MyDLNote - Inpainting: Image Inpainting with Learnable Bidirectional Attention Maps
Image Inpainting with Learnable Bidirectional Attention Maps
我的博客尽可能提取文章内的主要传达的信息,既不是完全翻译,也不简单粗略。论文的motivation和网络设计细节,将是我写这些博客关注的重点。
文章:
http://openaccess.thecvf.com/content_ICCV_2019/papers/Xie_Image_Inpainting_With_Learnable_Bidirectional_Attention_Maps_ICCV_2019_paper.pdf
本文是针对部分卷积 Image Inpainting for Irregular Holes Using Partial Convolutions 存在的两个问题而提出的模型。部分卷积的这两个问题是: re-normalization 不是自动学习的,mask-updating 只考虑前向传播。本文提出了一种学习特征 re-normalization 和mask-updating 的可学习注意图模块,该模块能够有效地适应不规则孔洞和卷积层的扩展。阅读本博客,可参看我部分卷积的博客。
【相关博客】 MyDLNote - Network: [18ECCV] Image Inpainting for Irregular Holes Using Partial Convolutions
目录
Image Inpainting with Learnable Bidirectional Attention Maps
Abstract
Introduction
Proposed Method
Revisiting Partial Convolution
Learnable Attention Maps
Learnable Bidirectional Attention Maps
Model Architecture
Loss Functions
Abstract
Most convolutional network (CNN)-based inpainting methods adopt standard convolution to indistinguishably treat valid pixels and holes, making them limited in handling irregular holes and more likely to generate inpainting results with color discrepancy and blurriness. Partial convolution has been suggested to address this issue, but it adopts handcrafted feature renormalization, and only considers forward mask-updating. In this paper, we present a learnable attention map module for learning feature re-normalization and mask-updating in an end-to-end manner, which is effective in adapting to irregular holes and propagation of convolution layers. Furthermore, learnable reverse attention maps are introduced to allow the decoder of U-Net to concentrate on filling in irregular holes instead of reconstructing both holes and known regions, resulting in our learnable bidirectional attention maps. Qualitative and quantitative experiments show that our method performs favorably against state-of-the-arts in generating sharper, more coherent and visually plausible inpainting results. The source code and pre-trained models will be available at: https://github.com/Vious/LBAM_inpainting/.
基于CNN的 inpainting 算法不能较好地处理非规则空洞修复,会产生颜色差异和模糊问题。
partial conv. 能够较好地解决非规则空洞修复问题,但它采用人为设定的特征重正则化 re-normalization,只考虑 mask 的正向更新。
[MyNote: 这里的 re-normalization,指的是原文中 sum(1)/sum(M) 比例因子,用来调整适当的比例对有效 (unmasked) 输入的变化量,请参考原文公式(1)。]
本文提出了一种可学习的 attention map 模型,以端到端的方式学习特征 re-normalization 和 mask 更新。
引入可学习的反向注意图,使 U-Net 的解码器专注于填充不规则的空洞,而不是同时重建空洞和已知区域,从而得到可学习的双向注意图。
Introduction
There may exist multiple potential solutions for the given holes in an image, i.e., the holes can be filled with any plausible hypotheses coherent with the surrounding known regions. And the holes can be of complex and irregular patterns, further increasing the difficulty of image inpainting.
问题:这些空洞可以用任何与周围已知区域相一致的合理假设来填补。空洞的形状复杂、不规则,进一步增加了绘画的难度。
PatchMatch, gradually fill in holes by searching and copying similar patches from known regions. Albeit exemplar-based methods are effective in hallucinating detailed textures, they are still limited in capturing high-level semantics, and may fail to generate complex and non-repetitive structures.
尽管基于范例的方法在产生细节纹理方面是有效的,但是它们在捕获高级语义方面仍然是有限的,并且可能不能生成复杂的和非重复的结构。
Benefited from the powerful representation ability and large scale training, CNN-based methods are effective in hallucinating semantically plausible result. And adversarial loss [8] has also been deployed to improve the perceptual quality and naturalness of the result. Nonetheless, most existing CNN-based methods usually adopt standard convolution which indistinguishably treats valid pixels and holes. Thus, they are limited in handling irregular holes and more likely to generate inpainting results with color discrepancy and blurriness. As a remedy, several postprocessing techniques [10, 34] have been introduced but are still inadequate in resolving the artifacts.
基于 CNN 的方法得益于强大的表达能力和大规模的训练,能够有效地实现语义上的似是而非的结果。对抗性损失也被用来改善感知质量和结果的自然性。然而,多数 现有的CNN方法无法区分有效的像素和空洞。因此,它们在处理不规则孔洞时受到限制,更容易产生色彩不一致和模糊的效果。作为补救措施,引入了几种后处理技术 [10,34],但在解决 artifacts 方面仍然不够。
For better handling irregular holes and suppressing color discrepancy and blurriness, partial convolution (PConv) [17] has been suggested. In each PConv layer, mask convolution is used to make the output conditioned only on the unmasked input, and feature re-normalization is introduced for scaling the convolution output. A mask-updating rule is further presented to update a mask for the next layer, making PConv very effective in handling irregular holes. Nonetheless, PConv adopts hard 0-1 mask and handcrafted feature re-normalization by absolutely trusting all filling-in intermediate features. Moreover, PConv considers only forward mask-updating and simply employs allone mask for decoder features.
部分卷积 (PConv) 可以更好地处理不规则孔洞和抑制颜色差异和模糊。在每个 PConv 层中,使用 mask 卷积使输出仅以unmasked 的输入为条件,并引入特征重归一化来缩放卷积输出。进一步提出了一个 mask-updating 规则来更新下一层的掩码,使得 PConv 在处理不规则孔洞时非常有效。尽管如此,PConv 采用了硬 0-1mask(即在decoder中,使用的是全为 1 的 mask,即对全部图像进行修复)和手工制作的特征重新标准化(原文中的sum(1)/sum(M)),完全信任所有填充的中间特征。
In this paper, we take a step forward and present the modules of learnable bidirectional attention maps for the re-normalization of features on both encoder and decoder of the U-Net architecture. To begin with, we revisit PConv without bias, and show that the mask convolution can be safely avoided and the feature re-normalization can be interpreted as a re-normalization guided by hard 0-1 mask. To overcome the limitations of hard 0-1 mask and handcrafted mask-updating, we present a learnable attention map module for learning feature re-normalization and mask-updating. Benefited from the end-to-end training, the learnable attention map is effective in adapting to irregular holes and propagation of convolution layers.
在本文中,提出了可学习的双向注意映射模块,用于重新标准化的特征在 U-Net 的编码器和解码器。首先,我们对 PConv 进行了研究,证明了 mask 卷积是可以安全避免的,特征的 re-normalization 可以解释为在 hard 0-1 mask 指导下的 re-normalization。
为了克服 hard 0-1 mask 和人为 mask-updating 的局限性,我们提出了一种可学习的注意力地图模块,用于学习特征的重新规格化和 mask-updating。得益于端到端的训练,可学习注意图能够有效地适应不规则孔洞和卷积层的传播。
Furthermore, PConv simply uses all-one mask on the decoder features, making the decoder should hallucinate both holes and known regions. Note that the encoder features of known region will be concatenated, it is natural that the decoder is only required to focus on the inpainting of holes. Therefore, we further introduce learnable reverse attention maps to allow the decoder of U-Net concentrate only on filling in holes, resulting in our learnable bidirectional attention maps. In contrast to PConv, the deployment of learnable bidirectional attention maps empirically is beneficial to network training, making it feasible to include adversarial loss for improving visual quality of the result.
此外,PConv 简单地在解码器特性上使用 all-one mask,使解码器产生空穴和已知区域的幻觉。注意到 U-Net 的特点,已知区域已经通过 skip-connection 从 encoder 传到了 decoder,所以自然地,decoder 只需要学习空洞区域就可以了。
因此,我们进一步引入可学习的反向注意图,使 U-Net 的解码器只专注于填补漏洞,从而得到可学习的双向注意图。
与 PConv 相比,可学习的双向注意力地图的经验部署有利于网络训练,使得包含对抗损失以提高结果的视觉质量成为可能。
Proposed Method
Revisiting Partial Convolution
PConv 如图 2(a)所示。
A PConv layer generally involves three steps, i.e., (i) mask convolution, (ii) feature re-normalization, and (iii) mask-updating. Denote by ![]() the input feature map and M the corresponding hard 0-1 mask. We further let
the input feature map and M the corresponding hard 0-1 mask. We further let  be the convolution filter and
be the convolution filter and  be its bias. To begin with, we introduce the convolved mask
be its bias. To begin with, we introduce the convolved mask ![]() , where ⊗ denotes the convolution operator,
, where ⊗ denotes the convolution operator, ![]() denotes a 3 × 3 convolution filter with each element 1/9 . The process of PConv can be formulated as,
denotes a 3 × 3 convolution filter with each element 1/9 . The process of PConv can be formulated as,
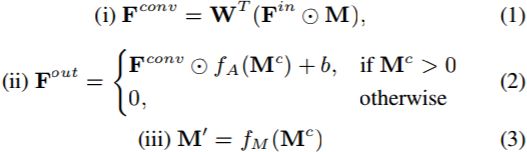
where ![]() denotes the attention map, and
denotes the attention map, and 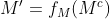 denotes the updated mask. We further define the activation functions for attention map and updated mask as,
denotes the updated mask. We further define the activation functions for attention map and updated mask as,
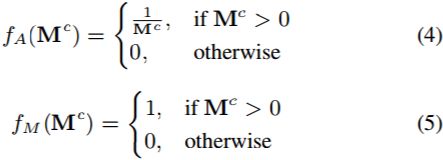
From Eqns. (1)∼(5) and Fig. 2(a), PConv can also be explained as a special interplay model between mask and convolution feature map.
![]() 就是 3x3 的卷积核,其每个元素都是 1/9。摘要和引言说的 re-normalization 是固定的就是指这个
就是 3x3 的卷积核,其每个元素都是 1/9。摘要和引言说的 re-normalization 是固定的就是指这个 ![]() 是固定的。
是固定的。
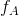 其实就是原文中的比例因子 sum(1)/sum(
其实就是原文中的比例因子 sum(1)/sum( ),用来调整适当的比例对有效 (unmasked) 输入的变化量。
),用来调整适当的比例对有效 (unmasked) 输入的变化量。
![]() 就是 mask 的更新。
就是 mask 的更新。
PConv 也可以解释为 mask 与卷积特征图之间特殊的交互作用模型。
However, PConv adopts the hand-crafted convolution filter ![]() as well as hand-crafted activation functions
as well as hand-crafted activation functions![]() and
and ![]() , thereby giving some leeway for further improvements.
, thereby giving some leeway for further improvements.
Moreover, the nondifferential property of ![]() also increases the difficulty of end-to-end learning. To our best knowledge, it remains a difficult issue to incorporate adversarial loss to train a U-Net with PConv.
also increases the difficulty of end-to-end learning. To our best knowledge, it remains a difficult issue to incorporate adversarial loss to train a U-Net with PConv.
Furthermore, PConv only considers the mask and its updating for encoder features. As for decoder features, it simply adopts all-one mask, making PConv limited in filling holes.
本文认为,对抗损失函数不能很好的应用于 PConv 构成的 U-Net 网络里。(为什么?因为 mask 更新是不可微分的吗?为什么mask 更新不可微分就会影响对抗损失函数的效果呢?)
PConv 只考虑 encoder 的 mask 更新,而 decoder 则使用全部是 1 的 mask,这限制了修复能力。(已知区域已经通过 skip-connection 从 encoder 传到了 decoder,所以自然地,decoder 只需要学习空洞区域就可以了。)
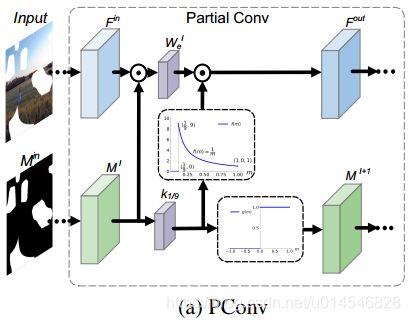
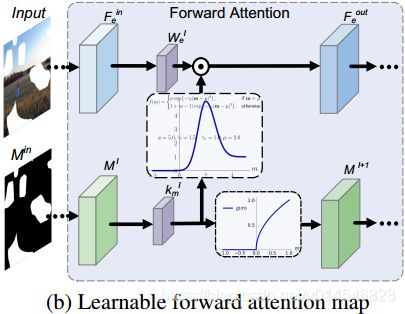
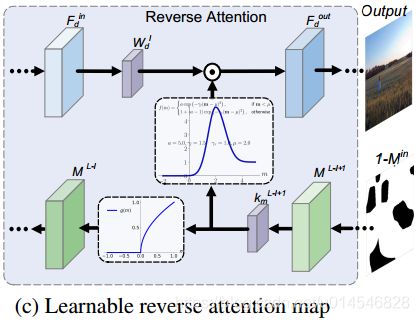
Figure 2. Interplay models between mask and intermediate feature for PConv and our learnable bidirectional attention maps. Here, the white holes in
denotes missing region with value 0, and the black area denotes the known region with value 1.
Learnable Attention Maps
The convolution layer without bias has been widely adopted in U-Net for image-to-image translation and image inpainting. When the bias is removed, it can be readily seen from Eqn. (2) that the convolution features in updated holes are zeros. Thus, the mask convolution in Eqn. (1) is equivalently rewritten as standard convolution,
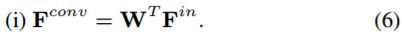
Then, the feature re-normalization in Eqn. (2) can be interpreted as the element-wise product of convolution feature and attention map,
![]()
在图到图和图像修复都采用卷积层中不使用偏差 b。公式(2)可以理解为卷积的特征图与注意力图之间的元素相乘操作。
Even though, the handcrafted convolution filter ![]() is fixed and not adapted to the mask. The activation function for updated mask absolutely trusts the inpainting result in the region
is fixed and not adapted to the mask. The activation function for updated mask absolutely trusts the inpainting result in the region ![]() , but it is more sensible to assign higher confidence to the region with higher
, but it is more sensible to assign higher confidence to the region with higher ![]() .
.
但是卷积核 ![]() 是固定的,并没有与 mask 相适应。更新 mask 的激活函数绝对信任
是固定的,并没有与 mask 相适应。更新 mask 的激活函数绝对信任 ![]() 区域内的 inpainting 结果,但更明智的做法是将更高的置信度赋给具有更高的
区域内的 inpainting 结果,但更明智的做法是将更高的置信度赋给具有更高的 ![]() 区域。[也就是说,PConv 只考虑更新 mask 中大于0的部分,而本文认为更好的做法是更新的 mask 最好是将获得较高的值的区域作为新的 mask。]
区域。[也就是说,PConv 只考虑更新 mask 中大于0的部分,而本文认为更好的做法是更新的 mask 最好是将获得较高的值的区域作为新的 mask。]
To overcome the above limitations, we suggest learnable attention map which generalizes PConv without bias from three aspects.
First, to make the mask adaptive to irregular holes and propagation along with layers, we substitute ![]() with layer-wise and learnable convolution filters
with layer-wise and learnable convolution filters ![]() .
.
Second, instead of hard 0-1 mask-updating, we modify the activation function for updated mask as,
![]()
where 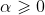 is a hyperparameter and we set
is a hyperparameter and we set ![]() . One can see that
. One can see that ![]() degenerates into
degenerates into ![]() when
when 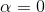 .
.
Third, we introduce an asymmetric Gaussian-shaped form as the activation function for attention map,
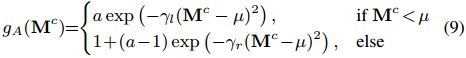
where  ,
,  , , and
, , and ![]() are the learnable parameters, we initialize them as = 1.1, = 2.0, = 1.0,
are the learnable parameters, we initialize them as = 1.1, = 2.0, = 1.0, ![]() = 1.0 and learn them in an end-to-end manner.
= 1.0 and learn them in an end-to-end manner.
To sum up, the learnable attention map adopt Eqn. (6) in Step (i), and the next two steps are formulated as,
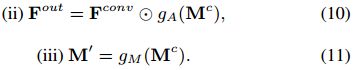
Fig. 2(b) illustrates the interplay model of learnable attention map. In contrast to PConv, our learnable attention map is more flexible and can be end-to-end trained, making it effective in adapting to irregular holes and propagation of convolution layers.
针对 ![]() 是固定的,及 mask 更新只考虑 >0 的情况(0-1 分段函数),提出三个方面的改进:
是固定的,及 mask 更新只考虑 >0 的情况(0-1 分段函数),提出三个方面的改进:
首先,为了使 mask 能够适应不规则的孔洞并随层传播,我们使用了分层的、可学习的卷积滤波器 ![]() 。
。
其次,我们将更新后的 mask 的激活函数修改为公式 (8)。【具体地说,就是将分段 0-1 函数先改成 ReLU,然后再做个伽马变换。】
第三,我们引入了一个不对称的高斯形态作为注意力图的激活函数公式(9),其中 , , , 和 ![]() 是可学习参数,我们将它们初始化为 = 1.1、 = 2.0、 = 1.0、
是可学习参数,我们将它们初始化为 = 1.1、 = 2.0、 = 1.0、![]() = 1.0,并以端到端方式学习它们。
= 1.0,并以端到端方式学习它们。
图 2(b) 为可学习注意图的交互作用模型。与 PConv 相比,我们的可学习注意图更加灵活,可以端到端的训练,使得它能够有效地适应不规则的孔和卷积层的传播。
Learnable Bidirectional Attention Maps
When incorporating PConv with U-Net for inpainting, the method only updates the masks along with the convolution layers for encoder features. However, all-one mask is generally adopted for decoder features. As a result, the ![]() -th layer of decoder feature in both known regions and holes should be hallucinated using both
-th layer of decoder feature in both known regions and holes should be hallucinated using both ![]() -th layer of encoder feature and
-th layer of encoder feature and ![]() -th layer of decoder feature. Actually, the
-th layer of decoder feature. Actually, the  -th layer of encoder feature will be concatenated with the
-th layer of encoder feature will be concatenated with the ![]() -th layer of decoder feature, and we can only focus on the generation of the
-th layer of decoder feature, and we can only focus on the generation of the ![]() -th layer of decoder feature in the holes.
-th layer of decoder feature in the holes.
We further introduce learnable reverse attention maps to the decoder features. Denote by ![]() the convolved mask for encoder feature
the convolved mask for encoder feature ![]() . Let
. Let ![]() be the convolved mask for decoder feature
be the convolved mask for decoder feature ![]() . The first two steps of learnable reverse attention map can be formulated as,
. The first two steps of learnable reverse attention map can be formulated as,
![]()
where ![]() and
and ![]() are the convolution filters. And we define
are the convolution filters. And we define 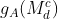 as the reverse attention map. Then, the mask
as the reverse attention map. Then, the mask ![]() is updated and deployed to the former decoder layer,
is updated and deployed to the former decoder layer,
![]()
Fig. 2(c) illustrates the interplay model of reverse attention map. In contrast to forward attention maps, both encoder feature (mask) and decoder feature (mask) are considered. Moreover, the updated mask in reverse attention map is applied to the former decoder layer, while that in forward attention map is applied to the next encoder layer.
PConv 只考虑了 encoder 的部分卷积,而没有考虑 decoder。于是提出了逆向可学习注意力图模型,这样就形成了 Learnable Bidirectional Attention Maps。反向和正向是相同的模型,只是输入输出不同罢了。decoder 的输出则是二者的相加。
图2(c)为逆向注意图的交互作用模型。与前向注意映射相比,编码器特征 (mask) 和解码器特征 (mask) 都被考虑在内。另外,注意图的反向更新的掩码应用于前一解码器层,而注意图的正向更新的掩码应用于下一编码器层。
By incorporating forward and reverse attention maps with U-Net, Fig. 3 shows the full learnable bidirectional attention maps. Given an input image ![]() with irregular holes, we use
with irregular holes, we use ![]() to denote the binary mask, where ones indicate the valid pixels and zeros indicate the pixels in holes. From Fig. 3, the forward attention maps take
to denote the binary mask, where ones indicate the valid pixels and zeros indicate the pixels in holes. From Fig. 3, the forward attention maps take ![]() as the input mask for the re-normalization of the first layer of encoder feature, and gradually update and apply the mask to next encoder layer. In contrast, the reverse attention maps take
as the input mask for the re-normalization of the first layer of encoder feature, and gradually update and apply the mask to next encoder layer. In contrast, the reverse attention maps take ![]() as the input for the re-normalization of the last (i.e.,
as the input for the re-normalization of the last (i.e.,  -th) layer of decoder feature, and gradually update and apply the mask to former decoder layer. Benefited from the end-to-end learning, our learnable bidirectional attention maps (LBAM) are more effective in handling irregular holes. The introduction of reverse attention maps allows the decoder concentrate only on filling in irregular holes, which is also helpful to inpainting performance. Our LBAM is also beneficial to network training, making it feasible to exploit adversarial loss for improving visual quality.
-th) layer of decoder feature, and gradually update and apply the mask to former decoder layer. Benefited from the end-to-end learning, our learnable bidirectional attention maps (LBAM) are more effective in handling irregular holes. The introduction of reverse attention maps allows the decoder concentrate only on filling in irregular holes, which is also helpful to inpainting performance. Our LBAM is also beneficial to network training, making it feasible to exploit adversarial loss for improving visual quality.
通过使用 U-Net 合并正向和反向注意力地图,图 3 显示了完整的可学习的双向注意力地图。对于具有不规则孔洞的输入图像 ![]() ,
,![]() 用 1 表示有效的像素,用 0 表示孔洞中的像素。从图 3 中可以看出,前向注意图作为编码器特征的第一层 re-normalization 的输入 mask
用 1 表示有效的像素,用 0 表示孔洞中的像素。从图 3 中可以看出,前向注意图作为编码器特征的第一层 re-normalization 的输入 mask ![]() ,并逐步更新应用到下一层编码器。相反,反向注意图
,并逐步更新应用到下一层编码器。相反,反向注意图 ![]() 作为最后一个注意图的 re-normalization 的输入,即第 层的解码器特征,并逐步更新和适用于前解码器层的掩码。得益于端到端的学习,我们的可学习双向注意图 (LBAM)在处理不规则孔洞时更加有效。反向注意图的引入使得解码器只专注于填充不规则的孔,这也有助于inpainting性能。我们的LBAM也有利于网络训练,使得利用竞争损失来提高视觉质量成为可能。
作为最后一个注意图的 re-normalization 的输入,即第 层的解码器特征,并逐步更新和适用于前解码器层的掩码。得益于端到端的学习,我们的可学习双向注意图 (LBAM)在处理不规则孔洞时更加有效。反向注意图的引入使得解码器只专注于填充不规则的孔,这也有助于inpainting性能。我们的LBAM也有利于网络训练,使得利用竞争损失来提高视觉质量成为可能。
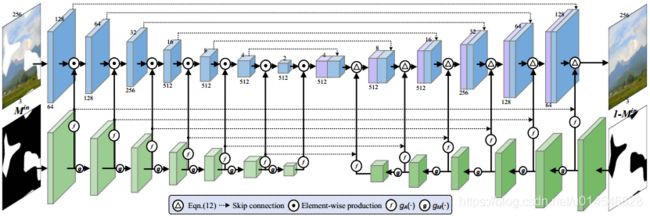
Figure 3. The network architecture of our model. The circle with triangle inside denotes operation form of Eqn.( 12), gA and gM represent activation functions of Eqn.( 9) and mask updating function of Eqn.( 8).
Model Architecture
We modify the U-Net architecture [11] of 14 layers by removing the bottleneck layer and incorporating with bidirectional attention maps (see Fig. 3). In particular, forward attention layers are applied to the first six layers of encoder, while reverse attention layers are adopted to the last six layers of decoder. For all the U-Net layers and the forward and reverse attention layers, we use convolution filters with the kernel size of 4 × 4, stride 2 and padding 1, and no bias parameters are used. In the U-Net backbone, batch normalization and leaky ReLU nonlinearity are used to the features after re-normalization, and tanh nonlinearity is deployed right after convolution for the last layer. Fig. 3 also provides the size of feature map for each layer, and more details of the network architecture are given in the suppl.
我们修改了 14 层的 U-Net 架构,去掉了瓶颈层,加入了双向注意力地图 (见图3)。特别是,编码器的前 6 层采用了正向注意力层,而解码器的后 6 层采用了反向注意力层。对于所有的 U-Net 层以及正向和反向的注意层,我们使用了核尺寸为 4×4、stride 2 和padding 1 的卷积滤波器,并且没有使用任何偏置参数。在 U-Net 骨干网中,对重新归一化后的特征采用批处理归一化和漏电ReLU非线性,最后一层卷积后立即展开tanh非线性。图3还提供了每个层的 feature map 的大小,增刊中给出了更多的网络架构细节。
Loss Functions
Pixel Reconstruction Loss.
![]()
Perceptual Loss.
![]()
Style Loss.
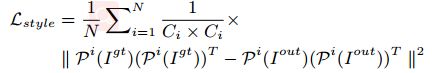
Adversarial Loss.
Adversarial loss [8] has been widely adopted in image generation [24, 27, 38] and low level vision [16] for improving the visual quality of generated images. In order to improve the training stability of GAN, Arjovsky et al. [1] exploit the Wasserstein distance for measuring the distribution discrepancy between generated and real images, and Gulrajani et al. [9] further introduce gradient penalty for enforcing the Lipschitz constraint in discriminator. Following [9], we formulate the adversarial loss as, where D(·) represents the discriminator. Iˆ is sampled from Igt and Iout by linear interpolation with a randomly selected factor, λ is set to 10 in our experiments. We empirically find that it is difficult to train the PConv model when including adversarial loss. Fortunately, the incorporation of learnable attention maps is helpful to ease the training, making it feasible to learn LBAM with adversarial loss. Please refer to the suppl. for the network architecture of the 7-layer discriminator used in our implementation.
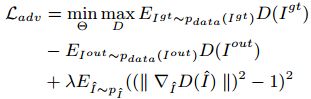
Model Objective
Taking the above loss functions into account, the model objective of our LBAM can be formed as,
![]()
where λ1, λ2, λ3, and λ4 are the tradeoff parameters. In our implementation, we empirically set λ1 = 1, λ2 = 0.1, λ3 = 0.05 and λ4 = 120.