Transformer:Attention is all you need
- 声明:本文是学习https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html的笔记
如果你对attention和seq2seq不了解最好了解一下在来看Transformer。seq2seq and attention
Transformer是在2017年在论文“Attention is all you need”中提出的。它只依赖于attention机制,不需要循环神经网络或卷积的参与。在有着更高的翻译质量并且模型速度提升了一个等级。目前,Transformer(包括带有变体的)不仅仅是sequence to sequence任务的标准模型,也是语言模型和预训练设置中的标准。
Transformer 介绍了一个新的模型范例:与之前的模型使用RNN,CNN来完成encoder和decoder相比,Transformer只使用attention。

让我们看一下Google AI blog post中介绍Transformer的插图:
在不看那么多细节的情况下,让我们来就说一些我们在上边的图中得到了什么信息:

看完之后,我们会想什么原因使得Transformer相比于RNN更适用于语言理解呢??
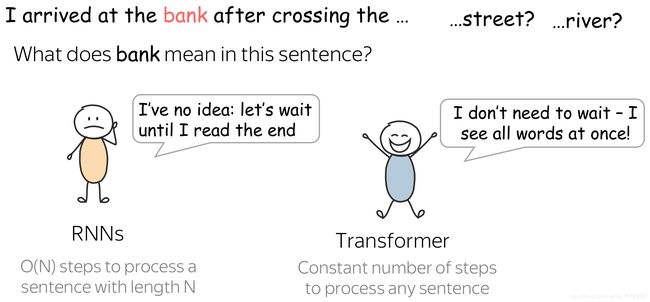
是因为,当对一个句子进行encoder时,如上图,RNN在读完整个句子前都不知道bank是什么意思,在句子很长的情况下这可能会话费很多时间。相反的是,在transformer的encoder中,tokens彼此进行交流在一次中就完成了。
一般的,Transformer的encoder可以认为是在推理步骤中的一个序列。在每一步,tokens彼此交流(这也是我们需要attention的地方----self-attention),交换信息,并且尝试在整个句子的语境中更好的理解彼此。这样的事情会发生在数层中如(6)。
在每一个decoder层,前文的也会彼此影响通过self-attention机制。另外的,他们也会看encoder编码状态。
现在,让我们尝试了解如何在模型中准确实现这一点。
self-attention:the“look at Each Other” Part
self-attention是模型的一个核心部分。attention和self-attention不同之处是self-attention在相同表示之间进行操作。例如:一些层中的所有的encoder状态。

自注意力机制是模型中token彼此之间进行交流的地方。每一个token 使用注意力机制看句子中的其他tokens,聚集语境,更新之前的自身的向量表示,可以看下边的图示:
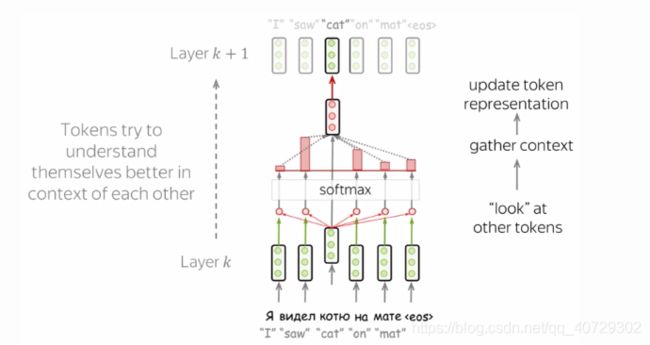
在实际中,这一步是并行进行的。
在self-attention中的Query ,Key,和 Value
self-attention是通过一个query-key-value机制来实现的。在self-attention中每一个输入的token都有三个与他所扮演的角色相适应的表示:
query:询问信息
key:表明他有一些信息
value:提供信息
query在一个token与其他token交流的时候时候使用----他寻找可以更好的理解自己的信息。key是回应query的请求的:它被用于计算attention权重。value在计算attention输出的时候被使用:他将相应的信息交给请求这些信息的tokens。(例如给这些token一个大的权重)
每一个向量都收到三个表示:

计算attention输出的公式如下所示:

Masked Self-Attention:“Don‘t Look Ahead”for the Decoder
在decoder中,也有一个self-attention机制:这个self-attention实现了“look”之前的token的功能。
在decoder中,self-attention与在encoder中的有些许的不同。encoder一次接所有其他tokens的信息并且tokens可以看到输入语句中的所有tokens。在decoder中,我们一次产生一个词:在生成过程中,我们不知道未来将要生成的token。
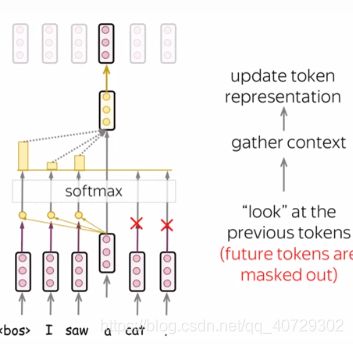
为了阻止decoder看到未来的信息,模型使用了带屏蔽功能的self-attention:未来的token被屏蔽掉了。如上图所示。
但是为什么decoder可以看到未来的信息呢?
这是因为,在生成时是不知道未来的信息的,我们不能知道接下来将会出现什么。但是在训练过程中,我们使用的是参考翻译。因此,在训练过程中,我们将全部的目标语句喂给decoder,没有“masks”,token就会看到未来,这不是我们所希望的。
这也是为了计算效率考虑:Transformer没有循环神经网络,所以所有的tokens都可以一次被处理。这也是transformer在机器翻译领域受欢迎的原因之一----他比有循环神经网络的模型训练速度快很多。对于有循环神经网络的模型,一次训练包含了:O(len(source)+len(target)步。对于Transformer,就是O(1)。
多头注意力机制(Multi-Head Attention):单独的关注不同的东西
一般情况下,理解一个单词在句子中的角色要求理解这个词是如何与句子中的不同部分的联系。这很重要,不仅仅在处理输入数据时,而且对生成目标也很重要。举个例子,在一些语言中,主语会影响谓语动词的状态,谓语动词的状态又影响了宾语等。我想说的是:每一个单词都在很多的关系中。
因此,我们需要让模型关注不同的东西:这就是multi-head attention的动机。与有一个attention不同,multi-head attention有几个“head”,他们独立的进行工作。
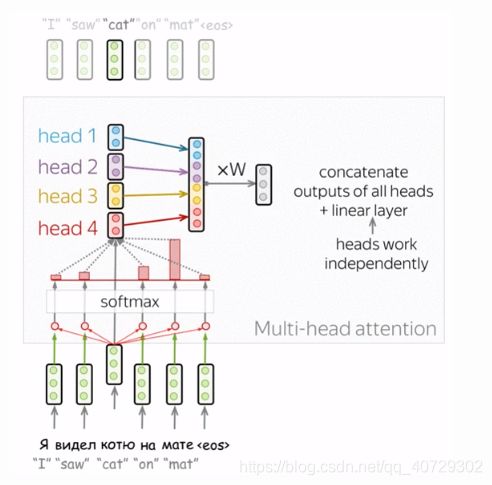
这是由几个attention结合在一起实现的。

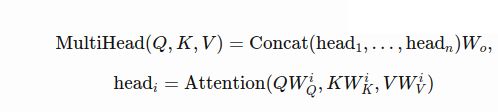
在实际应用中,我们可以讲将使用单独的attention生成的queries,keys,values分割为几部分来实现多头的注意力机制。这种方式下,模型有一个attention或几个attention有相同的大小----multi-head attention不会增加模型的大小。
Transformer:Model Architecture
在我们明白了模型的主要部分和大致观点后,我们来看一下 整体的模型。图片来自于初始论文中。
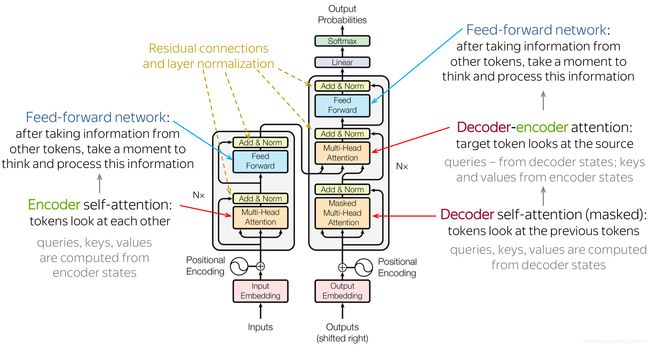
事实上,模型确实包含了我们之前讨论的:在encoder中,tokens彼此交流并且更新他们的表示,在decoder中,生成当前的目的词语首先看已经生成的目标序列然后看源输入来更新他的表示。这些步骤会在某些层中发生,通常是6层。
让我们来更加仔细的看一下模型的其他部分:
Feed-fordword blocks
除了attention,每一个层都有一个feed-forward网络结构:两个线性层加一个在他们中间的ReLU非线性层。

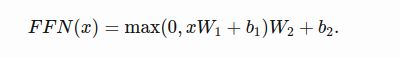
通过attention机制看到了其他的tokens后,模型使用FFN去处理新的信息(attention–“看其他的词,收集信息”,FFN-“花一些时间想一想并且处理这些信息”)
Residual connections
我们已经在卷积语言模型中看到过残差连接(Residual connection)了,残差连接很简单,将输入添加到输出,同时又很有用:他们简化了网络的导数流,并且使层数可以很大。

在Transformer中,残差连接在每一个FFN模块后被使用。在上边的架构图中,残差连接是黄色块中“Add & Norm”中的Add。
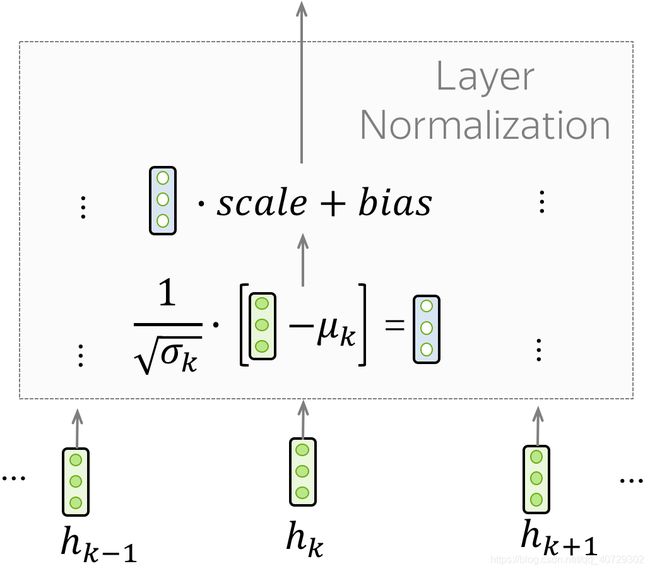
Layer Normalization
在“Add & Norm”中的Norm代表Layer Normalization也就是层归一化。他独立的归一化每一个训练中的例子。这可以控制流下下一层的 流,层归一化提高了收敛稳定性,有时也会提高质量。
在Transfoermer中,我们需要对每一个token的向量表示进行归一化,另外,层归一化中有可训练的参数去缩放的得出层的结果或者下一层的输入。
Position encoding
注意因为Transformer不包含循环神经网络或者卷积神经网络,所以我们并不知道输入序列的位置信息。因此,我们需要去想办法让模型知道tokens的确切的位置信息。为了达到这个目的,我们有两个embedding:一个为了tokens一个为了位置。一个token的输入表示是两个词向量之和。
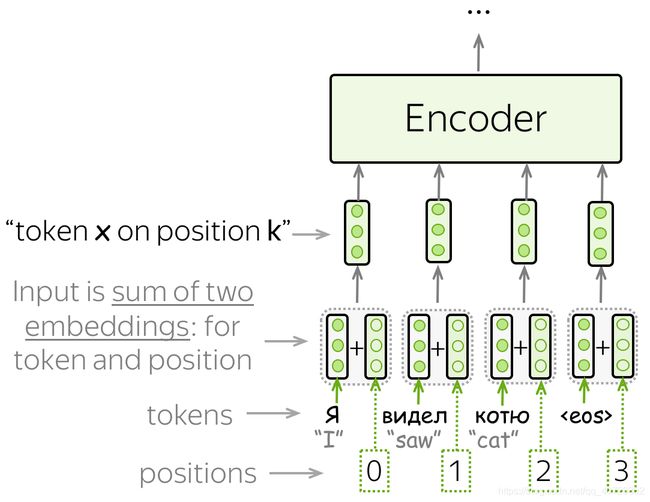
位置词向量可以被学习,作者发现如果有固定的位置向量并不会对模型的质量造成影响。在Transformer中固定的位置编码是:
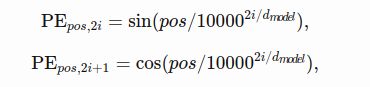
pos是位置,i是向量维度。位置编码的每个维度都对应一个正弦曲线,并且波长形成从2π到10000·2π的几何级数。
Subword segmentation:byte pair encoding
我们都知道的是,模型有一个预定义的关键词的词汇表。输入中不在词汇表中的词会被一个特殊的字符UNK(“unknown”)代替。因此,如果你使用词来做为基本单位,你就会处理一个数量固定的词。这也是固定词汇表的问题:你会碰到很多词汇表中不包括的词汇,但这时模型不能正确的翻译他们。
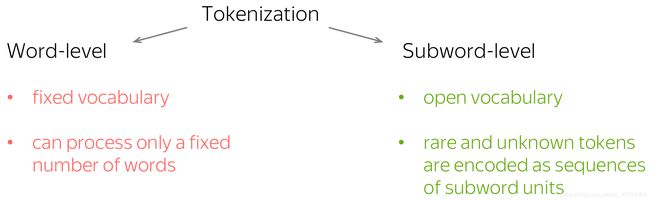
但是我们怎样才能做到表示所有的词汇呢?即使我们在训练集中并没有看到过这个词?事实是,即使你对一个单词不熟悉,但你可能熟悉组成这个单词的一部分–subwords(子字),最坏的情况你还认识字母。为什么不把很少出现的和我们不认识的字变成更小的部分呢?
这正是在论文Neural Machine Translation of Rare Words with Subword Units中由Rico Sennrich, Barry Haddow, Alexandra Birch提出的。他们介绍了实际意义上的标准的子词分词也就是Byte Pair Encoding(BPE)。BPE保留常见的词将很少出现的词和不知道词变为更小的部分。
但是他是怎样工作的呢?
原始在在论文中提出的BPE是一个简单的数据压缩技术,他将句子中单一的,没被使用过的byte替换为最频繁出现的bytes对。现在我们所说的BPE就是指经过改变后用于分词的技术。
BPE算法包括了两个部分:
(1)训练:学习“BPE rules”,也就是要合并哪些字母对
(2)推断:将学习到的规则应用于去对文本进行分词。
让我们来更仔细的看一下模型:
Training:学习BPE 规则
在这步中,算法对建立一个合并表格和一个词汇表。初始状态是由字符组成的词汇表和一个空的merge表格。在这步中,句子中的每一个都做为一个字符序列,算法会:
(1)对出现的字母对进行计数:计算训练数据中每队字母出现了几次
(2)找到最经常出现的字母对
(3)将这对进行合并:在合并表格中添加一对,将这个词增加到
词汇表中
实际上,该算法首先计算每个单词出现在数据中的次数。 使用此信息,它可以更轻松地计算字母对。 还要注意,token不能跨越单词边界-一切都发生在单词之内。
下边是一个图示:

当我们到达最大数量的合并后,并不是所有的词都会合并为一个单个的词。例如:上图中的mats就被分为两个tokens:mat@@ s。注意在分词后我们增加一个特殊的字符@@ 以区别完成的词和不是完整的词。
Inference:segment a text
在学习到BPE规则后,你拥有了一个合并表格,现在我们将使用他去对一个新的文本进行分词。
算法以将一个词分解为字符做为开始。之后,会循环做下边这两步直到不能再进行合并为止:
1.在所有可能合并的可能中,找到在合并表格中概率最高的
2.完成合并
如下图所示:

声明:本文是学习https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html的笔记。有需要的小伙伴可以去看原文。