最简单的线性分类器——逻辑回归
1. 分类和分类器
1.1 分类
在数据挖掘中,常见的方法有四类,回归、分类、聚类和关联分析(根据关联做推荐)。其中分类是对已知类别的数据进行学习和分类,确定分类的标准和依据。从而实现在获取新对象(数据或内容)时,为新对象划分其所属类别。
1.2 分类器
分类器即分类过程中需要用到的分类函数或分类模型。该函数或模型可以把对象的数据映射到指定类别中的某一个,从而可用于数据的分类预测。
分类器的构造大致需要以下四个步骤:
- 选定样本,将所有样本分为训练集和测试集两个部分。在选定样本时尤其要注意不同类别样本的平衡(非平衡样本会对模型的准确造成较大影响)。
- 在训练集上执行分类器算法,生成分类模型。
- 在测试集上执行分类模型,生成预测结果。
- 根据预测结果,计算必要的评估指标,评估分类模型的性能。
2. 逻辑回归——最简单的线性分类器
2.1 二分类中的逻辑回归
逻辑回归主要利用了Logistic函数来构造,该函数形式为:
![]()
其对应的图像函数:
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-5,5,0.01)
y = 1/(1+np.exp(-x))
plt.plot(x,y)
plt.xlabel('z')
plt.ylabel('y')
plt.grid()
plt.show() 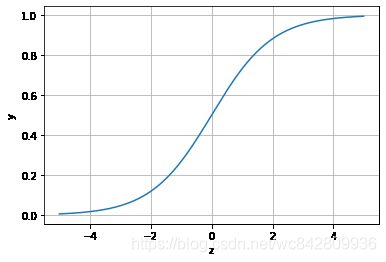
在逻辑回归中,等式左端被定义为“类别为1”的概率,回归方程如下:
![]()
当y > 0.5时,分类为1;当y < 0.5时,分类为0。y = 0.5时,可以找到该线性分类器的决策边界。
2.2 多分类中的逻辑回归
又上述公式我们可得,普通的逻辑回归只能解决二分类问题,要想实现多类别分类问题,需要对逻辑回归进行改进。
方法一:多个二分类器叠加。直接根据每个类别,都建立一个二分类器,带有这个类别的样本标记为1,带有其他类别的样本标记为0。假如我们有N个类别,最后我们就得到了N个二分类器。
方法二:修改逻辑回归的损失函数,让其适应多分类问题(后续会深入讨论)。
3. 逻辑回归的Python实现
利用Python sklearn中自带的鸢尾花数据进行建模。
## 基础函数库
import numpy as np
## 导入画图库
import matplotlib.pyplot as plt
import seaborn as sns
## 导入逻辑回归模型函数
from sklearn.linear_model import LogisticRegression
## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式
from sklearn.datasets import load_iris
data = load_iris() #得到数据特征
iris_target = data.target #得到数据对应的标签
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式
## 合并标签和特征信息
iris_all = iris_features.copy() ##进行浅拷贝,防止对于原始数据的修改
iris_all['target'] = iris_target
## 特征可视化
## 特征与标签组合的散点可视化
sns.pairplot(data=iris_all,diag_kind='hist', hue= 'target')
plt.show()
# 选取其前三个特征绘制三维散点图
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
iris_all_class0 = iris_all[iris_all['target']==0].values
iris_all_class1 = iris_all[iris_all['target']==1].values
iris_all_class2 = iris_all[iris_all['target']==2].values
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(iris_all_class0[:,0], iris_all_class0[:,1], iris_all_class0[:,2],label='setosa')
ax.scatter(iris_all_class1[:,0], iris_all_class1[:,1], iris_all_class1[:,2],label='versicolor')
ax.scatter(iris_all_class2[:,0], iris_all_class2[:,1], iris_all_class2[:,2],label='virginica')
plt.legend()
plt.show()
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
## 选择其类别为0和1的样本 (不包括类别为2的样本)
iris_features_part = iris_features.iloc[:100]
iris_target_part = iris_target[:100]
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(iris_features_part, iris_target_part, test_size = 0.2, random_state = 2020)
## 定义 逻辑回归模型
clf = LogisticRegression(random_state=0, solver='lbfgs')
# 在训练集上训练逻辑回归模型
clf.fit(x_train, y_train)
## 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()