【TPN】Temporal Pyramid Network for Action Recognition论文解析
Temporal Pyramid Network for Action Recognition
2022/04/21
行为识别中的时间金字塔
基础知识
-
光流 optical flow(参考文献):
- 光流(optical flow)是空间运动物体在观察成像平面上的像素运动的瞬时速度。
- 光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
- 光流场,指图像中所有像素点构成的一种二维(2D)瞬时速度场,其中的二维速度矢量是景物中可见点的三维速度矢量在成像表面的投影。
-
光流法基本原理:
- 亮度恒定不变。即同一目标在不同帧间运动时,其亮度不会发生改变。这是基本光流法的假定(所有光流法变种都必须满足),用于得到光流法基本方程;
- 时间连续或运动是“小运动”。即时间的变化不会引起目标位置的剧烈变化,相邻帧之间位移要比较小。同样也是光流法不可或缺的假定。
-
光流示例:



flow_x flow_y img
Abstract
视觉节奏(Visual tempo)表征一个动作的动态性和时间尺度。对不同动作的视觉节奏进行建模有助于识别他们。以往的工作经常通过对原始视频进行多速率采样并构造一个输入级的帧金字塔(frame pyramid)来捕捉视觉节奏,这通常需要构建一个代价巨大的多分支网络来进行处理。在这项工作中,我们在特征级(feature-level)提出了一个通用的时间金字塔(Temporal Pyramid Network, TPN),这个金字塔能以即插即用的形式灵活的集成进2D或3D网络中。TPN的两个重要组成部分:特征源和特征融合,构成了主干网络的特征层次结构(feature hierarchy),使其可以捕捉不同节奏的动作实例。
1. Intuoduction
视觉节奏事实上描述了一个动作的速度,它往往决定了识别时在时间尺度上的有效持续时间。动作类别天然具有不同的视觉节奏(例如拍手和走路),如图1所示。

fig.1
即使是同样的动作,不同的人也可能采取不同的视觉节奏来完成,具体来说,翻跟头(Somersaylting)的节奏差异最大,而剪羊毛(Shearing sheep)的差异最小。
在视频识别的常用模型中,如C3D与I3D,往往会叠加一系列的时间卷积。在这些网络中,随着一层深度的增加,它的时间感受野也会增加。因此,单个模型中的不同深度的特征已经能够捕捉到快慢节奏的信息。
2. Related Work
- Video Action Recognition
- Visual Tempo Modeling in Action Recognition
3. Temporal Pyramid Network

fig.2 Framework of TPN
描述了整体的网络结构,Spatial Modulation用于对齐空间和语义特征,Temporal Modulation用于调整时间节奏,使其更丰富Information Flow用于汇聚各个方向的特征,以增强和丰富层级的表达。
3.1Feature Source of TPN
层次特征集合(Collection of Hierarchical Features).
TPN建立在一组具有M层次特征的基础上,并且这些特征从下到上具有越来越大的节奏感受野,有两种方式可以替代骨干网络来收集这些特征。
- 单深度金字塔(Single-depth pyramid)
一个简单的方法是在某一深度选择一个size为 C × T × W × H C\times T\times W\times H C×T×W×H的特征 F b a s e F_{base} Fbase,然后在时间维度用M个不同的速率进行采样: { r 1 , . . . , r M ; r 1 < r 2 < . . . < r M } \lbrace r_{1},...,r_{M};r_{1} - 多深度金字塔(Multi-depth pyramid)
一个更好的来收集M层特征集合的方式是采用深度递增的方式,从而可以得到一个不同的TPN,由size为 { C 1 × T 1 × W 1 × H 1 , . . . , C M × T m × W M × H M } \lbrace C_{1} \times T_{1} \times W_{1} \times H_{1},...,C_{M} \times T_{m} \times W_{M} \times H_{M} \rbrace {C1×T1×W1×H1,...,CM×Tm×WM×HM}的特征 { F 1 , F 2 , . . . , F M } \lbrace F_{1},F_{2},...,F_{M} \rbrace {F1,F2,...,FM}组成,特征中的维度满足以下条件: { C i 1 ≥ C i 2 , W i 1 ≥ W i 2 , H i 1 ≥ H i 2 ; i 1 < i 2 } \lbrace C_{i_{1}} \geq C_{i_{2}}, W_{i_{1}} \geq W_{i_{2}}, H_{i_{1}} \geq H_{i_{2}}; i_{1} < i_{2} \rbrace {Ci1≥Ci2,Wi1≥Wi2,Hi1≥Hi2;i1<i2},这种多深度金字塔特征维度上包含了更丰富的语义信息,但是在特征融合时需要仔细处理,以宝成特征之间正确的信息流动。
空间语义调整(Spatial Semantic Modulation)
为了对齐多深度金字塔中的空间语义,TPN设计了一个特别的空间语义调整。空间语义调整工作以两个互补的方式进行。对于除顶层特征外的每一个特征,都应用一组具有特定水平步幅的卷积,使其空间形状和感受野与顶层特征匹配。此外,这个操作中添加了一个辅助的classification head以加强监督(receive stronger supervision),增强了语义。因此TPN的总体loss即为:
L t o t a l = L C E , o + ∑ i = 1 M − 1 λ i L C E , i (1) L_{total}=L_{CE,o} + \sum_{i=1}^{M-1} \lambda_{i}L_{CE,i} \tag{1} Ltotal=LCE,o+i=1∑M−1λiLCE,i(1)
其中, L C E , o L_{CE,o} LCE,o是原始的交叉熵损失函数, L C E , i L_{CE,i} LCE,i是第 i i i-th个辅助头(auxiliary head)的loss。 λ i \lambda_{i} λi是平衡系数。经过空间语义调整,特征的shape和连续语义(consistent semantics)在空间维度上得到了对齐。然而它在时间维度上仍然没有标定(校准),我们在这里引入时间速率调整机制。
时间速率调整(Temporal Rate Modulation)
回顾[5]中的输入层(input-level)帧金字塔中,可以动态的调整帧采样率以提高模型的适用性。相反,TPN由于在骨干网络的特征上进行操作,导致其灵活性有限,这些特征的视觉节奏仅受其在原始网络中的深度控制。为了使TPN具有与input-level级别的特征金字塔相似的灵活性,在时间速率调整中我们引入了一系列的超参数: { α i } i = 1 M {\lbrace \alpha_{i} \rbrace}_{i=1}^M {αi}i=1M。具体来说, α i \alpha_i αi表示经过空间语义调整后,在 i i i-level的更新特征将被一个参数化的子网络以参数 α i \alpha_i αi进行降采样。这些超参数的加入能够控制特征在时间尺度上的相对差异,可以更有效的时间特征融合。由于符号滥用,我们使用size为 C i × T i × W i × H i C_i \times T_i \times W_i\times H_i Ci×Ti×Wi×Hi的特征 F i F_i Fi,表示同时经过空间语义调整和时间速率调整后的第 i i i-th个特征。
3.2 Information Flow of TPN
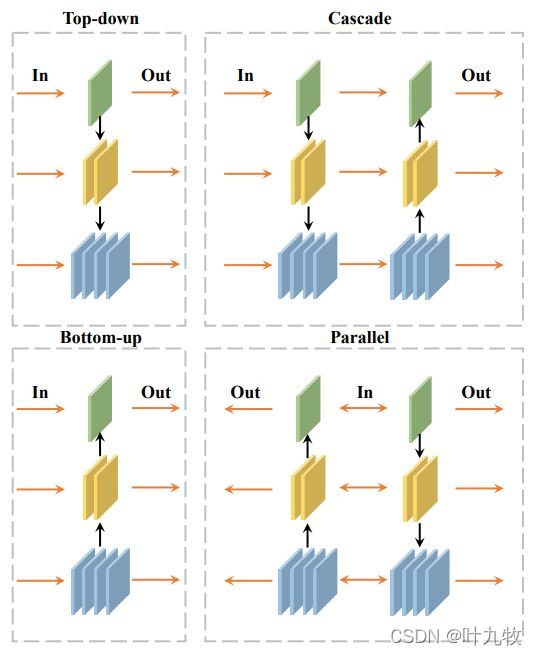
fig.3 Information Flow
描述了不同的特征融合方式,具体表达为4个融合流。
在3.1中分层特征经过收集和预处理后,其在视觉节奏上是动态的,而在空间语义上是一致的,接下来可以进行特征融合了。
设 F i ′ F^{'}_i Fi′为第 i i i-th级的聚合特征,一般有三个基本选项:
y = { F i Isolation Flow F i ⨁ g ( F i − 1 , T i / T i − 1 ) Bottom-up Flow F i ⨁ g ( F i + 1 , T i / T i + 1 ) Top-down Flow (2) y=\left\{ \begin{array}{ll} F_i & \operatorname{Isolation\ Flow} \\ F_i\bigoplus g(F_{i-1}, T_i/T_{i-1}) & \operatorname{Bottom-up \ Flow} \\ F_i\bigoplus g(F_{i+1}, T_i/T_{i+1}) & \operatorname{Top-down \ Flow} \end{array} \right. \tag{2} y=⎩⎨⎧FiFi⨁g(Fi−1,Ti/Ti−1)Fi⨁g(Fi+1,Ti/Ti+1)Isolation FlowBottom-up FlowTop-down Flow(2)
其中, ⨁ \bigoplus ⨁表示元素加法,同时为了保证连续特征之间的加法兼容性,在进行下/上采样操作时,函数 g ( F , δ ) g(F,\delta) g(F,δ)被应用在时间维度上,其中 F F F是特征而 δ \delta δ是参数。注意,top-down/bottom-up flow中的top/bottom特征将不会被其他特征所聚合。
除了上述基本聚合流(basic flows)之外,我们还可以将它们结合起来实现两个额外的操作,命名为串联流(Cascade Flow)和并联流(Parallel Flow)。fig3中展示了所有可能的聚合流。
在此之上可以构建更复杂的流,但是我们在这方面的努力并没有明显的提升效果。