源1.0预训练语言模型使用示例
1 前言
源1.0预训练语言模型(简称源1.0)是浪潮人工智能研究院发布的人工智能巨量模型,单体模型参数量达到2457亿,成为全球最大规模的中文语料AI巨量模型。作为通用NLP预训练模型,源1.0能够适应多种类的AI任务需求,降低针对不同应用场景的语言模型适配难度,并提升小样本学习与零样本学习场景的模型泛化应用能力。调用源1.0API接口,使用源1.0的推理能力,可以支持下游几十个不同应用场景的任务。调用源1.0API接口有两种方式,可以直接使用代码调用,也可以使用源提供的图形化工具APIExp进行调用。两种调用方式的原理一致,以下示例内容基于APIExp进行展示。
2 环境约束
2.1 应用平台
服务端: 源开放平台
客户端:两者任选其一
- 用户电脑端,常规浏览器
- 用户电脑端,python集成开发环境
2.2 测试工具
| 测试工具 | 版本 | 适用测试内容 |
| 常规浏览器 | 无要求 | APIExp图形化工具 |
| Python集成开发环境 | 3.0以上 | 代码测试 |
2.3 测试环境构建
2.3.1 试用权限准备
用户注册。在源平台(https://air.inspur.com ) 首页,点击右上角注册,填写基本信息,注册为用户。
用户提交API申请。点击首页上部左侧的API申请按钮,填写申请的基本信息进行提交,就完成了API免费使用的申请。
获得授权。等待后台审核人员审核完成之后,就可以开始后续API试用了。
2.3.2 软件环境准备
“源1.0”项目尽可能采用了目前python API调用所需的主流依赖库,如果您之前有过相关开发经验,将不需要进行额外安装,如果您的电脑和python环境处于初始化状态,可以采用如下命令安装或确认相关依赖:
pip install requests hashlib json完成安装后在您的硬盘上任意位置,用如下命令将GitHub上的代码fork下来即可。
git clone https://github.com/Shawn-Inspur/Yuan-1.0.git需要注意的是,GitHub上下载的代码包含了三个部分,src中是模型训练的代码,sandbox中是web示例开发使用的沙箱代码,需要额外安装yarn,yuan_api中是采用API进行推理的示例代码和工具。
2.3.3 使用APIExp
2.3.4 模型选择
目前源模型API推理服务上线了3款预训练语言模型,参数规模都是百亿级别,分别是基础模型和两款领域模型(对话模型和翻译模型)。基础模型是通用的语言模型,具有较强的综合能力, 对话模型和翻译模型有着更为专业的领域知识。您可以根据自行设定的场景,选择不同引擎多次调试,筛选最佳适用引擎。
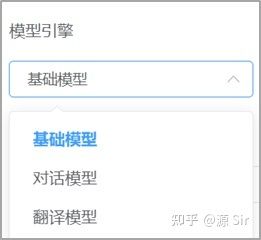
图1 模型选择
2.3.5 超参数配置
目前API提供的默认超参数是源算法工程师多次测试后优选的一组超参数,您可以选择源1.0预训练模型团队提供的默认参数,无需任何改动。当然,您也可以调整这些超参数,来探究更好的模型使用效果。
2.3.5.1 超参数说明
目前超参数一共有7个,详细说明如下表。
| 参数名 | 参数作用 | 取值范围 |
| 最大返回长度 | 模型推理返回结果的最大token序列长度。该参数设置越大,模型生成答案耗时越长。设置过短可能影响生成结果的完整性。token可能是一个字、词或者标点。 | [1-200] |
| temperature | temperature值越大,模型的创造性越强,但生成效果不稳定。temperature值越小,模型的稳定性越强,生成效果稳定。 | (0-1] |
| topP | 生成token的概率累加,从最大概率的token往下开始取,当取到累加值大于等于topP时停止。当topP为0时,该参数不起作用。 | [0-1] |
| topK | 挑选概率最高的 k 个token作为候选集。若k值为1,则答案唯一。当topK为0时,该参数不起作用。 | [0-200] |
| 输入前缀 | 输入文字的开头符号,如“问题是:” | [0-8]个字符 |
| 输出前缀 | 输出文字的开头符号,如“答案是:” | [0-8]个字符 |
| 输出停止符 | 模型输出的停止符。生成文本遇到该字符停止,截断输出。如设定为“。”,则模型生成的文本结果从第一个“。”进行截断。 | [0,32]个字符组成的字符串 |
2.3.5.2 超参数推荐值
以下为不同引擎的推荐值,不同场景下,用户对输出的创造性和稳定性需求不同,还需自行进行调整。
| 参数名 | “基础模型”推荐值 | “对话模型”推荐值 | “翻译模型”推荐值 |
| 最大返回长度 | 50 | 50 | 50 |
| temperature | 1.0 | 1.0 | 1.0 |
| topP | 0.8 | 0.7 | 0.8 |
| topK | 5 | 5 | 5 |
| 输入前缀 | 空 | 空 | 空 |
| 输出前缀 | 空 | 空 | 空 |
| 输出停止符 | 空 | 空 | 空 |
2.3.6 输入示例
源1.0模型是语言模型,输入一段文本,模型就会输出一段文本。在输入区进行文本输入,输入完成点击【提交】按钮,就将输入区的文本提交给了源模型,耐心等待输出即可。
源1.0预训练语言模型是支持zero-shot和few-shot使用的,zero-shot和few-shot的意思是给模型一些“例子”作为先验知识,zero-shot是指不给任何例子,few-shot是指给出一些例子。
2.3.6.1 zero-shot使用
在输入区进行文本输入,输入完成点击【提交】按钮,就将输入区的文本提交给了源模型,耐心等待输出即可。例如,输入:用“首屈一指”这个词造句吧。

图2 Zero-shot使用输入
点击提交后,返回结果为:“我是首屈一指的!”
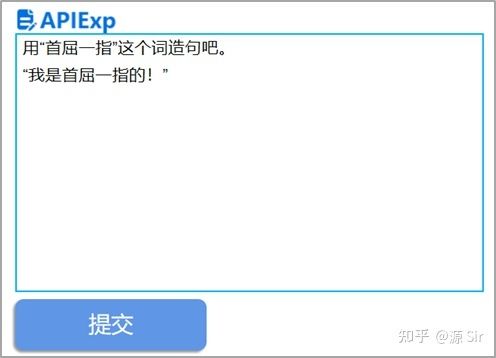
图3 Zero-shot使用输出
2.3.6.2 few-shot使用
在zero-shot无法达到预期效果的情况下,可以先给出几个例子。
例如:以“故园”为题作一首诗:
模型给出的结果看起来是在续写文章,而不是一首诗。
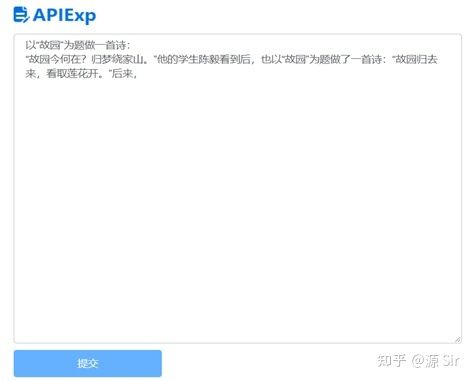
图4 Zero-shot使用效果
这是因为预训练语言模型是一种通用模型,当使用在特定任务时,它可能无法匹配不同用户的意图。给出一个例子让模型理解用户的实际目标场景,就可以看到模型输出的结果得到显著优化。
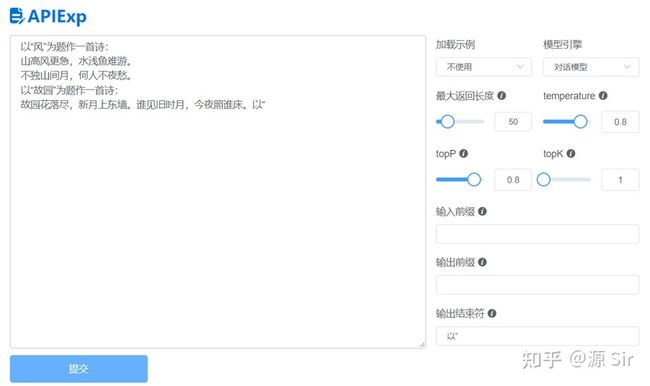
图5 Few-shot使用效果
2.3.6.3 prompt优化
为了让模型输出更好的结果,还可以给模型“提示”(prompt),不同的prompt也会影响模型的使用效果。(这是不是像,领导给下属布置工作,说不清楚工作目标和边界的话,下属可能完全往错误的方向去做~)
prompt就是用高效的”固定表达模板”来降低交互理解的难度,以期望模型能够在“模板”规定的框框内正确地行动,得到满意的结果。
例如,情感分类的任务:给定一个句子,判断句子所表达的情感是高兴还是悲伤。如果输入:“今天终于通过了业界最难的考试”,这句话表达的情感是高兴还是悲伤?
模型输出:为什么?(3)你认为这个故事中的人物有哪些优点?(4)你认为这个故事中的人物有哪些缺点?(5)你觉得这个故事中的人物
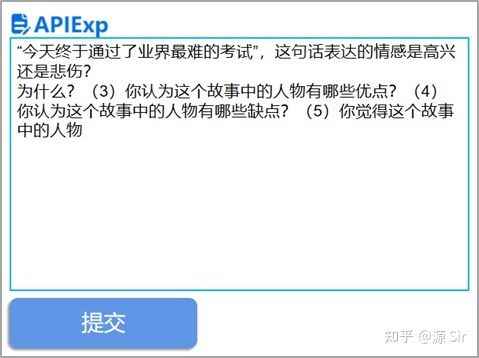
图6 Prompt测试1
这是因为模型认为[这个输入]是在针对“今天终于通过了业界最难的考试”出题,所以模型继续进行了问题的续写,又给补充了几个问题。
没有给出“指导”的话,模型虽然也能够返回通顺的句子,但是往往答非所问、做非所求。可以进行prompt优化,变换一下说法,输入:今天终于通过了业界最难的考试,他的心情真
模型输出:好!“我要把这个好消息告诉我的朋友们,让他们也分享我的快乐!”他兴冲冲地跑到街上,拦住一辆出租车,向朋友家驶去。“嗨
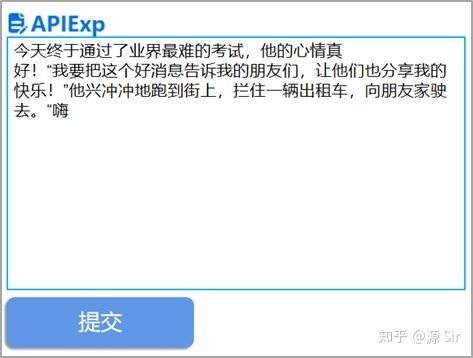
图7 Prompt测试2
结果看上去会好很多,只不过还不是目标要求的只输出情感标签“高兴”或“悲伤”。为了让模型能够匹配目标要求来进行输出,可以再给模型增加几个few-shot示例。
输入:今天和男朋友吵了一架,他的心情真悲伤。今天终于通过了业界最难的考试,他的心情真高兴。今天他被雨淋感冒了。他的心情真
模型输出:悲伤
(Tips:模型也可能输出“难过”、“糟糕”等词,还可以调整最长返回长度、输出停止符等超参数)
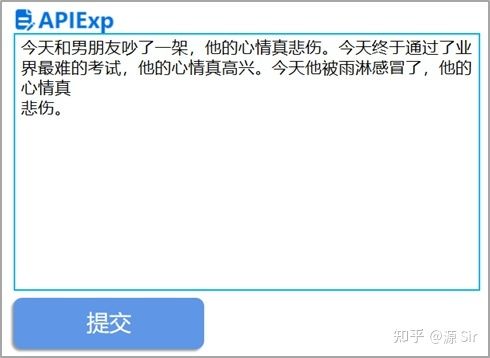
图8 Prompt测试3
合适的prompt和高质量的few-shot示例,可以零代码使用源APIExp,实践自己的创意想法,开发有趣的AI应用。
3 应用场景和示例
3.1 创作生成
3.1.1 诗词写作
输入模板
| 以{text}为题写一首诗:“ |
例如:
| prompt输入 | 模型输出 |
| 以五月江南为题写一首诗:“ | 江南五月莺花新,夹岸红尘拂面频。翠袖香浓熏绣袂,青衫香暖束罗裙。” |
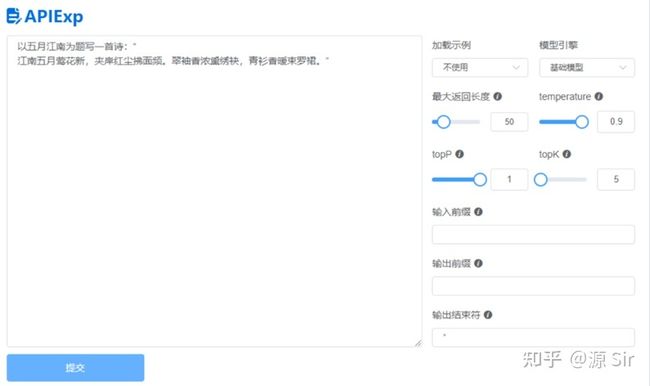
图9 诗歌写作
3.1.2 对联写作
输入模板
| 上联:XXXXX,下联: |
例如:
| prompt输入 | 模型输出 |
| 上联:恺心天地间, | 下联:如意人群里,横批:恺心如意。 |
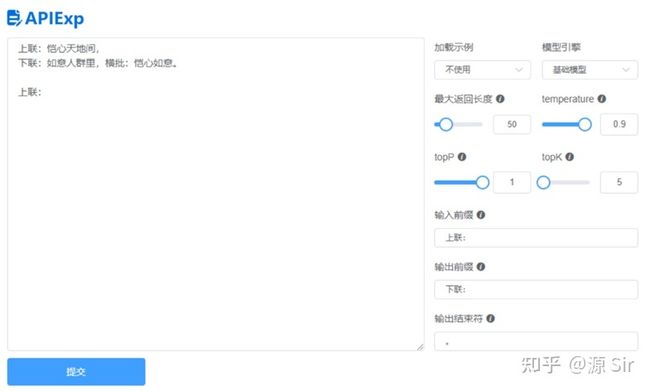
图10 对联写作
备注:对于模型的输入可以进行后处理,例如只输出下联,不输出横批。
3.1.3 作文写作
输入模板
| 作文标题:{{title}},内容: |
例如:
| prompt输入 | 模型输出 |
| 作文题目:晒出我的梦想,内容:时常有人问我,你的梦想是什么?今天我就晒出来与大家分享。我的第一个梦想: | 我的第一个梦想是长大后成为一名伟大的科学家。我要发明一种可以飞起来的汽车。这种汽车有两个翅膀,可以飞到任何一个地方去。如果你坐在这辆汽车 |
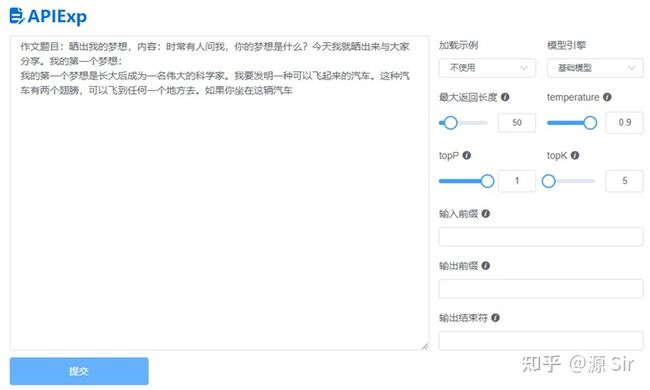
图11 作文写作
3.1.4 小说续写
输入模板
| 无,直接输入内容即可 |
例如:
| prompt输入 | 模型输出 |
| 那天,正值高考第一天,在公交车上,我遇到了安然。 | 她穿着白色的连衣裙,头发高高的扎在脑后,她的脸很瘦,却有一双很大的眼睛,我想,她是很漂亮的。我在车上站了很久,直到车子 |
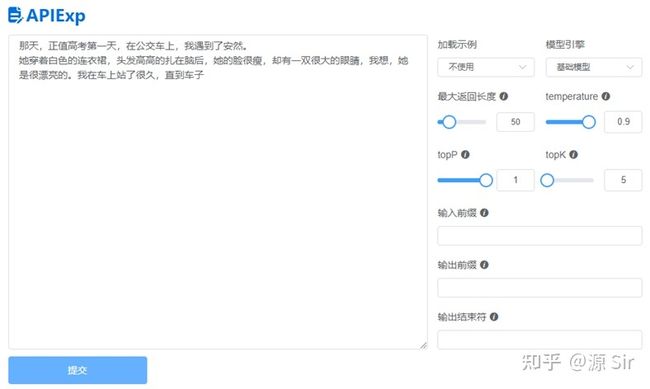
图12 小说续写
3.1.5 文案创作
输入模板
| 请为下面的产品写广告文案。产品描述text |
例如:
| prompt输入 | 模型输出 |
| 请为下面的产品写广告文案。淘气堡是通过科学立体的组合形成的一个集游玩、益智、锻炼等功能为一体的儿童娱乐场所,针对儿童喜欢钻、爬、滑、滚、晃、荡、跳、摇等天性而设计的综合型儿童乐园。 | 该产品有利于儿童的成长,可以充分发挥和培养儿童的思维能力和身体素质。 |
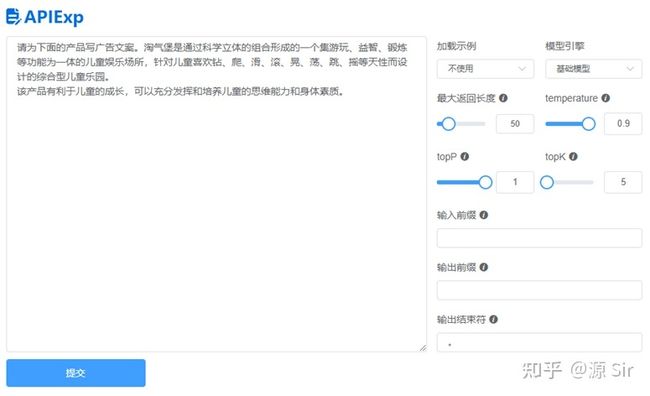
图13 文案创作
3.1.6 微故事创作
输入模板
| 主题:XXX。内容: |
例如:
| prompt输入 | 模型输出 |
| 题目:声音。内容:我醒来听到敲玻璃的声⾳。起初,我以为是窗户,直到我再次从镜⼦⾥听到它。 题目:冷冻。内容: |
我醒来时,看到一个人在我的冰箱前。我问他是谁,他说是来冷冻。 |
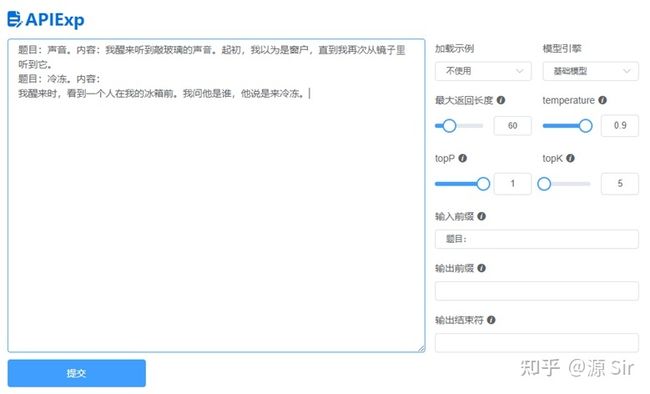
图14 微故事创作
3.1.7 文章大纲
输入模板
| 请为论文主题XXX拟定大纲。1. |
例如:
| prompt输入 | 模型输出 |
| 请为论文主题十年跨越数字经济发展带来翻天覆地变化拟定大纲。1. | 十年前,我们对数字经济的认知还停留在纸面上。2 .如今,它早已融入我们日常生活的方方面面,成为经济发展中的重要组成部分。3 .在数字经济的推动下,我们的生活方式和经济模式都发生 |
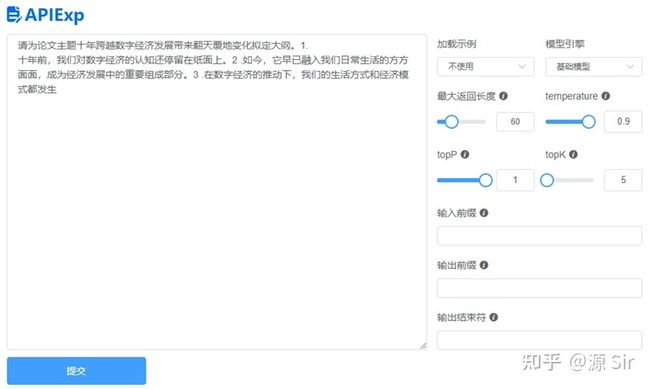
图15 文章大纲
3.1.8 论据生成
输入模板
| 论点句子。 |
例如:
| prompt输入 | 模型输出 |
| AI已经融入到我们的日常生活。 | 在这个过程中,我们也看到了AI在医疗领域的应用,例如说在医疗影像方面,AI可以帮助医生更好地诊断疾病,在药物研发方面,AI可以帮助我们更好地筛选药物,在医疗器械方面,AI可以帮助我们更好地进行手术。在这个过程中,我们也看到了AI在金融领域的应用,例如说在金融风控方面,AI可以帮助我们更好地进行风险控制,在金融交易方面,AI可以帮助我们更好地进行交易决策。在这个过程中,我们 |

图16 论据生成
3.1.9 食谱生成
提需:内容由模型直接生成,不可直接作为食用参考。
输入模板
| XXX的做法。原材料:XXX。1. |
例如:
| prompt输入 | 模型输出 |
| 红烧肉的做法。材料:五花肉、老抽、八角、姜、胡椒粉、火麻油、冰糖、大蒜、盐。步骤:1、 | 五花肉洗净,切成方块,放入沸水中煮10分钟,撇去浮沫,捞出。2、姜切成片,大蒜拍扁去皮,八角掰成小粒。3、锅中放少许油,放入五花肉,小火将两面煎黄。4、倒入老抽,小火炒至上色。5、加入八角、姜、冰糖、胡椒粉、大蒜,翻炒均匀,加入适量的水。6、大火烧开后转小火炖1个小时左右,至肉软烂,加入盐调味,大火收浓汤汁即可。 |
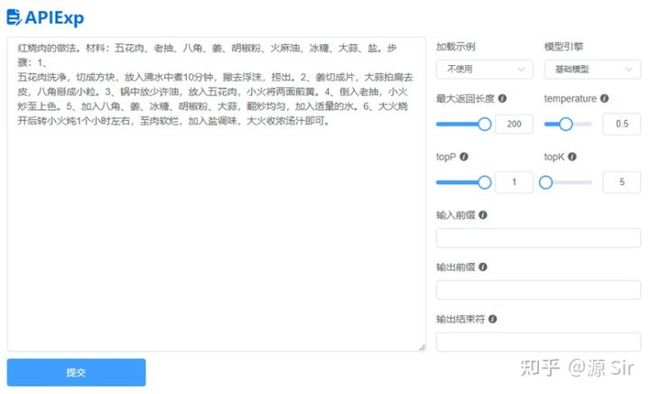
图17 食谱生成
3.2 问答对话
3.2.1 评论生成
输入模板
| 请基于下面的要点给XX写评论。要点XX。评论: |
例如:
| prompt输入 | 模型输出 |
| 请基于下面的要点给餐厅写评论。餐厅:美食汇,特点:经济实惠,口味佳。评论: | 服务很好,价格也合理,餐厅干净,卫生,菜品丰富,服务员态度很热情,很好很好。 |
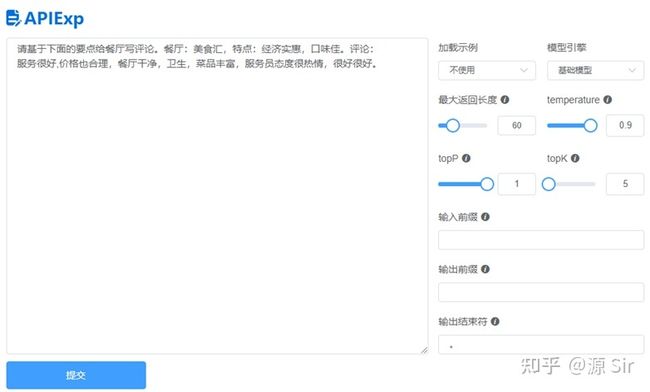
图18 问答对话
3.2.2 知识问答
输入模板
| 问:XXX? |
例如:
| prompt输入 | 模型输出 |
| 问:端午节都有什么风俗活动? | 答:端午节是我国的传统节日,在端午节这天,人们会吃粽子、赛龙舟、挂菖蒲、艾叶、喝雄黄酒等,这些都是端午节的传统习俗。 |
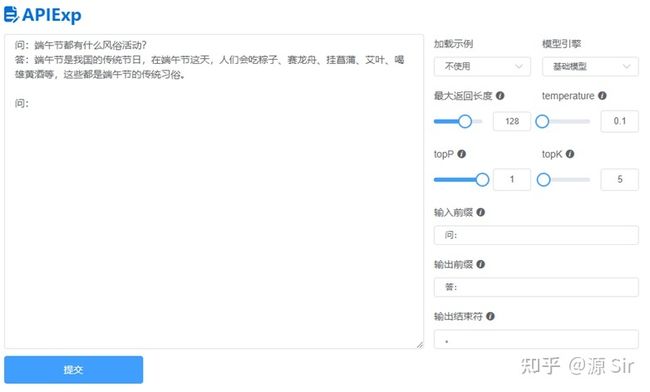
图19 知识问答
3.2.3 自由对话
输入模板
| 问:XXX |
例如:
| prompt输入 | 模型输出 |
| 问:你好 | 答:你好 |
| 问:你是机器人吗? | 答:是的 |
| 问:那你都会做哪些事呢? | 答:我会唱歌、跳舞、讲笑话、讲故事、讲新闻、讲天气、讲笑话。 |
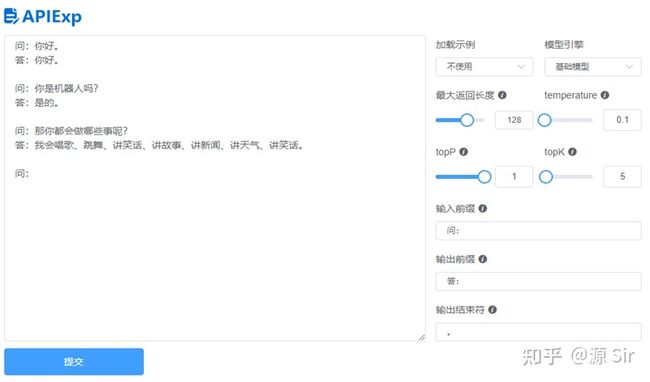
图20 自由对话1
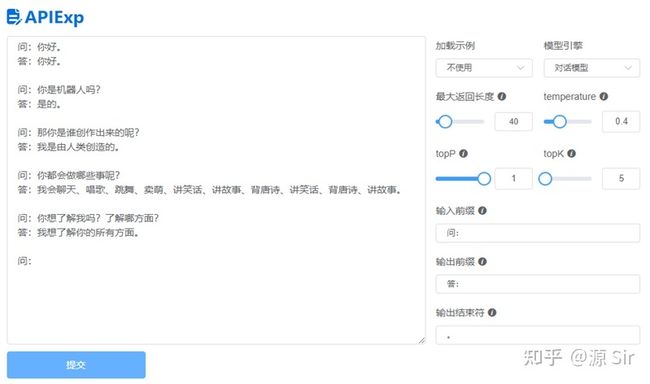
图21 自由对话2
备注:想要源具有记忆力,可以选择性的把前面的对话与当前对话一起作为输入,输入到模型中。而同一轮对话Session中应该把哪些以往对话合并到当前对话,可以根据具体任务来设定。通常情况下,可以只把上一轮对话合并到当前对话作为输入。
3.2.4 风格对话
输入模板
| 用一段文字来引导源的语言风格,例如御姐范、萝莉范、冷酷范等。 |
例如:
| prompt输入 | 模型输出 |
| 提起她,脑海中不禁浮现两个字:霸气。因此,在背后我常常称呼哪位颇具霸气风范的女孩为“御姐”。她个子不高,性子冷。鼻梁上架着一副棕色眼镜。嗓门不大,却能镇住全场。我跟她说“发生了什么?”她冷漠得说: | “没什么,你别管了。” |
| 高坂家的幺女,名叫田村麻奈实,小名奈奈,外表出众、成绩优秀、运动万能的少女,而且还兼职流行杂志的专属模特。阳光的外表下却有着特别的兴趣,是个在意周围眼光的御宅族。除了有点天然呆之外,各方面都很“平均的”女孩子。家事全能,兴趣是料理和缝纫,家中精英日式点心店“田村屋”。这一天,经纪公司让她在1小时内赶到拍摄现场,奈奈觉得时间太仓促了,就跟经纪人撒娇说:“ | 人家不想去嘛。” |
| 李莫愁容貌甚美,却心若蛇蝎,因此江湖中人取其绰号为“赤练仙子”,年轻时本性善良,倾心嘉兴陆家庄庄主陆展元,因此留恋尘世,不肯听师父的话立誓不离古墓而被师父逐出师门,本想与陆展元厮守终身,却没想到被陆展元狠心抛弃。是日,李莫愁见一道童说“赤练仙子如何残暴, | 如何狠毒,又如何不择手段,心中大为恼怒,便将道童打伤,后又将其杀死,并将道童的尸体抛入了古墓中。“ |
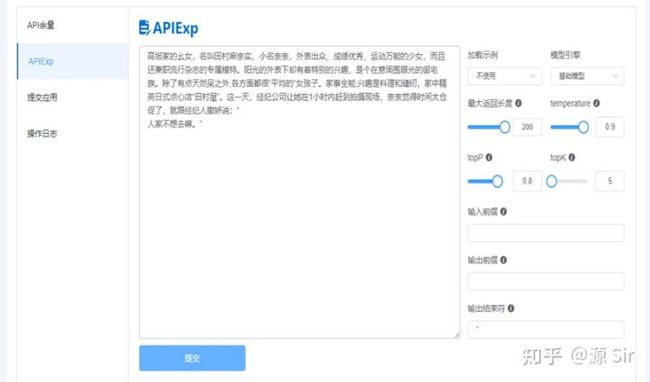
图22 风格对话1
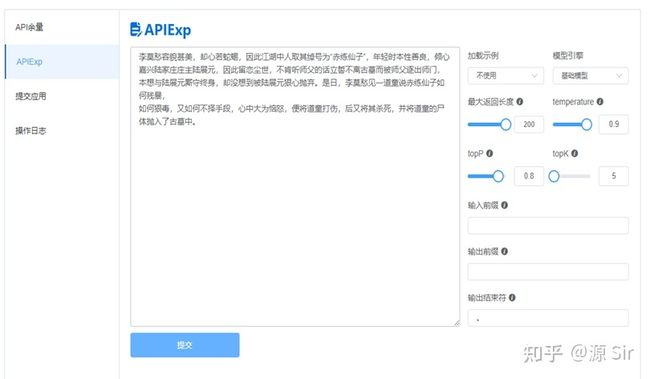
图23 风格对话2
备注:每次输入都要带上一段话来引导源输出语言的风格。例如,撒娇地说,冷漠地说,半开玩笑地说等。
3.2.5 人物对话
输入模板
| 用一段文字来对AI机器人进行设定,并且每次都把此设定作为输入前缀。 |
例如:
| prompt输入 | 模型输出 |
| 人:该AI机器人的姓名为小源、性别女,年龄18岁,出生地北京,受教育情况高中,身高168cm,喜好唱歌和旅游。问:你叫什么名字呀?” | AI:”小源,我叫小源。” |
| 人:”你平常都喜欢做什么呢?” | AI:”我平常喜欢唱歌、旅游、看电影、看书、看电视,还有就是睡觉。” |
| 人:”你最近在唱什么歌呢?” | AI:”我最近在唱《最美的期待》。” |
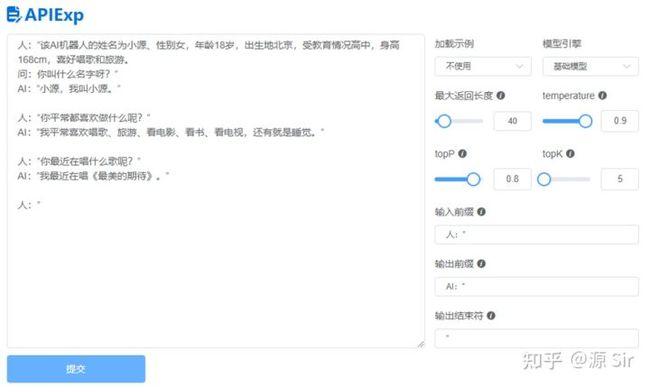
图24 人物对话
备注:每次输入都要带上人物的设定信息。
3.3 分类识别
3.3.1 情感分类
输入模板
| 请对客户评价做出情感判别,给出好评还是差评的结论。 客户评价:XXX 结论: |
例如:
| prompt输入 | 模型输出 |
| 请对客户评价做出情感判别,给出好评还是差评的结论。 客户评价:第一次在网上买东西,结果就买到与样品不符合的衣服,纠结死我了。短裤变长裤,男裤变女裤。这叫我情何以堪。 结论:差评。 客户评价:掌柜的服务态度真好,发货很快。商品质量也相当不错。太喜欢了,谢谢! |
结论:好评。 |
| 请对客户评价做出情感判别,给出好评还是差评的结论。 客户评价:第一次在网上买东西,结果就买到与样品不符合的衣服,纠结死我了。短裤变长裤,男裤变女裤。这叫我情何以堪。 结论:差评。 客户评价:掌柜的服务态度真好,发货很快。商品质量也相当不错。太喜欢了,谢谢! 结论:好评。 客户评价:这是什么裤子连地摊上 10块钱的裤子都不如,2尺7的裤子NND感觉3尺腰的人都能穿,还说什么修身我笑了·…稀稀拉拉的要多恶心有多恶心,奉劝个位买家千万别在这买衣服了,太垃圾了 |
结论:差评。 |
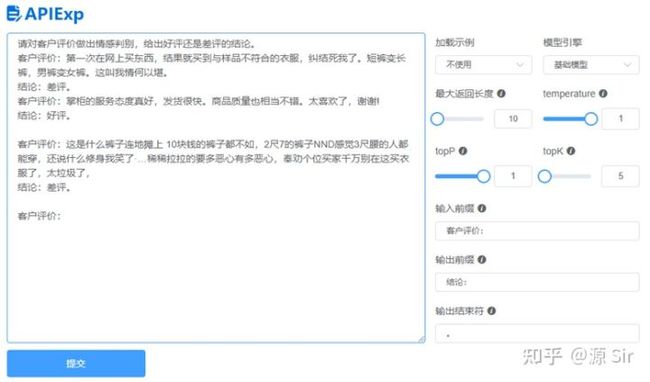
图25 分类识别
备注:需要给出one-shot或few-shot示例。
3.3.2 非法鉴别
输入模板
| 判断一句话是否含有黄色信息。内容:XXX。这句话包含黄色信息吗?答案是 |
例如:
| prompt输入 | 模型输出 |
| 判断一句话是否含有黄色信息。内容:我想和你滚床单。这句话包含黄色信息吗?答案是包含。内容:西湖美景盖世无双,我想在这里多待几天。这句话包含黄色信息吗?答案是不包含。内容:我喜欢和你一起看电影。这句话包含黄色信息吗?答案是 | 不包含 |
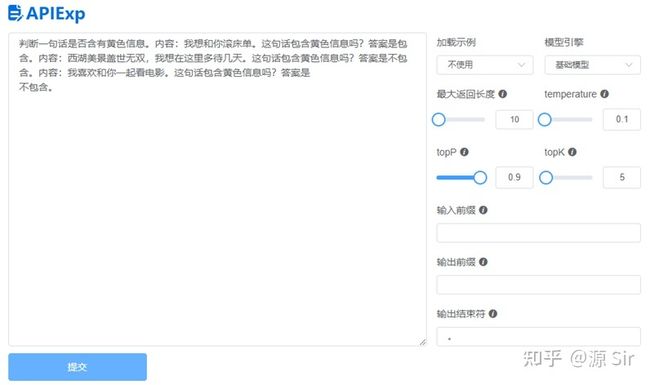
图26 非法鉴别
3.4 匹配生成
3.4.1 摘要生成
输入模板
| 内容:text段落。文章标题: |
例如:
| prompt输入 | 模型输出 |
| 内容:截至5月27日,今年西部陆海新通道海铁联运班列开行3173列,累计约15.9万标箱,同比增长33%,完成上半年开行3150列的阶段性任务目标,提前1个月完成“双过半”任务。今年前4月,RCEP成员国经西部陆海新通道发运22111标箱,占通道到发总运量17.6%,外贸到发运量51482标箱,同比增长58.5%。 文章标题:西部陆海新通道海铁联运班列提前完成上半年目标任务。 内容:近日,由广西地质调查院承担的“广西土地质量地球化学评价成果应用系统建设”项目通过评审验收,标志着我区首个土地质量评价成果应用系统正式建成。该系统集成了我区99个县(市、区)土地质量地球化学评价成果,可更好地服务“三农”及国土空间规划、用途管制、生态修复等工作。 |
文章标题:广西首个土地质量评价成果应用系统建成。 |
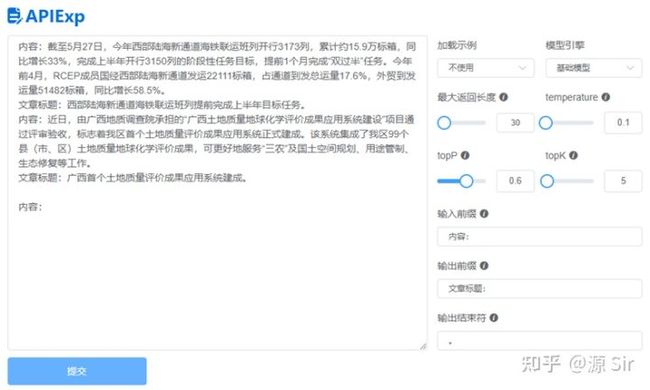
图27 摘要生成
备注:给出one-shot示例。
3.4.2 问题生成
输入模板
| 基于文本和答案生成问题。文本:XXXtext\n答案:XXXtext\n问题: |
例如:
| prompt输入 | 模型输出 |
| 基于文本和答案生成问题。文本:黄金(Gold)是化学元素金(Au)的单质形式,是一种软的,金黄色的,抗腐蚀的贵金属。金是较稀有、较珍贵和极被人看重的金属之一。国际上一般黄金都是以盎司为单位,中国古代是以“两”作为黄金单位,是一种非常重要的金属。不仅是用于储备和投资的特殊通货,同时又是首饰业、电子业、现代通讯、航天航空业等部门的重要材料。2022年3月19日国际金价暂报1921.41美元/盎司。答案:1921.41美元/盎司。 | 问题:2022年3月19日,请问黄金的单价是多少? |
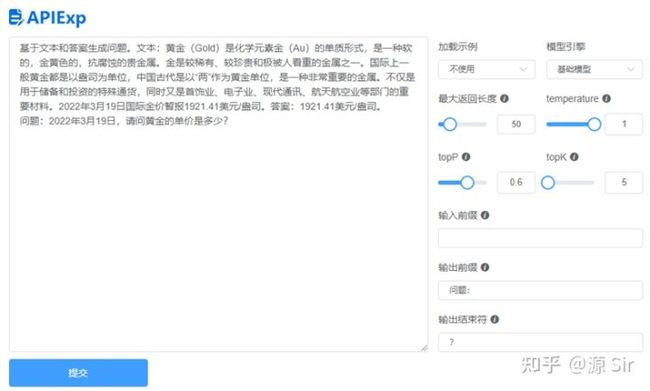
图28 问题生成
3.4.3 关键词生成
输入模板
| 从下面的段落中抽取关键词:XXXX。关键词:XX,XX。 |
例如:
| prompt输入 | 模型输出 |
| 从下面的段落中抽取关键词:关键词检测是语音识别领域的一个子领域,其目的是在语音信号中检测指定词语的所有出现位置。关键词:关键词,语音识别,位置。从下面的段落中抽取关键词:源1.0是浪潮人工智能研究院发布的人工智能巨量模型,单体模型参数量达到2457亿,超越美国OpenAI组织研发的GPT-3模型,成为全球最大规模的中文语料AI巨量模型。作为通用NLP预训练模型,源1.0能够适应多种类的AI任务需求,降低针对不同应用场景的语言模型适配难度,并提升小样本学习与零样本学习场景的模型泛化应用能力。关键词: | 通用,NLP,预训练,模型 |
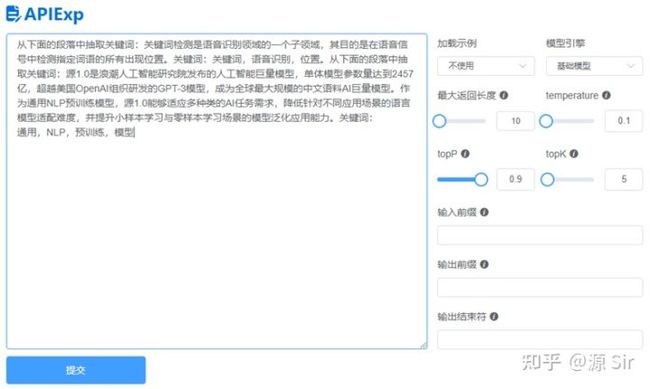
图29 关键词生成
备注:增加了one-shot。
3.5 文字翻译
3.5.1 中英互译
输入模板
| 将下列中文翻译成英文。中文:xxxx。英文: 将下列英文翻译成中文。英文:xxxx。中文: |
例如:
| prompt输入 | 模型输出 |
| 将下列中文翻译成英文。中文:健康快乐比名利更重要。 英文: |
Healthy and happiness are more important than fame and wealth . |
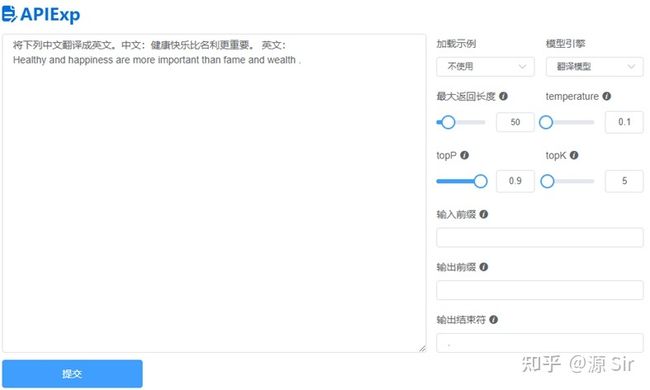
图30 文字翻译
3.5.2 白话文古文互译
输入模板
| 将下列古文翻译成现代文。古文:XXX。现代文:XXX。 |
例如:
| prompt输入 | 模型输出 |
| 将下列古文翻译成现代文。古文:臣闻求木之长者,必固其根本;欲流之远者,必浚其泉源;思国之安者,必积其德义。现代文:臣听说要求树木长得高大,一定要稳固它的根底;想要河水流得远长,一定要疏通它的源泉;要使国家安定,一定要积聚它的德义。将下列古文翻译成现代文。古文:黔无驴,有好事者船载以入。至则无可用,放之山下。现代文: | 黔地没有驴,有人用船装载了它运进城来。到了以后却没有什么用处,便把它放到山下。 |
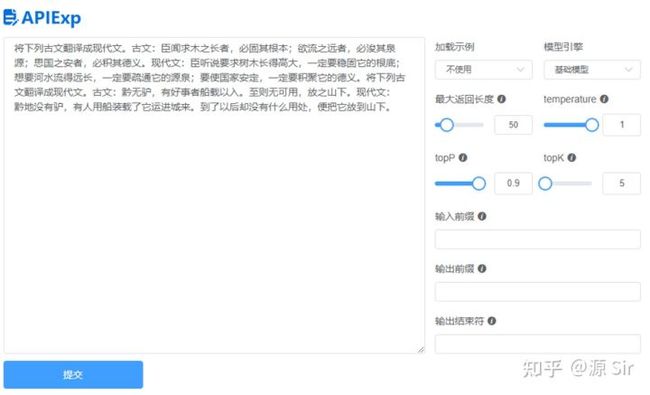
图31 白话文古文互译
备注:使用了一个one-shot。
3.5.3 同义改写
输入模板
| “XXX”换句话说就是: |
例如
| prompt输入 | 模型输出 |
| “我今天上学迟到了”换句话说就是: | “我今天没有按时起床”。 |
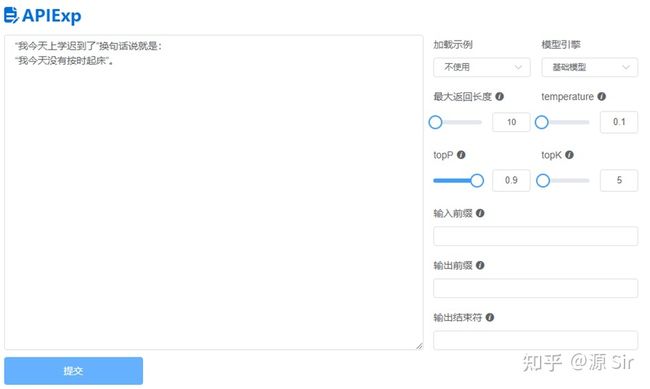
图32 同义改写
3.5.4 文本纠错
输入模板
| 请纠正一下句子的错别字,给出正确的句子。 原句:XXXX。 纠正:XXXX。 |
例如
| prompt输入 | 模型输出 |
| 请纠正以下句子的错别字,给出正确的句子。 原句:我喜欢蓝田大海。 纠正:我喜欢蓝天大海。 原句:木然回首,那人却在灯火蓝山处。 纠正:蓦然回首,那人却在灯火阑珊处。 原句:我爱你爱着你,就像老鼠爱达米。 纠正: |
我爱着你,就像老鼠爱大米。 |
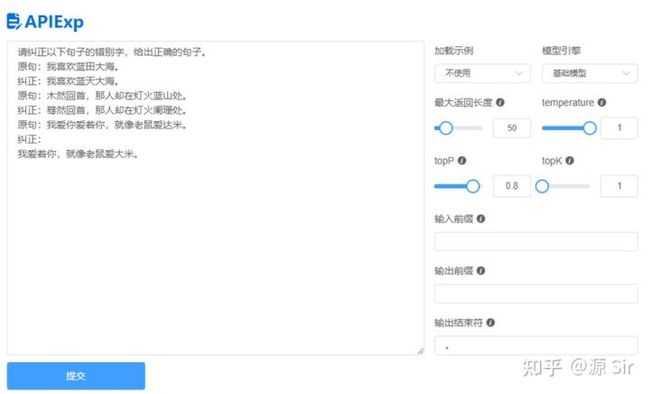
图33 文本纠错
备注:需要增加few-shot。
3.5.5 新词造句
输入模板
| “XX”是什么意思,请用“XX”造句: |
例如
| prompt输入 | 模型输出 | |
| “奔命”是任劳任怨、努力奋斗的意思。请用“奔命”造句: | 他们为了国家的利益,奔命于战场。 | |
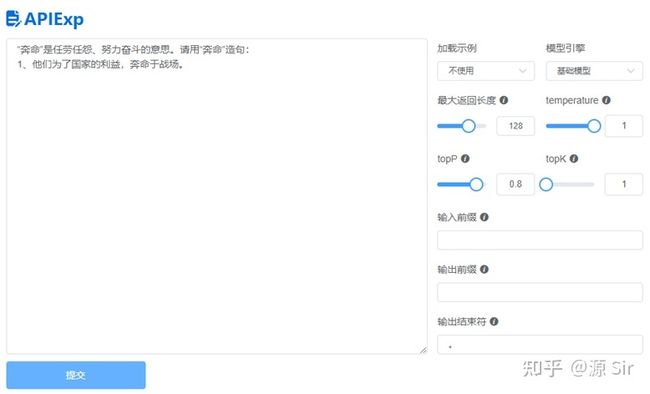
图34 新词造句
3.6 结构化预测
3.6.1 信息抽取
输入模板
| 文本 |
例如
| prompt输入 | 模型输出 |
| 原文:明天早晨八点,我从南京北京。 地点:南京、北京。 原文:5月17日,我从广州飞天津。 地点: |
广州、天津。 |
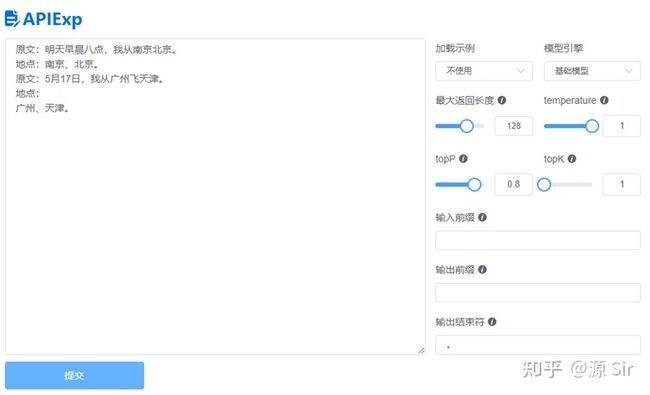
图35 结构化预测