Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
摘要
Transformers在图像分类和其他视觉任务上的强大性能往往归功于multi-head attention layers层的设计。然而,这种强劲表现在多大程度上是由注意力引起的,目前还不清楚。在这篇简短的报告中,我们要问:注意力层有必要吗?具体来说,我们用patch dimension的前馈层替换Transformers中的注意力层。最终的体系结构只是一系列以交替方式应用于patch和feature维度的前馈层。在ImageNet上的实验中,该体系结构表现惊人地好:ViT/DeiT-base-sized模型获得了74.9%的top-1精度,而ViT和DeiT分别为77.9%和79.9%。这些结果表明,Transformers的其他方面,如patch embedding,可能比之前认为的更负责的表现。我们希望这些结果能促使社区花更多的时间来理解为什么我们目前的模型如此有效。
1. Introduction
由[4]介绍的vision transformers架构,将一系列的transformers模块应用于一系列的图像块。每个块由一个 multi-head 注意层[11]和一个沿着特征维度应用的前馈层(即线性层,或单层MLP)组成。这种架构的通用特性,加上它在图像分类基准测试中的强大性能,引起了视觉社区的极大兴趣。然而,目前还不清楚为什么vision transformers有效。
最常被引用的transformer在视觉任务上成功的原因是它的注意力层的设计,这给了这个模型是一个全局的接受域。这一层可以看作是一个与数据相关的线性层,当应用到图像patch上时,它类似于(但不完全等同于)卷积。事实上,最近的大量工作都是为了提高注意力层的效率和效力。
在这篇简短的报告中,我们进行了一个实验,希望能揭示为什么vision transformers在一开始就工作得这么好。具体来说,我们将注意力从视觉转换器中移除,取而代之的是应用在patch维度上的前馈层。如图一所示,该模型只是一系列以交替方式应用于patch和feature维度的前馈层(图1)。
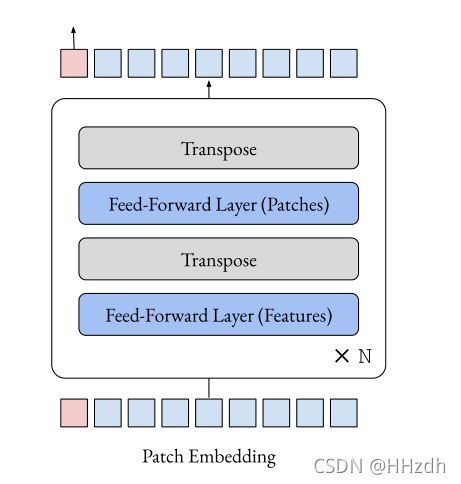 图1:本报告中探索的架构非常简单,由patch embedding和一系列前馈层组成。这些前馈层交替应用于图像标记的patch和feature维度。该架构与ViT[4]相同,只是将注意层替换为前馈层。
图1:本报告中探索的架构非常简单,由patch embedding和一系列前馈层组成。这些前馈层交替应用于图像标记的patch和feature维度。该架构与ViT[4]相同,只是将注意层替换为前馈层。
在ImageNet上进行的实验(表1)表明,即使不需要注意,也可以获得相当强的性能。值得注意的是,在不进行任何超参数优化的情况下(即使用与ViT对应的超参数), ViT-base-sized模型的top-1准确率为74.9%。这些结果表明,vision transformers的强大表现可能不是由于注意力机制,而是由于其他因素,如由patch embedding和精心设计的训练增强集产生的诱导偏差。
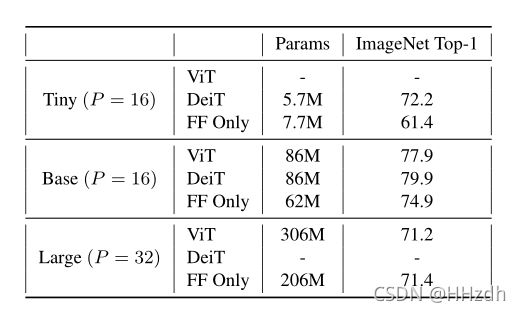 表1:ImageNet top-1精度在不同模型尺寸下的比较。第一列中,P为以像素为单位的patch大小。总的来说,只有前馈层(只有FF层)的模型比有关注层的模型表现得更差,但无论如何,它们的表现都令人惊讶地好。在有或没有关注的情况下,最大型的模型的性能都会下降。
表1:ImageNet top-1精度在不同模型尺寸下的比较。第一列中,P为以像素为单位的patch大小。总的来说,只有前馈层(只有FF层)的模型比有关注层的模型表现得更差,但无论如何,它们的表现都令人惊讶地好。在有或没有关注的情况下,最大型的模型的性能都会下降。
本报告的主要目的是探讨简单体系结构的局限性。我们不希望破坏ImageNet基准;在这方面,像神经结构搜索(如EfficientNet[8])这样的方法将不可避免地表现最好。尽管如此,我们希望社区发现这些结果是有趣的,这些结果促使更多的研究人员去调查为什么我们目前的模型是如此有效。
2. Background
这份报告的背景是,在过去的几个月里,对vision transformer架构变体的研究出现了爆炸式增长:Deit[9]添加蒸馏,DeepViT[14]混合注意头,CaiT[10]将注意层分为两个阶段,Token-to-Token ViT[13]在整个网络中聚合相邻的令牌,CrossViT[1]在两个规模处理补丁,PiT[6]添加池化层,LeViT[5]使用卷积嵌入和修改的注意/归一化层,CvT[12]在注意层使用深度卷积,Swin/Twins[2,7]结合了全局和局部注意,这只是其中的几个例子。
这些作品都是对vision transformer架构的改进,每个作品在ImageNet上都表现出了强大的性能。然而,目前还不清楚ViT的不同部分或它的许多变体如何对每个模型的最终性能做出贡献。这份报告详细介绍了一个实验,研究了这个问题的一个方面,即关注层对ViT的成功有多重要。
3. Method and Experiments
3.1. Do You Even Need Attention?
我们将注意层从ViT模型中移除,代之以patch维度上的一个简单前馈层。我们在特征维上使用与标准前馈网络相同的结构,也就是说,我们将patch维投影到高维空间,应用非线性,并将其投影回来到原空间。图2给出了PyTorch代码。
我们应该注意到,就像vision transformer及其许多变体一样,这种仅前馈网络与卷积网络具有很强的相似性。事实上,patch维度上的前馈层可以被看作是一种不同寻常的卷积,具有一个完整的接受域和一个单一的通道。由于特征维上的前馈层可以看作是1x1卷积,所以从技术上说,整个网络是一种伪装的卷积网络。也就是说,它在结构上更像一个transformer,而不是传统设计的卷积网络(如ResNet/VGG)。
3.2. Experimental Setup
我们使用DeiT[9]的设置在ImageNet[3]上训练三个模型,分别对应于ViT/DeiT微型、基础和大型网络。由于计算限制,小型和基础网络的patch大小为16,而大型网络的patch大小为32。训练和评估在分辨率为224px的地方进行。值得注意的是,我们对所有模型使用与DeiT完全相同的超参数,这意味着我们的性能可能通过超参数调优得到改善。
3.3. Results
表1显示了简单前馈网络在ImageNet上的性能。最值得注意的是,仅前馈版本的ViT/Deit-base实现了令人惊讶的强大性能(74.9%的top-1精度),可与许多旧的卷积网络(如VGG16, ResNet-34)相媲美。这样的比较是不公平的因为前馈模型使用了更强的训练增广,但从绝对意义上说,它仍然是一个相当强的结果。
对于有注意和没有注意的模型,大模型的性能下降,分别产生71.2%和71.4%的top-1精度。正如[4]中所详细描述的,对于如此庞大的模型来说,使用更大的数据集进行预训练是必要的。
3.4. Do You Even Need Feed-Forward Layers?
当然,既然我们尝试只用前馈层训练模型,我们也尝试只用注意层训练模型。在这个模型中,我们简单地将特征维度上的前馈层替换为特征维度上的关注层。我们只试验了一个很小的模型(4.0M参数),但它的表现非常糟糕(在100个纪元时,top-1精度为28.2%,此时我们结束了运行)。
3.5. Discussion
实验证明,不需要注意层,就可以训练出一个相当强的vision transformer图像分类器。此外,没有前馈层的注意力层似乎不会产生类似的强性能。这些结果表明,ViT的强大性能可能更多地归因于它的patch embedding和训练过程,而不是注意层的设计。特别是patch embedding提供了强烈的归纳偏差,这可能是模型强大性能的主要驱动因素之一。
从实际的角度来看,仅前馈模型比vision transformer有一个显著的优势,即它的复杂性与序列长度是线性的,而不是二次的。这种情况是由于在前馈层的中间投影维数应用于patch,其大小不一定依赖于序列长度。通常选择中间维为输入特征数(即patch数)的倍数,在这种情况下,模型确实是二次的,但这并不一定需要这种情况。
除了性能更差之外,纯前馈模型的一个主要缺点是它只能在固定长度的序列上运行(由于patch上的前馈层)。对于图像分类来说,这不是一个大问题,因为图像被裁剪成标准大小,但这限制了体系结构对其他任务的适用性。
仅前馈模型阐明了vision transformer和注意力机制的一般情况。对于未来,研究这些结论在图像域之外的应用程度将是很有趣的,例如在NLP/audio中。
3.6. Conclusion
这篇简短的报告表明,没有注意层的vision transformer式网络可以产生令人惊讶的强图像分类器。这个方向的未来工作可以尝试更好地理解transformer体系结构的其他部分(例如标准化层或初始化方案)的贡献。更广泛地说,我们希望这篇简短的报告能鼓励进一步调查为什么我们目前的模型表现得和它们一样好。
References
[1]Chun-Fu Chen, Quanfu Fan, and Rameswar Panda. Crossvit:Cross-attention multi-scale vision transformer for image classification, 2021.
[2]Xiangxiang Chu, Zhi Tian, Y uqing Wang, Bo Zhang, Haibing Ren, Xiaolin Wei, Huaxia Xia, and Chunhua Shen.Twins: Revisiting spatial attention design in vision trans-formers, 2021.
[3]J. Deng, W. Dong, R. Socher, L. Li, Kai Li, and Li FeiFei. Imagenet: A large-scale hierarchical image database.InProc. CVPR, pages 248–255, 2009.
[4]Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov,Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner,Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2020.
[5]Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze.Levit: a vision transformer in convnet’s clothing for faster inference, 2021.
[6]Byeongho Heo, Sangdoo Y un, Dongyoon Han, Sanghyuk Chun, Junsuk Choe, and Seong Joon Oh. Rethinking spatial dimensions of vision transformers, 2021.
[7]Ze Liu, Y utong Lin, Y ue Cao, Han Hu, Yixuan Wei,Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows, 2021.
[8]Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational Conference on Machine Learning, pages 6105–6114. PMLR,2019.
[9]Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers and distillation through attention.arXiv preprint arXiv:2012.12877, 2020.
[10]Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles,Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers.arXiv preprint arXiv:2103.17239, 2021.
[11]Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNIPS, 2017.
[12]Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu,Xiyang Dai, Lu Y uan, and Lei Zhang. Cvt: Introducing convolutions to vision transformers.arXiv preprint arXiv:2103.15808, 2021.
[13]Li Y uan, Y unpeng Chen, Tao Wang, Weihao Y u, Y ujun Shi,Francis EH Tay, Jiashi Feng, and Shuicheng Yan. Tokens-to-token vit: Training vision transformers from scratch on imagenet.arXiv preprint arXiv:2101.11986, 2021.
[14]Daquan Zhou, Bingyi Kang, Xiaojie Jin, Linjie Yang, Xi-aochen Lian, Zihang Jiang, Qibin Hou, and Jiashi Feng.Deepvit: Towards deeper vision transformer, 2021.