数据分析之NumPy
创建ndarray对象
通过NumPy的内置函数array()可以创建ndarray对象,其语法格式如下:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)

导入numpy
#注意默认都会给numpy包设置别名为np
import numpy as np
array创建数组:
#array()函数,括号内可以是列表、元组、数组、迭代对象,生成器等
np.array([1,2,3,4,5])
type(np.array([1,2,3,4,5]))
numpy.ndarray
#元组
np.array((1,2,3,4,5))
array([1, 2, 3, 4, 5])
#数组
a=[1,2,3,4,5]
b=np.array(a)
b
array([1, 2, 3, 4, 5])
#迭代对象
np.array(range(10))
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
#生成器
np.array([i**2 for i in range(10)])
array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81])
练习题:
创建10以内的偶数的数组
np.array([i for i in range(10) if i%2!=0])
array([1, 3, 5, 7, 9])
#列表中元素类型不相同(哪个数据类型占内存最大,就走哪个,要保持一致)
np.array([1,2,3,4,'5'])
array(['1', '2', '3', '4', '5'], dtype='ar1=np.array(range(10)) #整型
ar1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
ar2=np.array([1,2,3.14,4,5]) #浮点型
ar2
array([1. , 2. , 3.14, 4. , 5. ])
ar3=np.array([
[1,2,3] ,
('a','b','c')
]) #二维数组:嵌套序列(列表,元组均可)
ar3
array([['1', '2', '3'],
['a', 'b', 'c']], dtype='#注意嵌套序列数量不一会怎么样
ar4=np.array([[1,2,3] ,('a','b','c','b')])
ar4
array([list([1, 2, 3]), ('a', 'b', 'c', 'b')], dtype=object)
ar4.ndim #几维
1
ar4.shape
(2,)
1.设置dtype参数,默认自动识别
a=np.array(range(10))
a
#设置数组元素类型
have_dtype_a=np.array(range(10),dtype='float')
have_dtype_a
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
思考如何将浮点型的数据,设置为整形,会是什么情况?
np.array([1,1.4,1.6],dtype='int')
array([1, 1, 1])
2.设置copy参数,默认为true
a=np.array([1,2,3,4,5])
#定义b,复制a(相当于深拷贝,重新开辟一块内存)
b=np.array(a)
print('a:',id(a),'b:',id(b)) #地址不同
a: 2449778162256 b: 2449782598032
#修改a,b不会改变
a[1]=3
b
array([1, 2, 3, 4, 5])
a=np.array([1,2,3,4,5])
#直接等于,是试图操作,相当于列表的引用赋值
b=a
print('a:',id(a),'b:',id(b)) #地址相同
a: 2449777942960 b: 2449777942960
a=np.array([1,2,3,4,5])
#定义b,当设置copy参数为false时,不会创建副本
#两个变量指向的相同的内存地址,没有创建新的对象
b=np.array(a,copy=False)
print('a:',id(a),'b:',id(b)) #地址相同
print('以上是地址')
b[0]=10
print('a:',a,'b:',b)
a: 2449778207024 b: 2449778207024
以上是地址
a: [10 2 3 4 5] b: [10 2 3 4 5]
3.ndmin用于指定数组的维度
a=np.array([1,2,3])
print(a)
a=np.array([1,2,3],ndmin=2)
print(a)
a.ndim
[1 2 3]
[[1 2 3]]
2
4.subok参数,类型为bool值,默认为false。为True,使用object的内部数据类型;False:使用object数组的数据类型
#创建一个矩阵
a=np.mat([1,2,3,4])
#输出矩阵类型
print(type(a))
#既要复制一份副本,又要保持原类型
at=np.array(a,subok=True)
print(type(at))
print('at:' ,id(at),'a',id(a))
#若subok为False(默认)
af=np.array(a)
print(type(af))
at: 2449820920960 a 2449820920736
书写代码是需要注意的内容:
#定义一个数组
a=np.array([1,2,3,4])
#在定义新数组时,如果想复制a的几种方案
#1.使用np.array()
b=np.array(a)
print('b=np.array():',id(a),id(b))#地址不同
#2.使用数组的copy()方法
c=a.copy()
print('c=a.copy():',id(a),id(c))#地址不同
#注意不能使用=复制,直接使用=号,会使两个变量指向相同的内存地址
d=a
#修改d也会相应的修改a
print('d=a:',id(a),id(d))#地址相同
b=np.array(): 2449778382192 2449778373808
c=a.copy(): 2449778382192 2449778372848
d=a: 2449778382192 2449778382192
arange()生成数组区间
根据start与stop指定的范围以及step设定的步长,生成一个ndarray。
numpy.arange(start,stop,step,dtype)
参数说明:
start —— 开始位置,数字,可选项,默认起始值为0
stop —— 停止位置,数字
step —— 步长,数字,可选项, 默认步长为1,如果指定了step,则还必须给出start。
dtype —— 输出数组的类型。 如果未给出dtype,则从其他输入参数推断数据类型。
np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(3.1)
array([0., 1., 2., 3.])
#这个的结果?
range(3.1)#错误的
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_12108\3524418489.py in
1 #这个的结果?
----> 2 range(3.1)
TypeError: 'float' object cannot be interpreted as an integer
#返回浮点型的,也可以指定类型
x=np.arange(5,dtype=float)
x
array([0., 1., 2., 3., 4.])
设置了起始值,终止值,及步长
#起始值为10,终止值20,步长是2
np.arange(10,20,2)
array([10, 12, 14, 16, 18])
#起始是0,终止是20,步长为3
#np.arange(20,3)#错误,如果指定了step,则还必须给出start
#正确的书写规则
np.arange(20,step=3)
array([ 0, 3, 6, 9, 12, 15, 18])
#如果数据太大而无法打印,Numpy会自动跳过数组的中心部分,并只打印边角:
np.arange(100000)
array([ 0, 1, 2, ..., 99997, 99998, 99999])
np.arange(0,200+1,3)
array([ 0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36,
39, 42, 45, 48, 51, 54, 57, 60, 63, 66, 69, 72, 75,
78, 81, 84, 87, 90, 93, 96, 99, 102, 105, 108, 111, 114,
117, 120, 123, 126, 129, 132, 135, 138, 141, 144, 147, 150, 153,
156, 159, 162, 165, 168, 171, 174, 177, 180, 183, 186, 189, 192,
195, 198])
如何防止float不精确影响numpy.arange
想得到一个长度为3的,从0.1开始,间隔为0.1的数组,想当然地如下coding,结果出乎意料:
np.arange(0.1,0.4,0.1)
array([0.1, 0.2, 0.3])
linspace()创建等差数列
返回间隔[开始,停止]上计算的num个均匀间隔的样本。**数组是一个等差数列构成**
np.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None
参数说明:
start 参数数值范围的起始点。如果设置为0,则结果的第一个数为0.该参数必须提供。
stop 参数数值范围的终止点。通常其为结果的最后一个值,但如果修改endpoint = False, 则结果中不包括该值
num 参数控制结果中共有多少个元素。如果num=5,则输出数组个数为5.该参数可选,缺省为50.
endpoint 参数决定终止值(stop参数指定)是否被包含在结果数组中。如果 endpoint = True, 结果中包括终止值,反之不包括。缺省为True。
retstep参数,如果是True时,生成的数组中会显示间距,反之不显示。
dtype参数和其他的 NumPy 一样, np.linspace中的dtype 参数决定输出数组的数据类型。如果不指定,python基于其他参数值推断数据类型。如果需要可以显示指定,参数值为NumPy 和 Python支持的任意数据类型。
#以下实例start=1,stop=10,num=10
np.linspace(1,10,10)
array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
#使用endpoint参数,设置不包含终止值
np.linspace(1,10,9,endpoint=False)
array([1., 2., 3., 4., 5., 6., 7., 8., 9.])
#使用retstep参数,设置生成的数组张总显示间距
np.linspace(1,10,10,retstep=True)
(array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]), 1.0)
#使用dtype参数,设置返回类型
x1=np.linspace(1,10,9,dtype=int)#取整
x2=np.linspace(1,10,9)
print(x1)
print(x2)
[ 1 2 3 4 5 6 7 8 10]
[ 1. 2.125 3.25 4.375 5.5 6.625 7.75 8.875 10. ]
logspace()创建等比数列
返回间隔[开始,停止]上计算的num个均匀间隔的样本。数组是一个比数列构成
np.logspace(start,stop,num=50,endpoint=True,base=10.0,dtype=None)
参数说明:
start 参数数值范围的起始点。如果设置为0,则结果的第一个数为0.该参数必须提供。
stop 参数数值范围的终止点。通常其为结果的最后一个值,但如果修改endpoint = False, 则结果中不包括该值
num 参数控制结果中共有多少个元素。如果num=5,则输出数组个数为5.该参数可选,缺省为50.
endpoint 参数决定终止值(stop参数指定)是否被包含在结果数组中。如果 endpoint = True, 结果中包括终止值,反之不包括。缺省为True。
base:对数log的底数
dtype参数和其他的 NumPy 一样, np.linspace中的dtype 参数决定输出数组的数据类型。如果不指定,python基于其他参数值推断数据类型。如果需要可以显示指定,参数值为NumPy 和 Python支持的任意数据类型。
np.logspace(0,9,10,base=2)
array([ 1., 2., 4., 8., 16., 32., 64., 128., 256., 512.])
np.logspace(A,B,C,base=D)
A:生成数组的起始值为D的A次方
B:生成数组的结束值为D的B次方
C:总共生成C个数
D:指数型数组的底数为D,当省略base=D时,默认底数为10
#使用前三个参数将[1,5]均分为三个数
np.logspace(1,5,3,base=2,dtype=int)
array([ 2, 8, 32])
#取1.0,2.0之间10个常用的对数
np.logspace(1.0,2.0,num=10)#可以理解为把1~2均分为十份指数,分别赋给base作为指数
array([ 10. , 12.91549665, 16.68100537, 21.5443469 ,
27.82559402, 35.93813664, 46.41588834, 59.94842503,
77.42636827, 100. ])
x=np.linspace(1.0,2.0,num=10)
print(x)
10**x
[1. 1.11111111 1.22222222 1.33333333 1.44444444 1.55555556
1.66666667 1.77777778 1.88888889 2. ]
array([ 10. , 12.91549665, 16.68100537, 21.5443469 ,
27.82559402, 35.93813664, 46.41588834, 59.94842503,
77.42636827, 100. ])
NumPy 数组属性
Numpy的数组中比较重要ndarray对象属性有:
ndarray.ndim 秩,即轴的数量或维度的数量
ndarray.shape 数组的维度,对于矩阵,n 行 m 列
ndarray.size 数组元素的总个数,相当于 .shape 中 n*m 的值
ndarray.dtype ndarray 对象的元素类型
ndarray.itemsize ndarray 对象中每个元素的大小,以字节为单位
ndarray.shape
ndarray.shape 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim 属性(秩)。比如,一个二维数组,其维度表示"行数"和"列数"。
a=np.array([1,2,3,4,5,6])
print('一维数组:',a.shape)
b=np.array([[1,2,3],[4,5,6]])
print('二维数组:',b.shape)
c=np.array([
[
[1,2,3,4],
[2,4,5,6]
],
[
[1,2,4,5],
[1,3,4,5]
]
])
print('三维数组',c.shape)
一维数组: (6,)
二维数组: (2, 3)
三维数组 (2, 2, 4)
NumPy 也提供了 reshape 函数来调整数组大小
a=np.array([1,2,4,5,3,5,6,3,5,7])
#ndarray.reshape 通常返回的是非拷贝副本,即改变返回后数组的元素,原数组对应元素的值也会改变。
b=a.reshape(5,2)#5行2列
b[1,1]=3
print(a)
print(b)
[1 2 4 3 3 5 6 3 5 7]
[[1 2]
[4 3]
[3 5]
[6 3]
[5 7]]
ndarray.ndim
ndarray.ndim 用于返回数组的维数,等于秩。
a=np.array([
[
[1,2,3,4],
[2,4,5,6]
],
[
[1,2,4,5],
[1,3,4,5]
]
])
x=a.ndim
y=b.ndim
print(x)
print(y)
3
2
ndarray.itemsize
ndarray.itemsize 以字节的形式返回数组中每一个元素的大小。
例如,一个元素类型为 float64 的数组 itemsize 属性值为 8(float64 占用 64 个 bits,每个字节长度为 8,所以 64/8,占用 8 个字节),又如,一个元素类型为 complex32 的数组 item 属性为 4(32/8)。
a=np.array([
[
[1,2,3,4],
[2,4,5,6]
],
[
[1,2,4,5],
[1,3,4,5]
]
]
,dtype=float
)
x=a.itemsize
print(x)
8
ndarray.size 数组元素的总个数,相当于 .shape 中 n*m 的值
x=a.size
print(x)
16
ndarray.dtype ndarray 对象的元素类型
x=a.dtype
print(x)
float64
#修改dtype
a.dtype=int
y=a.dtype
print(y)
int32
NumPy 创建数组
ndarray 数组除了可以使用底层 ndarray 构造器来创建外,也可以通过以下几种方式来创建。
numpy.empty方法
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy.empty(shape, dtype = float, order = 'C')
numpy.zeros
创建指定大小的数组,数组元素以 0 来填充:
numpy.zeros(shape, dtype = float, order = 'C')
numpy.ones
创建指定形状的数组,数组元素以 1 来填充:
numpy.ones(shape, dtype = None, order = 'C')
参数说明:
shape 数组形状
dtype 数据类型,可选
order 有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。
#注意 − 数组元素为随机值,因为它们未初始化。
a=np.empty(shape=(2,3),dtype=float)
print(a)
[[6.23042070e-307 4.67296746e-307 1.69121096e-306]
[1.29061074e-306 1.89146896e-307 7.56571288e-307]]
#使用numpy.zeros() 创建指定大小的数组,数组元素以 0 来填充
b=np.zeros(shape=(2,3),dtype=int)
print(b)
[[0 0 0]
[0 0 0]]
# 使用numpy.ones() 创建指定形状的数组,数组元素以 1 来填充
#默认为浮点数,我们这里手动指定类型为int
c=np.ones(shape=(3,3),dtype=int)
print(c)
[[1 1 1]
[1 1 1]
[1 1 1]]
NumPy 从已有的数组创建数组 numpy.asarray
numpy.asarray 类似 numpy.array,但 numpy.asarray 参数只有三个,比 numpy.array 少两个。
numpy.asarray(a, dtype = None, order = None)
参数说明:
a 任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组
dtype 数据类型,可选
order 可选,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。
#将列表转换为 ndarray
x=[1,2,3,4,5,6]
#是直接拷贝副本,修改副本主体编号改变
a=np.asarray(x,dtype=float)
a[1]=10
print(a)
print(x)
[ 1. 10. 3. 4. 5. 6.]
[1, 2, 3, 4, 5, 6]
#将元组转换为 ndarray
x=(1,2,3,4,5,6,7,8)
a=np.asarray(x,dtype=float)
print(a)
[1. 2. 3. 4. 5. 6. 7. 8.]
#将元组列表转换为 ndarray
x=[(1,2,3),(1,3,4)]
a=np.asarray(x,dtype=float)
print(a)
[[1. 2. 3.]
[1. 3. 4.]]
numpy.frombuffer()用于实现动态数组。
numpy.frombuffer 接受 buffer 输入参数,以流的形式读入转化成 ndarray 对象。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
注意:buffer 是字符串的时候,Python3 默认 str 是 Unicode 类型,所以要转成 bytestring 在原 str 前加上 b。
参数说明:
buffer 可以是任意对象,会以流的形式读入。
dtype 返回数组的数据类型,可选
count 读取的数据数量,默认为-1,读取所有数据。
offset 读取的起始位置,默认为0。
a=b'hello worldll'
#buffer 是字符串的时候,Python3 默认 str 是 Unicode 类型,所以要转成 bytestring 在原 str 前加上 b。
b=np.frombuffer(a,dtype='S1')
print(b)
[b'h' b'e' b'l' b'l' b'o' b' ' b'w' b'o' b'r' b'l' b'd' b'l' b'l']
numpy.fromiter 方法从可迭代对象中建立 ndarray 对象,返回一维数组。
numpy.fromiter(iterable, dtype, count=-1)
参数说明
iterable 可迭代对象
dtype 返回数组的数据类型
count 读取的数据数量,默认为-1,读取所有数据
list =np.arange(5)
it=iter(list)
a=np.fromiter(it,dtype=float)
print(a)
[0. 1. 2. 3. 4.]
NumPy 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
a=np.arange(10)
s=slice(2,7,2)# 从索引 2 开始到索引 7 停止,间隔为2
print(a[s])
[2 4 6]
# 以上实例中,我们首先通过 arange() 函数创建 ndarray 对象。 然后,分别设置起始,终止和步长的参数为 2,7 和 2。
# 我们也可以通过冒号分隔切片参数 start:stop:step 来进行切片操作:
b=a[2:7:2]
print(b)
# 冒号 : 的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。
# 如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
c=a[2] #将返回与该索引相对应的单个元素
print(c)
d=a[2:] #表示从该索引开始以后的所有项都将被提取。
print(d)
[2 4 6]
2
[2 3 4 5 6 7 8 9]
#切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
b=a[(...,2)]#放在行
print(b)
c=a[(2,...)]#放在列
print(c)
[3 5 6]
[4 5 6]
NumPy 高级索引
NumPy 比一般的 Python 序列提供更多的索引方式。
除了之前看到的用整数和切片的索引外,数组可以由整数数组索引、布尔索引及花式索引。
整数数组索引
# 以下实例获取数组中 (0,0),(1,1) 和 (2,0) 位置处的元素。
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
b=a[[0,1,2],[0,1,0]]
print(b)
[1 4 4]
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('我们的数组是:' )
print (x)
print ('\n')
#可以这么理解:行列表是二维,列列表是二维,所有最后的元素列表也是二维
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print ('这个数组的四个角元素是:')
print (y)
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
这个数组的四个角元素是:
[[ 0 2]
[ 9 11]]
# 返回的结果是包含每个角元素的 ndarray 对象。
# 可以借助切片 : 或 … 与索引数组组合。
a = np.array([[1,2,3], [4,5,6],[7,8,9]])
b=a[1:3,1:3]
print(b)
c=a[1:3,[1,2]]
print(c)
d=a[...,1:3]
print(d)
[[5 6]
[8 9]]
[[5 6]
[8 9]]
[[2 3]
[5 6]
[8 9]]
布尔索引
我们可以通过一个布尔数组来索引目标数组。
布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
#以下实例获取大于 5 的元素
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('我们的数组是:')
print (x)
print ('\n')
# 现在我们会打印出大于 5 的元素
print ('大于 5 的元素是:')
print (x[x > 5])
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
大于 5 的元素是:
[ 6 7 8 9 10 11]
#以下实例使用了 ~(取补运算符)来过滤 NaN。
a = np.array([np.nan, 1,2,np.nan,3,4,5])
print (a[~np.isnan(a)])
#np.nan是一个特殊的浮点型数据
[1. 2. 3. 4. 5.]
#以下实例演示如何从数组中过滤掉非复数元素。
a = np.array([1, 2+6j, 5, 3.5+5j])
print (a[np.iscomplex(a)])
[2. +6.j 3.5+5.j]
# 布尔索引不一定针对数组的所有元素,可以针对某一列的数据,进而提取需要的数组。
a = np.array([[1, 1, 0],
[2, 1, 0],
[3, 2, 0],
[4, 2, 0],
[5, 3, 0]])
print(a[a[...,0] > 2])#第0列大于2的行
[[3 2 0]
[4 2 0]
[5 3 0]]
花式索引
花式索引指的是利用整数数组进行索引。
花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。
对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素,如果目标是二维数组,那么就是对应下标的行。
花式索引跟切片不一样,它总是将数据复制到新数组中。
一维数组
一维数组只有一个轴 axis = 0,所以一维数组就在 axis = 0 这个轴上取值:
#实例
x = np.arange(9)
print(x)
# 一维数组读取指定下标对应的元素
print("-------读取下标对应的元素-------")
x2 = x[[0, 6]] # 使用花式索引
print(x2)
print(x2[0])
print(x2[1])
[0 1 2 3 4 5 6 7 8]
-------读取下标对应的元素-------
[0 6]
0
6
二维数组
#1、传入顺序索引数组
#实例
x=np.arange(32).reshape((8,4))
print(x)
# 二维数组读取指定下标对应的行
print("-------读取下标对应的行-------")
print (x[[4,2,1,7]])
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
-------读取下标对应的行-------
[[16 17 18 19]
[ 8 9 10 11]
[ 4 5 6 7]
[28 29 30 31]]
#3、传入多个索引数组(要使用 np.ix_)
# np.ix_ 函数就是输入两个数组,产生笛卡尔积的映射关系。
# 笛卡尔乘积是指在数学中,两个集合 X 和 Y 的笛卡尔积(Cartesian product),又称直积,表示为 X×Y,
# 第一个对象是X的成员而第二个对象是 Y 的所有可能有序对的其中一个成员。
# 例如 A={a,b}, B={0,1,2},则:
# A×B={(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
# B×A={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)}
#实例
x=np.arange(32).reshape((8,4))
print(x)
#如果 np.xi_ 中输入两个列表,则第一个列表存的是待提取元素的行标,第二个列表存的是待提取元素的列标,
# 第一个列表中的每个元素都会遍历第二个列表中的每个值,构成新矩阵的一行元素。
print (x[np.ix_([1,5,7,2],[0,3,1,2])])
print(x[np.ix_([1,2,4],[2,1,0,3])])
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
[[ 6 5 4 7]
[10 9 8 11]
[18 17 16 19]]
NumPy 广播(Broadcast)
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
a=np.array([1,2,3,4])
b=np.array([10,20,30,40])
c=a*b
print(c)
[ 10 40 90 160]
#当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。如:
a=np.array([6,6,6])
b=np.array([
[0,0,0],
[60,70,80],
[909,707,808]
])
c=a+b
print(c)
[[ 6 6 6]
[ 66 76 86]
[915 713 814]]
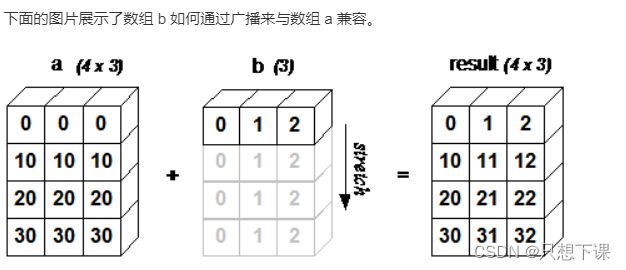
#模拟广播
a=np.array([6,6,6])
b=np.array([
[0,0,0],
[60,70,80],
[909,707,808]
])
#numpy.tile()是个什么函数呢,说白了,就是把数组沿各个方向复制
aa=np.tile(a,(3,1))#沿着x轴复制一倍,y轴复制三倍
print(aa+b)
[[ 6 6 6]
[ 66 76 86]
[915 713 814]]
#numpy.tile(A , reps)详解:
#这里的 A 就是数组,reps 可以是一个数,一个列表、元组或者数组等,就是类数组的类型。先要理解准确,先把 A 当作一个块(看作一个整体,别分开研究每个元素)。
#(1)如果 reps 是一个数,就是简单的将 A 向右复制 reps - 1 次形成新的数组,就是 reps 个 A 横向排列:
a = np.array([[1,2],[3,4]])
b = np.tile(a,2) #向右复制,两个 A 横向排列
print(b)
#(2)如果 reps 是一个 array-like(类数组的,如列表,元组,数组)类型的,它有两个元素,如 [m,n],
#实际上就是将 A 这个块变成 m * n 个 A 组成的新数组,有 m 行,n 列 A:
a = np.array([[1,2],[3,4]])
b = np.tile(a,(2,3)) #2 * 3 个 A 组成新数组
print(b)
[[1 2 1 2]
[3 4 3 4]]
[[1 2 1 2 1 2]
[3 4 3 4 3 4]
[1 2 1 2 1 2]
[3 4 3 4 3 4]]
广播的规则:
让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
输出数组的形状是输入数组形状的各个维度上的最大值。
如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
简单理解:对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
数组拥有相同形状。
当前维度的值相等。
当前维度的值有一个是 1。
若条件不满足,抛出 "ValueError: frames are not aligned" 异常
NumPy 迭代数组
NumPy 迭代器对象 numpy.nditer 提供了一种灵活访问一个或者多个数组元素的方式。
迭代器最基本的任务的可以完成对数组元素的访问。
#接下来我们使用 arange() 函数创建一个 2X3 数组,并使用 nditer 对它进行迭代。
a=np.arange(6).reshape(3,2)
print(a)
print("\n")
for i in np.nditer(a):
print(i,end=", ")
[[0 1]
[2 3]
[4 5]]
0, 1, 2, 3, 4, 5,
a = np.arange(6).reshape(2,3)
for x in np.nditer(a.T):
print (x, end=", " )
print ('\n')
print(a.T)
for x in np.nditer(a.T.copy(order='C')):
print (x, end=", " )
print ('\n')
0, 1, 2, 3, 4, 5,
[[0 3]
[1 4]
[2 5]]
0, 3, 1, 4, 2, 5,
同时nditer中,还提供了两个参数,控制迭代器输出顺序:
for x in np.nditer(a, order=‘F’) # Fortran order,即是列序优先;
for x in np.nditer(a.T, order=‘C’) # C order,即是行序优先
a=np.arange(12).reshape(3,4)
#order参数默认值为K,该默认值表示,按在存储器中的顺序输出
for x in np.nditer(a.T,order='K'):
print(x,end=',')
print('\n')
for x in np.nditer(a.T,order='C'):
print(x,end=',')
0,1,2,3,4,5,6,7,8,9,10,11,
0,4,8,1,5,9,2,6,10,3,7,11,
Numpy 数组操作
Numpy 中包含了一些函数用于处理数组,大概可分为以下几类:
修改数组形状
翻转数组
修改数组维度
连接数组
分割数组
数组元素的添加与删除
修改数组形状
函数 描述
reshape 不改变数据的条件下修改形状
flat 数组元素迭代器
flatten 返回一份数组拷贝,对拷贝所做的修改不会影响原始数组
ravel 返回展开数组
#reshape函数 不改变数据的条件下修改形状
a=np.arange(12).reshape(4,3)
print(a)
print(a.reshape(3,4))
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
#flat函数 数组元素迭代器
##对数组中每个元素都进行处理,可以使用flat属性,该属性是一个数组元素迭代器:
for i in a.flat:
print(i)
0
1
2
3
4
5
6
7
8
9
10
11
#numpy.ndarray.flatten(order)函数 numpy.ndarray.flatten 返回一份数组拷贝,对拷贝所做的修改不会影响原始数组
#order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'K' -- 元素在内存中的出现顺序。
b=a.flatten(order='C');
print(b)
b=a.flatten(order='F');
print(b)
[ 0 1 2 3 4 5 6 7 8 9 10 11]
[ 0 3 6 9 1 4 7 10 2 5 8 11]
#numpy.ravel()函数 展平的数组元素,顺序通常是"C风格",返回的是数组视图(view,有点类似 C/C++引用reference的意味),修改会影响原始数组。
#numpy.ravel(a, order='C')
b=a.ravel()
print(b)
#修改会修改原数据
b[1]=100
print(a)
print(b)
[ 0 5 2 10 10 10 6 7 8 9 10 11]
[[ 0 100 2]
[ 10 10 10]
[ 6 7 8]
[ 9 10 11]]
[ 0 100 2 10 10 10 6 7 8 9 10 11]
翻转数组
函数 描述
transpose 对换数组的维度
ndarray.T 和 self.transpose() 相同
rollaxis 向后滚动指定的轴
swapaxes 对换数组的两个轴
#numpy.transpose 函数用于对换数组的维度,格式:numpy.transpose(arr, axes)
#arr:要操作的数组 axes:整数列表,对应维度,通常所有维度都会对换。
a=np.arange(12).reshape(3,4)
print(a)
print(np.transpose(a,axes=(1,0)))
#高维数组示例
a=np.arange(16).reshape(2,2,4)
print(a)
print('\n')
#相当于把三维数组想成三个轴,分别为0,1,2,调换他们就是调换维度
print(np.transpose(a,axes=(0,2,1)))
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]]
[[[ 0 4]
[ 1 5]
[ 2 6]
[ 3 7]]
[[ 8 12]
[ 9 13]
[10 14]
[11 15]]]
#numpy.ndarray.T 类似 numpy.transpose:
a = np.arange(12).reshape(3,4)
print ('原数组:')
print (a)
print ('\n')
print ('转置数组:')
print (a.T)
原数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
转置数组:
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
#numpy.swapaxes 函数用于交换数组的两个轴
#numpy.swapaxes(arr, axis1, axis2)
#arr:输入的数组 axis1:对应第一个轴的整数 axis2:对应第二个轴的整数
a = np.arange(8).reshape(2,2,2)
print ('原数组:')
print (a)
print ('\n')
# 现在交换轴 0(深度方向)到轴 2(宽度方向)
print ('调用 swapaxes 函数后的数组:')
print (np.swapaxes(a, 2, 0))
原数组:
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
调用 swapaxes 函数后的数组:
[[[0 1]
[4 5]]
[[2 3]
[6 7]]]
修改数组维度
维度 描述
broadcast 产生模仿广播的对象
broadcast_to 将数组广播到新形状
expand_dims 扩展数组的形状
squeeze 从数组的形状中删除一维条目
# numpy.broadcast_to 函数将数组广播到新形状。它在原始数组上返回只读视图。 它通常不连续。
# 如果新形状不符合 NumPy 的广播规则,该函数可能会抛出ValueError。
a=np.arange(4).reshape(1,4)
print(a)
print('\n')
print(np.broadcast_to(a,(5,4)))
[[0 1 2 3]]
[[0 1 2 3]
[0 1 2 3]
[0 1 2 3]
[0 1 2 3]
[0 1 2 3]]
#numpy.expand_dims 函数通过在指定位置插入新的轴来扩展数组形状,函数格式如下:
#numpy.expand_dims(arr, axis)
x = np.array(([1,2],[3,4]))
print ('数组 x:')
print (x)
print ('\n')
y = np.expand_dims(x, axis = 0)
print ('数组 y:')
print (y)
print ('\n')
print ('数组 x 和 y 的形状:')
print (x.shape, y.shape)
print ('\n')
# 在位置 1 插入轴
y = np.expand_dims(x, axis = 1)
print ('在位置 1 插入轴之后的数组 y:')
print (y)
print ('\n')
print ('x.ndim 和 y.ndim:')
print (x.ndim,y.ndim)
print ('\n')
print ('x.shape 和 y.shape:')
print (x.shape, y.shape)
数组 x:
[[1 2]
[3 4]]
3
数组 y:
[[[1 2]
[3 4]]]
数组 x 和 y 的形状:
(2, 2) (1, 2, 2)
在位置 1 插入轴之后的数组 y:
[[[1 2]]
[[3 4]]]
x.ndim 和 y.ndim:
2 3
x.shape 和 y.shape:
(2, 2) (2, 1, 2)
#numpy.squeeze 函数从给定数组的形状中删除一维的条目,函数格式如下:
# numpy.squeeze(arr, axis)
# arr:输入数组 axis:整数或整数元组,用于选择形状中一维条目的子集
x = np.arange(9).reshape(1,3,3)
print ('数组 x:')
print (x)
print ('\n')
# np.squeeze()函数可以删除数组形状中的单维度条目,
# 即把shape中为1的维度去掉,但是对非单维的维度不起作用。
y = np.squeeze(x,axis=0)
print ('数组 y:')
print (y)
print ('\n')
print ('数组 x 和 y 的形状:')
print (x.shape, y.shape)
数组 x:
[[[0 1 2]
[3 4 5]
[6 7 8]]]
数组 y:
[[0 1 2]
[3 4 5]
[6 7 8]]
数组 x 和 y 的形状:
(1, 3, 3) (3, 3)
连接数组
函数 描述
concatenate 连接沿现有轴的数组序列
stack 沿着新的轴加入一系列数组。
hstack 水平堆叠序列中的数组(列方向)
vstack 竖直堆叠序列中的数组(行方向)
# numpy.concatenate 函数用于沿指定轴连接相同形状的两个或多个数组,格式如下:
# numpy.concatenate((a1, a2, ...), axis)
a = np.array([[1,2],[3,4]])
print ('第一个数组:')
print (a)
print ('\n')
b = np.array([[5,6],[7,8]])
print ('第二个数组:')
print (b)
print ('\n')
# 两个数组的维度相同
print ('沿轴 0 连接两个数组:')
print (np.concatenate((a,b)))
print ('\n')
print ('沿轴 1 连接两个数组:')
print (np.concatenate((a,b),axis = 1))
第一个数组:
[[1 2]
[3 4]]
第二个数组:
[[5 6]
[7 8]]
沿轴 0 连接两个数组:
[[1 2]
[3 4]
[5 6]
[7 8]]
沿轴 1 连接两个数组:
[[1 2 5 6]
[3 4 7 8]]
# numpy.stack 函数用于沿新轴连接数组序列,格式如下:
# numpy.stack(arrays, axis)
# arrays相同形状的数组序列 axis:返回数组中的轴,输入数组沿着它来堆叠
a = np.array([[1,2],[3,4]])
print ('第一个数组:')
print (a)
print ('\n')
b = np.array([[5,6],[7,8]])
print ('第二个数组:')
print (b)
print ('\n')
print ('沿轴 0 堆叠两个数组:')
print (np.stack((a,b),0))
print ('\n')
print ('沿轴 1 堆叠两个数组:')
print (np.stack((a,b),1))
print ('沿轴 2 堆叠两个数组:')
print (np.stack((a,b),2))
第一个数组:
[[1 2]
[3 4]]
第二个数组:
[[5 6]
[7 8]]
沿轴 0 堆叠两个数组:
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
沿轴 1 堆叠两个数组:
[[[1 2]
[5 6]]
[[3 4]
[7 8]]]
沿轴 2 堆叠两个数组:
[[[1 5]
[2 6]]
[[3 7]
[4 8]]]
# numpy.vstack 是 numpy.stack 函数的变体,它通过垂直堆叠来生成数组。
a = np.array([[1,2],[3,4]])
print ('第一个数组:')
print (a)
print ('\n')
b = np.array([[5,6],[7,8]])
print ('第二个数组:')
print (b)
print ('\n')
print ('竖直堆叠:')
c = np.vstack((a,b))
print (c)
第一个数组:
[[1 2]
[3 4]]
第二个数组:
[[5 6]
[7 8]]
竖直堆叠:
[[1 2]
[3 4]
[5 6]
[7 8]]
# numpy.hstack 是 numpy.stack 函数的变体,它通过水平堆叠来生成数组。
a = np.array([[1,2],[3,4]])
print ('第一个数组:')
print (a)
print ('\n')
b = np.array([[5,6],[7,8]])
print ('第二个数组:')
print (b)
print ('\n')
print ('水平堆叠:')
c = np.hstack((a,b))
print (c)
第一个数组:
[[1 2]
[3 4]]
第二个数组:
[[5 6]
[7 8]]
水平堆叠:
[[1 2 5 6]
[3 4 7 8]]
分割数组
函数 数组及操作
split 将一个数组分割为多个子数组
hsplit 将一个数组水平分割为多个子数组(按列)
vsplit 将一个数组垂直分割为多个子数组(按行)
# numpy.split 函数沿特定的轴将数组分割为子数组,格式如下:
# numpy.split(ary, indices_or_sections, axis)
a=np.arange(15).reshape(3,5)
print(a)
#axis 为 0 时在水平方向分割,axis 为 1 时在垂直方向分割
b=np.split(a,3,axis=0)
print(b)
#表明分割位置
c=np.split(a,[2,4],axis=1)
print(c)
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[array([[0, 1, 2, 3, 4]]), array([[5, 6, 7, 8, 9]]), array([[10, 11, 12, 13, 14]])]
[array([[ 0, 1],
[ 5, 6],
[10, 11]]), array([[ 2, 3],
[ 7, 8],
[12, 13]]), array([[ 4],
[ 9],
[14]])]
数组元素的添加与删除
函数 元素及描述
resize 返回指定形状的新数组
append 将值添加到数组末尾
insert 沿指定轴将值插入到指定下标之前
delete 删掉某个轴的子数组,并返回删除后的新数组
unique 查找数组内的唯一元素
# numpy.resize 函数返回指定大小的新数组。
# numpy.resize(arr, shape)
# arr:要修改大小的数组 shape:返回数组的新形状
a=np.arange(12).reshape(3,4)
print(a)
b=np.resize(a,(4,3))
print(b)
# 如果新数组大小大于原始大小,则包含原始数组中的元素的副本。
c=np.resize(a,(4,4))
print(c)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[ 0 1 2 3]]
# numpy.append 函数在数组的末尾添加值。 追加操作会分配整个数组,并把原来的数组复制到新数组中。
# 此外,输入数组的维度必须匹配否则将生成ValueError。
# append 函数返回的始终是一个一维数组。
# numpy.append(arr, values, axis=None)
# arr:输入数组 values:要向arr添加的值,需要和arr形状相同(除了要添加的轴)
# axis:默认为 None。当axis无定义时,是横向加成,返回总是为一维数组!
# 当axis有定义的时候,分别为0和1的时候(列数要相同)。当axis为1时,数组是加在右边(行数要相同)。
a=np.arange(6)
# 一维数组
b=np.append(a,3)
print(b)
#二维数组
c=a.reshape(2,3)
print(c)
#沿轴0添加元素
d=np.append(c,[[2,3,4]],axis=0)
print(d)
#沿轴1添加元素
f=np.append(c,[[1,2],[2,3]],axis=1)
print(f)
#不给定axis值(永远返回一维数组)
g=np.append(c,[7,8,9])
print(g)
[0 1 2 3 4 5 3]
[[0 1 2]
[3 4 5]]
[[0 1 2]
[3 4 5]
[2 3 4]]
[[0 1 2 1 2]
[3 4 5 2 3]]
[0 1 2 3 4 5 7 8 9]
#numpy.insert 函数在给定索引之前,沿给定轴在输入数组中插入值。
# 如果值的类型转换为要插入,则它与输入数组不同。 插入没有原地的,函数会返回一个新数组。 此外,如果未提供轴,则输入数组会被展开。
# numpy.insert(arr, obj, values, axis)
# arr:输入数组 obj:在其之前插入值的索引
# values:要插入的值 axis:沿着它插入的轴,如果未提供,则输入数组会被展开
a = np.array([[1,2],[3,4],[5,6]])
print ('第一个数组:')
print (a)
print ('\n')
print ('未传递 Axis 参数。 在删除之前输入数组会被展开。')
print (np.insert(a,3,[11,12]))
print ('\n')
print ('传递了 Axis 参数。 会广播值数组来配输入数组。')
print ('沿轴 0 广播:')
print (np.insert(a,1,[11],axis = 0))
print ('\n')
print ('沿轴 1 广播:')
print (np.insert(a,1,11,axis = 1))
第一个数组:
[[1 2]
[3 4]
[5 6]]
未传递 Axis 参数。 在删除之前输入数组会被展开。
[ 1 2 3 11 12 4 5 6]
传递了 Axis 参数。 会广播值数组来配输入数组。
沿轴 0 广播:
[[ 1 2]
[11 11]
[ 3 4]
[ 5 6]]
沿轴 1 广播:
[[ 1 11 2]
[ 3 11 4]
[ 5 11 6]]
NumPy 数学函数
NumPy 包含大量的各种数学运算的函数,包括三角函数,算术运算的函数,复数处理函数等。
三角函数
NumPy 提供了标准的三角函数:sin()、cos()、tan()。
#sin(),cos(),tan()
a=np.array([0,30,45,60,90])
#通过乘pi/180转化为弧度
print('正弦值')
print(np.sin(a*np.pi/180))
print('余弦值')
print(np.cos(a*np.pi/180))
print('正切值')
print(np.tan(a*np.pi/180))
正弦值
[0. 0.5 0.70710678 0.8660254 1. ]
余弦值
[1.00000000e+00 8.66025404e-01 7.07106781e-01 5.00000000e-01
6.12323400e-17]
正切值
[0.00000000e+00 5.77350269e-01 1.00000000e+00 1.73205081e+00
1.63312394e+16]
# arcsin,arccos,和 arctan 函数返回给定角度的 sin,cos 和 tan 的反三角函数。
# 这些函数的结果可以通过 numpy.degrees() 函数将弧度转换为角度。
a=np.array([0,30,45,60,90])
#通过乘pi/180转化为弧度
#arcsin()
sin=np.sin(a*np.pi/180)
print('计算反正弦值:')
print(np.arcsin(sin))
print('通过反正弦值求角度')
print(np.degrees(np.arcsin(sin)))
#其他同理
计算反正弦值:
[0. 0.52359878 0.78539816 1.04719755 1.57079633]
通过反正弦值求角度
[ 0. 30. 45. 60. 90.]
舍入函数
1.numpy.around() 函数返回指定数字的四舍五入值。
numpy.around(a,decimals)
参数:
a: 数组
decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置
2.numpy.floor()
numpy.floor() 返回小于或者等于指定表达式的最大整数,即向下取整。
3.numpy.ceil()
numpy.ceil() 返回大于或者等于指定表达式的最小整数,即向上取整。
#1.numpy.around()
a=np.array([1.27,1.56,1.72,8.99,2.39])
#保留一位小数
b=np.around(a,1)
print(b)
#如果为负,整数将四舍五入到小数点左侧的位置
c=np.around(a,-1)
print(c)
[1.3 1.6 1.7 9. 2.4]
[ 0. 0. 0. 10. 0.]
#2.numpy.floor()
c=np.floor(a)
print(c)
[1. 1. 1. 8. 2.]
#3.numpy.ceil()
d=np.ceil(a)
print(d)
[2. 2. 2. 9. 3.]
NumPy 算术函数
NumPy 算术函数包含简单的加减乘除: add(),subtract(),multiply() 和 divide()。
需要注意的是数组必须具有相同的形状或符合数组广播规则。
此外 Numpy 也包含了其他重要的算术函数。
1.numpy.reciprocal() 函数返回参数逐元素的倒数。如 1/4 倒数为 4/1。
2.numpy.power() 函数将第一个输入数组中的元素作为底数,计算它与第二个输入数组中相应元素的幂。
3.numpy.mod() 计算输入数组中相应元素的相除后的余数。 函数 numpy.remainder() 也产生相同的结果。
a=np.arange(9).reshape(3,3)
b=np.arange(3).reshape(1,3)
print(a)
print(b)
print('\n')
#加add()
print(np.add(a,b))
print('\n')
#减subtract()
print(np.subtract(a,b))
print('\n')
#乘multiply()
print(np.multiply(a,b))
print('\n')
#除divide()
c=np.add(a,[1,1,1])
d=np.add(b,[1,1,1])
print(c)
print(d)
print('\n')
print(np.divide(c,d))
[[0 1 2]
[3 4 5]
[6 7 8]]
[[0 1 2]]
[[ 0 2 4]
[ 3 5 7]
[ 6 8 10]]
[[0 0 0]
[3 3 3]
[6 6 6]]
[[ 0 1 4]
[ 0 4 10]
[ 0 7 16]]
[[1 2 3]
[4 5 6]
[7 8 9]]
[[1 2 3]]
[[1. 1. 1. ]
[4. 2.5 2. ]
[7. 4. 3. ]]
# 1.numpy.reciprocal() 函数返回参数逐元素的倒数。如 1/4 倒数为 4/1。
a=np.array([1,2,3,4,5,6,9],'float')
print(a)
print('倒数:')
b=np.reciprocal(a)
print(b)
#2.numpy.power() 函数将第一个输入数组中的元素作为底数,
# 计算它与第二个输入数组中相应元素的幂。
c=np.power(a,2)
print('幂函数:')
print(c)
#3.numpy.mod() 计算输入数组中相应元素的相除后的余数。
#函数 numpy.remainder() 也产生相同的结果。
d=np.mod(a,3)
print('求余数:')
print(d)
[1. 2. 3. 4. 5. 6. 9.]
倒数:
[1. 0.5 0.33333333 0.25 0.2 0.16666667
0.11111111]
幂函数:
[ 1. 4. 9. 16. 25. 36. 81.]
[1. 2. 0. 1. 2. 0. 0.]
NumPy 统计函数
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等
1.numpy.amin() 和 numpy.amax()
numpy.amin() 用于计算数组中的元素沿指定轴的最小值。
numpy.amax() 用于计算数组中的元素沿指定轴的最大值。
2.numpy.ptp()函数计算数组中元素最大值与最小值的差(最大值 - 最小值)。
3.百分位数是统计中使用的度量,表示小于这个值的观察值的百分比。 函数numpy.percentile()接受以下参数。 numpy.percentile(a, q, axis)
4.numpy.median() 函数用于计算数组 a 中元素的中位数(中值)
5.numpy.mean() 函数返回数组中元素的算术平均值。 如果提供了轴,则沿其计算。算术平均值是沿轴的元素的总和除以元素的数量。
6.numpy.average() 函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。
该函数可以接受一个轴参数。 如果没有指定轴,则数组会被展开。
加权平均值即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。
考虑数组[1,2,3,4]和相应的权重[4,3,2,1],通过将相应元素的乘积相加,并将和除以权重的和,来计算加权平均值
加权平均值 = (1*4+2*3+3*2+4*1)/(4+3+2+1)
7.标准差
标准差是一组数据平均值分散程度的一种度量。
标准差是方差的算术平方根。
标准差公式如下:std = sqrt(mean((x - x.mean())**2))
如果数组是 [1,2,3,4],则其平均值为 2.5。 因此,差的平方是 [2.25,0.25,0.25,2.25],并且再求其平均值的平方根除以 4,即 sqrt(5/4) ,结果为 1.1180339887498949。
8.方差
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即 mean((x - x.mean())** 2)。
换句话说,标准差是方差的平方根。
#1.numpy.amin() 和 numpy.amax()
a = np.array([[3,7,5],[8,4,3],[2,4,9]])
print(a)
#numpy.amin() 用于计算数组中的元素沿指定轴的最小值。
#1轴的
print('amin:')
print('1轴的:')
print(np.amin(a,1))
print('0轴的:')
print(np.amin(a,0))
#numpy.amax() 用于计算数组中的元素沿指定轴的最大值。
print('amax:')
print('1轴的:')
print(np.amax(a,1))
print('0轴的:')
print(np.amax(a,0))
[[3 7 5]
[8 4 3]
[2 4 9]]
amin:
1轴的:
[3 3 2]
0轴的:
[2 4 3]
amax:
1轴的:
[7 8 9]
0轴的:
[8 7 9]
# 2.numpy.ptp()函数计算数组中元素最大值与最小值的差(最大值 - 最小值)。
a=np.array([[3,7,5],
[8,4,3],
[2,4,9]])
print(a)
print(np.ptp(a))
print(np.ptp(a,1))
print(np.ptp(a,0))
[[3 7 5]
[8 4 3]
[2 4 9]]
7
[4 5 7]
[6 3 6]
# 3.百分位数是统计中使用的度量,表示小于这个值的观察值的百分比。
# 函数numpy.percentile()接受以下参数。 numpy.percentile(a, q, axis)
#参数说明:a: 输入数组 q: 要计算的百分位数,在 0 ~ 100 之间 axis: 沿着它计算百分位数的轴
a=np.array([[20,70,50,20],
[80,4,3,10],
[2,4,9,15]])
q=25
b=np.percentile(a,q)
print(b)
#按1轴
c=np.percentile(a,q,1)
print(c)
#按0轴
d=np.percentile(a,q,0)
print(d)
4.0
[20. 3.75 3.5 ]
[11. 4. 6. 12.5]
# 4.numpy.median() 函数用于计算数组 a 中元素的中位数(中值)
a=np.array([[20,70,50,20],
[80,4,3,10],
[2,4,9,15]])
b=np.median(a)
print(b)
c=np.median(a,1)
print(c)
12.5
[35. 7. 6.5]
#5.numpy.mean() 函数返回数组中元素的算术平均值。 如果提供了轴,则沿其计算。
#算术平均值是沿轴的元素的总和除以元素的数量。
a=np.array([[20,70,50,20],
[80,4,3,10],
[2,4,9,15]])
b=np.mean(a)
print(b)
c=np.mean(a,1)
print(c)
d=np.mean(a,0)
print(d)
23.916666666666668
[40. 24.25 7.5 ]
[34. 26. 20.66666667 15. ]
#6.numpy.average() 函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。
#该函数可以接受一个轴参数。 如果没有指定轴,则数组会被展开。
a=np.array([1,2,3,4])
print('数组:',a)
wts=np.array([4,3,2,1])
print('权重:',wts)
#如果不指定权重相当于mean函数
#不指定
print(np.average(a))
#指定权重
print(np.average(a,weights=wts))
# 如果 returned 参数设为 true,则返回权重的和
print(np.average(a,weights=wts,returned=True))
#在多维数组中,可以指定计算的轴
b = np.arange(6).reshape(3,2)
print ('我们的数组是:')
print (b)
print ('\n')
print ('修改后的数组:')
wt = np.array([3,5])
print (np.average(b, axis = 1, weights = wt))
print ('\n')
print ('修改后的数组:')
print (np.average(b, axis = 1, weights = wt, returned = True))
数组: [1 2 3 4]
权重: [4 3 2 1]
2.5
2.0
(2.0, 10.0)
我们的数组是:
[[0 1]
[2 3]
[4 5]]
修改后的数组:
[0.625 2.625 4.625]
修改后的数组:
(array([0.625, 2.625, 4.625]), array([8., 8., 8.]))
#7.标准差numpy.std()
print(np.std([1,2,3,4]))
1.118033988749895
#8.方差
#统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数
print(np.var([1,2,3,4]))
1.25
NumPy 排序、条件刷选函数
NumPy 提供了多种排序的方法。
这些排序函数实现不同的排序算法,每个排序算法的特征在于执行速度,最坏情况性能,所需的工作空间和算法的稳定性。
下表显示了三种排序算法的比较:
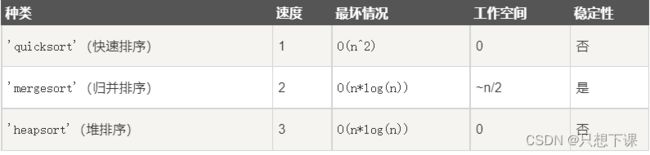
# 1.numpy.sort(a, axis, kind, order) 函数返回输入数组的排序副本。
# 参数说明:
# a: 要排序的数组
# axis: 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序, axis=0 按列排序,axis=1 按行排序
# kind: 默认为'quicksort'(快速排序)
# order: 如果数组包含字段,则是要排序的字段
a = np.array([[3,7],[9,1]])
print ('我们的数组是:')
print (a)
print ('\n')
print ('调用 sort() 函数:')
#默认按行排序
print (np.sort(a))
print ('\n')
print ('按列排序:')
print (np.sort(a, axis = 0))
print ('\n')
# 在 sort 函数中排序字段
dt = np.dtype([('name', 'S10'),('age', int)])
a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt)
print ('我们的数组是:')
print (a)
print ('\n')
print ('按 name 排序:')
print (np.sort(a, order = 'name'))
print ('\n')
print ('按 age 排序:')
print (np.sort(a, order = 'age'))
我们的数组是:
[[3 7]
[9 1]]
调用 sort() 函数:
[[3 7]
[1 9]]
按列排序:
[[3 1]
[9 7]]
我们的数组是:
[(b’raju’, 21) (b’anil’, 25) (b’ravi’, 17) (b’amar’, 27)]
按 name 排序:
[(b’amar’, 27) (b’anil’, 25) (b’raju’, 21) (b’ravi’, 17)]
按 age 排序:
[(b’ravi’, 17) (b’raju’, 21) (b’anil’, 25) (b’amar’, 27)]
#2.numpy.argsort() 函数返回的是数组值从小到大的索引值。
x=np.array([3,1,2])
print(np.argsort(x))
[1 2 0]
#3.numpy.lexsort() 用于对多个序列进行排序。
#把它想象成对电子表格进行排序,每一列代表一个序列,排序时优先照顾靠后的列。
# 录入了四位同学的成绩,按照总分排序,总分相同时语文高的优先
math = (10, 20, 50, 10)
chinese = (30, 50, 40, 60)
total = (40, 70, 90, 70)
#返回值是排序好的索引数组
ind =np.lexsort((math,chinese,total))
for i in ind:
print(total[i],chinese[i],math[i])
40 30 10
70 50 20
70 60 10
90 40 50
Numpy提供的条件刷取函数
#1.numpy.nonzero() 函数返回输入数组中非零元素的索引。
a = np.array([[30,40,0],[0,20,10],[50,0,60]])
print ('我们的数组是:')
print (a)
print ('\n')
print ('调用 nonzero() 函数:')
print (np.nonzero (a))
我们的数组是:
[[30 40 0]
[ 0 20 10]
[50 0 60]]
调用 nonzero() 函数:
(array([0, 0, 1, 1, 2, 2], dtype=int64), array([0, 1, 1, 2, 0, 2], dtype=int64))
#2.numpy.where() 函数返回输入数组中满足给定条件的元素的索引。
x = np.arange(9.).reshape(3, 3)
print ('我们的数组是:')
print (x)
print ( '大于 3 的元素的索引:')
y = np.where(x > 3)
print (y)
print ('使用这些索引来获取满足条件的元素:')
print (x[y])
我们的数组是:
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
大于 3 的元素的索引:
(array([1, 1, 2, 2, 2], dtype=int64), array([1, 2, 0, 1, 2], dtype=int64))
使用这些索引来获取满足条件的元素:
[4. 5. 6. 7. 8.]
#3.numpy.extract() 函数根据某个条件从数组中抽取元素,返回满条件的元素。
x = np.arange(9.).reshape(3, 3)
print ('我们的数组是:')
print (x)
# 定义条件, 选择偶数元素
condition = np.mod(x,2) == 0
print ('按元素的条件值:')
print (condition)
print ('使用条件提取元素:')
print (np.extract(condition, x))
我们的数组是:
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
按元素的条件值:
[[ True False True]
[False True False]
[ True False True]]
使用条件提取元素:
[0. 2. 4. 6. 8.]