【大数据】蔬菜价格分析(QDU)
- 【大数据】蔬菜价格分析(QDU)
- 【大数据】美国新冠肺炎疫情分析——错误版(QDU)
- 【大数据】美国新冠肺炎疫情分析——正确版(QDU)
- 【大数据】乳腺癌预测——老师给的链接(QDU)
- 由于kaggle上“猫狗大战”的测试集标签是错的,所以没做出来,用的github上的代码
- 【大数据】《红楼梦》作者分析(QDU)
问题分析
“蔬菜价格.xlsx”中记录中从2018年9月29号到2010年1月30日部分蔬菜和部分肉类的价格,其中涉及四十种蔬菜和二十三种肉类。
通过观察,并考虑到蔬菜与肉类合并成一类进行分析会使得事务总数过多,支持度会过低,缺乏合理性。因此采取对蔬菜和肉类分开进行关联性分析的方案,分别构建蔬菜价格信息表和肉类价格信息表,蔬菜间建立蔬菜关联规则,肉类间建立肉类关联规则。
对于同一日期中共同涨、跌的蔬菜或肉类分为一组,作为一组事务,而不对价格未发生变化的食品进行处理。对全部事务进行关联性分析后对具有关联性的组绘制价格曲线观察,并分析合理性。
解决思路

解决方案
读入数据
先将xls文件改成xlxs文件,使用xlrd库中的open_workbook函数打开文件并获取文件中的全部sheet,再对返回值调用sheets()[0]获取第一个sheet,即要处理的数据表格。
获取日期
之所以要获取日期列表,是因为在对食品价格波动进行分析时需要对相邻两日的价格做差得到价格差,将价格差作为分析价格波动重要指标。
遍历数据表格的第一列(对应列索引编号为0),对遍历到的日期数据使用datetime库中的datetime函数将单元格内容转换为日期并且添加至集合中,通过集合自动去重的功能得到无重复且乱序的全部日期。集合中的日期并不是按照添加的顺序排列的,因此需要调用sort函数将日期列表按照原始数据表格中的日期出现顺序排序,保证按顺序对应每日的价格信息。
得到的日期列表(部分)如下:
[datetime.datetime(2009, 6, 11, 0, 0),
datetime.datetime(2010, 1, 30, 0, 0),
datetime.datetime(2010, 1, 29, 0, 0),
datetime.datetime(2010, 1, 28, 0, 0),
datetime.datetime(2010, 1, 27, 0, 0),
...
datetime.datetime(2008, 10, 3, 0, 0),
datetime.datetime(2008, 10, 2, 0, 0),
datetime.datetime(2008, 10, 1, 0, 0),
datetime.datetime(2008, 9, 30, 0, 0),
datetime.datetime(2008, 9, 29, 0, 0)]
处理数据
对于蔬菜遍历原始数据表格中的第二、三列(对应列索引编号为1、2),对于肉类遍历原始数据表格中的第四、五列(对应列索引编号为3、4),以字典的形式保存食品名称和食品价格,其中以食品名称为键,以食品价格为值,目的是方便建立DataFrame。使用得到的以字典为项的列表进行去重、填充缺失值等操作后构建DataFrame,并将DataFrame的行索引设置为获取到的日期,返回最终的DataFrame。
-
存在的问题一:表格中存在不需要的处理的信息
对于不需要处理的信息比如许多文字:“日期”、“蔬菜名”、“肉食禽蛋”等均为非表格数据,无需进行统计。在遍历表格时需要对这类信息特殊判断,不加入表格数据。
-
数据存在的问题二:部分蔬菜和肉类在某些日期未统计价格
存在部分蔬菜和肉类在某些日期未统计价格,对于当某种食品的缺失数据多于设定的阈值时将此种食品从待分析的数据中排除。而对于未被排除的食品可能仍存在缺失值,我采用向前填充的方式将缺失值填充为后续最近日期的价格,这样可以有效地提高食品保留率并且尽可能地保证了保留食品价格的合理性。
-
数据存在的问题三:同一日期的价格信息重复统计
经过预处理和分析,发现2009年6月11日的食品价格统计过多次,因此在提取数据的基础上还需剔除个别数据。对于剩余的无重复数据,采用以日期为索引,以食品名称为列名,以价格为表中数据的方式保存食品价格变化信息,并以索引和价格分别为横纵坐标绘制各种食品的价格曲线,观察食品的价格变化曲线。
-
数据存在的问题四:区分每日的价格信息
由于每日的价格信息显示在一种表中且共用相同的列,因此需要对不同日期的数据进行分割。以连续空单元格的数量作为分割标准,当表中某行的名称和价格同时缺失时判断为空单元格,当空单元格连续出现大于1次时说明此处应两个日期数据的分界线。
-
数据存在的问题:空单元格
空单元格的判定标准不能单看其ctype属性是否为0,当单元格中的值为
'\u3000'时在表格中显示为空。
处理后的蔬菜(部分)价格信息表如下:
| 元葱 | 冬瓜 | 土豆 | 大头菜 | 大白菜 | 大蒜 | 尖椒 | 山药 | 油菜 | 生姜 | 胡萝卜 | 芋头 | 芸豆 | 芹菜 | 茄子 | 茭瓜 | 茼蒿 | 莴苣 | 菜花 | 菠菜 | 葱 | 蒜苔 | 藕 | 西红柿 | 豆芽 | 青椒 | 青萝卜 | 韭菜 | 香菜 | 鲜蘑菇 | 黄瓜 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2008-09-29 | 0.9 | 0.7 | 1.7 | 1.1 | 0.90 | 1.0 | 1.1 | 4.0 | 1.2 | 3.6 | 1.8 | 1.4 | 2.4 | 1.1 | 1.0 | 1.2 | 3.6 | 1.6 | 2.0 | 3.0 | 1.4 | 4.0 | 2.4 | 1.3 | 1.4 | 1.4 | 1.2 | 1.6 | 2.0 | 3.6 | 2.0 |
| 2008-09-30 | 0.9 | 0.7 | 0.7 | 1.1 | 0.90 | 1.0 | 1.1 | 4.0 | 1.0 | 3.6 | 1.8 | 1.4 | 2.6 | 1.1 | 1.0 | 1.2 | 3.6 | 1.6 | 1.8 | 4.0 | 1.6 | 4.0 | 2.4 | 1.4 | 1.4 | 1.7 | 1.2 | 1.6 | 2.4 | 3.6 | 2.4 |
| 2008-10-01 | 0.9 | 0.7 | 1.7 | 1.1 | 1.00 | 1.0 | 1.1 | 4.0 | 1.0 | 3.6 | 1.8 | 1.4 | 2.4 | 1.1 | 1.2 | 2.0 | 3.6 | 1.6 | 2.3 | 4.5 | 1.7 | 4.0 | 2.4 | 1.4 | 1.4 | 1.8 | 1.2 | 2.4 | 2.4 | 3.6 | 2.4 |
| 2008-10-02 | 0.8 | 0.7 | 1.6 | 1.1 | 1.00 | 1.2 | 1.1 | 4.0 | 1.0 | 3.0 | 1.4 | 1.2 | 2.2 | 1.1 | 1.4 | 1.5 | 4.2 | 1.6 | 2.0 | 4.0 | 1.7 | 4.0 | 2.4 | 1.4 | 1.4 | 1.7 | 1.2 | 1.6 | 2.4 | 5.0 | 2.4 |
| 2008-10-03 | 0.8 | 0.7 | 1.6 | 1.1 | 1.00 | 1.2 | 1.1 | 3.8 | 1.0 | 3.6 | 1.4 | 1.2 | 2.3 | 1.1 | 1.4 | 1.5 | 4.2 | 1.6 | 1.7 | 4.0 | 1.7 | 4.0 | 2.4 | 1.4 | 1.4 | 1.7 | 1.2 | 1.6 | 2.4 | 5.0 | 2.4 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 2010-01-26 | 2.2 | 1.2 | 2.2 | 1.8 | 1.30 | 8.0 | 4.2 | 6.0 | 4.4 | 7.0 | 1.6 | 3.0 | 3.7 | 2.5 | 4.0 | 3.3 | 3.2 | 1.6 | 2.4 | 4.4 | 2.0 | 8.0 | 3.0 | 3.4 | 1.4 | 4.2 | 0.8 | 4.0 | 4.0 | 4.0 | 3.8 |
| 2010-01-27 | 2.2 | 1.2 | 2.2 | 1.8 | 1.30 | 8.0 | 4.2 | 6.0 | 4.4 | 7.0 | 1.6 | 3.0 | 3.7 | 2.5 | 4.0 | 3.3 | 3.2 | 1.6 | 2.4 | 4.4 | 2.0 | 8.0 | 3.0 | 3.4 | 1.4 | 4.2 | 0.8 | 4.0 | 4.0 | 4.0 | 3.8 |
| 2010-01-28 | 2.2 | 1.2 | 2.2 | 1.8 | 1.40 | 8.0 | 4.2 | 6.0 | 4.4 | 7.0 | 1.6 | 3.0 | 3.8 | 2.4 | 4.8 | 3.3 | 4.0 | 1.6 | 2.2 | 4.4 | 2.0 | 8.0 | 3.0 | 3.4 | 1.4 | 4.2 | 0.8 | 4.5 | 4.0 | 4.0 | 3.4 |
| 2010-01-29 | 2.2 | 1.2 | 2.2 | 1.8 | 1.40 | 8.0 | 4.2 | 6.0 | 4.2 | 7.0 | 1.6 | 3.0 | 3.9 | 2.3 | 4.8 | 2.9 | 3.0 | 1.6 | 2.2 | 3.9 | 1.8 | 8.0 | 3.0 | 3.4 | 1.4 | 4.2 | 0.8 | 4.0 | 4.0 | 4.0 | 3.2 |
| 2010-01-30 | 2.2 | 1.2 | 2.2 | 1.8 | 1.40 | 8.0 | 4.2 | 6.0 | 4.2 | 7.0 | 1.6 | 3.0 | 3.9 | 2.3 | 4.8 | 2.8 | 3.0 | 1.6 | 2.2 | 3.9 | 1.8 | 8.0 | 3.0 | 3.4 | 1.4 | 4.2 | 0.8 | 4.0 | 4.0 | 4.0 | 3.2 |
处理后的肉类(部分)价格信息表如下:
| 猪口条 | 猪大排 | 猪大肠 | 猪心 | 猪肋排 | 猪肝 | 猪蹄 | 白条肉 | 精牛肉 | 精猪肉 | 精猪肚 | 羊肉片 | 翅中 | 翅根 | 西装鸡 | 鸡大腿 | 鸡心 | 鸡爪 | 鸡翅 | 鸡胸肉 | 鸡蛋 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2008-09-29 | 34.0 | 23.0 | 21.0 | 24.0 | 28.0 | 15.0 | 21.0 | 17.5 | 30.0 | 24.0 | 34.0 | 30.0 | 27.0 | 16.0 | 12.0 | 15.0 | 11.5 | 19.0 | 21.0 | 16.0 | 7.5 |
| 2008-09-30 | 34.0 | 23.0 | 21.0 | 24.0 | 28.0 | 15.0 | 21.0 | 17.5 | 30.0 | 24.0 | 34.0 | 30.0 | 27.0 | 16.0 | 12.0 | 15.0 | 11.5 | 19.0 | 21.0 | 16.0 | 7.5 |
| 2008-10-01 | 34.0 | 23.0 | 21.0 | 24.0 | 28.0 | 15.0 | 21.0 | 17.5 | 30.0 | 24.0 | 34.0 | 30.0 | 27.0 | 16.0 | 12.0 | 15.0 | 11.5 | 19.0 | 21.0 | 16.0 | 7.5 |
| 2008-10-02 | 34.0 | 23.0 | 21.0 | 24.0 | 28.0 | 15.0 | 21.0 | 17.5 | 30.0 | 24.0 | 34.0 | 30.0 | 27.0 | 16.0 | 12.0 | 15.0 | 11.5 | 19.0 | 21.0 | 16.0 | 7.0 |
| 2008-10-03 | 34.0 | 23.0 | 21.0 | 24.0 | 28.0 | 15.0 | 21.0 | 17.5 | 30.0 | 24.0 | 34.0 | 30.0 | 27.0 | 16.0 | 12.0 | 15.0 | 11.5 | 19.0 | 21.0 | 16.0 | 7.0 |
| 2008-10-04 | 34.0 | 23.0 | 21.0 | 24.0 | 28.0 | 15.0 | 21.0 | 17.5 | 30.0 | 24.0 | 34.0 | 30.0 | 27.0 | 16.0 | 12.0 | 15.0 | 11.5 | 19.0 | 21.0 | 16.0 | 7.0 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 2010-01-26 | 29.0 | 19.0 | 22.0 | 18.0 | 28.0 | 9.0 | 17.0 | 18.0 | 30.0 | 18.0 | 30.0 | 36.0 | 29.0 | 15.0 | 11.0 | 15.0 | 11.0 | 17.0 | 20.0 | 15.0 | 6.9 |
| 2010-01-27 | 29.0 | 19.0 | 22.0 | 18.0 | 28.0 | 9.0 | 17.0 | 18.0 | 30.0 | 18.0 | 30.0 | 36.0 | 29.0 | 15.0 | 11.0 | 15.0 | 11.0 | 17.0 | 20.0 | 15.0 | 6.9 |
| 2010-01-28 | 33.0 | 19.0 | 22.0 | 18.0 | 30.0 | 8.0 | 18.0 | 17.0 | 31.0 | 19.0 | 32.0 | 32.0 | 28.0 | 15.0 | 11.0 | 14.0 | 10.0 | 17.0 | 20.0 | 14.5 | 6.9 |
| 2010-01-29 | 33.0 | 19.0 | 22.0 | 18.0 | 30.0 | 8.0 | 18.0 | 17.0 | 31.0 | 19.0 | 32.0 | 32.0 | 28.0 | 15.0 | 11.0 | 14.0 | 10.0 | 17.0 | 20.0 | 14.5 | 6.9 |
| 2010-01-30 | 33.0 | 19.0 | 22.0 | 18.0 | 30.0 | 8.0 | 18.0 | 17.0 | 31.0 | 19.0 | 32.0 | 32.0 | 28.0 | 15.0 | 11.0 | 14.0 | 10.0 | 17.0 | 20.0 | 14.5 | 6.9 |
价格曲线
两幅图像,一幅为全部蔬菜或肉类的价格曲线,以范围从2018年9月29号到2010年1月30日的日期为横坐标,食品价格作为纵坐标将全部蔬菜或肉类的价格变化绘制于一张图上;另一幅,通过算法实现将一个figure按照食品种类数划分为行数与列数尽量相等的若干子图,每幅子图显示一组蔬菜或肉类的价格变化,由于一张图中显示全部食品的价格曲线过于混乱观察效果不佳,因此采用分组显示全部食品价格曲线的方式。
此部分存在的问题大多为绘图的细节问题,子图的分割和位置、标题的显示、中文乱码、横坐标日期的显示、图例位置和信息等问题。
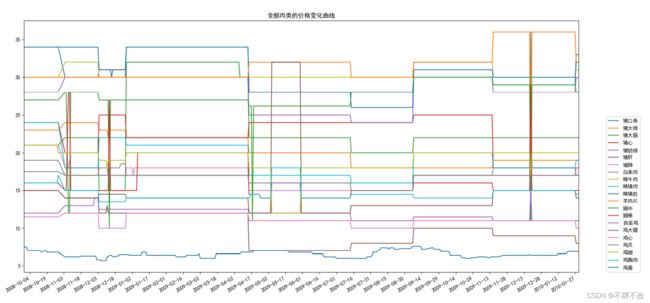
全部蔬菜的价格变化曲线如下:

全部肉类的价格变化曲线如下:
分组后全部蔬菜的价格变化曲线如下:
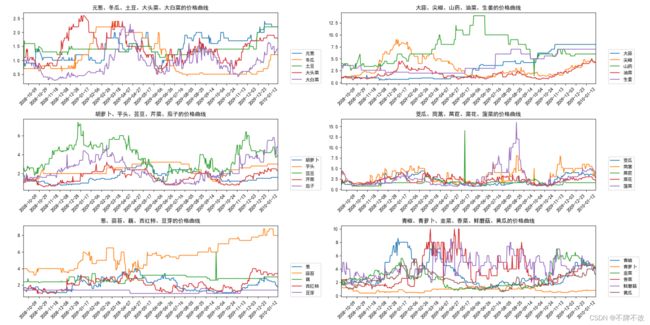
分组后全部肉类的价格变化曲线如下:
关联规则
对“机器学习实战”的“验证26-Apriori算法及实现”一节中的Apriori算法进行了部分修改后直接调用。
经过多次调参,最终将“蔬菜”关联规则的支持度设置为 0.1 0.1 0.1,可信度设置为 0.4 0.4 0.4和 0.5 0.5 0.5,“肉类”关联规则的支持度设置为 0.2 0.2 0.2,可信度设置为 0.7 0.7 0.7和 0.8 0.8 0.8,但是绘图时只显示可信度较高对应的关联组的价格曲线,输出会显示全部信息。
对loadDataSet函数的修改: 得到的DataFrame数据不可以直接用作数据分析,需要先对表格数据进行按列做差,得到涨跌数据,对于涨的均赋值为 1 1 1,对于跌的均赋值为 − 1 -1 −1,对于未发生价格变动的赋值为 0 0 0。分别获得每一行(即同日期)中同涨或同跌的食品的列索引(即食品种类对应的索引),将其划分为一个事务,并加入到事务列表中,返回事务列表。
对calcConf函数的修改: 通过列表推导式得到每组关联关系中索引对应的食品名称,将原先显示索引之间的关联关系转换为显示食品名称之间的关联关系,更加直观。
定义main函数用于调用生成关联规则的相关子函数: 此函数主要是调用Apriori核心函数,并将一些之前用索引表示的换成用名称表示,这部分代码的书写用到大量的嵌套列表推导式,这样的好处是减少循环降低复杂度并且代码简短。
对蔬菜进行关联分析得到的输出如下:
-----------------------蔬菜类 -----------------------
数据集总共包含事务总数: 667
候选集C1:
['元葱', '冬瓜', '土豆', '大头菜', '大白菜', '大蒜', '尖椒', '山药', '油菜', '生姜', '胡萝卜', '芋头', '芸豆', '芹菜', '茄子', '茭瓜', '茼蒿', '莴苣', '菜花', '菠菜', '葱', '蒜苔', '藕', '西红柿', '豆芽', '青椒', '青萝卜', '韭菜', '香菜', '鲜蘑菇', '黄瓜']
满足最小支持度为0.1的频繁项集列表L:
[['香菜', '尖椒', '蒜苔', '茄子', '芹菜', '大头菜', '鲜蘑菇', '西红柿', '葱', '大白菜', '黄瓜', '茼蒿', '韭菜', '青椒', '菠菜', '茭瓜', '芸豆', '胡萝卜', '元葱', '菜花', '油菜'], ['菜花', '大头菜', '油菜', '芸豆', '油菜', '菠菜', '菜花', '大白菜', '大白菜', '芸豆', '菠菜', '大白菜', '大头菜', '大白菜', '芸豆', '茄子', '芸豆', '尖椒', '青椒', '尖椒', '菠菜', '大头菜', '茼蒿', '菠菜', '菠菜', '黄瓜', '菜花', '芸豆', '菠菜', '芸豆', '菠菜', '韭菜'], []]
满足最小可信度为0.4的规则列表为:
(大头菜) --> (菜花) 可信度为: 0.3872832369942196
(菜花) --> (大头菜) 可信度为: 0.33668341708542715
(芸豆) --> (油菜) 可信度为: 0.3819095477386935
(油菜) --> (芸豆) 可信度为: 0.44705882352941173
(菠菜) --> (油菜) 可信度为: 0.3838383838383838
(油菜) --> (菠菜) 可信度为: 0.44705882352941173
(大白菜) --> (菜花) 可信度为: 0.36548223350253806
(菜花) --> (大白菜) 可信度为: 0.3618090452261307
(芸豆) --> (大白菜) 可信度为: 0.33668341708542715
(大白菜) --> (芸豆) 可信度为: 0.3401015228426396
(大白菜) --> (菠菜) 可信度为: 0.3401015228426396
(菠菜) --> (大白菜) 可信度为: 0.3383838383838384
(大白菜) --> (大头菜) 可信度为: 0.4213197969543147
(大头菜) --> (大白菜) 可信度为: 0.4797687861271676
(茄子) --> (芸豆) 可信度为: 0.41666666666666663
(芸豆) --> (茄子) 可信度为: 0.3768844221105528
(尖椒) --> (芸豆) 可信度为: 0.39655172413793105
(芸豆) --> (尖椒) 可信度为: 0.34673366834170855
(尖椒) --> (青椒) 可信度为: 0.5057471264367817
(青椒) --> (尖椒) 可信度为: 0.5365853658536586
(大头菜) --> (菠菜) 可信度为: 0.3872832369942196
(菠菜) --> (大头菜) 可信度为: 0.3383838383838384
(菠菜) --> (茼蒿) 可信度为: 0.38888888888888895
(茼蒿) --> (菠菜) 可信度为: 0.48125
(黄瓜) --> (菠菜) 可信度为: 0.3709677419354838
(菠菜) --> (黄瓜) 可信度为: 0.3484848484848485
(芸豆) --> (菜花) 可信度为: 0.407035175879397
(菜花) --> (芸豆) 可信度为: 0.407035175879397
(芸豆) --> (菠菜) 可信度为: 0.3768844221105528
(菠菜) --> (芸豆) 可信度为: 0.3787878787878788
(韭菜) --> (菠菜) 可信度为: 0.4276729559748428
(菠菜) --> (韭菜) 可信度为: 0.3434343434343434
满足最小可信度为0.5的规则列表为:
(尖椒) --> (青椒) 可信度为: 0.5057471264367817
(青椒) --> (尖椒) 可信度为: 0.5365853658536586
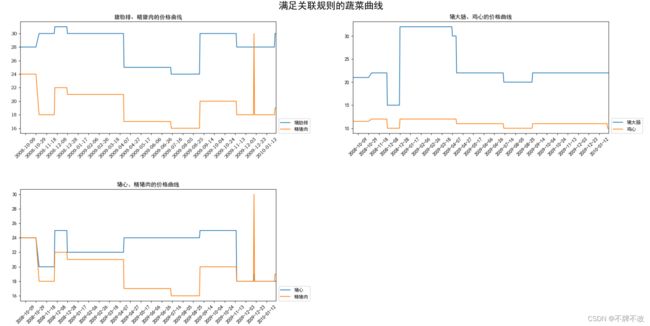
[['尖椒', '青椒']]
绘制蔬菜中关联性较强的价格曲线图:

对肉类进行关联分析得到的输出如下:
数据集总共包含事务总数: 29
候选集C1:
['猪口条', '猪大排', '猪大肠', '猪心', '猪肋排', '猪肝', '猪蹄', '白条肉', '精牛肉', '精猪肉', '精猪肚', '羊肉片', '翅中', '翅根', '西装鸡', '鸡大腿', '鸡心', '鸡爪', '鸡翅', '鸡胸肉', '鸡蛋']
满足最小支持度为0.2的频繁项集列表L:
[['羊肉片', '猪肋排', '鸡翅', '鸡心', '西装鸡', '翅中', '精猪肚', '精牛肉', '猪大肠', '猪大排', '鸡胸肉', '鸡爪', '鸡大腿', '翅根', '精猪肉', '白条肉', '猪蹄', '猪肝', '猪心', '猪口条'], ['精猪肉', '西装鸡', '翅根', '西装鸡', '鸡爪', '鸡翅', '精猪肉', '猪肋排', '翅中', '猪肝', '精牛肉', '翅中', '鸡心', '猪大肠', '猪心', '白条肉', '精猪肉', '猪心', '精猪肉', '白条肉', '翅根', '白条肉', '精猪肉', '翅根', '白条肉', '鸡大腿', '精猪肉', '鸡大腿', '翅根', '鸡大腿', '鸡胸肉', '鸡大腿'], ['精猪肉', '鸡大腿', '白条肉', '精猪肉', '猪心', '白条肉'], []]
满足最小可信度为0.7的规则列表为:
(茄子) --> (生姜) 可信度为: 0.6
(生姜) --> (茄子) 可信度为: 0.6
(茄子) --> (芹菜) 可信度为: 0.7
(芹菜) --> (茄子) 可信度为: 0.5833333333333334
(菜花) --> (莴苣) 可信度为: 0.75
(莴苣) --> (菜花) 可信度为: 0.75
(大白菜) --> (生姜) 可信度为: 0.875
(生姜) --> (大白菜) 可信度为: 0.7
(大蒜) --> (芸豆) 可信度为: 0.6666666666666666
(芸豆) --> (大蒜) 可信度为: 0.6
(芸豆) --> (油菜) 可信度为: 0.6
(油菜) --> (芸豆) 可信度为: 0.8571428571428571
(土豆) --> (茼蒿) 可信度为: 1.0
(茼蒿) --> (土豆) 可信度为: 0.8571428571428571
(山药) --> (大头菜) 可信度为: 0.5454545454545455
(大头菜) --> (山药) 可信度为: 0.75
(大头菜) --> (生姜) 可信度为: 0.875
(生姜) --> (大头菜) 可信度为: 0.7
(山药) --> (生姜) 可信度为: 0.6363636363636365
(生姜) --> (山药) 可信度为: 0.7
(山药) --> (芹菜) 可信度为: 0.5454545454545455
(芹菜) --> (山药) 可信度为: 0.5
(芹菜) --> (生姜) 可信度为: 0.5
(生姜) --> (芹菜) 可信度为: 0.6
(茭瓜) --> (山药) 可信度为: 0.7272727272727273
(山药) --> (茭瓜) 可信度为: 0.7272727272727273
(茭瓜) --> (生姜) 可信度为: 0.5454545454545455
(生姜) --> (茭瓜) 可信度为: 0.6
(茭瓜) --> (芹菜) 可信度为: 0.6363636363636365
(芹菜) --> (茭瓜) 可信度为: 0.5833333333333334
(茭瓜) --> (菠菜) 可信度为: 0.5454545454545455
(菠菜) --> (茭瓜) 可信度为: 0.6666666666666666
(山药) --> (生姜,茭瓜) 可信度为: 0.5454545454545455
(茭瓜) --> (生姜,山药) 可信度为: 0.5454545454545455
(生姜) --> (山药,茭瓜) 可信度为: 0.6
(山药) --> (生姜,大头菜) 可信度为: 0.5454545454545455
(大头菜) --> (生姜,山药) 可信度为: 0.75
(生姜) --> (大头菜,山药) 可信度为: 0.6
满足最小可信度为0.8的规则列表为:
(大白菜) --> (生姜) 可信度为: 0.875
(油菜) --> (芸豆) 可信度为: 0.8571428571428571
(土豆) --> (茼蒿) 可信度为: 1.0
(茼蒿) --> (土豆) 可信度为: 0.8571428571428571
(大头菜) --> (生姜) 可信度为: 0.875
[['猪肋排', '精猪肉'], ['猪大肠', '鸡心'], ['猪心', '精猪肉']]
绘制肉类中关联性较强的价格曲线图:

结果分析
根据每组中两种食品的同涨同跌率(即”同幅变化次数/总日期数“)和对应的散点图观察关联性强弱。
蔬菜中满足关联规则的蔬菜的同涨同跌率如下:

满足关联规则的蔬菜的同增幅率如下:
"尖椒" 和 "青椒" 的同增同减率: 0.6744186046511628
肉类中满足关联规则的肉类的同涨同跌率如下:

满足关联规则的肉类的同增幅率如下:
"猪肋排" 和 "精猪肉" 的同增同减率: 0.9936575052854123
"猪大肠" 和 "鸡心" 的同增同减率: 0.9957716701902748
"猪心" 和 "精猪肉" 的同增同减率: 0.9936575052854123
分析:
蔬菜的价格关联性可参考性比较高,因为数据波动比较明显,更容易确定关联性,而由于肉类的价格波动次数较少,所以同幅变化率高,参考意义不如蔬菜价格的关联性强。不过,两种不同的食品都不波动在一定程度上说明二者的关联性。总体而言,关联性较好,合理性较高。
总结展望
局限性
-
“最小支持度”设置的较低
当将“最小支持度”设置的较高时会出现无解的情况,初步确定主要原因是事务总数过多,一种情况出现的次数又相对较少,导致支持度比较低,不过可信度的值是可以接受的。
-
未对“蔬菜“和”肉类“相关联
在蔬菜间和肉类间进行了关联性分析,对于两类不同食品间的关联性分析没有完整且合理的思路。最开始想到的是遍历两类食品,在两类中各取一种食品比较价格起伏,但是觉得可信度较低,并未采用。
-
只考虑价格起伏,未考虑价格起伏程度
在进行关联性分析时,只将是否同起同伏作为是否具有关联性的唯一指标,而未将起伏程度作为指标,因此具有一定的不客观性。
展望
- 尝试采用更优质的建模方式,建立更佳的关联方式,有效提高最小支持度
- 将两类食品间的价格起伏抽象成事务,并对其进行关联性分析
- 添加更多关联性指标作为关联性分析的评判标准,使模型更加合理
附录(代码)
getAlldates.py
功能:获取时间序列
参数:excel的sheet变量
返回值:表格中第一列时间列表
from datetime import datetime
from xlrd import xldate_as_tuple
def getAlldates(table):
"获取全部的日期,并且是按出现顺序保存"
date_set = set()
date_index = []
for date_val in table.col_values(0):
try: # 当遍历到空单元格时会报错,try防止报错终止
date = datetime(*xldate_as_tuple(date_val, 0)) # 转为datatime类型 # xldate_as_tuple函数的第一个参数为单元格,第二个参数为日期格式
date_index.append(date)
date_set.add(date)
except:
continue
alldates = list(date_set)
alldates.sort(key=date_index.index) # 集合元素的顺序与插入元素顺序无关,因此需要将集合按原列表中的顺序排序
return alldates
getDataFrame.py
功能:数据处理,以DataFrame的形式分别获得蔬菜数据和肉类数据
参数:excel的sheet变量;对蔬菜数据操作还是对肉类数据操作,为1表示操作蔬菜否则操作肉类;时间序列
返回值:以时间序列为行索引,以食品名称为列索引,以价格为数据的DataFrame
import numpy as np
from pandas import Series, DataFrame
def getDataFrame(table, vegetable_meat, alldates):
"函数功能:创建蔬菜类或肉类的价格表格 table:整张excel表 vegetable_meat:0、1分别表示对蔬菜类或肉类进行数据处理 alldates:对应的时间列表 "
t = 1 if vegetable_meat == 0 else 3 # 控制被操作的列号 # 如果对蔬菜操作t=1,如果对肉操作t=3
# 获取DataFrame
i = 0
data_final = [] # 存储最终肉类组/蔬菜组的信息(包括名称和价格)
while i < table.nrows: # table.nrows 有效行数
data_list = []
cnt = 0 # 只有当连续出现的空单元数大于1时才开始一个新的分组
while True:
if cnt > 1:
break
if (table.cell(i, t).ctype == 0) | (table.cell(i, t).value == '\u3000'): # 当单元格为无效内容时 # 当单元格内容为"\u3000"或者ctype=0时表示空的
cnt = cnt + 1
elif (table.cell(i, t+1).ctype != 2): # 非数字,都直接pass
cnt = 0
pass
else:
cnt = 0
data_list.append((table.cell(i, t).value, table.cell(i, t+1).value))
i = i + 1
if i >= table.nrows: # 防止越界报错
break
i = i + 1
if len(data_list) > 0:
data_dict = dict(data_list)
data_final.append(data_dict)
data_final.pop(233) # 第234组数据与第1组数据一样,去重
dataframe = DataFrame(data_final, index=alldates) # 以日期为索引创建DataFrame
number_nan = dataframe.isnull().sum() # 按列统计Nan数量
threshold_value = 0.2 # 当缺失数据多于20%,则舍去此列
columns = dataframe.columns.values.tolist() # 获取全部列名列表
array_delete = np.where(np.array(list(number_nan)) > threshold_value * len(alldates)) # 保存要被删除的列的索引
array_delete = array_delete[0].tolist() # 被删除列的索引组成的列表
drop_columns_name = [columns[idx] for idx in array_delete] # 保存被删除列的名称
dataframe = dataframe.drop(drop_columns_name, axis=1) # 丢弃对应的列
dataframe = dataframe.sort_index(ascending=True) # 按日期升序排序
dataframe.fillna(method='bfill', inplace=True) # Nan值用后一天的价格填充
return dataframe
getFigure.py
getRowColumnNUmber()
功能:划分的子图的行数与列数尽量相等
参数:总组数
返回值:子图的行数和列数
getFigure()
功能:绘制两幅图,分别是全部蔬菜或肉类的价格曲线图和分组后的蔬菜或肉类的价格曲线图
参数:对蔬菜数据操作还是对肉类数据操作,为1表示操作蔬菜否则操作肉类;数据对应的DataFrame表格
返回值:无
import math
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from datetime import datetime
def getRowColumnNUmber(group_nummber):
# 将这些子图尽可能行列相同,且使得行列尽量只差 1
subplot_row_number = int(math.sqrt(group_nummber))
subplot_col_number = int(math.sqrt(group_nummber))
while subplot_col_number * subplot_row_number < group_nummber:
subplot_row_number = subplot_row_number + 1
if subplot_col_number * subplot_row_number >= group_nummber:
break
subplot_col_number = subplot_col_number + 1
return subplot_row_number, subplot_col_number
def getFigure(vegetable_meat, dataframe):
dataframe_index = dataframe.index
dataframe_column = dataframe.columns
dataframe_column_list = dataframe_column.tolist()
fig_vegetable = plt.figure(figsize=(20, 10)) # 全部蔬菜的价格曲线
plt.xlim([datetime(2008, 9, 29), datetime(2010, 1, 30)]) # 日期范围
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) # 日期格式
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=15)) # 日期间隔
fig_vegetable.autofmt_xdate() # 斜的日期标签
for idx in dataframe_column_list: # 遍历列名
eachcolumn = dataframe.loc[:, idx].tolist()
plt.plot(dataframe_index, eachcolumn) # x轴是日期,y轴是价格
plt.rcParams['font.sans-serif'] = 'SimHei' # 使图形中的中文正常编码显示
plt.rcParams['axes.unicode_minus'] = False # 使坐标轴刻度表签正常显示正负号
plt.title('全部' + ('蔬菜' if vegetable_meat == 0 else '肉类') + '的价格变化曲线')
plt.legend(bbox_to_anchor=(1.05, 0), loc=3, borderaxespad=0,
labels=dataframe_column_list) # 设置标签显示的信息和位置 labels:设置图标名称
# 每个子图显示至少step条曲线
step = 5 if vegetable_meat == 0 else 3
dataframe_after_group_2Dlist = [dataframe.iloc[:, i:i + step] for i in
range(0, len(dataframe_column_list), step)] # 以step为组内数量进行分组
dataframe_column_list_after_group = [dataframe_column_list[i:i + step] for i in
range(0, len(dataframe_column_list), step)] # 列名也要分组
group_nummber = len(dataframe_after_group_2Dlist)
lastgroup_column_number = dataframe_after_group_2Dlist[group_nummber - 1].shape[1] # 如果最后一组的曲线过少,则与前一组合并
if (lastgroup_column_number != step) & (lastgroup_column_number < 0.5 * step) & (group_nummber > 1):
dataframe_after_group_2Dlist[group_nummber - 2] = pd.concat(
[dataframe_after_group_2Dlist[group_nummber - 2],
dataframe_after_group_2Dlist[group_nummber - 1]], axis=1)
dataframe_column_list_after_group[group_nummber - 2].extend(
dataframe_column_list_after_group[group_nummber - 1])
dataframe_after_group_2Dlist.pop(group_nummber - 1)
dataframe_column_list_after_group.pop(group_nummber - 1)
group_nummber = group_nummber - 1
subplot_row_number, subplot_col_number = getRowColumnNUmber(group_nummber)
plt.figure(figsize=(30, 20)) # 分组显示价格变化曲线
for i in range(group_nummber): # 遍历每个子图
eachgroup = dataframe_after_group_2Dlist[i] # 每一组(DataFrame类型)
plt.subplot(subplot_row_number, subplot_col_number, i + 1)
plt.xlim([datetime(2008, 9, 29), datetime(2010, 1, 30)]) # 日期范围
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) # 日期格式
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=20)) # 日期间隔
plt.xticks(rotation=45) # x轴文字旋转45°
plt.tight_layout() # 默认间隔 # 让子图紧贴边
plt.subplots_adjust(left=0.03, bottom=0.1, right=0.92, top=0.96, wspace=0.25 if vegetable_meat == 0 else 0.3,
hspace=0.5) # 设置子图位置 # left和bottom控制左下角子图的左下角位置,right和top控制右上角子图右上角的位置,wspace控制子图间的水平间隔,hspace控制子图间的垂直间隔
plt.rcParams['font.family'] = ['SimHei'] # legend不支持中文,此句设置显示中文
for j in range(eachgroup.shape[1]): # eachgroup.shape[1]为该组的列数
eachcolumn = eachgroup.iloc[:, j] # 得到价格数据
plt.plot(dataframe_index, eachcolumn)
plt.title('、'.join(dataframe_column_list_after_group[i]) + '的价格曲线')
plt.legend(bbox_to_anchor=(1.05, 0), loc=3, borderaxespad=0, labels=dataframe_column_list_after_group[i])
plt.show()
return
getAnalysisFigure.py
功能:绘制满足关联规则的食品组对应的价格曲线
参数:对蔬菜数据操作还是对肉类数据操作,为1表示操作蔬菜否则操作肉类;每组的食品名称;数据对应的DataFrame表格
返回值:无
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from datetime import datetime
from resultAnalysis import resultAnalysis
from getFigure import getRowColumnNUmber
def getAnalysisFigure(vegetable_meat, data, dataframe):
dataframe_index = dataframe.index
subplot_row_number, subplot_col_number = getRowColumnNUmber(len(data))
plt.figure(figsize=(30, 20)) # 分组显示价格变化曲线
for i in range(len(data)): # 遍历每个子图
eachgroup = data[i] # 每一组两个字符串
plt.subplot(subplot_row_number, subplot_col_number, i + 1)
plt.xlim([datetime(2008, 9, 29), datetime(2010, 1, 30)]) # 日期范围
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) # 日期格式
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=20)) # 日期间隔
plt.xticks(rotation=45) # x轴文字旋转45°
plt.tight_layout() # 默认间隔 # 让子图紧贴边
plt.subplots_adjust(left=0.03, bottom=0.1, right=0.92, top=0.92, wspace=0.3 if vegetable_meat == 0 else 0.3,
hspace=0.5) # 设置子图位置 # left和bottom控制左下角子图的左下角位置,right和top控制右上角子图右上角的位置,wspace控制子图间的水平间隔,hspace控制子图间的垂直间隔
plt.rcParams['font.sans-serif'] = 'SimHei' # 使图形中的中文正常编码显示
plt.rcParams['font.family'] = ['SimHei'] # legend不支持中文,此句设置显示中文
for j in eachgroup: # eachgroup.shape[1]为该组的列数
eachcolumn = dataframe.loc[:, j] # 得到价格数据
plt.plot(dataframe_index, eachcolumn)
plt.title('、'.join(data[i]) + '的价格曲线')
plt.legend(bbox_to_anchor=(1.01, 0), loc=3, borderaxespad=0, labels=eachgroup)
plt.suptitle('满足关联规则的' + ('蔬菜' if vegetable_meat == 0 else '肉类') + '曲线', fontsize = 20)
# plt.show()
resultAnalysis(vegetable_meat, dataframe, data, subplot_row_number, subplot_col_number) # 绘制结果分析曲线
return
myapriori.py
功能:生成关联规则
import numpy as np
import UnionCode
"""
函数说明:处理数据并加载数据集
"""
def loadDataSet(dataframe):
dataframe = dataframe.values
diff_array = np.diff(dataframe, axis = 0)
diff_array[diff_array < 0] = -1 # 跌
diff_array[diff_array > 0] = 1 # 涨
diff_array[diff_array == 0] = 0 # 未变
x_lt, y_lt = np.where(diff_array < 0)
x_lt = x_lt.tolist()
y_lt = y_lt.tolist()
x_gt, y_gt = np.where(diff_array > 0)
x_gt = x_gt.tolist()
y_gt = y_gt.tolist()
# x_eq, y_eq = np.where(diff_array == 0)
data = []
idx_lt = 0
for i in range(diff_array.shape[0]):
eachdata = []
while idx_lt < len(x_lt):
if x_lt[idx_lt] == i:
eachdata.append(y_lt[idx_lt])
else:
break
idx_lt = idx_lt + 1
if len(eachdata) > 0:
data.append(eachdata)
idx_gt = 0
for i in range(diff_array.shape[0]):
eachdata = []
while idx_gt < len(x_gt):
if x_gt[idx_gt] == i:
eachdata.append(y_gt[idx_gt])
else:
break
idx_gt = idx_gt + 1
if len(eachdata) > 0:
data.append(eachdata)
# 去掉一天中只存在一种蔬菜涨跌的组,这可以去除无效事务总数,有效地减少事务总数
return_data = []
for item in data:
if len(item) <= 1:
continue
else:
return_data.append(item)
return return_data
"""
函数说明:构建集合C1。即所有候选项元素的集合。
parameters:
dataSet -数据集
return:
frozenset列表
output:
[forzenset([1]),forzenset([2]),……]
"""
def createC1(dataSet):
C1 = [] #创建一个空列表
for transaction in dataSet: #对于数据集中的每条记录
for item in transaction: #对于每条记录中的每一个项
if not [item] in C1: #如果该项不在C1中,则添加
C1.append([item])
C1.sort() #对集合元素排序
return list(map(frozenset,C1)) #将C1的每个单元列表元素映射到forzenset() #frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素
"""
函数说明:构建符合支持度的集合Lk
parameters:
D -数据集
Ck -候选项集列表
minSupport -感兴趣项集的最小支持度
return:
retList -符合支持度的频繁项集合列表L
supportData -最频繁项集的支持度
"""
def scanD(D,Ck,minSupport):
ssCnt = {} #创建空字典
for tid in D: #遍历数据集中的所有交易记录
for can in Ck: #遍历Ck中的所有候选集
if can.issubset(tid): #判断can是否是tid的子集
if not can in ssCnt: ssCnt[can] = 1 #如果是记录的一部分,增加字典中对应的计数值。
else: ssCnt[can] += 1
numItems = float(len(D)) #得到数据集中交易记录的条数 #转换成float是为了后面除法
retList = [] #新建空列表
supportData = {} #新建空字典用来存储最频繁集和支持度
for key in ssCnt: #for循环遍历字典默认遍历key值;遍历dir.values()可以实现遍历值
support = ssCnt[key] / numItems #计算每个元素的支持度
if support >= minSupport: #如果大于最小支持度则添加到retList中
retList.insert(0,key) #首插法
supportData[key] = support #并记录当前支持度,索引值即为元素值
return retList,supportData
"""
函数说明:apriori算法实现
parameters:
dataSet -数据集
minSupport -最小支持度
return:
L -候选项集的列表
supportData -项集支持度
"""
def apriori(dataSet, minSupport=0.5):
C1 = createC1(dataSet)
D = list(map(set, dataSet)) # 将数据集转化为集合列表
L1, supportData = scanD(D, C1, minSupport) # 调用scanD()函数,过滤不符合支持度的候选项集
L = [L1] # 将过滤后的L1放入L列表中
k = 2 # 最开始为单个项的候选集,需要多个元素组合
while (len(L[k - 2]) > 0):
Ck = aprioriGen(L[k - 2], k) # 创建Ck
Lk, supK = scanD(D, Ck, minSupport) # 由Ck得到Lk
supportData.update(supK) # 更新支持度
L.append(Lk) # 将Lk放入L列表中
k += 1 # 继续生成L3,L4....
return L, supportData
"""
函数说明:构建集合Ck
parameters:
Lk -频繁项集列表L
k -候选集的列表中元素项的个数
return:
retList -候选集项列表Ck
"""
def aprioriGen(Lk, k):
retList = [] # 创建一个空列表
lenLk = len(Lk) # 得到当前频繁项集合列表中元素的个数
for i in range(lenLk): # 遍历所有频繁项集合
for j in range(i + 1, lenLk): # 比较Lk中的每两个元素,用两个for循环实现
L1 = list(Lk[i])[:k - 2];
L2 = list(Lk[j])[:k - 2] # 取该频繁项集合的前k-2个项进行比较
# [注]此处比较了集合的前面k-2个元素,需要说明原因
L1.sort();
L2.sort() # 对列表进行排序
if L1 == L2: # 对应位置的元素全部相等
retList.append(Lk[i] | Lk[j]) # 使用集合的合并操作来完成 e.g.:[0,1],[0,2]->[0,1,2]
return retList
"""
函数说明:关联规则生成函数
parameters:
L -频繁项集合列表
supportData -支持度字典
minConf -最小可信度
return:
bigRuleList -包含可信度的规则列表
"""
def generateRules(vegetable_meat, L, supportData, minConf=0.7):
bigRuleList = [] # 创建一个空列表
for i in range(1, len(L)): # 遍历频繁项集合列表
for freqSet in L[i]: # 遍历频繁项集合
H1 = [frozenset([item]) for item in freqSet] # 为每个频繁项集合创建只包含单个元素集合的列表H1
if (i > 1): # 要从包含两个或者更多元素的项集开始规则构建过程
rulesFromConseq(vegetable_meat, freqSet, H1, supportData, bigRuleList, minConf)
else: # 如果项集中只有两个元素,则计算可信度值,(len(L)=2)
calcConf(vegetable_meat, freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
"""
函数说明:规则构建函数
parameters:
freqSet -频繁项集合
H -可以出现在规则右部的元素列表
supportData -支持度字典
brl -规则列表
minConf -最小可信度
return:
null
"""
def rulesFromConseq(vegetable_meat, freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0]) # 得到H中的频繁集大小m
if (len(freqSet) > (m + 1)): # 查看该频繁集是否大到可以移除大小为m的子集
Hmp1 = aprioriGen(H, m + 1) # 构建候选集Hm+1,Hmp1中包含所有可能的规则
Hmp1 = calcConf(vegetable_meat, freqSet, Hmp1, supportData, brl, minConf) # 测试可信度以确定规则是否满足要求
if (len(Hmp1) > 1): # 如果不止一条规则满足要求,使用函数迭代判断是否能进一步组合这些规则
rulesFromConseq(vegetable_meat, freqSet, Hmp1, supportData, brl, minConf)
"""
函数说明:计算规则的可信度,找到满足最小可信度要求的规则
parameters:
freqSet -频繁项集合
H -可以出现在规则右部的元素列表
supportData -支持度字典
brl -规则列表
minConf -最小可信度
return:
prunedH -满足要求的规则列表
"""
# def calcConf(freqSet, H, supportData, brl, minConf=0.7):
# prunedH = [] # 为保存满足要求的规则创建一个空列表
# for conseq in H:
# conf = supportData[freqSet] / supportData[freqSet - conseq] # 可信度计算[support(PUH)/support(P)]
# if conf >= minConf:
# print(freqSet - conseq, '-->', conseq, '可信度为:', conf)
# brl.append((freqSet - conseq, conseq, conf)) # 对bigRuleList列表进行填充
# prunedH.append(conseq) # 将满足要求的规则添加到规则列表
# return prunedH
def calcConf(vegetable_meat, freqSet, H, supportData, brl, minConf=0.7):
nameSet = UnionCode.vegetable_list if vegetable_meat == 0 else UnionCode.meat_list
prunedH = [] # 为保存满足要求的规则创建一个空列表
for conseq in H:
conf = supportData[freqSet] / supportData[freqSet - conseq] # 可信度计算[support(PUH)/support(P)]
if conf >= minConf:
nameSet_1 = [nameSet[idx] for idx in freqSet - conseq]
nameSet_2 = [nameSet[idx] for idx in conseq]
print('(' + ','.join(nameSet_1) + ')', '-->', '(' + ','.join(nameSet_2) + ')', '可信度为:', conf) # 对源代码进行修改。显示蔬菜或肉类的名称
brl.append((freqSet - conseq, conseq, conf)) # 对bigRuleList列表进行填充
prunedH.append(conseq) # 将满足要求的规则添加到规则列表
return prunedH
resultAnalysis.py
功能:绘制同涨同跌散点图,用于观察关联关系是否合理
参数:对蔬菜数据操作还是对肉类数据操作,为1表示操作蔬菜否则操作肉类;数据对应的DataFrame表格;每组的食品名称;子图行数;子图列数
返回值:无
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from datetime import datetime
def resultAnalysis(vegetable_meat, dataframe, data, subplot_row_number, subplot_col_number):
plt.figure(figsize=(30, 20)) # 分组显示价格变化曲线
for i in range(len(data)): # 遍历每个子图
eachgroup = data[i] # 每一组两个字符串
plt.subplot(subplot_row_number, subplot_col_number, i + 1)
plt.xlim([0, dataframe.index.shape[0]-2])
plt.yticks(range(0,2,1), ['同幅度变化', '不同幅变化','']) # 重要! # 不仅可以控制y轴变化为整数,且可以更换为字符串
# plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) # 日期格式
# plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=20)) # 日期间隔
# plt.xticks(rotation=45) # x轴文字旋转45°
plt.tight_layout() # 默认间隔 # 让子图紧贴边
plt.subplots_adjust(left=0.06, bottom=0.1, right=0.92, top=0.92, wspace=0.3 if vegetable_meat == 0 else 0.3,
hspace=0.5) # 设置子图位置 # left和bottom控制左下角子图的左下角位置,right和top控制右上角子图右上角的位置,wspace控制子图间的水平间隔,hspace控制子图间的垂直间隔
plt.rcParams['font.sans-serif'] = ['STZhongsong'] # 使图形中的中文正常编码显示
plt.rcParams['font.family'] = ['SimHei'] # legend不支持中文,此句设置显示中文
plt.rcParams['axes.unicode_minus'] = False
bool_araay0 = np.diff(dataframe.loc[:, eachgroup[0]].values, axis=0)
bool_araay0[bool_araay0 < 0] = -1 # 跌
bool_araay0[bool_araay0 > 0] = 1 # 涨
bool_araay0[bool_araay0 == 0] = 0 # 未变
bool_araay1= np.diff(dataframe.loc[:, eachgroup[1]].values, axis=0)
bool_araay1[bool_araay1 < 0] = -1 # 跌
bool_araay1[bool_araay1 > 0] = 1 # 涨
bool_araay1[bool_araay1 == 0] = 0 # 未变
bool_araay = (bool_araay0 == bool_araay1)
array = np.ones(bool_araay.shape)
array[bool_araay] = 0
array[~bool_araay] = 1
y = [int(i) for i in array]
x1 = np.where(bool_araay)[0].tolist() # np.where的返回值太坑了!!!
x2 = np.where(~bool_araay)[0].tolist()
y1 = [0*int(i) for i in np.ones(len(x1)).tolist()]
y2 = [int(i) for i in np.ones(len(x2)).tolist()]
print(' "' + eachgroup[0] + '" 和 "' + eachgroup[1] + '" 的同增同减率:', len(y1)/(len(y1)+len(y2)))
plt.scatter(x1, y1, marker='o', s=6, color='g')
plt.scatter(x2, y2, marker='*', s=6, color = 'r')
plt.title('、'.join(data[i]) + '的价格曲线')
plt.show()
return
UnionCode.py
功能:从此运行,显示关联规则等信息
参数:无
返回值:无
使用方式:“曲线绘制”部分的被注释掉的部分分别用于显示全部食品价格曲线图和分组后的全部食品价格曲线图;“_main_”中的两个函数调用是用于显示满足关联规则的食品的价格曲线以及效果分析图
import xlrd # 对excel文件操作的模块
import pandas as pd
from getFigure import getFigure
from getAlldates import getAlldates
from getDataFrame import getDataFrame
from getAnalysisFigure import getAnalysisFigure
# ---------------------------------------数据读入-------------------------------------------
original_data = xlrd.open_workbook(r'C:\Users\23343\Desktop\蔬菜价格.xlsx') # 打开文件
table = original_data.sheets()[0]
# -------------------------------------获取时间列表------------------------------------------
alldates = getAlldates(table)
# ------------------------------------数据处理成表格-----------------------------------------
vegetable_dataframe = getDataFrame(table, 0, alldates) # 蔬菜
meat_dataframe = getDataFrame(table, 1, alldates) # 肉类
vegetable_list = vegetable_dataframe.columns.values.tolist()
meat_list = meat_dataframe.columns.values.tolist()
# 下面两句代码在jupyter中能比较好的显示出表格
# pd.set_option('display.max_columns', 100)
# pd.set_option('display.width', 500)
# ----------------------------------------曲线绘图------------------------------------------
# getFigure(0, vegetable_dataframe) # 蔬菜
# getFigure(1, meat_dataframe) # 肉类
# -----------------------------得到规则并绘制相关价格曲线观察效果-------------------------------
def main(vegetable_meat, dataframe):
from myapriori import loadDataSet, createC1, apriori, generateRules # 在if __name__ == '__main__':中导入可以解决两个包相互引用的问题
print('-----------------------' + ('蔬菜' if vegetable_meat == 0 else '肉') + '类 -----------------------')
dataSet = loadDataSet(dataframe)
minsuppose = 0.1 if vegetable_meat == 0 else 0.2
minconfidence = 0.5 if vegetable_meat == 0 else 0.8
nameSet = vegetable_list if vegetable_meat == 0 else meat_list
print("数据集总共包含事务总数:", len(dataSet))
name_dataSet = [[nameSet[idx] for idx in dataSet[i]] for i in range(len(dataSet))] # 将数据集的数字转换成对应的蔬菜或肉类名称
print("数据集:\n", name_dataSet)
C1 = createC1(dataSet)
name_C1 = [nameSet[idx] for item in C1 for idx in item] # 将C1中的数字转换为对应的名称
print("候选集C1:\n", name_C1)
L, suppData = apriori(dataSet, minsuppose)
name_L = [[nameSet[idx] for fro in L[i] for idx in fro] for i in range(len(L))] # 将L中的数字转换为对应的名称 # 注意对frozenset也要遍历一遍,因此是三重循环
print("满足最小支持度为" + str(minsuppose) + "的频繁项集列表L:\n", name_L)
print("满足最小可信度为"+ str(round(minconfidence-0.1, 1)) + "的规则列表为:")
vegetable_rules = generateRules(0, L, suppData, minconfidence-1)
# 不绘制此曲线了
# vegetable_rules2strlist = [[vegetablenameSet[idx] for i in range(2) for idx in item[i]] for item in vegetable_rules]
# vegetable_rules2strlist = [vegetable_rules2strlist[i] for i in range(0, len(vegetable_rules2strlist), 2)] # A->B 与 B->A 算一个,为了后续方便画图
# print(vegetable_rules2strlist)
# getAnalysisFigure(0, vegetable_rules2strlist, vegetable_dataframe)
print("满足最小可信度为" + str(minconfidence) + "的规则列表为:")
rules = generateRules(0, L, suppData, minconfidence)
rules2strlist = [[nameSet[idx] for i in range(2) for idx in item[i]] for item in rules]
rules2strlist = [rules2strlist[i] for i in range(0, len(rules2strlist), 2)] # A->B 与 B->A 算一个,为了后续方便画图
print(rules2strlist)
getAnalysisFigure(0, rules2strlist, dataframe)
return
if __name__ == '__main__':
main(0, vegetable_dataframe) # 蔬菜
# main(1, meat_dataframe) # 肉类