知识图谱-生物信息学-医学顶刊论文(Briefings in Bioinformatics-2021):MPG:一种有效的自我监督框架,用于学习药物分子的全局表示以进行药物发现
6.(2021.9.14)Briefings-MPG:一种有效的自我监督框架,用于学习药物分子的全局表示以进行药物发现
论文标题:An effective self-supervised framework for learning expressive molecular global representations to drug discovery
论文期刊:Briefings in Bioinformatics 2021
论文地址:https://www.researchgate.net/profile/Jun-Wang-8/publication/351297761_An_effective_self-supervised_framework_for_learning_expressive_molecular_global_representations_to_drug_discovery/links/61ee73719a753545e2f2a50b/An-effective-self-supervised-framework-for-learning-expressive-molecular-global-representations-to-drug-discovery.pdf
文章思路(2个工作):
-
有监督数据获取太麻烦 ⟹ \Longrightarrow ⟹ 无监督数据 ⟹ \Longrightarrow ⟹ 基于批量的正/负样本生成进行对比判别计算代价太大,难以用于大规模数据集,但大规模数据集预训练是必要的 ⟹ \Longrightarrow ⟹ 要高效 ⟹ \Longrightarrow ⟹ MolGNet:用Transformer表示分子结构图,并在FFN之后加了个GRU作为节点更新函数。
-
现有的针对大规模数据集的自监督预训练方法都集中在节点层面的表示,无全局的语义结构信息 ⟹ \Longrightarrow ⟹ 加入图层面的图自监督策略 ⟹ \Longrightarrow ⟹ **成对半图判别(PHD):将分子结构图分解成两个半图,这两个半图中的一个有0.5的概率被与来自另一个无关图的半图所代替,这个图就被当作负样本,否则就是正样本。然后让模型预测各半图对中的半图是不是来自同一分子结构图。**SWS
- 6.(2021.9.14)Briefings-MPG:一种有效的自我监督框架,用于学习表达分子全局表示以进行药物发现.pdf
- 摘要
- 1.引言
- 2.方法
- 2.1 MPG框架概述
- 2.1.1 MolGNet概述
- 2.1.2 自监督策略概述
- 2.2 MolGNet模型
- 2.2.1 邻居注意力模块
- 2.2.2 前馈神经网络
- 2.2.3 顶点更新函数
- 2.3 PHD策略
- 2.3.1 图的分解和负采样
- 2.3.2 虚拟集合节点
- 2.3.3 输入表示
- 2.1 MPG框架概述
摘要
如何生成具有表达性的分子表示是人工智能驱动药物研发的一个根本挑战。图神经网络(GNN)已经成为一种强大的分子数据建模技术。然而,以往的监督方法通常存在有标签数据稀缺和泛化能力差的问题。在此,我们提出了一种新的基于分子预训练图的深度学习框架MPG,该框架从大规模的未标记分子中学习分子表示。在MPG中,我们提出了一种用于分子图建模的强大GNN模型–MolGNet,并设计了一种有效的自监督策略在节点和图层面对模型进行预训练。在对1100万个未标记分子进行预训练后,我们发现MolGNet可以捕获有价值的化学信息,从而产生可解释的表示。经过预先训练的MolGNet可以通过一个额外的输出层进行微调,在14个基准数据集上为广泛的药物发现任务创建最先进的模型,包括分子特性预测、药物-药物相互作用(DDI)和药物-靶点相互作用(DTI)。在MPG中预先训练的MolGNet有潜力成为药物发现过程中的优秀分子编码器。
1.引言
药物发现是一项复杂的系统工程,从发明到上市在实践中是一个漫长的旅程。同时,由于生物系统的复杂性和大量实验,药物发现容易失败,而且十分昂贵。为了解决这些问题,许多研究人员在早期临床前研究的不同阶段提出了各种计算机辅助药物发现(CADD)方法,用于从Hit识别和选择、Hit-to-Lead优化到临床候选药物。尽管在辅助药物发现方面取得了成功,但许多基于分子模拟技术的传统CADD方法存在计算量大、程序费时的问题,限制了其在制药行业的应用。
人工智能(AI)和药物发现之间的跨学科研究因其优越的速度和性能而受到越来越多的关注。许多人工智能技术已经成功地应用于药物发现的各种任务中,如分子性质预测、DDI和DTI预测。这些研究的基本挑战之一是如何从分子结构中学习表达形式。在早期,分子表示是基于人工制作的特征,如分子描述符或指纹。大多数传统的机器学习方法都是围绕着这些分子表示的特征工程进行的。
相比之下,人们对通过深度神经网络学习的分子表示感兴趣,从拟合原始输入到特定的任务相关目标。近年来,在极具潜力的深度学习体系结构中,以消息传递神经网络(MPNN)为代表的图神经网络(GNN)逐渐成为分子数据建模的有力候选者。由于分子自然是由通过化学键(边)连接的原子(节点)组成的图形,因此它非常适合GNN。到目前为止,研究者们提出了各种GNN结构,并在药物发现方面取得了很大的进展。然而,有一些限制需要解决。分子表示中深度学习的挑战主要来自于标记数据的稀缺,因为实验室实验既昂贵又耗时。因此,药物发现中的训练数据集通常在大小上是有限的,所以在这上面训练的GNN往往会过拟合,导致学习的表示缺乏泛化能力。
减轻对大型标记数据集的需求的一种方法是通过自监督学习在未标记的数据上预先训练模型,然后将学习的模型转移到下游任务。这些方法已经得到了广泛的应用,并在计算机视觉(CV)和自然语言处理(NLP)方面取得了巨大的突破,如BERT。最近的一些工作已经使用自我监督学习来在简化的分子结构图(SMILES)上预训练语言模型来学习分子表征,例如通过将SMILES视为序列来预训练BERT,以及在重构的SMILES上预训练自动编码器。最近,由于GNN的优越性能,一些研究人员开始研究分子图数据的预训练策略。然而,由于分子图的拓扑结构多变,图数据往往比图像和文本数据更复杂,这给直接采用自监督学习方法处理分子图带来了挑战。如今,一些研究人员也开始利用对比学习来表示图数据,并在无监督图学习方面取得最先进的性能。然而,大多数算法,如Infoggraph,通常采用基于批量的正/负样本生成进行对比判别,这带来了巨大的计算代价,不适合在大规模数据集上进行预训练,而大规模数据集对于预训练是必不可少的。受语言模型的启发,已经提出了一些简单的针对大规模数据集的自监督预训练方法,如Ngram、AttrM、ConextPredict和MotifPredict。然而,这些方法主要集中在节点层面的表示学习,而不是显式地学习全局图的表示,导致图层面的任务(例如分子分类)的收益有限。此外,有人已经证明,只带有图层面策略或节点层面策略其中一种的预训练GNN模型给出的改进有限,有时会导致许多下游任务的负迁移。因此,在节点层面策略的基础上开发一种高效的图自监督策略是必要的。
针对上述问题,我们提出了一种新的基于MPG的深度学习框架MPG。在MPG中,我们首先开发了一种新的GNN,它集成了MPNN和Transformer的强大能力来学习分子表示,称为MolGNet。更重要的是,我们提出了一种概念简单但使用起来强大的图自监督策略–成对半图判别法(PHD)。我们将PHD和AttrMating结合起来,在节点和图形级别联合预训练我们的MolGNet模型。在对1100万个未标记分子进行预训练MolGNet后,我们首先调查了我们在MPG中的模型学到了什么。我们发现,预先训练的MolGNet可以捕获有意义的分子模式,包括分子支架和一些量子属性,以生成可解释和可表达的表示。此外,我们进行了广泛的实验,以评估我们的MPG在广泛的药物发现任务(包括分子性质预测、DTI和DDI)中的性能。物品们使用了14个广泛使用的数据集,实验结果表明,我们的MPG在多个药物发现任务上提升了最先进的性能,显示了MPG的巨大容量和通用性。综上所述,我们的MPG从大规模的非标记分子中学习有意义和有表达的分子表示,为自监督学习在药物发现过程中的应用奠定了基础。
2.方法
2.1 MPG框架概述
实现MPG框架的关键有两个方面:一是设计一个能够从分子结构中获取有价值信息的强大模型;二是提出一种有效的自我监督策略来预训练模型。我们将在MPG中介绍MolGNet模型和预训练策略(参见图1)。
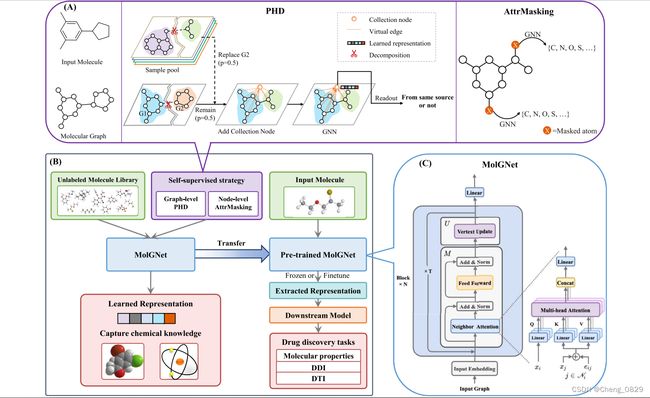
图1.MPG框架概述。
图1的左下子图(B)说明了MPG框架的工作流程,MPG框架包括两个关键组件——MolGNet和自我监督策略;MolGNet的架构如右下子图©所示;顶部子图(A)说明了我们的自我监督策略的方案,包括我们提出的PHD和用于预训练GNN模型的AttrMasking。
2.1.1 MolGNet概述
除了 U \mathbf{U} U(GRU)之外,其余的几乎和Transformer的编码器结构一致
如图1©所示,MolGNet由 N = 5 N=5 N=5个相同块的堆叠而成;每个层重复执行 T = 3 T=3 T=3次的共享消息传递操作(即时间步为3的序列网络),以使用更少的参数实现更大的接受域。每个时间步 t t t的消息传递操作包含消息计算函数 M \mathbf{M} M和顶点更新函数 U \mathbf{U} U,其中 M \mathbf{M} M聚集邻居的信息并且 U \mathbf{U} U使用聚集的信息来更新节点的状态。形式上,这两个组件根据消息传递机制依次工作以更新每个节点的隐藏状态 x i t x^t_i xit:
m i t = M ( { x i t − 1 , x j t − 1 , e i j } , j ∈ N i ) (1) m_i^t=\mathbf{M}\left(\left\{x_i^{t-1}, x_j^{t-1}, e_{i j}\right\}, j \in \mathcal{N}_i\right) \tag{1} mit=M({xit−1,xjt−1,eij},j∈Ni)(1)
x i t = U ( h i t − 1 , m i t ) (2) x_i^t=\mathbf{U}\left(h_i^{t-1}, m_i^t\right) \tag{2} xit=U(hit−1,mit)(2)
其中, N i \mathcal{N}_i Ni表示节点 i i i的邻居, e i j e_{ij} eij表示节点 i i i和节点 j j j之间的边,顶点更新函数 U \mathbf{U} U是一个门控循环单元(GRU)网络, h i t − 1 h^{t−1}_i hit−1是 U \mathbf{U} U的隐藏状态, h i 0 h^0_i hi0是初始原子表示 x i 0 x^0_i xi0。具体地说, M \mathbf{M} M有两个子层。第一个子层执行我们提出的邻居注意力模块(即多头注意力),用于从邻居节点和边缘提取信息,第二个子层是一个全连接前馈网络。我们在两个子层的每个子层周围使用残差连接,以避免过度平滑问题,随后是层标准化(LayerNorm)。为了便于残差连接,模型中的所有子层都生成d=768维的输出。有关MolGNet组件的更多详细信息可以在下一节中找到。
过度平滑(over-smoothing)是图神经网络(GNN)中经常出现的一个问题,即在GNN的训练过程中,随着网络层数的增加和迭代次数的增加,每个节点的隐含层表示会趋向于收敛到同一个值,即梯度消失。
2.1.2 自监督策略概述
化学中的大多数任务(例如,分子性质预测)依赖于固有的全局分子特征。然而,就我们所知,目前针对大规模分子图的预训练策略主要集中在节点层面的表示学习。在这里,我们提出了一种自监督的预训练策略,称为PHD,它在图层面显式地预训练GNN。受对比学习的启发,PHD策略的关键思想如图1(A)所示,是学习比较两个半图(每个半图从一个图样本中分解),并区分它们是否来自相同的来源(二进制分类)。如果我们假设来自同一来源的两个半图可以组合成一个有效的分子,而来自不同来源的两个半图不能,那么PHD就是通过组合两个半图来识别分子的有效性,这可能会教会网络捕捉一些分子的固有模式。特别是,在GNN的消息传递的基础上,我们采用了一个称为集合节点的虚拟节点来整合两个半图的信息。集合节点的表示作为给定的两个半图的全局表示,学习通过最大似然估计来预测两个半图是否来自同一来源。为了更好地执行PHD任务,需要学习的集合节点表示对能够区分半图对之间的相似性和差异性的全局信息进行编码。此外,我们将我们的PHD策略与最近提出的节点级策略AttrMasking相结合进行联合预训练,以充分利用结构图信息并避免负迁移。简而言之,AttrMasking用于预测被掩蔽的节点的类型,如图1(A)所示。在接下来的部分中,我们首先介绍了MolGNet的基本组件,然后详细描述了自监督策略PHD。

图1(A):MPG中的自我监督策略的方案,包括我们提出的PHD和用于预训练GNN模型的AttrMasking。
2.2 MolGNet模型
MolGNet由三个关键组件组成:图关注力模块、前馈网络和顶点更新功能。我们将在下面详细说明这三个组成部分。
2.2.1 邻居注意力模块
在时间步 t t t输入到邻居注意模块的是一组原子表示 x = { x 1 t − 1 , ⋯ , x N t − 1 } , x 1 t − 1 ∈ R d \boldsymbol{x}=\{x_1^{\mathrm{t}-1},\cdots,x_N^{\mathrm{t}-1}\},\mathrm{x}_1^{\mathrm{t}-1}\in\mathbb{R}^d x={x1t−1,⋯,xNt−1},x1t−1∈Rd和一组连接表示 e = { ⋯ , e i , j , ⋯ } , e i , j ∈ R d \boldsymbol{e}=\{\cdots,e_{i,j},\cdots \},e_{i,j}\in \mathbb{R}^d e={⋯,ei,j,⋯},ei,j∈Rd。该模块捕获原子与其邻居(包括其邻居原子和邻居边)之间的交互信息,以生成每个节点的消息表示 m = { m 1 t , ⋯ , m N t } , m i t ∈ R d \boldsymbol{m}=\{m_1^{\mathrm{t}},\cdots,m_N^{\mathrm{t}}\},\mathrm{m}_i^{\mathrm{t}}\in\mathbb{R}^d m={m1t,⋯,mNt},mit∈Rd。
对于每个原子 i i i,邻居注意力模块首先将原子 i i i的邻居原子表示 x j t x_j^t xjt与它们之间的边的连接表示 e i , j e_{i,j} ei,j相加,以表示相邻信息 I j t I_j^t Ijt,即:
I j t = x j t − 1 + e i , j (3) I_j^t=x_j^{t-1}+e_{i,j} \tag{3} Ijt=xjt−1+ei,j(3)
给定相邻信息和原子表示,该模块对原子执行Scaled Dot-Product attention–一个用于计算注意力得分的共享注意力机制。形式上,我们首先将节点 x i t x_i^t xit的原子表示映射到查询 q i t q_i^t qit,并将其相邻信息 i j t i_j^t ijt分别映射到键 K j t K_j^t Kjt和值 V j t V_j^t Vjt,计算公式如下:
Q i t = W q x i t − 1 (4) Q_i^t=W_q \boldsymbol{x}_i^{t-1} \tag{4} Qit=Wqxit−1(4)
K j t = W k I j t (5) K_j^t=W_k \boldsymbol{I}_j^t \tag{5} Kjt=WkIjt(5)
V j t = W v I j t (6) V_j^t=W_v \boldsymbol{I}_j^t \tag{6} Vjt=WvIjt(6)
其中, W k \mathrm{W}_{\mathrm{k}} Wk、 W q \mathrm{W}_q Wq和 W v \mathrm{W}_v Wv是原子表示的可学习权重矩阵, Q i t Q_i^t Qit和 K j t K_j^t Kjt的维度是 d k d_k dk,而 V j t V_j^t Vjt的维度是 d d d。我们计算查询 Q i t Q_i^t Qit和键 K j t K_j^t Kjt的点积 s i , j t s_{i,j}^t si,jt,以表明相邻信息对节点 i i i的重要性。为了避免点积结果变得很大,我们将点积按 1 d k \frac{1}{\sqrt{d_k}} dk1进行缩放,即"Scaled"。即:
s i , j t = Q i t K j t T d k (7) s_{i,j}^t=\frac{Q_i^t K_j^{t^T}}{\sqrt{d_k}} \tag{7} si,jt=dkQitKjtT(7)
为了使系数在不同节点之间易于比较,我们使用softmax函数对所有 j j j选项进行归一化:
a i , j t = softmax ( s i , j t ) = e s i , j t ∑ j ∈ N i e s i , j t (8) a_{i,j}^t=\operatorname{softmax}(s_{i,j}^t)=\frac{e^{s_{i,j}^t}}{\sum_{j\in\mathcal{N}_i}e^{s_{i,j}^t}} \tag{8} ai,jt=softmax(si,jt)=∑j∈Niesi,jtesi,jt(8)
其中, N i \mathcal{N}_i Ni代表节点 i i i的邻居。
获得相邻节点的重要性,即注意力之后,将归一化的注意力系数 a i , j t a^t_{i,j} ai,jt与邻居值 V j V_j Vj一起用于应用到加权求和运算,以导出每个节点的消息表示 m i t m^t_i mit:
m i t = ∑ j ∈ N i a i , j t V j t (9) m_i^t=\sum_{j \in \mathcal{N}_i} a^t_{i,j} V^t_j \tag{9} mit=j∈Ni∑ai,jtVjt(9)
邻居注意力模块还采用多头注意力机制来稳定自注意力的学习过程,即 K K K个独立的注意力机制相互执行公式(9)的变换,然后将它们的特征连接起来,输入线性变换,产生如下输出表示:
m i t = W m ∥ k K ∑ j ∈ N i a i , j t , k V j t , k (10) m_i^t=W_m \|_k^K \sum_{j \in \mathcal{N}_i} a_{i, j}^{t, k} V_j^{t, k} \tag{10} mit=Wm∥kKj∈Ni∑ai,jt,kVjt,k(10)
其中 ∥ \| ∥表示串联, a i , j t , k a_{i, j}^{t, k} ai,jt,k是由第k个注意力机制计算的归一化后的注意力系数, V j t , k V_j^{t, k} Vjt,k是对应的邻居的值, W m W_m Wm是在所有节点上共享的可学习权重矩阵。
2.2.2 前馈神经网络
为了提取消息的深层表示,增加模型的表达能力,我们将邻居注意力模块提取的消息表示反馈到一个全连接前馈网络中。该网络由两个线性变换组成,其间有一个高斯误差线性单元(GELU)作为激活函数。
m i t = W 2 σ ( W 1 m i t + b 1 ) + b 2 (10) \mathrm{m}_i^{\mathrm{t}}=\mathrm{W}_2 \sigma\left(\mathrm{W}_1 m_i^{\mathrm{t}}+b_1\right)+b_2 \tag{10} mit=W2σ(W1mit+b1)+b2(10)
其中 W 1 ∈ R d f f × d W_1\in\mathbb{R}^{d_{ff}\times d} W1∈Rdff×d和 W 2 ∈ R d × d f f W_2\in\mathbb{R}^{d\times d_{ff}} W2∈Rd×dff是可学习的权重矩阵, σ \sigma σ是激活函数GELU。在我们的实验中,维度 d f f = 3072 , d = 768 d_{ff}=3072,d=768 dff=3072,d=768,即第一个全连接层把矩阵从768维放大到3072维,第二个全连接层又缩小到768维。
2.2.3 顶点更新函数
基于邻居消息 m i t m_i^t mit,模型MolGNet使用GRU网络来更新原子的表示 x i t x_i^t xit,其计算如下:
r i t = sigmoid ( W m r m i t + b m r + W x r h i t − 1 + b h r ) (12) r_i^{\mathrm{t}}=\operatorname{sigmoid}\left(\mathrm{W}_{m r} m_i^{\mathrm{t}}+b_{m r}+\mathrm{W}_{\mathrm{xr}} h_i^{\mathrm{t}-1}+b_{h r}\right) \tag{12} rit=sigmoid(Wmrmit+bmr+Wxrhit−1+bhr)(12)
u i t = sigmoid ( W m u m i t + b m u + W x u h i t − 1 + b h u ) (13) u_i^{\mathrm{t}}=\operatorname{sigmoid}\left(\mathrm{W}_{m u} m_i^{\mathrm{t}}+b_{m u}+\mathrm{W}_{\mathrm{xu}} h_i^{\mathrm{t}-1}+b_{h u}\right) \tag{13} uit=sigmoid(Wmumit+bmu+Wxuhit−1+bhu)(13)
x i t = tanh ( W i n m i t + b i n + r i t ∗ ( W h n h i t − 1 + b h n ) ) (14) x_i^{\mathrm{t}}=\tanh \left(\mathrm{W}_{i n} m_i^{\mathrm{t}}+b_{i n}+r_i^{\mathrm{t}} *\left(\mathrm{~W}_{h n} h_i^{\mathrm{t}-1}+b_{h n}\right)\right) \tag{14} xit=tanh(Winmit+bin+rit∗( Whnhit−1+bhn))(14)
h i t = ( 1 − u i t ) ∗ x i t − 1 + u i t ∗ x i t (15) h_i^{\mathrm{t}}=\left(1-u_i^{\mathrm{t}}\right) \ast x_i^{\mathrm{t}-1}+u_i^{\mathrm{t}} \ast x_i^{\mathrm{t}} \tag{15} hit=(1−uit)∗xit−1+uit∗xit(15)
其中, h i t h_i^{\mathrm{t}} hit是原子 i i i在GRU的时间 t t t的隐藏状态, h i t − 1 h_i^{\mathrm{t-1}} hit−1是在时间 t − 1 t−1 t−1的隐藏状态,初始隐藏状态 h i 0 h_i^{\mathrm{0}} hi0是原子表示 x i 0 x_i^{\mathrm{0}} xi0, r i t r_i^{\mathrm{t}} rit和 u i t u_i^{\mathrm{t}} uit分别是重置门和更新门。 ∗ \ast ∗是哈达玛乘积。
2.3 PHD策略

图1(A):MPG中的自我监督策略的方案,包括我们提出的PHD和用于预训练GNN模型的AttrMasking。
成对半图判别法(Pairwise Half-graph Discrimination, PHD)。简单地说,PHD任务的目的是区分两个半图是否来自同一来源。如图1(A)所示,首先将图分解成两个半图,这两个半图中的一个有0.5的概率被与来自另一个无关图的半图所代替,这个图就被当作负样本,否则就是正样本。我们使用交叉熵损失函数代替噪声对比估计(NCE)来进行简单计算,以优化网络参数:
L = − ∑ i = 1 m y log ( p ) + ( 1 − y ) log ( 1 − p ) (16) L=-\sum^m_{i=1}y\operatorname{log}(p)+(1-y)\operatorname{log}(1-p) \tag{16} L=−i=1∑mylog(p)+(1−y)log(1−p)(16)
其中m是样本数。经过预训练后,集合节点嵌入可以被看作是图层面的图表示,并用于下游任务。此外,图的表示也可以通过平均节点嵌入或其他的全局图池化方法来获得。
在接下来的部分中,我们将详细描述PHD的重要组成部分。
2.3.1 图的分解和负采样
我们将图分解成两个半图,作为正样本的半图对,其中一个半图有0.5的概率被替换其中一个半图以产生负样本。如图2所示,给定一个图 G = ( V , E ) G=(V,E) G=(V,E),其中 V V V代表节点, E E E代表边。使用采样节点 v 3 v_3 v3作为边界节点,将 G G G分成两个半图 G s , 1 G_{s,1} Gs,1和 G s , 2 G_{s,2} Gs,2,其中 G s , 1 G_{s,1} Gs,1包含节点 v 0 , v 1 , v 2 {v_0,v_1,v_2} v0,v1,v2, G s , 2 G_{s,2} Gs,2包含节点 v 3 , v 4 , v 5 , v 6 , , v 7 {v_3,v_4,v_5,v_6,,v_7} v3,v4,v5,v6,,v7。这两个半图中的边分别对应于邻接矩阵的左上方子矩阵和右下方子矩阵。为了产生大小不同且均衡的半图,在总节点数的1/3到2/3范围内随机抽样边界节点索引。
对于负抽样,我们随机抽样数据集中的另一个图,并使用上述方法将其分离为两个半图,并用这两个半图中的一个替换 G s , 2 G{s,2} Gs,2以生成负样本。如何生成负样本可能会对学习嵌入的质量产生很大影响。它可以驱动模型来估计这两个图是否可以合并成有效的图。通过这种方式,该模型可以从下游任务所必需的节点和边中学习图的有价值的图级特征。
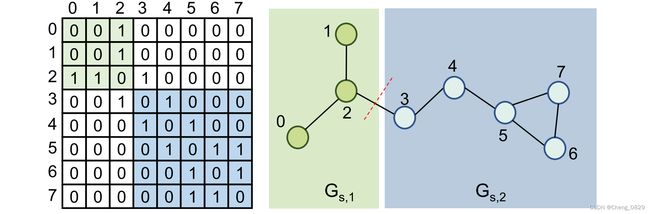
图2.图分解示例。左子图是右子图的图邻接矩阵,其中绿色和蓝色代表分解后的两个半图。
2.3.2 虚拟集合节点
通过上述方法得到的半图对是两个相互独立且没有任何联系的图。我们将这两个半图连接成一个完整的图,并引入一个虚拟集合节点,通过聚合每个节点的信息来获得全局图级表示。集合节点通过虚拟有向边与所有其他节点链接,从其他节点指向集合节点。在GNN的消息传递过程中,集合节点从所有其他节点学习其表示,但不影响它们的特征更新过程。因此,收集节点的特征可以掌握半图对的全局表示,并输入前馈神经网络进行最终预测。
2.3.3 输入表示
输入表示由特征嵌入和分段嵌入两部分组成。图一般由一组节点特征和边特征来描述,如表1所示。除了特征嵌入,我们还在每一个节点和每条边上增加了一个可学习的分段嵌入,以指示它属于哪个半图。最终的输入表示是将分段嵌入和特征嵌入相加得到的。通过这种方式,该模型可以区分来自不同分段的节点和边,从而可以同时输入两个图,如图3所示。
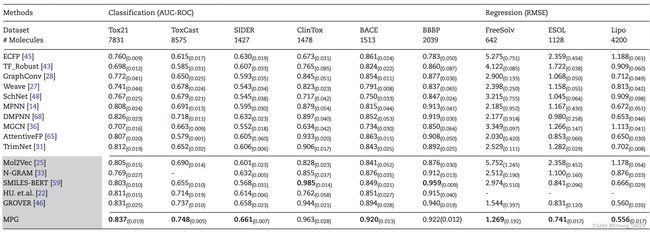
表1:分子性质预测的性能比较。
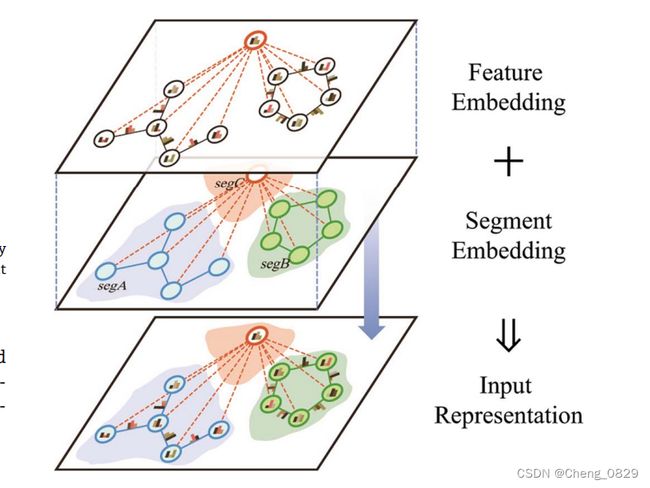
图3.图数据的输入表示由两部分组成:特征嵌入和分段嵌入。
(A)特征嵌入:一组节点和边的特征经过嵌入变换来描述一个图。
(B)分段嵌入:每一个节点和每条边有一个可学习的分段嵌入,指示它属于哪个半图,不同的颜色代表不同的分段。