论文阅读:Visual Semantic Localization based on HD Map for AutonomousVehicles in Urban Scenarios
题目:Visual Semantic Localization based on HD Map for Autonomous
Vehicles in Urban Scenarios
中文:基于高清地图的城市场景自动驾驶车辆视觉语义定位
来源: ICRA 2021
链接:https://ieeexplore.ieee.org/document/9561459
个人觉得有用的和自己理解加粗和()内表示,尽量翻译的比较全,有一些官方话就没有翻译了,一些疑惑的地方欢迎大家探讨。
如果对整个领域比较了解 建议只用看一下 引言最后一段 + 第三章网络结构即可。可以打开右侧目录跳转~
这篇文章公式较多,有些地方自己也没太理解透彻,欢迎探讨!
0、摘要
高度准确和强大的定位能力对于城市场景中的自动驾驶汽车 (AVs) 至关重要。传统的基于视觉的方法会因照明,天气,观看和外观变化而丢失。在本文中,我们提出了一种新颖的视觉语义定位算法,该算法基于高清地图和语义特征的紧凑表示。语义特征广泛出现在城市道路上,并且对照明,天气,观看和外观变化具有鲁棒性。重复的结构,遗漏的检测和错误的检测使数据关联 (DA) 高度模糊。为此,提出了考虑局部结构一致性、全局模式一致性和时间一致性的鲁棒DA方法。此外,我们引入了滑动窗口因子图优化框架,以融合关联和里程计测量,而无需为地图特征提供高精度绝对高度信息。
我们在模拟和真实城市道路上评估了提出的定位方法。实验表明,该方法能够实现高度精确的定位,平均纵向误差为0.43m,平均横向误差为0.12m,平均偏航角误差为0.11。
1、引言 INTRODUCTION
AVs近年来受到了业界和学术界的广泛关注。高度精确的定位是AVs必不可少的技术,因为各种模块 (例如决策,计划和控制) 在很大程度上取决于定位。为了实现准确的定位,AVs配备了各种传感器,例如GNSS,相机,激光雷达,IMU,车轮编码器等。由于激光雷达的价格昂贵,低成本相机和IMU更适合商用级AVs的定位。
城市场景中存在各种复杂的路况,如城市峡谷、隧道、高架桥等,这给自动驾驶汽车带来了更大的挑战。为了在此场景中实现稳健的定位,出现了各种方法,例如基于 GNSS 的方法 [1]、[2]、基于视觉的方法 [3]、[4]、基于视觉惯性的方法 [5]-[8]、LiDAR-基于方法 [9]、[10]。基于 GNSS 的方法在开放场景中可以达到厘米级精度,但在遮挡和多路径条件下不够可靠。融合GNSS和IMU或里程计[11]-[15]的方法被提出来解决GNSS的问题,但由于里程计的漂移,它们在长期缺乏全球位置信息的场景中仍然失败。为了解决漂移问题,基于先验图的方法被广泛应用。最常用的地图是点云地图,可以通过ICP或NDT方法实现厘米级定位,但点云地图的存储对于商用级AV来说是一个很大的挑战。传统的视觉特征图也被尝试用于定位,但它们会因光照、天气、观察和外观变化而导致跟踪丢失。
为了解决这个问题,我们提取视觉语义特征并基于高清地图进行定位。与传统的视觉特征相比,语义特征广泛出现在城市道路上,对天气、光照、观看和外观变化具有长期稳定和鲁棒性。由于语义特征的奇异性、错误检测和漏检,数据关联 (DA) 是最大的挑战之一。因此,我们提出了一种具有一致 DA 的准确且稳健的视觉语义定位系统。本文的主要贡献总结如下:
- 一种基于视觉语义特征和轻量级高清地图的精确鲁棒定位算法,无需地图特征的高精度绝对高度信息。
- 一种基于局部结构一致性、全局模式一致性和时间一致性的鲁棒DA 方法来解决DA 的歧义。
- 因子图优化框架,它紧密耦合视觉语义测量和里程计测量以实现稳健的定位。
- 在模拟和真实城市道路上进行了大量实验,以验证DA 的有效性和定位的准确性。
2、相关工作RELATED WORK
2.1. 基于传统视觉特征的方法Methods based on traditional visual features
基于传统视觉特征的方法提取点、线、面等几何特征,通过描述符进行特征匹配。 Mul-Artal [3] 和 Sons [16] 分别用 ORB 和 BIRD 描述符构建特征图,然后通过特征匹配得到位姿。 ETH ASL LAB 在该领域做了广泛的工作 [17]-[21],包括多会话地图摘要和基于外观的在线地标选择。然而,这些方法仍然无法摆脱天气、光照、观看和外观变化的影响。
2.2. 基于道路语义特征的方法Methods based on semantic features on roads
基于道路语义特征的方法被广泛应用于AVs。语义特征包括道路标记,交通信号灯,交通标志,电线杆等。Schreiber [22] 和Poggenhans [23] 检测到道路标记和路缘,并通过将特征与地图匹配来定位AVs。Lu [24] 应用倒角匹配来构造道路标记的约束,并提出了一个非线性优化问题来估计6DoF姿势。此外,Jeong [25] 对道路标记进行分类以避免歧义,并通过子图匹配,环路闭合和位姿图优化实现了精确的定位。Wilbers [26] 和Spangenberg [27] 通过具有深度的极点实现了姿势估计。同时,Sefati [28] 融合了摄像头和激光雷达的道路标记和交通标志,以通过PF进行定位。此外,Wu [29] 通过从相机中提取的车道线和从占用网格中提取的斑点特征进行定位。马 [30] 通过概率直方图滤波融合了INS,GPS,车道线和交通标志的定位结果。除了道路标线和电线杆外,Kummerle [31] 还通过激光提取了建筑物垂直面的几何信息,以实现精确定位。
在本文中,我们仅使用单目相机进行定位。Jin [32] 和Xiao [444] 的工作与我们的工作相似,但是我们不要求绝对高度,而是要求相对于当前位置的路面的高度。这简化了地图构建的难度,大大降低了成本。
2.3 语义数据关联 Semantic data association
由于语义特征的奇异性,错误和遗漏检测,实现正确和健壮的关联极具挑战性。Spangenberg [27] 通过欧几里得距离和极点宽度将感知极点与地图相关联。同时,胡 [34] 和肖 [444] 应用RANSAC消除了不匹配。此外,Kummerle [31] 和Wilbers [26] 通过累积随时间的检测来构建子图,以解决DA的歧义。在目标跟踪领域,执行了匈牙利算法 [35] 和多假设跟踪 [36]。为了解决DA的奇异性,Bowman [37] 将概率数据关联 (DA) 引入语义SLAM系统。与这些方法相反,我们提出了一种基于局部结构一致性,全局模式一致性和时间一致性的鲁棒DA方法,以消除由奇异性引起的不匹配。
3、系统总览SYSTEM OVERVIEW
全局定位问题可以定义为: 给定一些列传感器测量 ![]() 和高精度地图
和高精度地图![]() ,来估计代表状态轨迹的位置序列
,来估计代表状态轨迹的位置序列![]() ,位姿
,位姿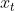 和特征位置
和特征位置 定义为
定义为![]() 和
和![]() ,定位问题可以表示为以下最大后验(MAP)推理问题:
,定位问题可以表示为以下最大后验(MAP)推理问题:

(通俗一点解释,一致地图和现在观测,如何确定我现在的位置。最大后验概率就是在当前条件下,现在位置最大的可能性。这里的DA,data association数据关联,个人认为就是定位,把当前的观测量和地图关联起来,不知道这样解释是不是对的)
MAP问题可以分为两个步骤,包括DA(data association)过程和基于DA的位姿估计过程。等式 (1) 意味着DA过程,在执行位姿估计之前,需要在测量和基于先验位姿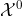 的地图之间建立DA
的地图之间建立DA ![]() 。因此,MAP推理问题可以重新定义为:
。因此,MAP推理问题可以重新定义为:
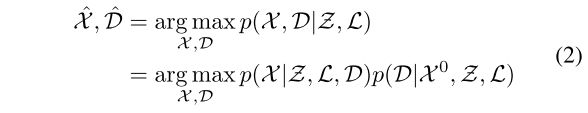
因此,定位框架分为四个组件,即传感器和地图、检测器、关联和优化,如图2所示。
传感器由单目摄像机、IMU、两个轮编码器和GNSS接收器组成。摄像机用于检测语义特征。IMU和车轮编码器形成里程计,以提供局部相对运动估计。GNSS接收器可以提供当前姿态的粗略估计,用于系统初始化。
检测器层从图像中检测道路标记,电线杆,交通信号灯和标志。
关联层将从图像中提取的语义特征与高清地图中的特征相关联。关联过程分为五个步骤。(1)围绕先前的姿势生成建议,并根据每个采样的位姿将地图特征投影到图像中。(2)实现了基于局部结构一致性的粗关联,以找到近似最佳采样位姿。(3)一个考虑匹配数,匹配相似性和局部结构相似性的最优关联方法,以实现最优全局共识匹配。(4)执行连续帧之间的特征跟踪。(5)进行时间平滑以获得时间一致的DA。(后边会详细介绍这五个步骤)
优化层中,基于DA和里程计的测量进行位姿图优化。

4、方法METHODOLOGY
4.1 语义特征和检测Semantic Features and Detection
语义特征的选择对定位性能至关重要。在本文中,我们根据参考文献[31]中提出的标准选择特征,因此选择道路标记、电线杆、交通灯和标志进行定位。它们易于检测、经常出现、具有紧凑表示的内存效率高,并且天气、照明、观察和外观不变。
我们采用了一种流行的卷积神经网络 (CNN) 方法YOLOV3 [38] 来检测特征。
检测到的标识![]() 包括检测到的类别
包括检测到的类别![]() ,表示检测置信度的分数
,表示检测置信度的分数![]() 和边界框
和边界框![]() 。标志的四个顶点存储在高清地图中,每个点的高度是相对于当前位置的路面的高度。
。标志的四个顶点存储在高清地图中,每个点的高度是相对于当前位置的路面的高度。
检测到的电线杆![]() 由检测到的类
由检测到的类![]() ,表示检测置信度的分数
,表示检测置信度的分数![]() 和代表两个顶点的
和代表两个顶点的![]() 组成。存储在具有两个顶点的HD map中。道路标记在图像平面和高清地图中表示为样本点。
组成。存储在具有两个顶点的HD map中。道路标记在图像平面和高清地图中表示为样本点。
4.2语义数据和高精度地图关联 Semantic Data Association with HD map
由于语义特征的奇异性、误检和漏检,DA成为语义定位系统最具挑战性的问题之一。在本文中,我们提出了一种基于局部结构、全局模式和时间一致性的鲁棒 DA 方法,以解决 DA 的模糊性并确保时空一致性。为了说明所提出的 DA 方法,算法 1 中提供了伪代码,建议先看完后边五个步骤再回头来看这个伪代码。

DA 过程的详细信息如下:
第 1 步:先验位姿生成建议、投影
通过对里程计获得的先验位姿进行采样来生成建议。对于每个采样的位姿![]() ,地图特征被投影到图像平面中:
,地图特征被投影到图像平面中:

![]() 是第i章地图特征。
是第i章地图特征。 和
和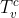 是相机的内参和外参。(就是世界坐标系投影到相机平面)
是相机的内参和外参。(就是世界坐标系投影到相机平面)
第 2 步:粗关联
基于局部结构一致性的粗关联来找到近似最优采样位姿,以消除由大的先验位姿误差引起的不匹配。局部结构一致性使感知特征的横向位置分布和相应的重投影特征保持一致。首先,感知和重投影特征根据横向位置按升序排序。其次,我们计算每个感知特征 和每个重投影特征
和每个重投影特征 之间的相似度:
之间的相似度:
![]()
其中,![]() 和
和![]() 可以通过感知结果的离线学习得到(应该是指的是lable,score,4.1中的类别和分数和通过训练得出)。对于标志,概率
可以通过感知结果的离线学习得到(应该是指的是lable,score,4.1中的类别和分数和通过训练得出)。对于标志,概率![]() 由位置和大小相似性组成:(b是边界框由位置+大小,pose+size)
由位置和大小相似性组成:(b是边界框由位置+大小,pose+size)
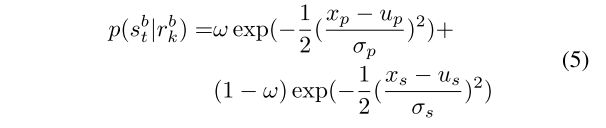
其中,ω 是用于加权位置相似性和大小相似性的学习的超参数。![]() 分别表示地图特征和感知特征的位置和大小。
分别表示地图特征和感知特征的位置和大小。![]() 可以从感知结果中离线学习。与标志相似,电线杆的似然
可以从感知结果中离线学习。与标志相似,电线杆的似然![]() 由位置,方向和重叠相似性组成。
由位置,方向和重叠相似性组成。
如果感知特征的最大相似度得分大于阈值并且保留了局部结构,则将它们视为匹配对。对于每个采样姿势,计算成本 C 以基于匹配数![]() 和匹配误差
和匹配误差![]() 对其进行近似评估:
对其进行近似评估:

其中,ω 是一个超参数。![]() 被定义为特征i和i'之间的横向距离,如图3所示。带有max C的提议被视为近似最优匹配采样姿势,并将在步骤3中使用。
被定义为特征i和i'之间的横向距离,如图3所示。带有max C的提议被视为近似最优匹配采样姿势,并将在步骤3中使用。

第 3 步:最优关联方法
基于近似最优匹配采样位姿,进行考虑匹配数、匹配相似度和局部结构相似度的最优关联方法,实现最优全局一致匹配。通过解决以下优化问题,它被表述为多阶图匹配问题:

其中,N 和 M 是感知和重投影特征的数量
![]() 是两个特征之间的边数。
是两个特征之间的边数。
ω1、ω2 和 ω3 是超参数。
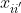 :当感知特征i 和 投影特征i' 匹配上了就有贡献。
:当感知特征i 和 投影特征i' 匹配上了就有贡献。
![]() :表示感知特征 i 和重投影特征 i' 之间的相似度,由等式(4)计算。
:表示感知特征 i 和重投影特征 i' 之间的相似度,由等式(4)计算。
![]() 表示边
表示边![]() 和边
和边![]() 之间的相似性
之间的相似性

![]() 和
和![]() 是特征i和j、i'和j'的图三中的横向距离
是特征i和j、i'和j'的图三中的横向距离
优化问题将通过通用随机重加权行走框架[39]来解决。
第4步 :特征跟踪Feature tracking
该过程在连续帧中的特征之间建立关联。由于感知到的特征是静态的并且保持局部结构,因此我们将过程公式化为类似于等式 (7) 的多阶图匹配问题。
第5步: 时间平滑 Temporal smoothing
该过程构建了连续帧中的感知特征与地图特征之间的最佳一致匹配。当前帧的匹配正确性可以通过滑动窗口中先前的匹配结果来验证。此外,如果当前帧出现不匹配,则可以根据之前的匹配和跟踪发现并纠正。 Temporal smoothing 通过对滑动窗口中每一帧的匹配 D1:T 和匹配置信度 ct,i 进行加权,得到地图特征 xl 对应的感知特征 si:

![]() 表示地图特征
表示地图特征 是否与感知特征
是否与感知特征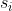 匹配。
匹配。
匹配置信度![]() 通过评估特征和局部结构相似性给出:
通过评估特征和局部结构相似性给出:

如果最佳感知特征的累积置信度远大于第二最佳感知特征的置信度,则最佳感知特征将被认为是地图特征 的匹配对。否则认为地图特征存在不确定匹配,可以给出与每个感知特征的匹配概率。该过程区分了确定匹配和不确定匹配,可以解决奇异性引起的不匹配问题。
4.3. 位姿图优化Pose Graph Optimization
式(2)的姿态估计过程可以定义为先验概率和似然的乘积:
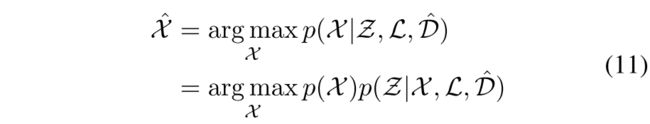
通过高斯分布假设,通过测距的相对运动估计获得先验分布![]() 。我们基于里程计测量
。我们基于里程计测量![]() 和匹配一对特征
和匹配一对特征![]() 来制定滑动窗口非线性最小二乘估计器,以估计最近的T位姿。与常用的滤波方法相比,优化方法可以处理异步和延迟测量,并在相同的计算资源下实现更高的精度 [40]。优化目标表示为:
来制定滑动窗口非线性最小二乘估计器,以估计最近的T位姿。与常用的滤波方法相比,优化方法可以处理异步和延迟测量,并在相同的计算资源下实现更高的精度 [40]。优化目标表示为:

其中,每个误差项连同对应的信息矩阵可以看作一个因子,每个状态变量可以看作一个节点,因此定位问题可以用因子图表示,如图4所示。误差项由里程计误差 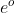 ,语义测量误差
,语义测量误差 ![]() 和地图误差
和地图误差 ![]() 。里程计误差定义为:
。里程计误差定义为:


语义测量误差因子![]() 表示为:
表示为:

[·]0 表示向量的第一个元素。测量误差仅采用横向误差,消除了高程误差的影响和地图地物对绝对高度准确的要求,如图 5所示。

地图误差因子![]() 表示为:
表示为:
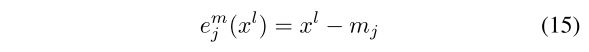
![]() 是第j个地图特征的位置。在本文中,我们采用了参考文献 [26] 中提出的地图特征的方差构造方法。在地图因子的各向同性假设下,根据假定的地图质量,地图因子的方差可以定义为:
是第j个地图特征的位置。在本文中,我们采用了参考文献 [26] 中提出的地图特征的方差构造方法。在地图因子的各向同性假设下,根据假定的地图质量,地图因子的方差可以定义为:

γ是逆卡方累积分布函数
c表示置信度
r表示半径
非线性优化问题可以直接用迭代算法求解。采用滑动窗口代替全批处理方法,在保证定位精度的同时提高计算效率。旧状态被截断并直接忽略。 Marginalization方法也可以处理old state,但是会累积线性化误差,使系统矩阵变得密集,造成死锁。边缘化方法基于过去的数据约束姿态,但使用地图特征作为先验足以约束车辆姿态。
5. 实验结果EXPERIMENTAL EVALUATION
5.1 仿真典型场景
我们首先评估感知和地图错误如何影响所提出算法的性能。选取典型的十字路口场景,道路两侧放置四根电线杆,车辆前方有两个红绿灯和两个交通标志。不同感知和地图误差下的位置和偏航角误差如图6所示。所有结果均为1000次试验的平均值,以消除随机性。结果表明,在 0.2m 地图误差和 5 像素感知误差下,所提出的方法获得了 0.23m 位置误差和 0.064° 偏航误差的高精度定位。

所提出的算法不需要地图特征的高精度绝对高度。我们将我们的方法与6dop位姿估计方法进行了比较,以揭示地图特征不同高度误差的影响。实验也在典型交叉口上实施。图7说明了结果,它表明我们的方法在位置和偏航角上都获得了明显较小的误差。因此,我们的横向误差测量模型有利于所提出系统的性能。

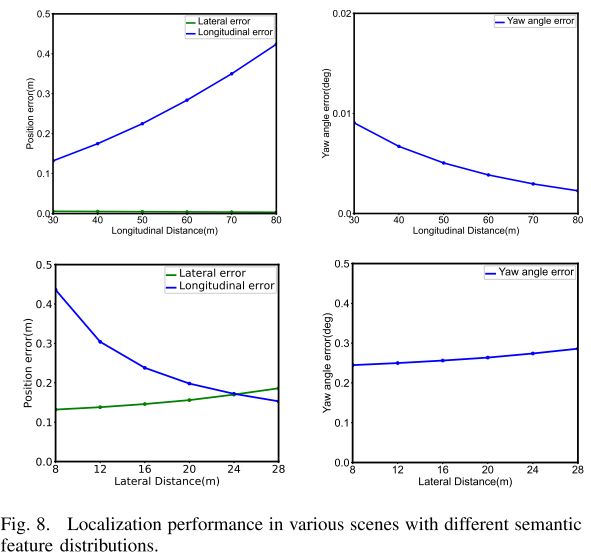
不同的特征分布也会影响定位性能。为了探索所提出算法的性能局限性,我们在具有不同特征分布的各种场景中对其进行了量化。我们将它们分为两种情况,包括车辆与特征之间的不同纵向距离,以及车辆坐标系中特征之间的不同横向距离。选取车辆两侧各有两根杆子,距离不同的典型场景。假设地图和感知特征分别具有 0.05m 和 2 像素的标准偏差。实验结果如图 8 所示。说明纵向距离越长,纵向定位越差,横向和偏航定位越好。然而,随着横向距离的增加,纵向精度变得更好,但横向和偏航定位变得更差。
5.2真实城市场景 Real Uran Road Scene
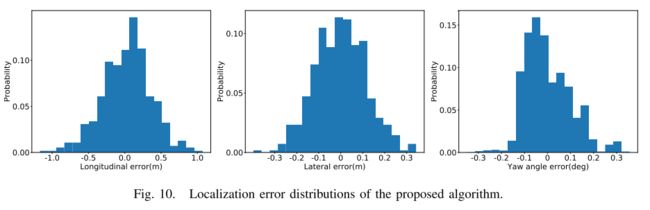
我们用我们的车辆在 30 公里的城市道路上评估所提出算法的性能,该道路具有城市峡谷、隧道和高架桥等各种场景。为了评估定位精度,将融合 LiDAR、RTK 和里程计的定位结果作为 groundtruth。与基于最近邻 (NN) 的 6DoF 位姿估计方法在各种场景中所提出的系统的定位性能如表 1 所示,它描述了所提出的系统在各种场景中实现了更高的精度,平均纵向误差为 0.43m ,平均横向误差 ela 为 0.12m,平均偏航角误差 ey 为 0.11°。图 9 给出了带有定位误差的轨迹,并在高架道路上与 GNSS 定位精度进行了比较。它表明我们的方法具有明显更低的误差,这证明了我们的方法在 GNSS 失败的复杂道路场景中的有效性。图 10 给出了横向、纵向和偏航误差分布。

还通过在具有错误和漏检的各种场景中的实验来评估所提出的 DA 方法的正确性。图 11 给出了两个场景的 DA 结果。左图显示了我们的方法在一般场景中的正确匹配。中间和右边的图像说明关联方法有效地处理了由错误检测引起的歧义,这主要得益于局部结构和时间一致性约束。我们还将高清地图的大小与特征地图和点云地图进行了比较。高清地图每公里只需要大约10KB,而特征图和压缩点云图分别需要53MB和3MB。

6. 结论CONCLUSIONS
在本文中,我们提出了一种新颖的语义定位算法,该算法利用从图像中提取的语义特征和高清地图中的特征。为了处理由重复结构、漏检和错误检测引起的 DA 模糊性,执行了一种考虑局部结构、全局模式和时间一致性的鲁棒 DA 方法。紧密耦合关联和里程计测量的滑动窗口因子图优化框架旨在实现准确和稳健的定位。所提出的系统得到了验证,结果表明所提出的方法达到了亚米级定位精度。将来,我们希望用更全面的理论扩展我们的框架,以实时评估本地化性能。我们还计划检测更多的语义特征,以提高所提出系统的鲁棒性。
(读完感觉这是一个偏向于定位的论文并不是偏向于语义,语义只浅浅带过,定位主要是通过语义地图特征匹配。做了大量工作在匹配上,也就是文中所说的DA,推荐一起看另外一篇文章,也是华为做的同样是ICRA2021,但不是诺亚实验室,是车bu那边可能更贴近实际应用一些。
论文阅读RoadMap: A Light-Weight Semantic Map for Visual Localizationtowards Autonomous Driving轻量语义自动驾驶地图_shiyueyueya的博客-CSDN博客)
整理不易,求点赞~
另外这篇论文的公式,确实超出了自己的水平,欢迎大家可以一起探讨~