End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers
3 The DETR model
对于检测中的直接集合预测,有两个因素是必不可少的。(1)一个集合预测损失,迫使预测和真实boxes之间的唯一匹配;(2)一个能预测(单次)一组对象并对其关系进行建模的架构。我们在图2中详细描述了我们的架构。
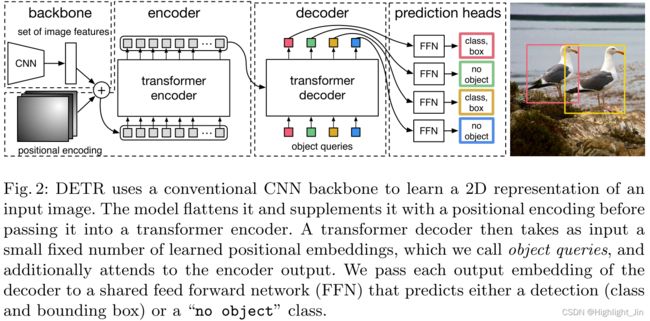
Fig.2: DETR使用一个传统的CNN骨架来学习输入图像的二维表示。该模型对其进行扁平化处理,并在将其传入变换器编码器之前用位置编码进行补充。然后,一个 transformer 解码器将少量固定的学习到的位置嵌入作为输入,我们称之为object queries,并额外关注编码器的输出。我们将解码器的每个输出嵌入传递给一个共享前馈网络(FFN),该网络预测一个检测(类别和边界框)或一个 "无对象 "类别。
3.1 Object detection set prediction loss
DETR推断出一个固定大小的N个预测集,只需通过一次解码器,其中N被设定为明显大于图像中的典型物体数量。训练的主要困难之一是对预测的物体(类别、位置、大小)与真实值进行评分。我们的损失在预测对象和真实值之间产生一个最佳的双点匹配,然后优化特定对象(边界框)的损失。
让我们用 y y y表示真实值的对象集,而 y ^ = { y i ^ } i = 1 N \hat{y} = \{\hat{y_i}\}^N_{i=1} y^={yi^}i=1N是N个预测的集合。假设 N N N大于图像中物体的数量,我们把 y y y也看作是一个用 ∅ ∅ ∅填充的 N N N大小的集合(无物体)。为了在这两个集合之间找到一个双侧匹配,我们寻找一个成本最低的 N N N个元素 σ ∈ S N σ∈SN σ∈SN的排列组合:
σ ^ = arg min σ ∈ Σ N ∑ i N L m a t c h ( y i , y ^ σ ( i ) ) \hat{\sigma} = \argmin_{\sigma\in\Sigma_N} \sum_{i}^{N} \mathcal{L}_{match}({y_i, \hat{y}_{\sigma(i)}}) σ^=σ∈ΣNargmini∑NLmatch(yi,y^σ(i))
其中,Lmatch(yi, ˆyσ(i))是真实值yi和索引为σ(i)的预测之间的一对匹配成本。按照先前的工作(如[43]),用匈牙利算法有效地计算了这个最佳分配。
匹配成本既考虑了预测的类别,也考虑了预测和真实值的相似度。真实值的每个元素i可以被看作是yi=(ci,bi),其中ci是目标类标签(可能是∅),bi∈[0,1]4是一个定义真实box中心坐标及其相对于图像大小的高度和宽度的向量。对于索引为σ(i)的预测,我们将ci类的概率定义为ˆpσ(i)(ci),将预测的盒子定义为ˆbσ(i)。通过这些符号,我们将Lmatch(yi, ˆyσ(i))定义为-1{ci6=∅}。ˆpσ(i)(ci) + 1{ci6=∅}Lbox(bi, ˆbσ(i))。这种寻找匹配的程序与现代检测器中用于匹配提议[37]或锚点[22]与地面真实对象的启发式分配规则的作用相同。主要区别在于,我们需要找到一对一的匹配,以实现无重复的直接集合预测。
第二步是计算损失函数,即在上一步中匹配的所有配对的匈牙利损失。我们对损失的定义与普通物体检测器的损失类似,即类预测的负对数可能性和后面定义的盒式损失的线性组合:
其中σ是在第一步(1)中计算出的最佳分配。在实践中,当ci=∅时,我们将对数概率项的权重降低了10倍,以考虑到类的不平衡性。这类似于Faster R-CNN训练程序如何通过下采样来平衡正/负建议[37]。请注意,一个对象和∅之间的匹配成本并不取决于预测,这意味着在这种情况下,成本是一个常数。在匹配成本中,我们使用概率ˆpˆσ(i)(ci)而不是对数概率。这使得类别预测项可以与Lbox(-, -)相称(如下所述),我们观察到了更好的经验性能。
Bounding box loss.匹配成本和匈牙利损失的第二部分是Lbox(-),对包围盒进行评分。与许多检测器不同的是,我们直接进行箱体预测,作为对一些初始猜测的∆,我们直接进行箱体预测。虽然这种方法简化了实施,但却带来了一个损失的相对比例问题。最常用的’1’损失对于小盒子和大盒子会有不同的尺度,即使它们的相对误差是相似的。为了缓解这个问题,我们使用了’1’损失和广义IoU损失[38]Liou(-, -)的线性组合,它是尺度不变的。总的来说,我们的boss损失是Lbox(bi, ˆbσ(i)),定义为……其中λiou, λL1∈R是超参数。这两个损失按批次内的对象数量进行归一化处理。
3.2 DETR architecture
DETR的整体架构出奇地简单,在图2中描述。它包含三个主要部分,我们在下面描述:一个CNN主干来提取一个紧凑的特征表示,一个编码器-解码器转化器,以及一个简单的前馈网络(FFN),进行最终的检测预测。
与许多现代检测器不同,DETR可以在任何深度学习框架中实现,该框架提供了一个通用的CNN骨干和一个仅有几百行的转化器架构实现。DETR的推理代码可以在PyTorch[32]中用不到50行实现。我们希望我们的方法的简单性能够吸引新的研究人员加入检测社区。
Backbone. 从初始图像ximg∈R3×H0×W0(有3个颜色通道2)开始,一个传统的CNN骨干生成一个较低分辨率的激活图f∈RC×H×W。我们使用的典型值是C = 2048和H, W = H032 , W032。
Transformer encoder. 首先,一个1x1的卷积将高级激活图f的通道维度从C减少到一个较小的维度d,创建一个新的特征图z0∈Rd×H×W。编码器期望有一个序列作为输入,因此我们将z0的空间维度折叠成一个维度,从而得到一个d×HW的特征图。每个编码器层都有一个标准的架构,由一个多头自我注意模块和一个前馈网络(FFN)组成。由于变换器结构是不变的,我们用固定的位置编码[31,3]来补充它,这些编码被添加到每个注意力层的输入中。我们将该架构的详细定义推迟到补充材料中,该架构遵循[47]中的描述。
Transformer decoder. 解码器遵循转化器的标准结构,使用多头自和编码器-解码器注意机制转化N个大小为d的嵌入物。与原始转化器的区别是,我们的模型在每个解码器层对N个对象进行并行解码,而Vaswani等人[47]使用的是自回归模型,每次预测输出序列的一个元素。我们请不熟悉这些概念的读者参考补充材料。由于解码器也是包络不变的,N个输入嵌入必须是不同的才能产生不同的结果。这些输入嵌入是学习到的位置编码,我们称之为对象查询,与编码器类似,我们将它们添加到每个注意力层的输入中。N个对象查询被解码器转化为输出嵌入。然后,它们被一个前馈网络(在下一小节中描述)独立解码为箱体坐标和类别标签,产生N个最终预测。在这些嵌入上使用自我和编码器-解码器注意力,该模型使用它们之间的成对关系对所有物体进行全面推理,同时能够使用整个图像作为背景。
Prediction feed-forward networks (FFNs). 最终的预测是由一个具有ReLU激活函数和隐藏维度d的3层感知器和一个线性投影层计算的。FFN预测归一化的中心坐标、盒子的高度和宽度与输入图像的关系,线性层使用softmax函数预测类别标签。由于我们预测的是一个固定大小的N个边界框,其中N通常比图像中感兴趣的物体的实际数量大得多,所以一个额外的特殊类标签∅被用来表示在一个槽内没有检测到物体。这个类别的作用类似于标准物体检测方法中的 "背景 "类别。
Auxiliary decoding losses. 我们发现在训练过程中,在解码器中使用辅助损失[1]很有帮助,特别是帮助模型输出每个类别的正确对象数量。我们在每个解码层之后添加预测的FFN和匈牙利的损失。所有的预测FFN共享它们的参数。我们使用一个额外的共享层规范来规范来自不同解码层的预测FFN的输入。