多媒体技术论文研读报告
多媒体技术论文研读报告
一、论文基本信息
论文题目为:基于多模态特征融合嵌入的相似广告检索方法,作者信息:南京大学计算机软件新技术国家重点实验室,南京大学软件学院冯奕、周晓松、李传艺、葛季栋、骆斌,深圳市腾讯计算机系统有限公司王挺,胡雨成,张小鹏。
刊物:计算机学报,发表时间:2022.7.15。
二、研究背景
随着互联网人工智能技术的飞速发展,学习用户特征并精准投放广告能够显著提升广告的点击率(ClickThrough-Rate,CTR)与转化率(Conversion Rate,CVR).人群智能定向是解决广告投放问题中极其重要的一环,业界主流方法是使用转化用户和非转化用户训练基于用户特征的判断其是否会成为转化用户的分类模型.该分类器的优劣依赖广告的实际转化人群规模,但在实际应用中通常面临某些广告转化人群不足的问题,现有的单模态检索方案只关注于单个模态的特征(文本/图像),忽视了不同模态间的内在共有联系,使得挖掘出的广告特征不全且包含大量噪声,最终导致相似广告的检索结果质量不高,从而导致相似转化人群的扩充质量低下.而近年来兴起的跨模态检索方案主要关注以文搜图或以图搜文,并且没有考虑到通用目标检测器并不适用于特定领域图像数据这一事实.
三、研究方法
基于目前精准投放广告模型的问题,该论文提出了一种以广告分类为基本训练目标的多模态商品广告特征融合建模方法,具体来说,分别使用Transformer模型提取文本语义特征,使用目标检测YOLO模型挖掘图像中细粒度的视觉特征,并结合文本注意力机制识别图像中与商品相关的目标,以降低无关目标给广告特征带来的噪声影响.同时,该文提出了一种多模态融合注意力机制,以高效融合广告文本和图像特征.该模型命名为ToTYEmb(Text oriented Transformer-Yolo fusion Embedding).另外,该文还将相似广告扩充、转化人群扩充加入到现有的人群智能定向工作流中。模型整体架构如图1所示。
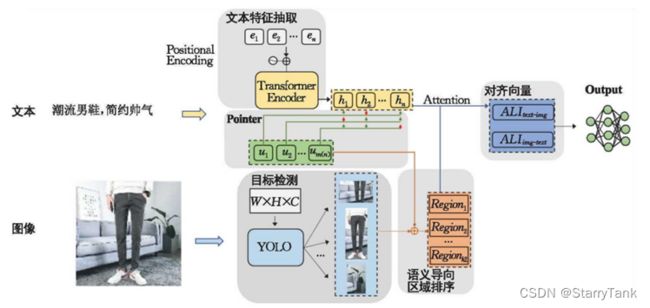
图1 ToTYEmb模型整体架构图
ToTYEmb主要由三个部分组成,分别是基于Transformer的文本特征提取器,基本YOLO的图像特征提取器,以及多模态融合组件。具体而言,对于文本模态,该文使用词级与训练Transformer生成隐层特征向量。对于图像模态,采用YOLO提取图中目标region。为了筛选出广告相关的region,该文提出一种以文本为线索的注意力机制给予关键region更大的权重,最后,利用一种cross attention策略,以融合文本语义和图像视觉语义,模型训练目标是细化商品分类预测,迭代训练完成后利用次顶层隐态向量作为一则广告的fusion embedding特征。
3.1 Transformer编码器
该文使用Transformer对广告文本进行特征提取,Transformer已被运用于多个预训练模型(如BERT等)的文本编码器,其可有效挖掘文本的语义,语序信息,且得self-attention机制,能够计算文本的关键信息,给定一个广告文本序列X={w_1,w_2,w_3,……,w_i},其中w_i为输入序列中词语,iϵ[1,n],Transformer编码过程如下:
e_i=W_e ω_i
h_i=Transformer(e_i+p_i)
其中,输入w_i由参数矩阵W_e转换成初始向量,向量维度为d_model,Transformer不同于RNN,非时序输入,需要单独的位置编码体现词的位置信息,本文采用和Transformer原文一致的的位置编码,接着将初始化的词Embedding和位置Embedding相加,通过Multi-head attention挖掘文本信息。
3.2 YOLO区域特征提取器
对于图像模态部分,该文关注于细粒度的region特征,提出利用目标检测模型YOLO抽取图像的关键目标的区域,并基于区域表达特征信息,相比于Faster-RCNN等两步计算模型,YOLO能以更快的速度达到足够有竞争力的性能。
具体表现上,本文采用YOLO-v3版本进行实现,相比于前两代,其解决了小目标物体检测识别率低的问题,对于一张图像,YOLO可以识别出多个目标,本文取出这些目标对应的卷积特征,用全连接层映射到固定维度:
r_j=F_v (v_j)
在提取出来的特征中,该文以文本信息为线索,对YOLO识别出的目标做筛选,保留商品相关目标,剔除无效目标。这样做有效避免了单纯凭借边框置信度取最高的区域特征在广告数据集上丢失信息的情况。
3.3图文融合注意力机制
在得到文本特征{H_1,H_2,…,H_n}和图像特征{r_1,r_2,…,r_k}后,该文提出一种跨模态的融合注意力机制来获得文本和图像的综合特征向量,其能够融合不同模态的特征并挖掘不同模态间的相关性。首先计算每个词和每个区域之间的相关度:
S_ij=H_i^T r_j
其中H_i^T为H_i的转置。广告中图文是有内在关系的,文本描述着图像的视觉信息,而图像也是文本的语义体现。为了凸显这种内在的关系,用图片信息表征每个词,用文本信息表征每个图片区域:
H_i’=∑_(j-1)k▒(exp(s_(ij)))/(∑_(m-1)^k▒S_im ) r_j
r_j’=∑_(i-1)n▒(exp(s_(ij)))/(∑_(m-1)^n▒S_mj ) h_i
其中H_i’为每个词的图像信息表示,r_j’为每个region的文本信息表示。值得注意的是,这里的矩阵乘并取Softmax操作的部分本质上就是类似于Transformer中的矩阵乘Attention,不一样之处在于跨模态乘法将两个不同量纲的数值乘到了一起,而保证其有效性的前提是对各自模态的每一个分量都做了相同操作。
3.4模型训练过程
该文以多分类交叉熵为损失函数:
loss=-∑▒ylogy
在下游实际召回过程中,直接根据广告图文融合特征向量召回特征空间特征空间中最近的相识广告,而非根据分类结果召回。因为测试集中有相当一部分商品类别从未在训练集中出现,在测试或者应用过程中,如果依据分类结果召回,范化能力较弱,该模型侧重自动地提取广告中多模态特征并获得图文融合嵌入向量,标签分类只是作为训练目标。
3.5相似广告检索下游框架
如图2所示为人群智能定向更新工作流,挖掘转化人群,即根据投放地广告在一定时间周期后,分析有哪些用户对这些广告进行了点击/收藏/购买等行为,并认为这批转化人群是真正容易对当前投放地广告产生兴趣地人群,将这些用户单独抽取出来。人群特征学习文本采用XGBoost模型,其为业内最常用点击预测模型之一。
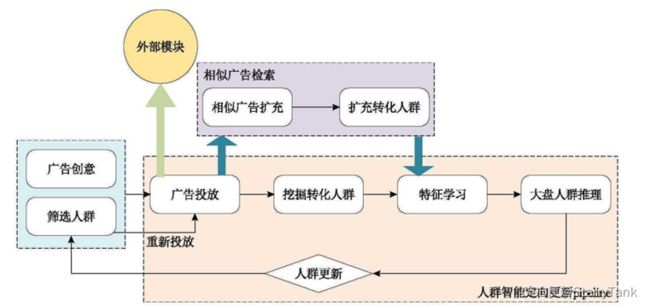
图2 人群智能定向更新与可插拔相似广告检索地扩充框架
四、结论和心得
4.1模型结果
该文以Word2Vec、ELMo、GPT、Bert、RoBerta、VGG16、InceptionV4、YOLO、ViLBERT、ESIM、ABCNN和DIIN为基线模型,该文模型整体来看,依据图文融合embedding思想所构建地最后三种模型在precision@k地指标上均远远高出单独从文本/图像角度依据embedding/matching方式召回相似广告,Top10精确率至少高出15个以上的百分点,这表明融合文本与图像信息对于相似广告检索而言是至关重要的。
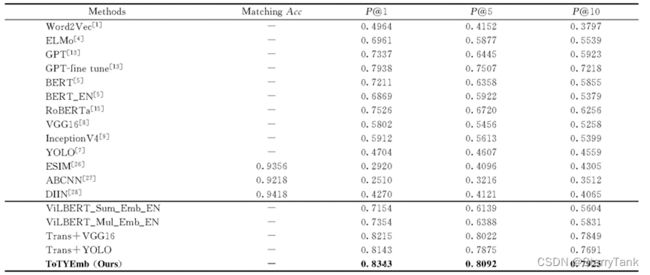
表1 文本方法和基线方法召回实验效果对比
4.2 心得
ToTYEmb模型能提取图文嵌入作为广告地融合内容特征,同时融合文本语义信息和图像的视觉信息,解决相似广告检索问题,进而将其作为可插拔组件加入到现有人群智能定向更新框架中,提升广告投放推荐的效果。相比于其它方法,该模型有如下优势:(1)利用YOLO以及基于文本线索的注意力机制,可提取出商品对应区域目标特征,从而减少背景噪声和无关目标。(2)以文本为线索,引导YOLO模块区域排序,避免丢失重要信息。(3)多模态注意力机制有效融合了文本模态和图像模态,使得特征向量更加健壮。
本次研读的这篇论文,让我开拓了视野。其能提取图文嵌入作为广告的融合内容特征,同时融合文本语义信息和图像信息,弥补了单模态Embedding信息的不足。能够讲文本和图像很好的结合起来,用于相似广告的检索,有很强的实际意义与落地空间。但现实生活中,海量的广告数据只有图片或者文字,如何实现模态之间的转换,弥补单模态的缺陷仍需要进行解决。