类
clf = Kmeans(k=3)
y_pred = clf.predict(anchor_reshape)
print(y_pred)
print("anchor_reshape[y_pred == 0]")
print(anchor_reshape[y_pred == 0])
print("anchor_reshape[y_pred == 1]")
print(anchor_reshape[y_pred == 1])
print("anchor_reshape[y_pred == 2]")
print(anchor_reshape[y_pred == 2])
print("anchor_reshape[y_pred == 3]")
print(anchor_reshape[y_pred == 3])
# 可视化聚类效果
fig = plt.figure()
ax = Axes3D(fig)
plt.scatter(anchor_reshape[y_pred == 0][:, 0], anchor_reshape[y_pred == 0][:, 1], anchor_reshape[y_pred == 0][:, 2], c="red", marker='*')
plt.scatter(anchor_reshape[y_pred == 1][:, 0], anchor_reshape[y_pred == 1][:, 1], anchor_reshape[y_pred == 1][:, 2], c="green", marker='*')
plt.scatter(anchor_reshape[y_pred == 2][:, 0], anchor_reshape[y_pred == 2][:, 1], anchor_reshape[y_pred == 2][:, 2], c="blue", marker='*')
plt.scatter(anchor_reshape[y_pred == 3][:, 0], anchor_reshape[y_pred == 3][:, 1], anchor_reshape[y_pred == 3][:, 2], c="yellow", marker='*')
plt.show()
if __name__ == "__main__":
main()
调整后的代码
# -*- coding : UTF-8 -*-
# @file : clustering_3d.py
# @Time : 2021-12-22 10:01
# @Author : wmz
import random
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import pandas as pd
import os
# 正规化数据集 X
def normalize(X, axis=-1, p=2):
lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))
lp_norm[lp_norm == 0] = 1
return X / np.expand_dims(lp_norm, axis)
# 计算一个样本与数据集中所有样本的欧氏距离的平方
def euclidean_distance(one_sample, X):
one_sample = one_sample.reshape(1, -1)
X = X.reshape(X.shape[0], -1)
distances = np.power(np.tile(one_sample, (X.shape[0], 1)) - X, 2).sum(axis=1)
return distances
class Kmeans():
"""Kmeans聚类算法.
Parameters:
-----------
k: int
聚类的数目.
max_iterations: int
最大迭代次数.
varepsilon: float
判断是否收敛, 如果上一次的所有k个聚类中心与本次的所有k个聚类中心的差都小于varepsilon,
则说明算法已经收敛
"""
def __init__(self, k=2, max_iterations=500, varepsilon=0.0001):
self.k = k
self.max_iterations = max_iterations
self.varepsilon = varepsilon
# 从所有样本中随机选取self.k样本作为初始的聚类中心
def init_random_centroids(self, X):
n_samples, n_features = np.shape(X)
centroids = np.zeros((self.k, n_features))
for i in range(self.k):
centroid = X[np.random.choice(range(n_samples))]
centroids[i] = centroid
return centroids
# 返回距离该样本最近的一个中心索引[0, self.k)
def _closest_centroid(self, sample, centroids):
distances = euclidean_distance(sample, centroids)
closest_i = np.argmin(distances)
return closest_i
# 将所有样本进行归类,归类规则就是将该样本归类到与其最近的中心
def create_clusters(self, centroids, X):
n_samples = np.shape(X)[0]
clusters = [[] for _ in range(self.k)]
for sample_i, sample in enumerate(X):
centroid_i = self._closest_centroid(sample, centroids)
clusters[centroid_i].append(sample_i)
return clusters
# 对中心进行更新
def update_centroids(self, clusters, X):
n_features = np.shape(X)[1]
centroids = np.zeros((self.k, n_features))
for i, cluster in enumerate(clusters):
centroid = np.mean(X[cluster], axis=0)
centroids[i] = centroid
return centroids
# 将所有样本进行归类,其所在的类别的索引就是其类别标签
def get_cluster_labels(self, clusters, X):
y_pred = np.zeros(np.shape(X)[0])
for cluster_i, cluster in enumerate(clusters):
for sample_i in cluster:
y_pred[sample_i] = cluster_i
return y_pred
# 对整个数据集X进行Kmeans聚类,返回其聚类的标签
def predict(self, X):
# 从所有样本中随机选取self.k样本作为初始的聚类中心
centroids = self.init_random_centroids(X)
# 迭代,直到算法收敛(上一次的聚类中心和这一次的聚类中心几乎重合)或者达到最大迭代次数
for _ in range(self.max_iterations):
# 将所有进行归类,归类规则就是将该样本归类到与其最近的中心
clusters = self.create_clusters(centroids, X)
former_centroids = centroids
# 计算新的聚类中心
centroids = self.update_centroids(clusters, X)
# 如果聚类中心几乎没有变化,说明算法已经收敛,退出迭代
diff = centroids - former_centroids
if diff.any() < self.varepsilon:
break
return self.get_cluster_labels(clusters, X)
def getFiles(path, suffix):
return [os.path.join(root, file) for root, dirs, files in os.walk(path) for file in files if file.endswith(suffix)]
def read_info_from_csv(file):
print(file)
df = pd.read_csv(file)
# print(df.head())
anchors = []
for v in df.values:
# print(v)
fid = v[0]
if "Avg" in fid:
continue
anchors.append(v[1:].tolist())
return anchors
def main():
# Load the dataset
lwh_list = []
csv_folder = r"D:\Work\Data\Patient_Data\bbox_bfresample_spacing1mm\bone_info_statisitic"
file_list = getFiles(csv_folder, '.csv')
anchors_all = []
for file in file_list:
# if not'hip' in file:
# continue
anchors = read_info_from_csv(file)
anchors_all.append(anchors)
print(anchors)
anchor_reshape1 = np.array(anchors_all).reshape(-1, 3)
print(anchor_reshape1)
np.savetxt('anchor_reshape.txt', anchor_reshape1)
anchor_reshape = np.loadtxt('anchor_reshape.txt')
print(anchor_reshape.shape)
# 用Kmeans算法进行聚类
classes = 8
clf = Kmeans(k=classes)
y_pred = clf.predict(anchor_reshape)
print(y_pred)
for i in range(classes):
print("anchor_reshape[y_pred == ]", i)
# print(anchor_reshape[y_pred == i])
print(np.mean(anchor_reshape[y_pred == i], axis=0))
# 可视化聚类效果
clolrs = ["red", "green", "blue", "yellow", "black", "cyan", "gold", "gray"]
fig = plt.figure()
ax = Axes3D(fig)
for i in range(classes):
plt.scatter(anchor_reshape[y_pred == i][:, 0], anchor_reshape[y_pred == i][:, 1],
anchor_reshape[y_pred == i][:, 2], c=clolrs[i], marker='*')
plt.show()
if __name__ == "__main__":
main()
pycharm下的显示效果(只能2D显示):

终端命令行执行时显示效果(3D显示,支持旋转)