tensorflow & keras 学习(官方文档)
tensorflow learning
0 语句积累篇
# 查看是否启用eager execution,若启用则返回True
tf.executing_eagerly()
# 矩阵相乘
m = tf.matmul(x, x)
# 矩阵对应位置元素相乘
c = np.multiply(a, b)
# 创建常量
a = tf.constant([[1, 2],
[3, 4]])
# 定义变量并初始化为[1.0]
w = tf.Variable([[1.0]])
# 在线抓取mnist数据集
(mnist_images, mnist_labels), _ = tf.keras.datasets.mnist.load_data()
# 下载数据集。将 with_info 设置为 True 会包含整个数据集的元数据,其中这些数据集将保存在 info 中。
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
# 对数据集进行切片分组
dataset = tf.data.Dataset.from_tensor_slices()
dataset = tf.data.Dataset.from_tensor_slices(
(tf.cast(mnist_images[...,tf.newaxis]/255, tf.float32),
tf.cast(mnist_labels,tf.int64)))
# tf.cast() 的作用是将mnist_images原来的数据类型(uint8)转化为指定类型。
# mnist_images[…,tf.newaxis] 是指在mnist_images(维度为(60000, 28, 28))后面再加一个维度,即变成(60000, 28, 28, 1)。省略号表示的是很多个冒号,也就是说[…,tf.newaxis]即为[:, :, :, tf.newaxis]。
dataset = dataset.shuffle(1000).batch(32)
# shuffle:打乱
# batch:分批次,每批32个数据
1 tensorflow基础知识
1.0 tf2.0介绍
底层框架:

training+deployment:训练和部署两部分,训练完之后保存模型,可以部署在服务器端、网页端、移动端等等。
准备数据–构建模型–运行调试–(分布式)训练–保存模型–(跨平台)部署
云端配置的优势:
- 每台机器都是统一规格的,比较好管理
- 没有机器损耗问题
- GPU等硬件设施配置问题不用考虑
1.1 Eager Execution
- TensorFlow 的 Eager Execution 是一种命令式编程环境,可立即评估运算,无需构建计算图:运算会返回具体的值,而非构建供稍后运行的计算图。
- 直观的界面
- 使用 Python 而非计算图控制流
注:在 Tensorflow 2.0 中,默认启用 Eager Execution。
1.2 性能测试工具 cProfile
- 会统计每个函数的总运行时间(包括子函数)、除自函数外的运行时间、运行次数、每次平均运行时间。
- 默认情况下,只统计主线程的运行时间。
- 如果想要统计多线程/进程的运行时间,需要对每个线程/进程分别执行cProfile的API。
参考学习文档
1.3 自动求导机制
tf.GradientTape() 是一个自动求导的记录器。只要进入了 with tf.GradientTape() as tape 的上下文环境,则在该环境中计算步骤都会被自动记录。
with tf.GradientTape() as tape:
loss = w * w
# 利用记录好的tape,计算y=x^2的导数
grad = tape.gradient(loss, w)
1.4 构建神经网络模型
mnist_model = tf.keras.Sequential([ # Sequential表示是顺序模型
tf.keras.layers.Conv2D(16,[3,3], activation='relu', # 二维卷积层,激活函数是relu。16个卷积核,每个卷积核的尺寸为3*3
input_shape=(None, None, 1)), # 输入的形状为一层,但不限大小
tf.keras.layers.Conv2D(16,[3,3], activation='relu'),
tf.keras.layers.GlobalAveragePooling2D(), # 全局按照平均规则池化层
tf.keras.layers.Dense(10) # 全连接层,10个神经元
])
1.5 检查点checkpoint
# 完整代码
x = tf.Variable(10.)
checkpoint = tf.train.Checkpoint(x=x)
x.assign(2.) # Assign a new value to the variables and save.
checkpoint_path = './ckpt/'
checkpoint.save('./ckpt/')
x.assign(11.) # Change the variable after saving.
# Restore values from the checkpoint
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_path))
print(x) # => 2.0
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,[3,3], activation='relu'),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(10)
])
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
checkpoint_dir = 'path/to/model_dir'
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
root = tf.train.Checkpoint(optimizer=optimizer,
model=model)
root.save(checkpoint_prefix)
root.restore(tf.train.latest_checkpoint(checkpoint_dir))
1.6 张量
就像 Python 数值和字符串一样,所有张量都是不可变的:永远无法更新张量的内容,只能创建新的张量。
通过使用 np.array 或 tensor.numpy 方法,您可以将张量转换为 NumPy 数组

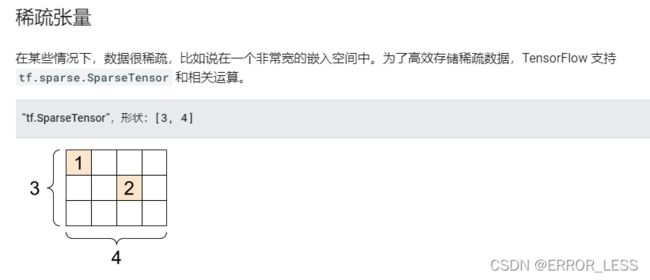
# 实现代码
# Sparse tensors store values by index in a memory-efficient manner
sparse_tensor = tf.sparse.SparseTensor(indices=[[0, 0], [1, 2]],
values=[1, 2],
dense_shape=[3, 4])
print(sparse_tensor, "\n")
# We can convert sparse tensors to dense
print(tf.sparse.to_dense(sparse_tensor))
1.7 Graph Excutation
- 张量的计算被执行为一个tensorflow图
- 无须python解释器就可以执行
- 在快速运行、并行计算、多机执行方面很有优势(可能会对我有用)
tf.function可以直接转换一般的python函数为tf函数
eager vs graph:

1.8 模块、层和模型
模块:
- 函数
- 变量
层:
大多数模型都由层组成。层是具有已知数学结构的函数,可以重复使用并且具有可训练的变量
现在构建层一般都使用keras这个高阶API
1.9 tensor 切片
# 分片操作
tf.slice
# 取特定元素组成新的张量
tf.gather
1.10 完整项目流程
查看链接并尝试运行
- 环境导入
- 数据集处理
- 下载数据集
- 检查数据
head -n5 {train_dataset_fp}查询前5个条目 - 分析数据集
- 创建可供训练的数据集
- 使用 Keras 创建模型
keras是创建层和模型的首选方式 - 训练模型
- 定义损失函数
- 定义梯度函数计算梯度
- 创建优化器optimizer
- 训练循环
- 可视化损失函数和准确率的走向
- 建立测试集评估模型
- 使用经过训练的模型进行预测
2 tensorflow进阶
2.1 TensorBoard:可视化工具包
TensorBoard 提供机器学习实验所需的可视化功能和工具:
- 跟踪和可视化损失及准确率等指标
- 可视化模型图(操作和层)
- 查看权重、偏差或其他张量随时间变化的直方图
- 将嵌入投射到较低的维度空间
- 显示图片、文字和音频数据
- 剖析 TensorFlow 程序

简要概述所显示的仪表板(顶部导航栏中的选项卡):
- Scalars 显示损失和指标在每个时期如何变化。 您还可以使用它来跟踪训练速度,学习率和其他标量值。
- Graphs 可帮助您可视化模型。在这种情况下,将显示层的Keras图,这可以帮助您确保正确构建。
- Distributions 和 Histograms显示张量随时间的分布。 这对于可视化权重和偏差并验证它们是否以预期的方式变化很有用。
- 当您记录其他类型的数据时,会自动启用其他TensorBoard 插件。 例如,使用 Keras TensorBoard 回调还可以记录图像和嵌入。
您可以通过单击右上角的“inactive”下拉列表来查看 TensorBoard 中还有哪些其他插件。
2.2 TensorFlow Hub:机器学习模型代码库
TensorFlow Hub 是一个包含经过训练的机器学习模型的代码库,这些模型稍作调整便可部署到任何设备上。只需几行代码即可重复使用经过训练的模型,例如 BERT 和 Faster R-CNN。
3 基于keras分布式训练–知识篇
3.0 深入理解tensorflow分布式训练
官方视频
All-reduce 和 Parameter servers 是对应的融合方法。
tf.distribute.experimental.ParameterServerStrategy策略支持异步训练
3.1 常规分布式训练策略
tf.distribute.Strategy 是一个可在多个 GPU、多台机器或 TPU 上进行分布式训练的 TensorFlow API。使用此 API,您只需改动较少代码就能分布现有模型和训练代码。
- 可用于keras等高级API
- 可用来分布式自定义训练循环
- 可以立即执行程序,但推荐使用
tf.function在计算图中执行

3.11 MirroredStrategy
tf.distribute.MirroredStrategy 支持在一台机器的多个 GPU(单机多卡) 上进行同步分布式训练。该策略会为每个 GPU 设备创建一个副本。模型中的每个变量都会在所有副本之间进行镜像。这些变量将共同形成一个名为 MirroredVariable 的单个概念变量。这些变量会通过应用相同的更新彼此保持同步。
数据并行:Batch数据切为N份分给各个GPU进行处理,梯度聚合之后更新给各个GPU上的参数。
高效的全归约算法(all-reduce)用于在设备之间传递变量更新。全归约算法通过加总各个设备上的张量使其聚合,并使其在每个设备上可用。这是一种非常高效的融合算法,可以显著减少同步开销。根据设备之间可用的通信类型,可以使用的全归约算法和实现方法有很多。默认使用 NVIDIA NCCL 作为全归约实现。
以下是创建 MirroredStrategy 最简单的方法:
mirrored_strategy = tf.distribute.MirroredStrategy()
3.12 TPUStrategy
无需用到,不做深入学习
3.13 MultiWorkerMirroredStrategy
tf.distribute.experimental.MultiWorkerMirroredStrategy 与 MirroredStrategy 非常相似。它实现了跨多个工作进程的同步分布式训练,而每个工作进程可能有多个 GPU。与MirroredStrategy 类似,它也会跨所有工作进程在每个设备的模型中创建所有变量的副本。
以下是创建 MultiWorkerMirroredStrategy 最简单的方法:
multiworker_strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
3.14 CentralStorageStrategy
tf.distribute.experimental.CentralStorageStrategy 也执行同步训练,但参数不会在每个GPU上,只存储在一个设备上。变量不会被镜像,而是放在 CPU 上,且运算会复制到所有本地 GPU 。如果只有一个 GPU,则所有变量和运算都将被放在该 GPU 上。
3.15 ParameterServerStrategy
tf.distribute.experimental.ParameterServerStrategy 支持在多台机器上进行参数服务器异步训练。在此设置中,有些机器会被指定为工作进程,有些会被指定为参数服务器。模型的每个变量都会被放在参数服务器上。计算会被复制到所有工作进程的所有 GPU 中。
机器分为Parameter Server和Worker两种:
- Parameter Server负责整合梯度,更新参数
- Worker负责计算,训练网络
伪代码流程:计算–推送–更新–拉取(如此循环迭代)
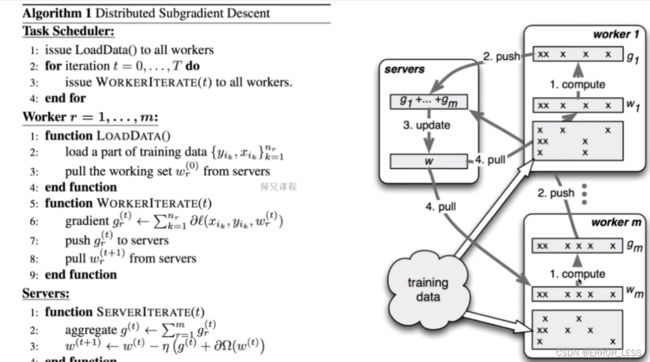
就代码而言,该策略看起来与其他策略类似:
ps_strategy = tf.distribute.experimental.ParameterServerStrategy()
3.16 小结
上述分布式策略总体可分为同步和异步两种。
二者的优劣:
- 多机多卡应用场景下,异步常常可以避免短板效应。因为多机经常型号不同,运行能力也会有所差异,同步的话就会造成短板效应,浪费资源和内存
- 单机多卡应用场景下,同步可以避免过多的通信,一定程度上提高效率
- 异步的计算会增加模型的泛化能力,因为异步训练并不是严格正确的,所以模型对错误的容忍力也更强。
3.2 在keras中使用分布式策略
我们已将 tf.distribute.Strategy 集成到 tf.keras(TensorFlow 对 Keras API 规范的实现)。tf.keras 是用于构建和训练模型的高级 API。将该策略集成到 tf.keras 后端以后,您可以使用 model.fit 在 Keras 训练框架中无缝进行分布式训练。
您需要对代码进行以下更改:
创建一个合适的 tf.distribute.Strategy 实例。
将 Keras 模型、优化器和指标的创建转移到 strategy.scope 中。
我们支持所有类型的 Keras 模型:序贯模型、函数式模型和子类化模型。
下面是一段代码,执行该代码会创建一个非常简单的带有一个密集层的 Keras 模型:
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])
model.compile(loss='mse', optimizer='sgd')
3.3 在自定义训练循环中使用分布式策略
主要适用场景:
如果您需要更多相对于使用 Estimator 或 Keras 时的灵活性和对训练循环的控制权,您可以编写自定义训练循环。例如,在使用 GAN 时,您可能会希望每轮使用不同数量的生成器或判别器步骤。同样,高级框架也不太适合强化学习训练。
目前暂不深入学习,因为还用不到。
4 基于keras分布式训练–实战篇
为什么需要分布式?
- 数据量太大
- 模型太复杂
4.0 分布式训练的GPU设置
- 单机训练默认只使用一个GPU,并且使用策略是不管需要多少计算资源默认使用全部GPU并将内存全部占满,使得另外的进程就无法使用GPU了
- 避免上述情况:
1. 内存自增长:根据需要占用资源
2. 虚拟设备机制:实际上只有一个GPU,手动切分成多个虚拟上的逻辑GPU - 多GPU使用
1. 虚拟GPU & 实际GPU
2. 手工设置 & 分布式机制
API列表:
- tf.debugging.set_log_device_placement :手动指定设备布置任务
- tf.config.set_soft_device_placement :自动指定设备布置任务
- tf.config.experimental.set_visible_devices :设置可见设备,例如机器上有4个GPU,但设置只对一个GPU可见,则该进程无法访问其他设备
- tf.config.experimental.list_physical_devices :获取所有物理设备(整块)
- tf.config.experimental.VirtualDeviceConfiguration :建立逻辑分区
- tf.config.experimental.list_logical_devices :获取所有逻辑设备(分块)
- tf.config.experimental.set_memory_growth :设置内存自增长,需在程序开始的时候就被设置
4.1 使用keras进行分布式训练(单机多卡)
官方文档
4.10 代码解释
# 禁用进度条
tfds.disable_progress_bar()
4.11 数据集相关
下载数据集可以有多种方式。
数据集一般都需要:
- 标准化到0-1范围
- 按BUFFER_SIZE打乱
- 按BATCH_SIZE分批次
4.12 checkpoint
实现检查点需要定义回调
有三种回调:
TensorBoard: 此回调(callbacks)为 TensorBoard 写入日志,允许您可视化图形。
Model Checkpoint: 此回调(callbacks)在每个 epoch 后保存模型。
Learning Rate Scheduler: 使用此回调(callbacks),您可以安排学习率在每个 epoch/batch 之后更改。
调用tensorboard:
# 看到之前日志是保存在'./logs'
tf.keras.callbacks.TensorBoard(log_dir='./logs')
# Load the TensorBoard notebook extension
%load_ext tensorboard
%tensorboard --logdir ./logs

4.13 导出到SavedModel
将图形和变量导出为与平台无关的 SavedModel 格式。 保存模型后,可以在有或没有 scope 的情况下加载模型。
类似此种方法加载模型:
replicated_model = tf.keras.models.load_model(path)
4.2 自定义分布式训练(单机多卡)
官方文档
# 分布式训练时出现的错误,说是数据集不可分
2021-08-13 21:23:57.794731: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:695] AUTO sharding policy will apply DATA sharding policy as it failed to apply FILE sharding policy because of the following reason: Found an unshardable source dataset: name: "TensorSliceDataset/_2"
op: "TensorSliceDataset"
input: "Placeholder/_0"
input: "Placeholder/_1"
attr {
key: "Toutput_types"
value {
list {
type: DT_FLOAT
type: DT_UINT8
}
}
}
attr {
key: "output_shapes"
value {
list {
shape {
dim {
size: 28
}
dim {
size: 28
}
dim {
size: 1
}
}
shape {
}
}
}
}
但在google drive中运行成功,是为什么呢?
4.3 使用keras进行分布式训练(多机多卡)
官方文档
为什么4台机器同时工作,效率只提高了1.5倍?
NCCL All-reduce 算法是用来聚合梯度的。
4.4 使用keras进行自定义分布式训练(多机多卡)
官方文档
在导入tensorflow包之前,需要做一些预处理:
# 为了防止多个工作节点都尝试用一个GPU而导致的错误,使所有GPU无法工作
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
# 重置TF_CONFIG环境变量
os.environ.pop('TF_CONFIG', None)
# 确保当前目录在python的路径下,目的是使这个笔记本之后能够导入之前用%%writefile写的文件
if '.' not in sys.path:
sys.path.insert(0, '.')