机器学习系列(3)——k近邻法(k-NN)
本文介绍k近邻法(k-nearest neighbor, k-NN)和kd树算法。
0x01、k近邻法简介
k近邻法是基本且简单的分类与回归方法。k近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的k个最近邻训练实例点,然后利用这k个训练实例点的类的多数来预测输入实例点的类。
k近邻模型对应于基于训练数据集对特征空间的一个划分。k近邻法中,当训练集、距离度量、k值及分类决策规则确定后,其结果唯一确定。常用的距离度量是欧氏距离及更一般的  距离。k 值小时,k近邻模型更复杂,k值大时,k近邻模型更简单。k值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的k。常用的分类决策规则是多数表决,对应于经验风险最小化。
距离。k 值小时,k近邻模型更复杂,k值大时,k近邻模型更简单。k值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的k。常用的分类决策规则是多数表决,对应于经验风险最小化。
k近邻法的实现需要考虑如何快速搜索k个最近邻点。kd树是一种便于对k维空间中的数据进行快速检索的数据结构,kd树是二叉树,表示对k维空间的一个划分,其每个结点对应于k维空间划分中的一个超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
0x02、k近邻模型
k近邻法使用的模型实际上对应于特征空间的划分。模型由三个基本要素:距离度量、k值的选择和分类决策规则决定。特征空间中,对于每个训练实例点,距离该点比其他点更近的所有点组成一个区域,叫做单元(cell)。每个训练实例点拥有一个单元,所有训练实例点的单元构成对特征空间的一个划分。最近邻法将实例  的类
的类  作为其单元中所有点的类标记(class label),这样,每个单元的实例点的类别是确定的。
作为其单元中所有点的类标记(class label),这样,每个单元的实例点的类别是确定的。
1、距离度量
设特征空间  是 n 维实数向量空间
是 n 维实数向量空间 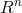 ,
,![]() ,
,![]() ,
,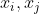 的 距离定义为:
的 距离定义为:

这里 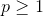 。
。
当 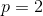 时,称为欧氏距离(Euclidean distance),即:
时,称为欧氏距离(Euclidean distance),即:
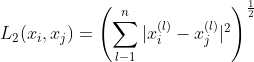
当  时,称为曼哈顿距离(Manhattan distance),即:
时,称为曼哈顿距离(Manhattan distance),即:

当  时,它是各个坐标距离的最大值(闵氏距离),即:
时,它是各个坐标距离的最大值(闵氏距离),即:
![]()
2、k值的选择
k值的选择会对k近邻法的结果产生重大影响。k值的减小就意味着整体模型变得复杂,容易发生过拟合;k值的增大意味着整体的模型变得简单。
如果选择较小的k值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差(approximation error)会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用。但缺点是“学习”的估计误差(estimation error)会增大,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰巧是噪声,预测就会出错。
如果选择较大的k值,就相当于用较大邻域中的训练实例进行预测。其优点是可以减少学习的估计误差,缺点是学习的近似误差会增大,这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。
在应用中k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k值。
3、分类决策规则
k近邻法中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定输入实例的类。
多数表决规则(majority voting rule):如果分类的损失函数为0-1损失函数,分类函数为:![]() ,
,
那么误分类的概率是:![]() 。对给定的实例
。对给定的实例 ![]() ,其近邻的k个训练实例点构成集合
,其近邻的k个训练实例点构成集合 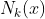 。如果涵盖 的区域的类别是
。如果涵盖 的区域的类别是  ,那么误分类率是:
,那么误分类率是:

要是误分类率最小即经验风险最小,就要使 ![]() 最大,所以多数表决规则等价于经验风险最小。
最大,所以多数表决规则等价于经验风险最小。
4、kd树
kd树表示对k维空间的一个划分(partition),构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域,kd树的每个结点对应于一个k维超矩形区域。
(1)构造kd树的方法
方法如下:构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域:通过递归,不断地对k维空间进行切分,生成子节点。通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数(median)为切分点,这样得到的kd树是平衡的。注意平衡的kd树搜索时的效率未必是最优的。
(2)搜索kd树
给定一个目标点,搜索其最近邻。首先找到包含目标点的叶结点,然后从该叶结点出发,依次回退到父结点,不断查找与目标点最邻近的结点,当确定不可能存在更近的结点时终止。这样搜索就被限制在空间的局部区域上,效率大为提高。
0x03、k近邻算法
1、基本k近邻算法
k近邻算法简单直观:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。k近邻法没有显式的 学习过程。
输入:训练数据集 ![]() ,其中,
,其中,![]() 为实例的特征向量,
为实例的特征向量,![]() 为实例的类别,
为实例的类别, ;实例特征向量
;实例特征向量  ;
;
输出:实例 所属的类  。
。
(1)根据给定的距离度量,在训练集 T 中找出与 最邻近的  个点,涵盖这 个点的 的邻域记作 ;
个点,涵盖这 个点的 的邻域记作 ;
(2)在 中根据分类决策规则(如多数表决)决定 的类别 :
![]()
其中, 为指示函数,即当
为指示函数,即当 ![]() 时 为1,否则 为0 。
时 为1,否则 为0 。
2、构造平衡kd树算法
输入:k 维空间数据集 ![]() ,其中
,其中 ![]() ;
;
输出: kd树 。
(1)开始:构造根结点,根结点对应于包含 T 的k维空间的超矩形区域。
选择  为坐标轴,以 T 中所有的实例的 坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个字区域。切分由通过切分点并与坐标轴 垂直的超平面实现。
为坐标轴,以 T 中所有的实例的 坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个字区域。切分由通过切分点并与坐标轴 垂直的超平面实现。
由根结点生成深度为1 的左右子结点:左子结点对应坐标 小于切分点的子区域,右子结点对应于坐标 大于切分点的子区域。
将落在切分点超平面上的实例点保存在根结点。
(2)重复:对深度为 j 的结点,选择  为切分点的坐标轴,
为切分点的坐标轴,![]() ,以该结点的区域中所有实例的 坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 垂直的超平面实现。
,以该结点的区域中所有实例的 坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 垂直的超平面实现。
由该结点生成深度为 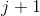 的左右子结点:左子结点对应坐标 小于切分点的子区域,右子结点对应坐标 大于切分点的子区域。将落在切分超平面上的实例点保存在该结点。
的左右子结点:左子结点对应坐标 小于切分点的子区域,右子结点对应坐标 大于切分点的子区域。将落在切分超平面上的实例点保存在该结点。
(3)知道两个子区域没有实例存在时停止,从而形成kd树的区域划分。
3、用kd树的最近邻搜索算法
输入:已构造的kd树,目标点 ;
输出: 的最近邻。
(1)在kd树中找出包含目标点 的叶结点:从根结点出发,递归地向下访问kd树。若目标点 x 当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点。知道子结点为叶结点为止;
(2)以此叶结点为“当前最近点”;
(3)递归地向上回退,在每个结点进行以下操作:
(a)如果该结点保存的实例点比当前最近点距离目标点更近,则以该实例点为“当前最近点”;
(b)当前最近点一定存在与该结点一个子结点对应的区域。检查该子结点的父结点的另一子结点对应的区域是否有更近的点。具体地,检查另一子结点对应的区域是否与以目标点为球心、以目标点与“当前最近点”间的距离为半径的超球体相交。如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着递归地进行最近邻搜索。如果不相交,向上回退。
(4)当回退到根结点时,搜索结束。最后的“当前最近点”即为 的最近邻点。
0x04、k近邻法在sklearn中的实现
sklearn中的API接口是:sklearn.neighbors。常用方法有:sklearn.neighbors.KNeighborsClassifier等。
| 参数 | 参数类型 | 默认值 | 参数含义 | 详细说明 |
| n_neighbors | int | 5 | 邻近的结点数量 | k近邻中的邻近结点数量。 |
| weights | {'uniform','distance'} 或 指定向量 |
"uniform" | 权重 | 预测中使用的权重。 Uniform:所有结点权重相等; distance:离簇中心越近的点权重越高; callable: 用户自定义数据点权重。 |
| algorithm | {'auto','ball_tree', 'kd_tree','brute'} |
"auto" | 计算最近邻结点的算法 | auto:自动选择算法; ball_tree:使用BallTree; kd_tree:使用KDTree; brute:使用brute-force搜索。 |
| leaf_size | int | 30 | 构造树的大小 | leaf_size传递给BallTree或者KDTree,表示构造树的大小,用于影响模型构建的速度和树需要的内存数量,最佳值是根据数据来确定的 |
| p | int | 2 | 设置Minkowski 距离的Power参数 | 当p=1时,等价于曼哈顿距离;当p=2等价于欧拉距离;当p>2时,就是Minkowski距离。 |
| metric | 字符串 或 自定义 | "minkowski" | 设置计算距离的方法 | 树计算距离的度量 |
| metric_params | dict | None | 传递给计算距离方法的参数 | 附加的关键词 |
| n_jobs | int | None | 并发执行 | 并发执行的job数量,用于查找邻近的数据点。默认值1,选取-1占据CPU比重会减小,但运行速度也会变慢,所有的core都会运行。 |
参考:
[1]. 李航. 统计学习方法(第二版)
[2]. sklearn学习第三篇:knn分类 - 博客园