yolov5初步实践
目标检测(yolov5)
对于目标检测这一方面,我曾经学习了解过人体姿态估计的代码,对于人体运动目标的检测可以描述为:研究人员通过一定的技术手段,在一段由摄像头获取的视频图像序列中获取感兴趣的运动目标,然 后利用相关的算法,使得机器在后续的图像序列中能够找到这些目标,并能得到 该目标在这段视频图像序列中的位置变化等相关信息。最终的结果是这样的
人体姿态估计的理念有部分能够借鉴到目标检测上,比如目标位置的确定以及矩形框的选用。
那么,关于目标检测,该如何去实现呢?由于自身能力有限,我选择到网上寻找答案,发现目前目标检测里最热门的是yolov5。yolov5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使得其速度与精度都得到了极大的性能提升,具体包括:输入端的Mosaic数据增强、自适应锚框计算、自适应图片缩放操作;基准端的Focus结构与CSP结构;Neck端的SPP与FPN+PAN结构;输出端的损失函数GIOU_Loss以及预测框筛选的DIOU_nms。 除此之外,YOLOv5中的各种改进思路仍然可以应用到其它的目标检测算法中。
关于yolov5的操作,我进行了以下几步:一、在https://github.com/ultralytics/yolov5中下载代码。二、阅读README,README里告诉了我如何做Inference。 三、完善未安装的包,在命令行加入摄像头
三、完善未安装的包,在命令行加入摄像头
四、运行在pycharm里detect.py ,会有以下识别视频:
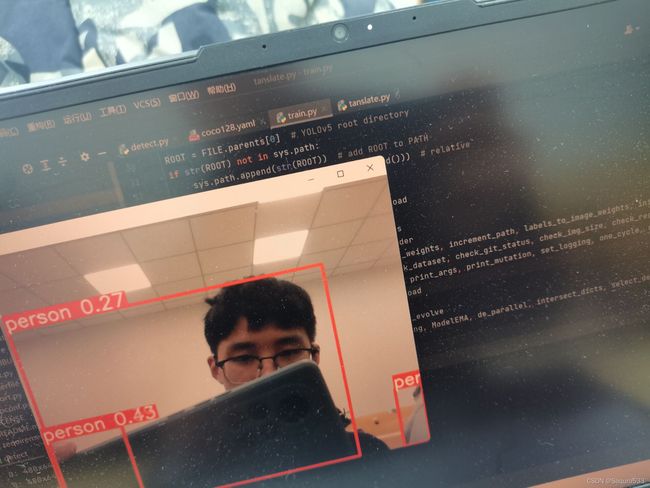
这样,目标检测的初步运行就完成了。
接下来,便是我们自己尝试数据的训练,coco128是一个是我选择用于练手的小型数据集,下载coco128,然后更改路径path: D:\data\detection\coco128,下一步我们要做的是数据的标注,我尝试了两种工具:labelimg和Labelme。Labelimg是矩形框标注工具,labelme是以点的形式标注数据的工具,另外这个工具标注完形成的文件是json后缀,我们需要通过代码编写把它转化为txt后缀供yolov5识别。代码我借鉴了csdn某up主的思路。
运行train.py即可开始训练。
这个训练建议在GPU环境下进行训练。这样速度快。
另外有一些本人关于数据标注的小发现,对于矩形框标注工具,涵括物体全部轮廓的数据在识别时精度更高;对于点标注工具,点越多,越贴合物体轮廓,识别精度更高。
Json文件转换:(25条消息) json格式数据集转yolo txt格式_wlh156423的博客-CSDN博客_json转yolo格式
Yolov5源码:https://github.com/ultralytics/yolov5