TopFormer
文章目录
- TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
- 一、Token Pyramid Module
-
- 1.代码
- 2.实验
- 二、Vision Transformer as Scale-aware Semantics Extractor
-
- 1.代码
- 2.实验
- 三、Semantics Injection Module(SIM) and Segmentation Head
-
- 1.代码
- 2.实验
- 四、Architecture and Variants
TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
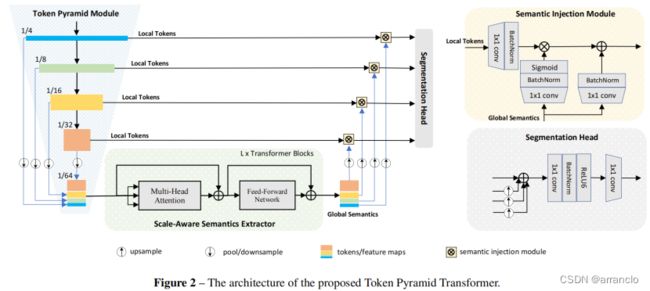
一、Token Pyramid Module
受MobileNets的启发,Token Pyramid Module由堆叠的MobileNet blocks组成。与MobileNets不同,Token Pyramid Module的目标并不是获得丰富的语义和较大的接受域,而是使用更少的blocks来构建token pyramid。
1.代码
代码如下:
TokenPyramidModule:InvertedResidual
输入依次穿过10层InvertedResidual,将其中四层的输出作为模块的输出,产生四种尺度的tokens,将被输入PyramidPoolAgg以及SIM模块。
class TokenPyramidModule(nn.Module):
def __init__(
self,
cfgs,
out_indices,
inp_channel=16,
activation=nn.ReLU,
norm_cfg=dict(type='BN', requires_grad=True),
width_mult=1.):
super().__init__()
self.out_indices = out_indices
self.stem = nn.Sequential(
Conv2d_BN(3, inp_channel, 3, 2, 1, norm_cfg=norm_cfg),
activation()
)
self.cfgs = cfgs
self.layers = []
for i, (k, t, c, s) in enumerate(cfgs): # 10层 InvertedResidual
output_channel = _make_divisible(c * width_mult, 8)
exp_size = t * inp_channel
exp_size = _make_divisible(exp_size * width_mult, 8)
layer_name = 'layer{}'.format(i + 1)
layer = InvertedResidual(inp_channel, output_channel, ks=k, stride=s, expand_ratio=t, norm_cfg=norm_cfg, activations=activation) # InvertedResidual
self.add_module(layer_name, layer)
inp_channel = output_channel
self.layers.append(layer_name)
def forward(self, x):
outs = []
x = self.stem(x)
for i, layer_name in enumerate(self.layers): # 10层 InvertedResidual
layer = getattr(self, layer_name)
x = layer(x) # 10层都经过
if i in self.out_indices: # [2, 4, 6, 9] 只输出四层的结果
outs.append(x)
return outs # 1, 32, 56, 56 1, 64, 28, 28 1, 128, 14, 14 1, 160, 7, 7
InvertedResidual:Conv2d_BN和ReLU
产生一种尺度的token
class InvertedResidual(nn.Module): # MobileNetV2
def __init__(
self,
inp: int,
oup: int,
ks: int,
stride: int,
expand_ratio: int,
activations = None,
norm_cfg=dict(type='BN', requires_grad=True)
) -> None:
super(InvertedResidual, self).__init__()
self.stride = stride
self.expand_ratio = expand_ratio
assert stride in [1, 2]
if activations is None:
activations = nn.ReLU
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1: # 第一层InvertedResidual的t为1 一共10层InvertedResidual
# pw
layers.append(Conv2d_BN(inp, hidden_dim, ks=1, norm_cfg=norm_cfg)) # Conv2d_BN
layers.append(activations()) # ReLU
layers.extend([
# dw
Conv2d_BN(hidden_dim, hidden_dim, ks=ks, stride=stride, pad=ks//2, groups=hidden_dim, norm_cfg=norm_cfg), # Conv2d_BN
activations(), # ReLU
# pw-linear
Conv2d_BN(hidden_dim, oup, ks=1, norm_cfg=norm_cfg) # Conv2d_BN
])
self.conv = nn.Sequential(*layers)
self.out_channels = oup
self._is_cn = stride > 1
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
Conv2d_BN:卷积和batch normalization合并,比Layer normalization运行得更快。
class Conv2d_BN(nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1,
norm_cfg=dict(type='BN', requires_grad=True)):
super().__init__()
self.inp_channel = a
self.out_channel = b
self.ks = ks
self.pad = pad
self.stride = stride
self.dilation = dilation
self.groups = groups
self.add_module('c', nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False)) # 卷积
bn = build_norm_layer(norm_cfg, b)[1]
nn.init.constant_(bn.weight, bn_weight_init)
nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn) # batch normalization
PyramidPoolAgg:avg_pool2d和cat
将不同尺度的tokens平均池化到目标大小,再将tokens沿着通道维度连接起来,产生新的tokens,将被输入Scale-aware Semantics Extractor模块。
class PyramidPoolAgg(nn.Module):
def __init__(self, stride):
super().__init__()
self.stride = stride
def forward(self, inputs): # 1, 32, 56, 56 1, 64, 28, 28 1, 128, 14, 14 1, 160, 7, 7
B, C, H, W = get_shape(inputs[-1]) # 1, 160, 7, 7
H = (H - 1) // self.stride + 1 # 4
W = (W - 1) // self.stride + 1 # 4
return torch.cat([nn.functional.adaptive_avg_pool2d(inp, (H, W)) for inp in inputs], dim=1) # 1, 384, 4, 4
2.实验
token pyramid的有效性以及tokens的规模选择

如表2所示,将来自不同尺度的堆叠tokens和最后一个token分别作为 Semantics Extractor的输入,并附加了一个1×1的卷积层来扩展后者与堆叠tokens一样的通道。实验结果证明了使用 token pyramid作为输入的有效性。

如表3所示,使用{ 1/4、1/8 、1/16、1/32 }的tokens可以在最复杂的计算下获得最佳性能。使用{ 1/16,1/32 }的令牌在最简单的计算下获得较差的性能。为了在精度和计算成本之间实现良好的权衡,在所有其他实验中使用{ 1/4、1/8 、1/16、1/32 }的tokens。
二、Vision Transformer as Scale-aware Semantics Extractor
可以获得全图像的感受域和尺度相关的语义(scale-aware semantics)
1.代码
代码如下:
BasicLayer:4层Block
输入依次穿过4层Block
class BasicLayer(nn.Module):
def __init__(self, block_num, embedding_dim, key_dim, num_heads,
mlp_ratio=4., attn_ratio=2., drop=0., attn_drop=0., drop_path=0.,
norm_cfg=dict(type='BN2d', requires_grad=True),
act_layer=None):
super().__init__()
self.block_num = block_num # 4层
self.transformer_blocks = nn.ModuleList()
for i in range(self.block_num):
self.transformer_blocks.append(Block( # vit的block
embedding_dim, key_dim=key_dim, num_heads=num_heads,
mlp_ratio=mlp_ratio, attn_ratio=attn_ratio,
drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_cfg=norm_cfg,
act_layer=act_layer))
def forward(self, x):
# token * N
for i in range(self.block_num):
x = self.transformer_blocks[i](x) # 4层block
return x
Block:Attention、Mlp、DropPath
一层vit
class Block(nn.Module):
def __init__(self, dim, key_dim, num_heads, mlp_ratio=4., attn_ratio=2., drop=0.,
drop_path=0., act_layer=nn.ReLU, norm_cfg=dict(type='BN2d', requires_grad=True)):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
self.attn = Attention(dim, key_dim=key_dim, num_heads=num_heads, attn_ratio=attn_ratio, activation=act_layer, norm_cfg=norm_cfg)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop, norm_cfg=norm_cfg)
def forward(self, x1):
x1 = x1 + self.drop_path(self.attn(x1)) # Attention+DropPath
x1 = x1 + self.drop_path(self.mlp(x1)) # MLP+DropPath
return x1
Attention(LeVit):LeVit、Conv2d_BN、ReLU
class Attention(torch.nn.Module):
def __init__(self, dim, key_dim, num_heads,
attn_ratio=4,
activation=None, # ReLU
norm_cfg=dict(type='BN', requires_grad=True),):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads # num_head key_dim
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
self.to_q = Conv2d_BN(dim, nh_kd, 1, norm_cfg=norm_cfg)
self.to_k = Conv2d_BN(dim, nh_kd, 1, norm_cfg=norm_cfg)
self.to_v = Conv2d_BN(dim, self.dh, 1, norm_cfg=norm_cfg)
self.proj = torch.nn.Sequential(activation(), Conv2d_BN(
self.dh, dim, bn_weight_init=0, norm_cfg=norm_cfg))
def forward(self, x): # x (B,N,C)
B, C, H, W = get_shape(x) # 1, 384, 4, 4
# reshape减少通道数将降低计算成本
qq = self.to_q(x).reshape(B, self.num_heads, self.key_dim, H * W).permute(0, 1, 3, 2) # 1, 128, 4, 4 => 1, 8, 16, 16
kk = self.to_k(x).reshape(B, self.num_heads, self.key_dim, H * W) # 1, 128, 4, 4 => 1, 8, 16, 16
vv = self.to_v(x).reshape(B, self.num_heads, self.d, H * W).permute(0, 1, 3, 2) # 1, 256, 4, 4 => 1, 8, 16, 32
attn = torch.matmul(qq, kk) # 1, 8, 16, 16
attn = attn.softmax(dim=-1) # dim = k # 1, 8, 16, 16
xx = torch.matmul(attn, vv) # 1, 8, 16, 32
xx = xx.permute(0, 1, 3, 2).reshape(B, self.dh, H, W) # 1, 256, 4, 4
xx = self.proj(xx) # ReLU、Conv2d_BN 1, 384, 4, 4
return xx
MLP:Conv2d_BN、Conv2d、ReLU、Dropout
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU, drop=0., norm_cfg=dict(type='BN', requires_grad=True)):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = Conv2d_BN(in_features, hidden_features, norm_cfg=norm_cfg)
self.dwconv = nn.Conv2d(hidden_features, hidden_features, 3, 1, 1, bias=True, groups=hidden_features)
self.act = act_layer()
self.fc2 = Conv2d_BN(hidden_features, out_features, norm_cfg=norm_cfg)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x) # Conv2d_BN
x = self.dwconv(x) # Conv2d
x = self.act(x) # ReLU
x = self.drop(x) # Dropout
x = self.fc2(x) # Conv2d_BN
x = self.drop(x) # Dropout
return x
DropPath:Conv2d_BN、Conv2d、ReLU、Dropout
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
# 针对x的第一维的数据 shape = x.shape[0], 1, 1, 1
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) # 生成随机小数
random_tensor.floor_() # binarize floor_()向下取整,random_tensor的数据有keep_prob的概率为1,drop_prob的概率为0
output = x.div(keep_prob) * random_tensor # div(),x的数据除以keep_prob
return output
2.实验
验证Scale-aware Semantics Extractor的有效性,实验表明SASE以更低的计算成本实现更好的性能
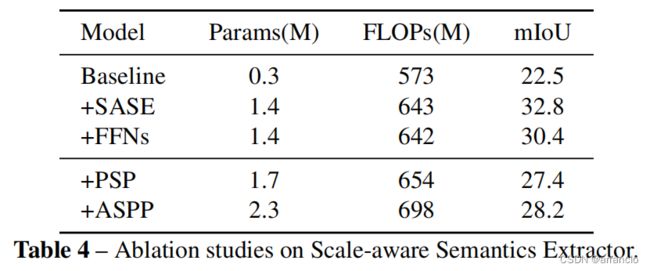
baseline: 不含SASE模块的Topformer
+SASE: 含SASE模块的Topformer
+FFNs:将SASE模块中的multi-head self-attention module替换为FFNs
+PSP:将SASE模块替换为PSP模块
+ASPP:将SASE模块替换为ASPP模块
Semantics Extractor的输入大小对精度和性能的影响,考虑到计算量和精度的权衡性,选择s64
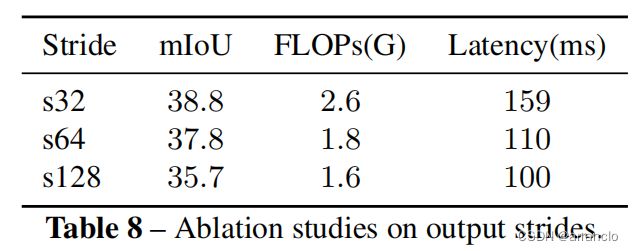
s32、s64、s128表示分辨率为输入大小的1/32×32、1/64×64、1/128×128
三、Semantics Injection Module(SIM) and Segmentation Head
在tokens{T1,…,TN }和scale-aware semantics之间存在着显著的语义差距,引入了Semantics Injection Module来融合这些tokens。
1.代码
代码如下:
InjectionMultiSum(SIM_BLOCK):卷积和h_sigmoid
SIM层由SIM_BLOCK组成,SIM总共输出4份数据。
class InjectionMultiSum(nn.Module):
def __init__(
self,
inp: int,
oup: int,
norm_cfg=dict(type='BN', requires_grad=True),
activations = None,
) -> None:
super(InjectionMultiSum, self).__init__()
self.norm_cfg = norm_cfg
self.local_embedding = ConvModule(inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
self.global_embedding = ConvModule(inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
self.global_act = ConvModule(inp, oup, kernel_size=1, norm_cfg=self.norm_cfg, act_cfg=None)
self.act = h_sigmoid()
def forward(self, x_l, x_g):
'''
x_g: global features(Scale-aware Semantics Extractor) 1, 32, 56, 56(将LeVit的输出split成四个tensor 1, 64, 28, 28 1, 128, 14, 14 1, 160, 7, 7)
x_l: local features(Token Pyramid Module) 1, 32, 4, 4 (1, 64, 4, 4 128, 4, 4 1, 160, 4, 4)
'''
B, C, H, W = x_l.shape
local_feat = self.local_embedding(x_l) # local_embedding卷积 1, 256, 56, 56
global_act = self.global_act(x_g) # global_act卷积 1, 256, 4, 4
sig_act = F.interpolate(self.act(global_act), size=(H, W), mode='bilinear', align_corners=False) # h_sigmoid、上采样 1, 256, 56, 56
global_feat = self.global_embedding(x_g) # global_embedding卷积 1, 256, 4, 4
global_feat = F.interpolate(global_feat, size=(H, W), mode='bilinear', align_corners=False) # 上采样 1, 256, 56, 56
out = local_feat * sig_act + global_feat # local tokens和semantics相乘,再加上semantics 1, 256, 56, 56
return out
h_sigmoid:ReLU6
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
2.实验
验证SIM的有效性,实验表明同时添加SigmoidAttn和SemInfo可以通过一点额外的计算带来很大的改进。

SigmoidAttn: local tokens 和 the semantics相乘
SemInfo: local tokens 和 the semantics相加
SIM中的通道数对mIoU和性能的影响

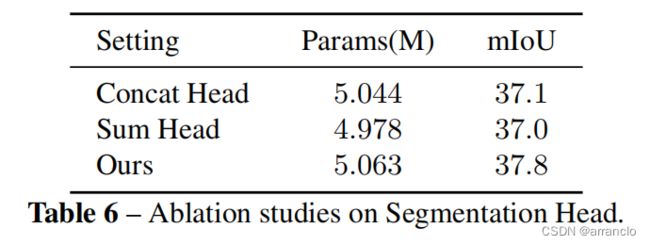
Segmentation Head的影响

四、Architecture and Variants
base, small和tiny 模型在每个multi-head self-attention module中分别有8、6和4个heads,以M = 256、M = 192和M = 128作为目标通道数。