五种模型(支持向量机,随机森林,线性回归,多项式回归,岭回归)对新型冠状病毒的历史数据进行预测
数据来源
上篇文章对新型冠状病毒的数据进行了爬取,本文利用爬取到的数据进行一些数据分析。
爬虫教学连接
本文使用的jupyter进行数据分析(2021年1月1日到4月14日的数据
其中,4月12到4月14日的数据用于预测与模型评估(均方误差作为评价标准))
知识预备
python的基本操作语句
python的库
numpy
pandas
matplotlib
五种模型的思想与sklearn库的五种模型的调用。
升级思路
可以爬中国各个省市的数据然后绘制空间图。
空间图绘制方法:
首先进行经纬度匹配:可以参考匹配经纬度 这篇文章
常用空间绘图工具(echarts,Qgis(wgs84),excel(火星坐标))
qgis操作可以参考这篇文章Qgis,操作不难。
可以将平面图升级为seaborn,或bokeh库绘制
时间序列模型也可以增加ARMA模型进行预测。(不要用传染病模型,不太好用,那个是封闭区间的,但是新冠这个与那个有本质的区别,当然有个最新升级的版本,我也没看过,可能可以用)
实现过程
- 导包,没什么可说的
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import pandas as pd
import random
import math
import time
from dateutil.parser import parse
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, mean_absolute_error
#from sklearn import linear_model
#导入线性模型和多项式特征构造模块
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import Ridge
import datetime
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
nameMap = {'毛里求斯':'Mauritius','圣皮埃尔和密克隆群岛':'St. Pierre and Miquelon','安圭拉':'Anguilla','荷兰加勒比地区':'Caribbean Netherlands','圣巴泰勒米岛':'Saint Barthelemy','英属维尔京群岛':'British Virgin Is.','科摩罗':'Comoros','蒙特塞拉特':'Montserrat','塞舌尔':'Seychelles','特克斯和凯科斯群岛':'Turks and Caicos Is.','梵蒂冈':'Vatican','圣其茨和尼维斯':'Saint Kitts and Nevis','库拉索岛':'Curaçao','多米尼克':'Dominica','圣文森特和格林纳丁斯':'St. Vin. and Gren.','斐济':'Fiji','圣卢西亚':'Saint Lucia','北马里亚纳群岛联邦':'N. Mariana Is.','格林那达':'Grenada','安提瓜和巴布达':'Antigua and Barb.','列支敦士登':'Liechtenstein','圣马丁岛':'Saint Martin','法属波利尼西亚':'Fr. Polynesia','美属维尔京群岛':'U.S. Virgin Is.','荷属圣马丁':'Sint Maarten','巴巴多斯':'Barbados','开曼群岛':'Cayman Is.','摩纳哥':'Monaco','阿鲁巴':'Aruba','特立尼达和多巴哥':'Trinidad and Tobago','钻石公主号邮轮':'Princess','瓜德罗普岛':'Guadeloupe','关岛':'Guam','直布罗陀':'Gibraltar','马提尼克':'Martinique','马耳他':'Malta','法罗群岛':'Faeroe Is.','圣多美和普林西比':'São Tomé and Principe','安道尔':'Andorra','根西岛':'Guernsey','泽西岛':'Jersey','佛得角':'Cape Verde','马恩岛':'Isle of Man','留尼旺':'Reunion','圣马力诺':'San Marino','马尔代夫':'Maldives','马约特':'Mayotte','巴林':'Bahrain','新加坡': 'Singapore Rep.', '多米尼加': 'Dominican Rep.', '巴勒斯坦': 'Palestine', '巴哈马': 'The Bahamas', '东帝汶': 'East Timor', '阿富汗': 'Afghanistan', '几内亚比绍': 'Guinea Bissau', '科特迪瓦': "Côte d'Ivoire", '锡亚琴冰川': 'Siachen Glacier', '英属印度洋领土': 'Br. Indian Ocean Ter.', '安哥拉': 'Angola', '阿尔巴尼亚': 'Albania', '阿联酋': 'United Arab Emirates', '阿根廷': 'Argentina', '亚美尼亚': 'Armenia', '法属南半球和南极领地': 'French Southern and Antarctic Lands', '澳大利亚': 'Australia', '奥地利': 'Austria', '阿塞拜疆': 'Azerbaijan', '布隆迪共和国': 'Burundi', '比利时': 'Belgium', '贝宁': 'Benin', '布基纳法索': 'Burkina Faso', '孟加拉国': 'Bangladesh', '保加利亚': 'Bulgaria', '波黑': 'Bosnia and Herz.', '白俄罗斯': 'Belarus', '伯利兹': 'Belize', '百慕大': 'Bermuda', '玻利维亚': 'Bolivia', '巴西': 'Brazil', '文莱': 'Brunei', '不丹': 'Bhutan', '博茨瓦纳': 'Botswana', '中非共和国': 'Central African Rep.', '加拿大': 'Canada', '瑞士': 'Switzerland', '智利': 'Chile', '中国': 'China', '象牙海岸': 'Ivory Coast', '喀麦隆': 'Cameroon', '刚果(金)': 'Dem. Rep. Congo', '刚果(布)': 'Congo', '哥伦比亚': 'Colombia', '哥斯达黎加': 'Costa Rica', '古巴': 'Cuba', '北塞浦路斯': 'N. Cyprus', '塞浦路斯': 'Cyprus', '捷克': 'Czech Rep.', '德国': 'Germany', '吉布提': 'Djibouti', '丹麦': 'Denmark', '阿尔及利亚': 'Algeria', '厄瓜多尔': 'Ecuador', '埃及': 'Egypt', '厄立特里亚': 'Eritrea', '西班牙': 'Spain', '爱沙尼亚': 'Estonia', '埃塞俄比亚': 'Ethiopia', '芬兰': 'Finland', '斐': 'Fiji', '福克兰群岛': 'Falkland Islands', '法国': 'France', '加蓬': 'Gabon', '英国': 'United Kingdom', '格鲁吉亚': 'Georgia', '加纳': 'Ghana', '几内亚': 'Guinea', '冈比亚': 'Gambia', '赤道几内亚': 'Eq. Guinea', '希腊': 'Greece', '格陵兰': 'Greenland', '危地马拉': 'Guatemala', '法属圭亚那': 'French Guiana', '圭亚那': 'Guyana', '洪都拉斯': 'Honduras', '克罗地亚': 'Croatia', '海地': 'Haiti', '匈牙利': 'Hungary', '印度尼西亚': 'Indonesia', '印度': 'India', '爱尔兰': 'Ireland', '伊朗': 'Iran', '伊拉克': 'Iraq', '冰岛': 'Iceland', '以色列': 'Israel', '意大利': 'Italy', '牙买加': 'Jamaica', '约旦': 'Jordan', '日本': 'Japan', '哈萨克斯坦': 'Kazakhstan', '肯尼亚': 'Kenya', '吉尔吉斯斯坦': 'Kyrgyzstan', '柬埔寨': 'Cambodia', '韩国': 'Korea', '科索沃': 'Kosovo', '科威特': 'Kuwait', '老挝': 'Lao PDR', '黎巴嫩': 'Lebanon', '利比里亚': 'Liberia', '利比亚': 'Libya', '斯里兰卡': 'Sri Lanka', '莱索托': 'Lesotho', '立陶宛': 'Lithuania', '卢森堡': 'Luxembourg', '拉脱维亚': 'Latvia', '摩洛哥': 'Morocco', '摩尔多瓦': 'Moldova', '马达加斯加': 'Madagascar', '墨西哥': 'Mexico', '北马其顿': 'Macedonia', '马里': 'Mali', '缅甸': 'Myanmar', '黑山': 'Montenegro', '蒙古': 'Mongolia', '莫桑比克': 'Mozambique', '毛里塔尼亚': 'Mauritania', '马拉维': 'Malawi', '马来西亚': 'Malaysia', '纳米比亚': 'Namibia', '新喀里多尼亚': 'New Caledonia', '尼日尔': 'Niger', '尼日利亚': 'Nigeria', '尼加拉瓜': 'Nicaragua', '荷兰': 'Netherlands', '挪威': 'Norway', '尼泊尔': 'Nepal', '新西兰': 'New Zealand', '阿曼': 'Oman', '巴基斯坦': 'Pakistan', '巴拿马': 'Panama', '秘鲁': 'Peru', '菲律宾': 'Philippines', '巴布亚新几内亚': 'Papua New Guinea', '波兰': 'Poland', '波多黎各': 'Puerto Rico', '朝鲜': 'Dem. Rep. Korea', '葡萄牙': 'Portugal', '巴拉圭': 'Paraguay', '卡塔尔': 'Qatar', '罗马尼亚': 'Romania', '俄罗斯': 'Russia', '卢旺达': 'Rwanda', '西撒哈拉': 'W. Sahara', '沙特阿拉伯': 'Saudi Arabia', '苏丹': 'Sudan', '南苏丹': 'S. Sudan', '塞内加尔': 'Senegal', '所罗门群岛': 'Solomon Is.', '塞拉利昂': 'Sierra Leone', '萨尔瓦多': 'El Salvador', '索马里兰': 'Somaliland', '索马里': 'Somalia', '塞尔维亚': 'Serbia', '苏里南': 'Suriname', '斯洛伐克': 'Slovakia', '斯洛文尼亚': 'Slovenia', '瑞典': 'Sweden', '斯威士兰': 'Swaziland', '叙利亚': 'Syria', '乍得': 'Chad', '多哥': 'Togo', '泰国': 'Thailand', '塔吉克斯坦': 'Tajikistan', '土库曼斯坦': 'Turkmenistan', '特里尼达和多巴哥': 'Trinidad and Tobago', '突尼斯': 'Tunisia', '土耳其': 'Turkey', '坦桑尼亚': 'Tanzania', '乌干达': 'Uganda', '乌克兰': 'Ukraine', '乌拉圭': 'Uruguay', '美国': 'United States', '乌兹别克斯坦': 'Uzbekistan', '委内瑞拉': 'Venezuela', '越南': 'Vietnam', '瓦努阿图': 'Vanuatu', '西岸': 'West Bank', '也门共和国': 'Yemen', '南非': 'South Africa', '赞比亚共和国': 'Zambia', '津巴布韦': 'Zimbabwe'}
nameList = ['中国','美国','巴西','印度','巴基斯坦','英国','阿富汗','墨西哥','南非','乌克兰']
file = '/home/aistudio/'#本块代码是你要读文件的地址
#读数据
confirmedCount=pd.read_csv(file + 'confirmedCount' +'.csv').set_index('dateId')
curedCount=pd.read_csv(file + 'curedCount' +'.csv').set_index('dateId')
deadCount = pd.read_csv(file + 'deadCount' +'.csv').set_index('dateId')
#confirmedCount
#求和(每天的人数)
world_cases = confirmedCount.sum(axis=1)
#world_cases
4
将int的时间数据转换为datetime类型
X_data = world_cases.index.values
X_data = X_data.reshape(-1,1).astype(str)
X_time = X_data
for i in range(X_data.size):
X_time[i] = (parse(X_data[i][0]))
解出横坐标,即把月份改为从0开始
days_since_1_1 = np.array([i for i in range(len(world_cases))]).reshape(-1, 1)
#predict_confirmed = np.array([i for i in range(len(world_cases[-4:-1]))+days_since_1_1[-1]+1]).reshape(-1, 1)
future_forcast = np.array([i for i in range(len(world_cases))]).reshape(-1, 1)
future_forcast
划分数据集,分为测试集和训练集。并且改成一维数据。
X_train_confirmed, X_test_confirmed, y_train_confirmed, y_test_confirmed = train_test_split(days_since_1_1, world_cases.values, test_size=0.02, shuffle=False)
y_train_confirmed = y_train_confirmed.reshape(-1,1)
X_train_confirmed = X_train_confirmed.reshape(-1,1)
X_test_confirmed = X_test_confirmed.reshape(-1,1)
y_test_confirmed = y_test_confirmed.reshape(-1,1)
print(y_test_confirmed)
支持向量机预测
使用随机参数优化,
kernel = ['linear', 'rbf']
# c是错误的惩罚参数C.默认1
c = [0.01, 0.1, 1, 10]
# gamma是'rbf','poly'和'sigmoid'的核系数。默认是'auto'
gamma = [0.01, 0.1, 1]
# Epsilon在epsilon-SVR模型中。它指定了epsilon-tube,其中训练损失函数中没有惩罚与在实际值的距离epsilon内预测的点。默认值是0.1
epsilon = [0.01, 0.1, 1]
# shrinking指明是否使用收缩启发式。默认为True
shrinking = [True, False]
svm_grid = {'kernel': kernel, 'C': c, 'gamma' : gamma, 'epsilon': epsilon, 'shrinking' : shrinking}
# 建立支持向量回归模型
svm = SVR()
# 使用随机搜索进行超参优化
svm_search = RandomizedSearchCV(svm, svm_grid, scoring='neg_mean_squared_error', cv=3, return_train_score=True, n_jobs=-1, n_iter=30, verbose=1)
svm_search.fit(X_train_confirmed, y_train_confirmed)
使用刚刚优化的参数进行建模,然后预测,并输出均方误差
svm_confirmed = svm_search.best_estimator_
svm_pred = svm_confirmed.predict(future_forcast)
# check against testing data
svm_test_pred = svm_confirmed.predict(X_test_confirmed)
plt.plot(svm_test_pred,'r')
plt.plot(y_test_confirmed,'b')
print('MAE:', mean_absolute_error(svm_test_pred, y_test_confirmed))
print('MSE:',mean_squared_error(svm_test_pred, y_test_confirmed))
print(svm_test_pred)
结果
红色为模型预测值,蓝色为实际值,以下均同,不重复。
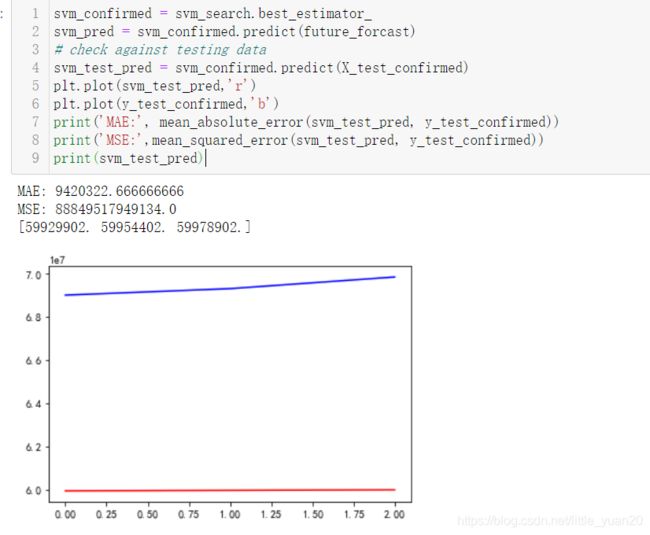
9.
随机森林模型
依然是先进行参数优化
ensemble_grid = {'n_estimators': [(i+1)*10 for i in range(20)],
'criterion': ['mse', 'mae'],
'bootstrap': [True, False],
}
ensemble = RandomForestRegressor()
ensemble_search = RandomizedSearchCV(ensemble, ensemble_grid, scoring='neg_mean_squared_error', cv=3, return_train_score=True, n_jobs=-1, n_iter=10, verbose=1)
ensemble_search.fit(X_train_confirmed, y_train_confirmed)
随机森林建模预测(这玩意回归问题挺垃圾的,一般分类用)
ensemble_confirmed = ensemble_search.best_estimator_
ensemble_pred = ensemble_confirmed.predict(future_forcast)
# check against testing data
ensemble_test_pred = ensemble_confirmed.predict(X_test_confirmed)
plt.plot(ensemble_test_pred,'r')
plt.plot(y_test_confirmed,'b')
print('MAE:', mean_absolute_error(ensemble_test_pred, y_test_confirmed))
print('MSE:',mean_squared_error(ensemble_test_pred, y_test_confirmed))
print(ensemble_test_pred)
结果
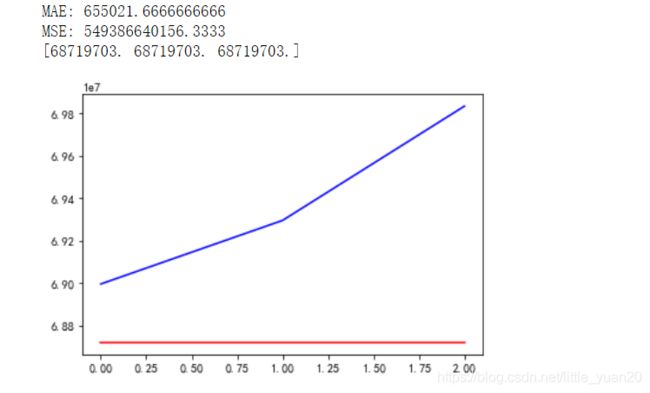
11.
线性回归
linear_model = LinearRegression(fit_intercept=False, normalize=True)
linear_model.fit(X_train_confirmed, y_train_confirmed)
test_linear_pred = linear_model.predict(X_test_confirmed)
linear_pred = linear_model.predict(future_forcast)
plt.plot(y_test_confirmed,'b')
plt.plot(test_linear_pred,'r')
print('MAE:', mean_absolute_error(test_linear_pred, y_test_confirmed))
print('MSE:',mean_squared_error(test_linear_pred, y_test_confirmed))
print('linear_model score:',linear_model.score(X_test_confirmed,y_test_confirmed))
print(test_linear_pred)
结果:五个模型里最垃圾的
r2是负数,意味着随机蒙一个都比模型预测的要好。
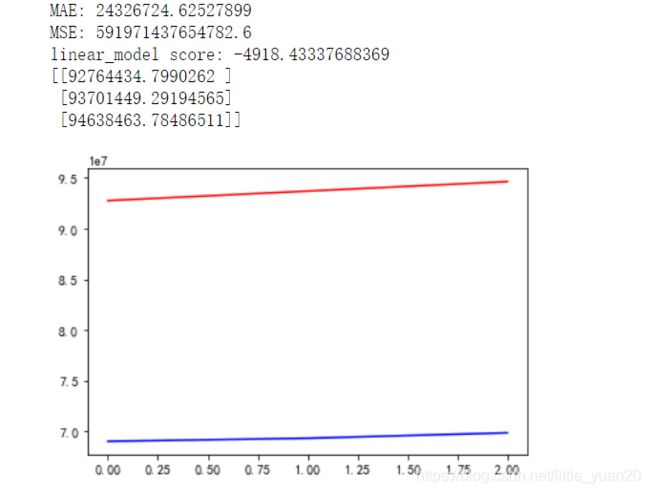
12.
多项式回归
#多项式回归
poly_reg =PolynomialFeatures(degree=7)
X_ploy =poly_reg.fit_transform(X_train_confirmed)
lin_reg_2=LinearRegression()
lin_reg_2.fit(X_ploy,y_train_confirmed)
test_poly_pred = lin_reg_2.predict(poly_reg.fit_transform(X_test_confirmed))
poly_pred = lin_reg_2.predict(poly_reg.fit_transform(future_forcast))
plt.plot(y_test_confirmed,'b')
plt.plot(test_poly_pred,'r')
print('MAE:', mean_absolute_error(test_poly_pred, y_test_confirmed))
print('MSE:',mean_squared_error(test_poly_pred, y_test_confirmed))
print('poly.score:', lin_reg_2.score(poly_reg.fit_transform(X_test_confirmed),y_test_confirmed))
print(test_poly_pred)
结果:拟合效果不错
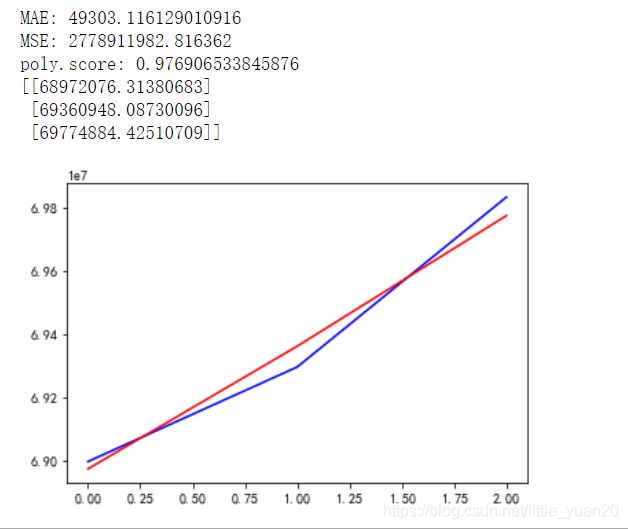
13.
岭回归
#岭回归
ridge =PolynomialFeatures(degree= 7)
X_ridge =ridge.fit_transform(X_train_confirmed)
clf =Ridge(alpha=0.001,fit_intercept=True)
clf.fit(X_ridge,y_train_confirmed)
test_ridge_pred = clf.predict(ridge.fit_transform(X_test_confirmed))
ridge_pred = clf.predict(ridge.fit_transform(future_forcast))
plt.plot(y_test_confirmed,'b')
plt.plot(test_ridge_pred,'r')
print('MAE:', mean_absolute_error(test_ridge_pred, y_test_confirmed))
print('MSE:',mean_squared_error(test_ridge_pred, y_test_confirmed))
print('CLF.score:', clf.score(ridge.fit_transform(X_test_confirmed),y_test_confirmed))
print(test_ridge_pred)
结果
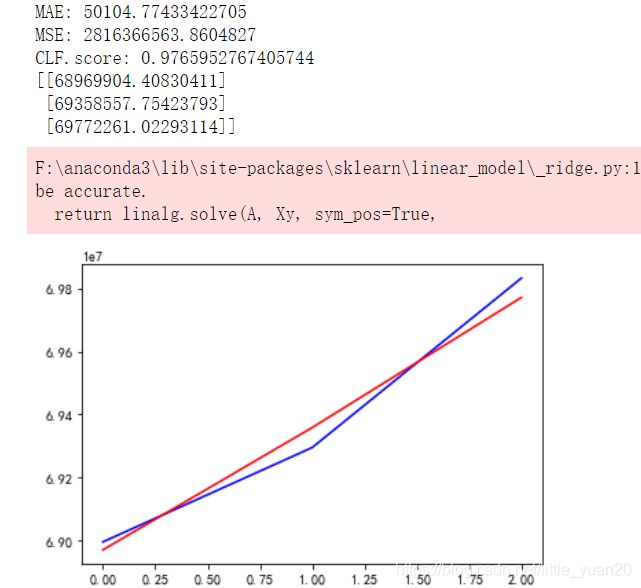
和多项式回归差不多.
14.
看一下源数据确诊人数的增长曲线
plt.figure(figsize=(20,8))
x = plt.plot(X_time.reshape(-1),world_cases.values.tolist())
plt.xlabel('Time in Days', size=20)
plt.ylabel('# confirmed Cases', size=20)
plt.xticks(rotation=50, size=10)
#plt.tight_layout()
plt.show()
结果

15.
看看各个模型的拟合效果和预测效果
plt.figure(figsize=(20,8))
plt.plot(X_time.reshape(-1), world_cases.values.tolist())
plt.plot(X_time.reshape(-1), svm_pred, linestyle='dashed')
plt.plot(X_time.reshape(-1), ensemble_pred, linestyle='dashed')
plt.plot(X_time.reshape(-1), linear_pred, linestyle='dashed')
plt.plot(X_time.reshape(-1), poly_pred, linestyle='dashed')
plt.plot(X_time.reshape(-1), ridge_pred, linestyle='dashed')
plt.title('#confirmed Coronavirus Cases Over Time', size=20)
plt.xlabel('Time in Days', size=20)
plt.ylabel('# confirmed Cases', size=20)
plt.legend(['Confirmed Cases', 'SVM predictions', 'Random Forest predictions', 'Linear Regression','Poly Linear Regression','Ridge Linear Regression'])
plt.xticks(rotation=50, size=10)
plt.show()
结果

16.
看一下死亡人数的曲线
total_deaths = deadCount.sum(axis=1)
#total_deaths
plt.figure(figsize=(20,8))
plt.plot(X_time.reshape(-1),total_deaths.values.tolist(), color='red')
plt.title('# Coronavirus Deaths Over Time', size=20)
plt.xlabel('Time', size=20)
plt.ylabel('# Deaths', size=20)
plt.xticks(rotation=50, size=10)
plt.show()

17.
看一下死亡人数比上确诊人数
mortality_rate = total_deaths / world_cases
mean_mortality_rate = np.mean(mortality_rate)
plt.figure(figsize=(20,8))
plt.plot(X_time.reshape(-1), mortality_rate, color='orange')
plt.axhline(y = mean_mortality_rate,linestyle='--', color='black')
plt.title('# Mortality Rate of Coronavirus Over Time', size=20)
plt.legend(['mortality rate', 'y='+str(mean_mortality_rate)])
plt.xlabel('Time', size=20)
plt.ylabel('# Mortality Rate', size=20)
plt.xticks(rotation=50, size=10)
plt.show()

18.
看一下治愈人数
total_recovered = curedCount.sum(axis=1)
#total_recovered
plt.figure(figsize=(20,8))
plt.plot(X_time.reshape(-1), total_recovered.values, color='green')
plt.title('# Coronavirus Cases Recovered Over Time', size=20)
plt.xlabel('Time', size=20)
plt.ylabel('# Recovered Cases', size=20)
plt.xticks(rotation=50, size=10)
plt.show()
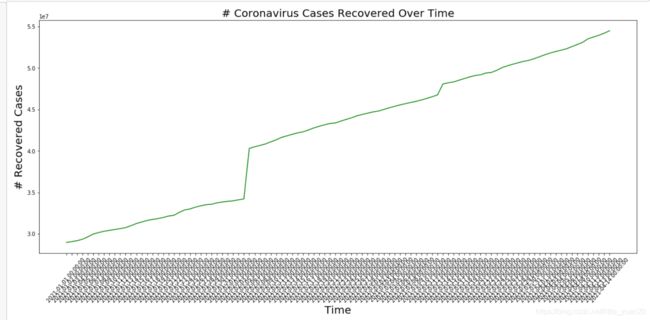
19.
死亡人数和治愈人数放在一块看一下
plt.figure(figsize=(20,8))
plt.plot(X_time.reshape(-1), total_deaths.values.tolist(), color='red')
plt.plot(X_time.reshape(-1), total_recovered.values.tolist(), color='green')
plt.legend(['death', 'recoveries'], loc='best', fontsize=20)
plt.title('# Coronavirus Cases', size=20)
plt.xlabel('Time', size=20)
plt.ylabel('# Cases', size=20)
plt.xticks(rotation=50, size=10)
plt.show()

20.
横坐标确诊人数,纵坐标死亡人数看一下。
plt.figure(figsize=(20, 6))
plt.plot(total_recovered, total_deaths)
plt.title('# of Coronavirus Deaths vs. # of Coronavirus Recoveries', size=30)
plt.xlabel('# of Coronavirus Recoveries', size=30)
plt.ylabel('# of Coronavirus Deaths', size=30)
plt.xticks(size=18)
plt.show()

21.
看一下10个国家确诊人数,死亡人数,治愈人数的对比
latest_confirmed = confirmedCount.iloc[-1]
latest_deaths = deadCount.iloc[-1]
latest_recoveries = curedCount.iloc[-1]
unique_countries = list(confirmedCount.keys())
country_confirmed_cases = []
no_cases = []
print('----confirmed----')
print(latest_confirmed)
print('----death----')
print(latest_deaths)
print('----recoveries----')
print(latest_recoveries)
外国与中国的确诊人数对比
outside_mainland_china_confirmed = 0
for i in nameList:
if i == '中国':
continue;
outside_mainland_china_confirmed += latest_confirmed[i]
plt.figure(figsize=(10, 8))
plt.barh(nameMap[nameList[0]], latest_confirmed[nameList[0]])
plt.barh('Outside Mainland China', outside_mainland_china_confirmed)
plt.title('# of Coronavirus Confirmed Cases')
plt.show()

23.
由于中国与其他国家差的太多,因此取log对比一下。
name = []
for i in nameList:
name.append(nameMap[i])
log_country_confirmed_cases = [math.log10(i) for i in latest_confirmed]
plt.figure(figsize=(8, 5))
plt.barh(name, log_country_confirmed_cases,height=0.5,alpha = 0.8)
plt.title('Common Log # of Coronavirus Confirmed Cases in Countries/Regions')
plt.xlabel('Log of # of Covid19 Confirmed Cases')
plt.tight_layout()
plt.show()

24.
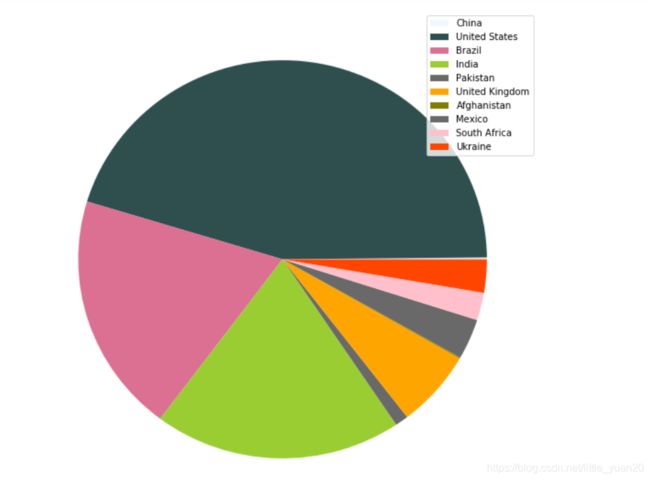
画一个饼图对比一下
c = random.choices(list(mcolors.CSS4_COLORS.values()),k = len(unique_countries))
plt.figure(figsize=(10,10))
plt.pie(latest_confirmed, colors=c)
plt.legend(name, loc='best')
plt.show()