k-近邻算法进行分类
最近学习机器学习,教材主要是周志华老师的《机器学习》和Peter Harrington的《机器学习实战》,周老师的书比较偏向于算法的讲解和推导,理论性很强,而《机器学习实战》更偏向机器学习算法的实际使用,还有Python代码的实现,更加直观。两本书配合起来,理论联系实际,可以学到不少东西。
今天先来看看比较简单的k-近邻算法,k-近邻算法属于监督学习方法,主要用于分类,它是懒惰学习的代表,所谓懒惰学习,就是不需要对模型进行训练,只需要将训练样本保存起来,等到处理待测样本时,再进行计算。
k-近邻算法的原理比较简单:
-
准备训练样本数据,每条样本要有标签,指明样本所属的类别;
-
输入被测样本数据(没有类别标签),与训练样本集中每条数据分别计算距离,提取距离最近的前k条训练样本数据的类别标签;
-
最后,对选出的k个类别标签进行投票,选出票数最多的分类,就是被测样本所属的分类。
下面开始看看例子,首先,我需要伪造一些数据,这里假设我的数据包含四列,前三列内容分别为一天的食物中肉,蔬菜和水果的比例(取值范围[0, 1],实际上也可以是三种食品的量),第四列是这一天的食物我是否喜欢的标签(0-喜欢,1-一般,2-不喜欢)。我这里写了一个小程序,用来生成假数据,数据会写入data.json中。
import random
import time
import json
data = []
random.seed(time.time())
for i in range(1000):
meat_ratio = random.uniform(0, 1)
vegetables_ratio = random.uniform(0, 1 - meat_ratio)
fruit_ratio = random.uniform(0, 1 - meat_ratio - vegetables_ratio)
if meat_ratio >= 0.4:
label = 0
elif meat_ratio < 0.4 and fruit_ratio >= 0.4:
label = 1
elif meat_ratio < 0.4 and fruit_ratio < 0.4:
label = 2
data.append([float('%.2f' % meat_ratio),
float('%.2f' % vegetables_ratio),
float('%.2f' % fruit_ratio), label])
json = json.dumps(data)
with open("data.json", "w") as f:
f.write(json)这段代码可以直接运行,主要为了生成100条数据。这100条数据中我会使用70条作为训练集,30条作为测试集。生成数据在data.json文件留作备用。生成的data.json的内容格式如下(由于随机生成,你的数据可能与我的不同):
[[0.92, 0.07, 0.0, 0], [0.21, 0.12, 0.54, 1],...]
k-近邻算法使用《机器学习实战》提供的程序,这里我针对Python3做了一些改动,我们来看一下算法的内容。
def classify0(in_x, data_set, labels, k=3):
# Calculate distance
data_set_size = data_set.shape[0]
diff_mat = np.tile(in_x, (data_set_size, 1)) - data_set
sq_diff_mat = diff_mat ** 2
sq_distances = sq_diff_mat.sum(axis=1)
distances = sq_distances ** 0.5
#Sort and get indicies
sorted_dist_indicies = distances.argsort()
#Find the first k labels and vote
class_count = {}
for i in range(k):
vote_i_label = labels[sorted_dist_indicies[i]]
class_count[vote_i_label] = class_count.get(vote_i_label, 0) + 1
sorted_class_count = sorted(class_count.items(),
key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]该算法的输入参数说明:
in_x:一条待测样本数据,类型为numpy的array;
data_set:训练集数据,类型为numpy的mat;
labels:训练集的标签集,类型为numpy的array;
k:取k个距离最近的样本的类别标签进行投票,默认是3。
接下来,我们首先计算距离,这里使用了欧氏距离进行计算,公式如下:
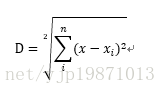
就是将被测数据的每一个特征值和训练集的第i个样本数据的对应特征值求差之后平方,再将所有平方值相加,得到的就是被测数据和训练集的第i个样本数据的欧式距离。
然后代码对计算出的距离进行排序,argsort返回距离排序后的列表的index,这样方便和labels对应。最后,对前k个距离最近的标签进行投票,并取得票数最多的类标签。
我们现在测试一下k-近邻算法处理我们当前这个问题的准确率如何。下面是《机器学习实战》提供的测试程序:
def auto_norm(data_set):
min_vals = data_set.min(0)
max_vals = data_set.max(0)
ranges = max_vals - min_vals
m = data_set.shape[0]
norm_data_set = data_set - np.tile(min_vals, (m, 1))
norm_data_set = norm_data_set / np.tile(ranges, (m, 1))
return norm_data_set, ranges, min_vals
def dating_class_test(dating_data_mat, dating_labels, ho_radio=0.10, k=3):
norm_mat, ranges, min_vals = auto_norm(dating_data_mat)
m = norm_mat.shape[0]
num_test_vecs = int(m * ho_radio)
error_count = 0.0
for i in range(num_test_vecs):
classifier_result = classify0(norm_mat[i, :],
norm_mat[num_test_vecs:m, :],
dating_labels[num_test_vecs:m], k)
print("the classifier came back with: %d, the real answer is: %d"
% (classifier_result, dating_labels[i]))
if classifier_result != dating_labels[i]:
error_count += 1.0
print("the total error rate is: %f and error count is: %f"
% (error_count / float(num_test_vecs), error_count)) auto_norm函数,是对特征数据的归一化处理,我们这里的特征数据已经归一化,所以这一步可以不做,但是为了通用性,我还是保留了这一部分代码。归一化可以百度一下,简单来说,就是将非[0, 1]范围的数据,映射到[0, 1]范围,如果不做这个处理,由欧式距离公式,如果某一个特征差值平方非常大,将会导致其他特征值的作用被弱化。
dating_class_test是我们的测试函数,该函数使用数据集测试k-近邻算法的错误率,ho_radio用来划分数据集,默认是0.10,即数据的90%作为训练集,10%z作为测试集。我们测试一下,在data.json数据上的错误率(由于随机生成的数据,你测试的错误率可能会与我的不同):
def read_data(filename):
with open(filename) as f:
data = json.load(f)
data_num = len(data)
data_set = np.zeros((data_num, 3))
data_labels = []
index = 0
for d in data:
data_set[index, :] = d[0:3]
data_labels.append(int(d[-1]))
index += 1
return data_set, data_labels
if __name__ == '__main__':
data_set, data_labels = read_data('data.json')
dating_class_test(data_set, data_labels, 0.3)最后输出为:
the total error rate is: 0.016667 and error count is: 5.000000
错误率只有0.02,相当低,这样,我们就可以放心的将k-近邻算法使用在我们的问题上了。下面写一个程序,来实现我们的目的:
def is_like_this_food():
meat_ratio = float(input('input meat ratio: '))
vegetables_ratio = float(input('input vegetables ratio: '))
fruit_ratio = float(input('input fruit ratio: '))
in_x = np.array([meat_ratio, vegetables_ratio, fruit_ratio])
data_set, data_labels = read_data('data.json')
norm_mat, ranges, min_vals = auto_norm(data_set)
classifier_result = classify0((in_x - min_vals) / ranges,
norm_mat, data_labels)
result_list = ['like', 'normal', 'do not like']
print("This food: ",
result_list[classifier_result])
if __name__ == '__main__':
is_like_this_food()input meat ratio: 0.5
input vegetables ratio: 0.4
input fruit ratio: 0.1
This food: like
现在我们回头再看一下,k-近邻算法有什么优缺点:
优点:精度比较高,算法逻辑简单,无需训练模型;
缺点:计算量随着训练集样本数量的增加而增加,占用空间也较大。
