【实战案例】血红细胞目标检测项目
来源:投稿 作者:LSC
编辑:学姐
背景
本项目的数据是血液细胞的图像和一一对应的xml格式的数据,用于目标检测。分为train和test两个文件夹,文件夹中的数据如下:
train共801张图像和801个xml文件,图像大小都是4164163,test共36张图像和36个xml文件。
图像如下:
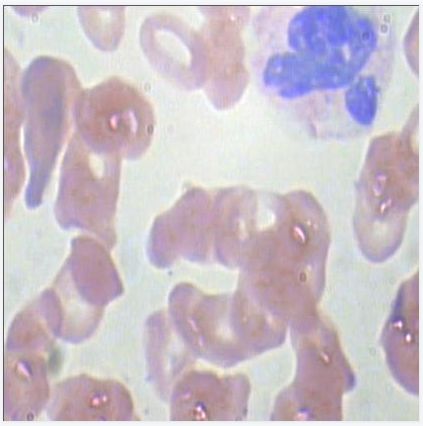
xml文件如下:
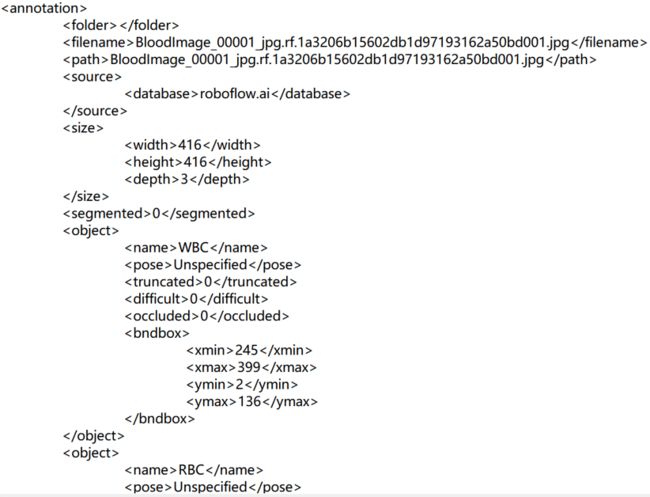
方法
采用faster-rcnn、ssd、retinanet模型分别对数据进行训练和推理,展示训练效果。具体步骤如下:
(1)数据输入和xml文件处理
(2)建立xml文件解析函数,对xml文件进行解析,对里面的重要信息进行读取,主要是图像框的类别和位置。
(3)自定义Dataset数据集方便读取数据
(4)定义Dataloader,加载数据集
(5)绘制边界框BoundingBox
(6)建立Faster-RCNN模型
(7)计算AnchorBox的mIou
(8)Faster-RCNN模型训练
(9)模型性能检测
(10)计算性能评价指标mAP
(11)尝试建立SSD模型和retinaNet模型进行训练
实验
这部分主要是代码的具体展示。
# 导入包
import os
import math
import glob
import shutil
import time
from tqdm import tqdm # ***
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import numpy as np
import pandas as pd
from PIL import Image
import matplotlib.pyplot as plt
import random
import cv2
import xml.etree.ElementTree as ET
train_path = path + 'train/'
train_xml_file = glob.glob(train_path + '*.xml')
train_xml_file
train_img_file = glob.glob(train_path + '*.jpg')
train_img_file
train_img_list = []
train_xml_list = []
for i in train_xml_file:
img = i[:-3]+'jpg'
if img in train_img_file:
train_img_list.append(img)
train_xml_list.append(i)
test_path='test/'
test_xml_list=glob.glob(test_path+'*.xml')
test_img_list=glob.glob(test_path+'*.jpg')
an_file = open(train_xml_list[0], encoding = 'utf-8')
tree = ET.parse(an_file) # 构建一颗ET树
root = tree.getroot() # 获取根节点,然后用根节点去获取需要的数据
for object in root.findall('object'):
cell = object.find('name').text
xmin = object.find('bndbox').find('xmin').text
xmax = object.find('bndbox').find('xmax').text
ymin = object.find('bndbox').find('ymin').text
ymax = object.find('bndbox').find('ymax').text
print(cell, xmin)
运行结果截图:

# xml文件解析函数
class_idx = {'WBC': 0, 'RBC': 1, 'Platelets': 2}
def get_labelFromxml(xml_file):
an_file = open(xml_file, encoding = 'utf-8')
tree = ET.parse(an_file)
root = tree.getroot()
labels = []
boxs = []
for object in root.findall('object'):
cell = object.find('name').text
cell_id = class_idx[cell]
xmin = object.find('bndbox').find('xmin').text
xmax = object.find('bndbox').find('xmax').text
ymin = object.find('bndbox').find('ymin').text
ymax = object.find('bndbox').find('ymax').text
if int(xmin) == 0 or int(xmin) > 416 or int(xmax) > 416:
pass
elif int(xmin) == 0 or int(xmax) == 0 or int(ymin) == 0 or int(ymax) == 0:
pass
elif int(xmin) == int(xmax) or int(ymin) == int(ymax):
pass
else:
labels.append(cell_id)
boxs.append([int(xmin), int(ymin), int(xmax), int(ymax)]) # x1, y1, x2, y2
return labels, boxs
labels, boxs = get_labelFromxml(train_xml_list[0])
boxs
运行结果截图:

transformer = transforms.Compose([
transforms.ToTensor()
])
class cell_dataset(Dataset):
def __init__(self, img_paths, xml_paths, transformer):
self.img_paths = img_paths
self.xml_paths = xml_paths
self.transformer = transformer
def __len__(self):
return len(self.img_paths)
def __getitem__(self, item):
img_path = self.img_paths[item]
# print(img_path)
img = Image.open(img_path)
img = self.transformer(img)
# print(img)
xml_path = self.xml_paths[item]
labels, boxs = get_labelFromxml(xml_path)
# print(labels)
labels = torch.as_tensor(labels, dtype = torch.int64)
# print(labels)
boxs = torch.as_tensor(boxs, dtype = torch.float32)
# print(boxs.shape)
target = {} # 把标签和边框打包
target['boxes'] = boxs
target['labels'] = labels
return img, target
train_data = cell_dataset(train_img_list, train_xml_list, transformer)
test_data=cell_dataset(test_img_list,test_xml_list,transformer)
def detection_collate(x): # 打包函数,用在dataloader里面,减少GPU的内存消耗
return list(tuple(zip(*x)))
train_dl = DataLoader(train_data, batch_size = 2, shuffle = True, collate_fn = detection_collate)
test_dl=DataLoader(test_data, batch_size=2, shuffle=True, collate_fn=detection_collate)
img, target = next(iter(train_dl))
target
运行结果截图:

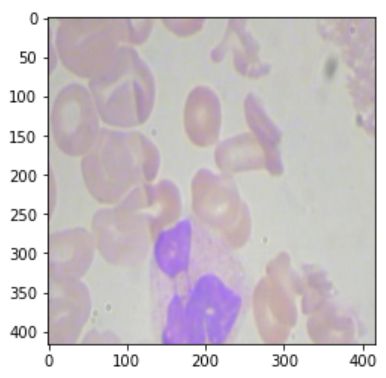
plt.imshow(img[0].permute(1, 2, 0))
运行结果截图:
img, target = next(iter(train_dl))
names = {0: 'WBC', 1: 'RBC', 2: 'Platelets'}
src_img = img[0].permute(1, 2, 0).numpy()
src_img = (src_img * 255).astype(np.uint8)
src_img = src_img.copy()
boxs = target[0]['boxes'].numpy()
labels = target[0]['labels'].numpy()
for idx in range(boxs.shape[0]):
x1, y1, x2, y2 = int(boxs[idx][0]), int(boxs[idx][1]), int(boxs[idx][2]), int(boxs[idx][3])
name = names[labels[idx]]
cv2.rectangle(src_img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(src_img, text = name, org = (x1, y1+10), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale = 0.5, thickness = 1,
lineType = cv2.LINE_AA, color = (0, 0, 255))
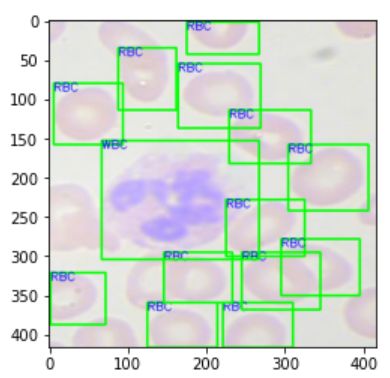
plt.imshow(src_img)
运行结果截图:
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained = False, progress = True, num_classes = 4)
img, target = next(iter(train_dl))
target = list(target)
model.train()
loss_dict = model(img, target)
loss_dict
运行结果截图:

losses = sum(loss for loss in loss_dict.values())
losses
运行结果截图:
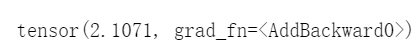
# mIOu计算示例
ground_truth = torch.as_tensor([[225, 15, 450, 200],
[30, 50, 180, 500]])
pred = torch.as_tensor([[205, 50, 400, 250],
[30, 50, 180, 540],
[30, 50, 180, 490]])
iou = torchvision.ops.box_iou(ground_truth, pred)
Iou
运行结果截图:

torch.max(iou, dim = 1)
np.mean(torch.max(iou, dim = 1)[0].numpy())
# 计算mIOU****
for i in range(len(pred)):
pic_pred = pred[i]['boxes']
label_boxes = target[i]['boxes']
iou = torchvision.ops.box_iou(pic_pred, label_boxes)
iou_mean = np.mean(torch.max(iou, dim = 1)[0].detach().numpy())
print(iou_mean)
运行结果截图:
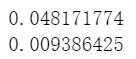
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001)
def train(epochs, model, optimizer, train_dl, test_dl):
model=model.to('cuda') #****
for epoch in range(epochs):
epoch_loss = []
epoch_iou = []
for images, targets in tqdm(train_dl):
model.train()
img_input=[]
for im in images:
im=im.to('cuda')
img_input.append(im)
lable_input=[]
for lb in targets:
lb_dic={}
for k,v in lb.items():
v=v.to('cuda')
lb_dic[k]=v
lable_input.append(lb_dic)
loss_dict = model(img_input, lable_input)
losses = sum(loss for loss in loss_dict.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
with torch.no_grad():
model.eval()
epoch_loss.append(losses.cpu().numpy())
try:
pred = model(images)
for i in range(len(pred)):
pic_boxes = pred[i]['boxes']
label_boxes = target[i]['boxes']
iou = torchvision.ops.box_iou(label_boxes, pic_boxes)
iou_total = np.mean(torch.max(iou, dim = 1)[0].cpu().numpy())
epoch_iou.append(iou_total)
except:
continue
test_epoch_loss = []
test_epoch_iou = []
for images, targets in tqdm(test_dl):
model.train() # ****** 这里用train模式,要注意
img_input=[]
for im in images:
im=im.to('cuda')
img_input.append(im)
lable_input=[]
for lb in targets:
lb_dic={}
for k,v in lb.items():
v=v.to('cuda')
lb_dic[k]=v
lable_input.append(lb_dic)
loss_dict = model(img_input, lable_input)
losses = sum(loss for loss in loss_dict.values())
with torch.no_grad():
model.eval()
test_epoch_loss.append(losses.cpu().numpy())
try:
pred = model(images)
for i in range(len(pred)):
pic_boxes = pred[i]['boxes']
label_boxes = target[i]['boxes']
iou = torchvision.ops.box_iou(label_boxes, pic_boxes)
iou_total = np.mean(torch.max(iou, dim = 1)[0].cpu().numpy())
test_epoch_iou.append(iou_total)
except:
continue
mIou=np.mean(epoch_iou)
epoch_loss=np.mean(epoch_loss)
test_mIou=np.mean(test_epoch_iou)
test_epoch_loss=np.mean(test_epoch_loss)
print('epoch:',epoch + 1,
'epoch_mIou:',mIou,
'epoch_loss:',epoch_loss,
'test_epoch_mIou:',test_mIou,
'test_epoch_loss:',test_epoch_loss)
train(10, model, optimizer, train_dl, test_dl)
# 模型性能检测
model.eval()
names ={'0':'WBC','1':'RBC','2':'Platelets'}
src_img = cv2.imread('D:/BloodImage_00002_jpg.rf.8abfeee935647b859f251b4ea8fb05b6.jpg')
img = cv2.cvtColor(src_img, cv2.COLOR_BGR2RGB)
labels,boxes=get_labelFromxml('D:/BloodImage_00002_jpg.rf.8abfeee935647b859f251b4ea8fb05b6.xml')
boxes=np.array(boxes)
labels=np.array(labels)
for idx in range(boxes.shape[0]):
x1, y1, x2, y2 = boxes[idx][0], boxes[idx][1], boxes[idx][2], boxes[idx][3]
name = names.get(str(labels[idx].item()))
cv2.rectangle(src_img,(x1,y1),(x2,y2),(255,0,0),thickness=1)
cv2.putText(src_img, text=name, org=(x1, y1+10), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.5, thickness=1, lineType=cv2.LINE_AA, color=(0, 0, 255))
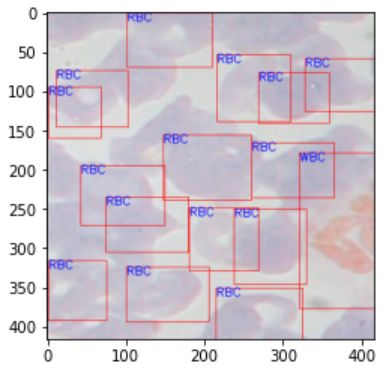
plt.imshow(src_img)
运行结果截图:
# 试用SSD模型,把上面的模型改为这一句
model=torchvision.models.detection.ssd(pretrained=False, progress=True, num_classes=4)
# 试用retinanet模型,把上面的模型改为这一句
model = torchvision.models.detection.retinanet_resnet50_fpn(pretrained = False, progress = True, num_classes = 4)
查看mAP值
把训练数据的xml数据和得到的结果数据的xml数据转为txt文本数据,函数代码如下:
class_to_id={'WBC':0,'RBC':1,'Platelets':2}
def get_labelFromXml(xml_file):
label=[]
bbox_list=[]
label_bbox=[]
####
xml_name=xml_file[37:-4]
xml_mAP_groundTruth='E:\血细胞目标检测\data\mAP\{}.txt'.format(xml_name)
with open(xml_mAP_groundTruth,'w') as f:
###
an_file = open(xml_file, encoding='utf-8')
tree=ET.parse(an_file)
root = tree.getroot()
for object in root.findall('object'):
cell=object.find('name').text
xmin=object.find('bndbox').find('xmin').text
xmax=object.find('bndbox').find('xmax').text
ymin=object.find('bndbox').find('ymin').text
ymax=object.find('bndbox').find('ymax').text
f.write(cell+'\t'+xmin+'\t'+ymin+'\t'+xmax+'\t'+ymax+'\n')
names ={'0':'WBC','1':'RBC','2':'Platelets'}
def getPrelable(images_file):
src_img = cv2.imread(images_file)
img = cv2.cvtColor(src_img, cv2.COLOR_BGR2RGB)
img_tensor = torch.from_numpy(img/255.).permute(2,0,1).float()##(3,416,416)
out = model([img_tensor])
boxes = out[0]['boxes'].cpu().detach().numpy().astype(int)
labels = out[0]['labels'].cpu().detach().numpy().astype(int)
scores = out[0]['scores'].cpu().detach().numpy()
img_bboxPredname=images_file[37:-4]
ml_mAP_pred='E:\血细胞目标检测\data\mAPpred\{}.txt'.format(img_bboxPredname)
with open(ml_mAP_pred,'w') as f:
for idx in range(boxes.shape[0]):
classes=names[str(labels[idx])]然后打开https://github.com/Cartucho/mAP网址下载源码,解压,把input文件夹里面的ground-truth和detection-results文件夹里面的文件清空,再把原本训练样本的txt放在input/ground-truth文件夹下,预测结果数据txt放在input/detection-results文件夹下,打开cmd命令行到map文件夹下,运行python main.py,可以看到:
coninf_score=str(scores[idx])
x1, y1, x2, y2 = boxes[idx][0], boxes[idx][1], boxes[idx][2], boxes[idx][3]
f.write(classes+'\t'+coninf_score+'\t'+str(x1)+'\t'+str(y1)+'\t'+str(x2)+'\t'+str(y2)+'\n')
然后打开https://github.com/Cartucho/mAP网址下载源码,解压,把input文件夹里面的ground-truth和detection-results文件夹里面的文件清空,再把原本训练样本的txt放在input/ground-truth文件夹下,预测结果数据txt放在input/detection-results文件夹下,打开cmd命令行到map文件夹下,运行python main.py,可以看到:
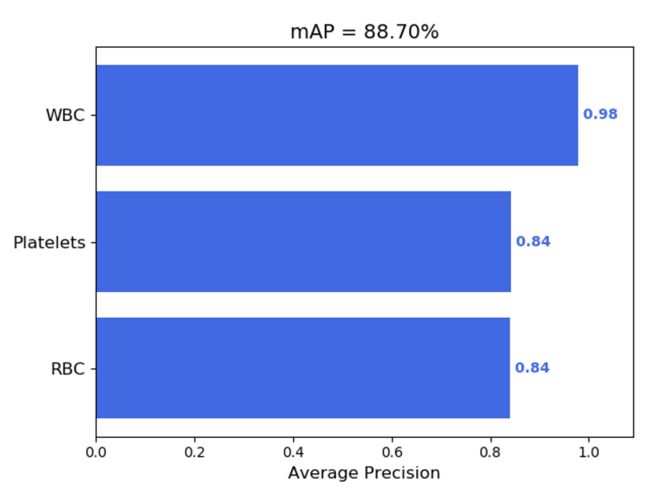
后续可以使用更多的模型,尝试使用其他backbone的模型,使用更多训练的trick——比如mixup数据增强、mosaic数据增强、学习率衰减、标签平滑等,改进和提升模型效果。
如有代码不规范之处,还望大家手敲避免复制出现报错。
点击卡片关注【学姐带你玩AI】
获取更多项目实战案例解析+代码数据集