Direct speech-to-speech translation with a sequence-to-sequence model
本篇详细介绍了Google Translate的新技术,从音频直接翻译音频。这个模型叫做S2ST(speech-to-speech translation)。原理是通过一个语音的声谱图映射到另一种语音的声谱图。
Abstract
我们提出了一种基于注意力的序列到序列神经网络,它可以直接将一种语言的语音转换成另一种语言的语音,而不依赖于中间文本表示。该网络经过端到端的训练,学习将语音谱图映射成另一种语言的目标谱图,对应于翻译后的内容(以不同的标准语音)。我们进一步证明了使用源说话者的声音合成翻译语音的能力。我们对两个西班牙语到英语的语音翻译数据集进行了实验,发现该模型的性能略低于直接语音到文本的翻译模型和文本到语音的合成模型的基线级联,证明了该方法在这一非常具有挑战性的任务上的可行性。
1. Introduction
我们的任务是语音到语音翻译(S2ST):将一种语言的语音翻译成另一种语言的语音。这个应用程序非常有助于打破不使用同一种语言的人之间的沟通障碍。具体地说,我们研究是否可以训练模型直接完成这项任务,而不依赖于中间文本表示。这与传统的S2ST系统不同,传统的S2ST系统通常分为三个部分:自动语音识别automatic speech recognition(ASR)、文本到文本机器翻译text-to-text machine translation(MT)和文本到语音合成text-to-speech synthesis(TTS)[1-4]。
级联系统Cascaded systems存在组件间错误复合的潜在问题,例如识别错误导致更大的翻译错误。直接S2ST模型通过训练来解决端到端的任务,避免了这个问题。由于只需要一个解码步骤,而不是三个,因此与级联系统相比,它们在减少计算需求和更低的推理延迟方面也有优势。此外,直接模型自然能够在翻译过程中保留副语言和非语言信息,例如,在合成的译文中保持源说话者的声音、情感和韵律。最后,直接对输入语音进行调节,可以很容易地学习生成不需要翻译的单词的流畅发音,比如名字。
然而,由于几个原因,解决直接的S2ST任务特别具有挑战性。全监督端到端训练需要收集大量的输入/输出语音对。与用于MT的并行文本对或用于ASR或TTS的语音文本对相比,此类数据更难收集。与单一的语音到语音模型相比,分解成更小的任务可以利用更低的训练数据需求,并且可以为给定的训练预算生成更健壮的系统。两个光谱图之间的不确定对齐也对训练提出了重大挑战,因为它们的基本口语内容不同。
本文提出了一种训练端到端的直接语音到语音翻译模型Translatotron。为了方便在没有预定义对齐的情况下进行训练,我们利用源或目标内容的高级表示形式,即转录形式,本质上是带有语音到文本任务的多任务训练。然而,在推理期间不使用中间文本表示。该模型的性能不如基线级联系统。然而,它证明了一个概念,并作为未来研究的起点。
对级联语音翻译系统中不同子系统的组合方法进行了广泛的研究。[5,6]使MT可以进入ASR的晶格。[7,8]采用随机有限状态传感器集成声学模型和翻译模型,该传感器可以使用维特比搜索直接解码翻译文本。在合成方面,[9]采用无监督聚类的方法寻找基于f0的韵律特征,并从源语音和目标语音中转移语调。[10]增强MT联合预测翻译词和重音,以提高合成语音的表达能力。[11]利用神经网络将源语音的持续时间和功率传递给目标。[12]通过将隐马尔可夫模型状态从ASR映射到TTS,将源说话人的语音转换为合成翻译语音。类似地,最近关于神经TTS的研究也集中于在参考数据有限的情况下适应新的声音[13-16]。
端到端语音到文本翻译(ST)的初始方法[17,18]的性能比ASR模型和MT模型的级联还要差。[19, 20]利用弱监督数据和多任务学习,实现了更好的端到端性能。[21]进一步表明,综合训练数据的使用优于多任务训练。在这项工作中,我们利用了综合训练目标和多任务训练的优势。
提出的模型类似于最近的语音转换的序列到序列模型,即用另一个人的声音再现一个话语[22-24]。例如,[23]提出了一种基于注意力的模型,根据源语音的输入特征(与ASR瓶颈特征连接的频谱图)在目标语音中生成频谱图。与S2ST相比,语音转换的输入输出比对更简单,近似单调。[23]还训练特定于每个输入-输出扬声器对的模型(即一对一转换),而我们研究多对一和多对多扬声器配置。最后,[25]在一个包含100个单词的玩具数据集中演示了一个基于注意力的直接S2ST模型。在这项工作中,我们训练真实的语言,包括自发的电话交谈,在一个更大的规模。
2. Speech-to-speech translation model
图1显示了所提议的Translatotron模型体系结构的概述。根据[15, 26],它是由几个单独训练组件:
1)一种引起序列测序网络生成目标色(蓝色)
2)声码器(红色)转换目标色timedomain波形
3)可选地,预训练编码器(绿色)可用于条件的解码器来识别源说话人的身份,使跨语言语音转换与翻译同时[27]。
序列到序列编码器堆栈将80通道的log-mel谱图输入特征映射到隐藏状态,这些隐藏状态通过基于注意力的对齐机制传递,从而形成一个自回归解码器,该解码器预测与翻译语音对应的1025个dimlog谱图的每一帧。两个可选的辅助译码器,每个都有自己的注意成分,预测源和目标音素序列。
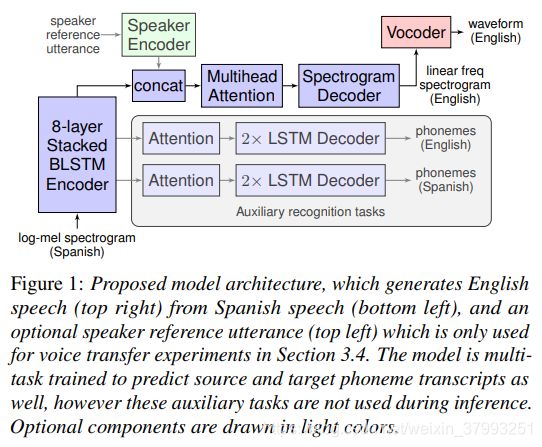
该编码器采用最新的语音翻译[21]和识别[28]模型,由8个双向LSTM层组成。如图1所示,最后一层输出被传递给初级解码器,而中间激活被传递给预测音素序列的辅助解码器。我们假设,早期的编码层更有可能很好地表示源内容,而较深的层可能学习编码关于目标内容的更多信息。
该谱图解码器使用类似Tacotron 2 TTS模型[26]的架构,包括pre-net、自回归LSTM堆栈和post-net components。为了适应更具挑战性的S2ST任务,我们对它做了一些修改。我们使用4-head multi-head additive attention[29]代替位置敏感注意,在实验中表现出较好的性能。与[26]中256-dim相比,我们还使用了一个更窄的32维pre-net bottleneck,我们发现这对于在训练中获得注意力至关重要。我们还使用2个约简因子[30],即预测每个解码步骤的两个谱图帧。最后,与翻译任务的结果一致[19,31],我们发现使用包含4或6个LSTM层的更深层解码器可以获得更好的性能。
我们发现,多任务训练是解决任务的关键,我们通过集成辅助解码器网络来预测与源语音和/或目标语音对应的音素序列。在训练过程中,利用这些辅助识别网络计算损失,帮助主谱图解码器学习注意。它们不用于推理。与主译码器相比,辅助译码器采用了具有单头加注意[32]的2层LSTMs。三种解码器均采用注意缺失和LSTM区出正则化[33],概率均为0.1。训练使用batch为1024的Adafactor优化器[34]。
由于我们只是在演示概念的证明,所以我们的实验主要依赖于低复杂度的Griffin-Lim[35]声码器。然而,我们在听力测试中使用WaveRNN[36]神经声码器来评估语音的自然度。
最后,为了控制输出扬声器标识,我们加入了一个可选扬声器编码器网络,如[15]。该网络是针对说话人验证任务进行有区别的预训练,在翻译加速器的训练过程中不进行更新。我们使用来自[37]的dvector V3模型,针对8种语言(包括英语和西班牙语)的更大的851K使用者进行训练。该模型从说话人的参考话语中计算出一个嵌入256-dim的说话人,并将其传递到线性投影层(使用序列到序列模型进行训练),将维数降至16。这对于将在训练过程中看不到的源语言使用者进行概括是至关重要的。
3. Experiments
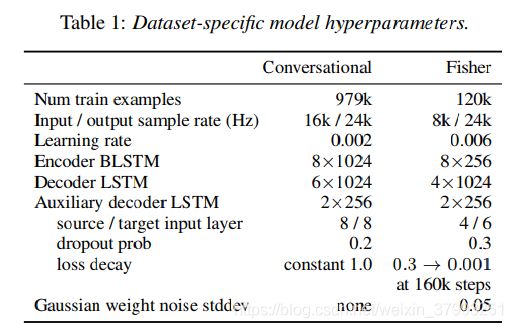
我们研究了两个西班牙语到英语的翻译数据集:来自[21]的大型并行文本和读语音对的“会话”语料库,以及来自西班牙语的Fisher电话会话语料库和相应的英语翻译[38],由于其自发性和非正式的说话风格,这两个语料库更小,更具挑战性。在3.1节和3.2节中,我们使用单一(女性)说话者英语TTS系统,从目标文本中合成目标语音;在第3.4节中,我们使用真实的人目标语音对会话数据集进行语音传输实验。模型使用Lingvo框架[39]实现。有关特定于数据集的超参数,请参见表1。
为了评估语音到语音的翻译性能,我们使用一个预先训练的ASR系统来识别生成的语音,并将生成的文本与地面真实参考译文进行比较,计算BLEU评分[40]作为语音清晰度和翻译质量的客观衡量标准。由于潜在的识别错误(参见图2),这可以看作是底层翻译质量的一个下界。我们使用[41]在960小时的LibriSpeech语料库[42]上训练的16k words piece attentionbasedasr模型,在test-clean和testother集上分别获得了4.7%和13.4%的错误率。此外,我们还进行了听力测试来测量主观言语自然度平均意见得分(MOS),以及说话人相似度MOS来进行语音转移。
3.1. Conversational Spanish-to-English
这个在[21]中描述的专有数据集是由众包人员获取的,用于阅读西班牙语-英语对话MT数据集的两边。在本节中,我们没有使用人类的目标语音,而是使用一个TTS模型来合成单个女性英语说话者的目标语音简化学习目标。我们使用英语Tacotron 2 TTS模型[26],但使用格里芬林声码器方便。此外,我们以与[21]相同的方式添加背景噪声和混响来增强输入源语音。
得到的数据集包含979k个并行话语对,包括1.4k小时的源语音和619小时的合成目标语音。总的目标语音持续时间要小得多,因为TTS输出具有更好的端点,并且包含更少的停顿。9.6k对被拿出来进行测试。
输入特征帧由一个80通道的log-mel谱图的3个相邻帧叠加而成,如[21]所示。在这些实验中没有使用扬声器编码器,因为目标语音总是来自同一个扬声器。
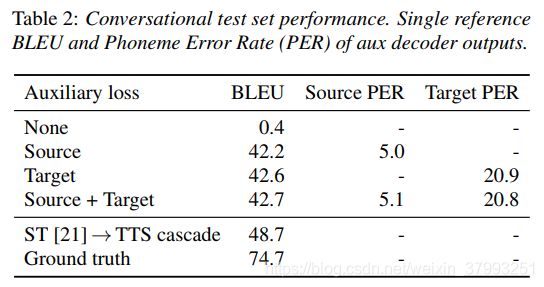
表2显示了使用不同辅助损耗组合训练的模型的性能,与基线ST→TTS级联模型相比,基线ST→TTS级联模型使用相同数据训练的语音到文本转换模型[21],使用相同Tacotron 2 TTS模型合成训练目标。请注意,由于评估过程中的ASR错误或合成地面真相时的TTS失败,地面真相BLEU评分低于100。
没有辅助损失的训练会导致极其糟糕的表现。该模型正确地综合了常见的单词和简单的短语,例如将“hola”翻译成“hello”。然而,它并不总是翻译完整的话语。虽然它总是在目标语音中产生似是而非的语音,但输出可以独立于输入,由一串无意义的音节组成。这与未能学会注意输入是一致的,并反映了直接S2ST任务的难度。
集成辅助性音素识别任务有助于规范编码器,并使模型能够学习注意力,极大地提高了性能。目标音素PER远高于源音素PER,反映了翻译任务的难度。两种辅助任务的训练质量都达到了最佳,但不同组合的训练效果差异较小。总体而言,与基线仍有6个蓝点的差距,说明还有改进的空间。然而,相对较小的差距显示了端到端方法的潜力。
3.2. Fisher Spanish-to-English
该数据集包含约120k个并行话语对,跨越127小时的源语音。使用与上一节相同的语音,使用并行波网[43]合成目标语音。结果包含了96小时的合成目标语音。
在[19]之后,通过叠加80通道的log-mel谱图,利用增量和加速度构建输入特征。与第3.1节相比,由于数据集的规模较小,我们发现要获得良好的性能,需要更仔细的正则化和调优。如表1所示,我们使用更窄的编码尺寸256,一个更浅的4层解码器,并添加高斯权值噪声到所有LSTM权值作为正则化,如在[19]。模型对辅助解码器超参数尤为敏感,与最佳性能时通过激活来自编码器的中间层堆栈作为输入到辅助解码器,使用更激进的dropout为0.3,腐烂的辅助减肥的训练为了鼓励模型适合主S2ST任务。
实验结果如表3所示。同样,使用两个辅助损耗效果最好,但是与3.1节不同的是,单独使用任何一个都有很大的性能提升。仅使用源识别损失的性能非常差,这表明在没有对翻译任务进行严格监督的情况下,学习对该任务的对齐尤其困难。
我们发现,4-head的注意力比一个head的效果更好,不像对话任务,两种注意力机制都有相似的表现。最后,就像在[21]中一样,我们发现在ST任务中对底层6个编码层进行预训练可以将BLEU的分数提高5分以上。这是性能最好的直接S2ST模型,获得了基线性能的76%。
3.3. Subjective evaluation of speech naturalness
为了评估表2和表3中表现最好的模型的综合质量,我们使用了[15]框架,基于主观听力测试众包5点MOS评价。对每个数据集进行1k个示例的评分,每个示例由一个评分者进行评分。虽然这种评价预期与翻译的正确性无关,但翻译错误会导致低分,评价者称这些例子“不可理解”。
结果如表4所示,比较了不同的vocoders,其中Griffin-Lim的结果对应于与3.1和3.2节相同的模型配置。正如预期的那样,使用WaveRNN vocoders可以显著地将评分从Griffin-Lim提高到“非常好”的范围(4.0以上)。注意,将Griffin-Lim结果与地面真相训练目标进行比较是最公平的,因为它们是使用相应的较低质量vocoders生成的。在这样的比较中,很明显,S2ST模型的得分没有ground truth高。
最后,我们注意到Translatotron与本次评估的基线之间存在类似的性能差距。在某种程度上,这是两种模型所犯错误类型不同的结果。例如,Translatotron有时会发错单词的发音,尤其是专有名词,使用原语的发音,例如“Dan”中的/ae/元音发错为/ah/,这与西班牙语一致,但对英语听众来说听起来不那么自然,而通过构建,基线一致地将结果投射到英语中。

图2展示了行为上的其他差异,其中Translatotron复制了输入“eh”不流畅性(在图的底部一行,转录为“a”,在0.4 - 0.8秒之间),但是级联没有。同样有趣的是,cascade将“Guillermo”翻译成英语形式“William”,而Translatotron使用西班牙语名称(尽管ASR模型误译为“the ermo”),这表明直接模型可能倾向于更直接地重构输入。类似地,在对应页面的示例7中,Translatotron将“pasejo”重新构造为“passage”而不是“tickets”,这可能反映出对同源词的偏爱。我们把详细的分析留给今后的工作。
3.4. Cross language voice transfer
在最后的实验中,我们通过训练图1所示的完整模型,使用源说话者的声音合成翻译后的语音。在训练过程中,扬声器编码器以地面真实目标扬声器为条件。我们使用了第3.1节的数据子集,其中我们将源记录和目标记录配对。请注意,每对音源和目标音箱总是不同的——数据不是从双语音箱中收集的。该数据集包含606k对话语,重采样至16khz,分别包含863小时和493小时的源语和目标语;6.3万对(第3.1节的一个子集)用于测试。由于目标记录中含有噪声,我们采用[15]的去噪和音量归一化来提高输出质量。
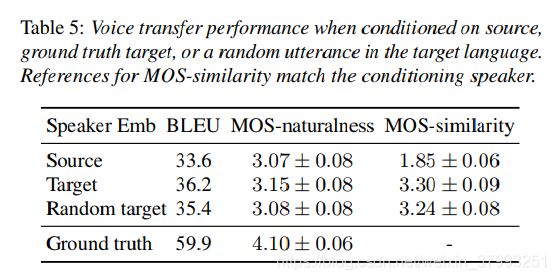
表5比较了使用不同调节策略的性能。第一行对应于将源扬声器的声音传输到翻译后的语音,而第2行是一个“欺骗”配置,因为嵌入扬声器可能会将有关目标内容的信息泄露给解码器。为了验证这不会对性能产生负面影响,我们还对第3行中的随机目标话语进行了条件设置。在所有情况下,性能都比表2和表4中针对合成目标训练的模型差。这是因为合成任意说话者的任务更加困难;训练目标更嘈杂,训练集更小;而用于评估的ASR模型对多噪声多说话者目标的误差更大。在BLEU评分方面,地面真实条件设置与随机目标之间的差异非常小,验证了潜在的内容泄漏不是一个问题(部分原因是扬声器嵌入的维度非常低)。然而,对源上的条件设置落后1.8个蓝点,反映了训练和推理配置之间条件设置语言的不匹配。在所有情况下,MOS评分都很接近。然而,对源说话人的条件设置显著降低了说话人相似度MOS超过1.4个点。这再次表明,在训练中使用英语母语者的嵌入式并不能很好地推广到西班牙语母语者。
4. Conclusions
我们提出了一个直接的语音到语音的翻译模型,训练端到端。我们发现在训练过程中使用语音转录是非常重要的,但推理并不需要中间的语音转录。该模型在两个西班牙语到英语的数据集上实现了高质量的翻译,尽管性能不如ST和TTS模型的基线级联。
此外,我们还演示了一种变体,它可以同时将源说话者的声音转换为翻译后的语音。语音传输不像在类似的TTS上下文[15]中工作得那么好,这反映了跨语言语音传输任务的难度,以及对[44]的评估。提高语音传输性能的潜在策略包括通过添加语言对抗性损失来改进说话人编码器,或者在S2ST损失中加入循环一致性术语[13]。
其他未来的工作包括利用弱监督,利用合成数据[21]或多任务学习来扩大训练规模[19,20],并将韵律等声学因素从源语转换为译文语[45-47]。
- [1] A. Lavie, A. Waibel, L. Levin, M. Finke, D. Gates, M. Gavalda, T. Zeppenfeld, and P. Zhan, “JANUS-III: Speech-to-speech translation in multiple languages,” in Proc. ICASSP, 1997.
- [2] W. Wahlster, Verbmobil: Foundations of speech-to-speech translation. Springer, 2000.
- [3] S. Nakamura, K. Markov, H. Nakaiwa, G.-i. Kikui, H. Kawai, T. Jitsuhiro, J.-S. Zhang, H. Yamamoto, E. Sumita, and S. Yamamoto, “The ATR multilingual speech-to-speech translation system,” IEEE Transactions on Audio, Speech, and Language Processing, 2006.
- [4] International Telecommunication Union, “ITU-T F.745: Functional requirements for network-based speech-to-speech translation services,” 2016.
- [5] H. Ney, “Speech translation: Coupling of recognition and translation,” in Proc. ICASSP, 1999.
- [6] E. Matusov, S. Kanthak, and H. Ney, “On the integration of speech recognition and statistical machine translation,” in European Conference on Speech Communication and Technology, 2005.
- [7] E. Vidal, “Finite-state speech-to-speech translation,” in Proc. ICASSP, 1997.
- [8] F. Casacuberta, H. Ney, F. J. Och, E. Vidal, J. M. Vilar et al., “Some approaches to statistical and finite-state speech-to-speech translation,” Computer Speech and Language, vol. 18, no. 1, 2004.
- [9] P. Aguero, J. Adell, and A. Bonafonte, “Prosody generation for speech-to-speech translation,” in Proc. ICASSP, 2006.
- [10] Q. T. Do, S. Sakti, and S. Nakamura, “Toward expressive speech translation: a unified sequence-to-sequence LSTMs approach for translating words and emphasis,” in Proc. Interspeech, 2017.
- [11] T. Kano, S. Takamichi, S. Sakti, G. Neubig, T. Toda, and S. Nakamura, “An end-to-end model for cross-lingual transformation of paralinguistic information,” Machine Translation, pp. 1–16, 2018.
- [12] M. Kurimo, W. Byrne, J. Dines, P. N. Garner, M. Gibson, Y. Guan, T. Hirsimaki, R. Karhila, S. King, H. Liang ¨ et al., “Personalising speech-to-speech translation in the EMIME project,” in Proc. ACL 2010 System Demonstrations, 2010.
- [13] E. Nachmani, A. Polyak, Y. Taigman, and L. Wolf, “Fitting new speakers based on a short untranscribed sample,” in ICML, 2018.
- [14] S. O. Arik, J. Chen, K. Peng, W. Ping, and Y. Zhou, “Neural voice cloning with a few samples,” in Proc. NeurIPS, 2018.
- [15] Y. Jia, Y. Zhang, R. J. Weiss, Q. Wang, J. Shen, F. Ren, Z. Chen et al., “Transfer learning from speaker verification to multispeaker text-to-speech synthesis,” in Proc. NeurIPS, 2018.
- [16] Y. Chen, Y. Assael, B. Shillingford, D. Budden, S. Reed, H. Zen, Q. Wang, L. C. Cobo, A. Trask, B. Laurie et al., “Sample efficient adaptive text-to-speech,” in Proc. ICLR, 2019.
- [17] A. Berard, O. Pietquin, C. Servan, and L. Besacier, “Listen and ´ translate: A proof of concept for end-to-end speech-to-text translation,” in NeurIPS Workshop on End-to-end Learning for Speech and Audio Processing, 2016.
- [18] A. Berard, L. Besacier, A. C. Kocabiyikoglu, and O. Pietquin, ´ “End-to-end automatic speech translation of audiobooks,” in Proc. ICASSP, 2018.
- [19] R. J. Weiss, J. Chorowski, N. Jaitly, Y. Wu, and Z. Chen, “Sequence-to-sequence models can directly translate foreign speech,” in Proc. Interspeech, 2017.
- [20] A. Anastasopoulos and D. Chiang, “Tied multitask learning for neural speech translation,” in Proc. NAACL-HLT, 2018.
- [21] Y. Jia, M. Johnson, W. Macherey, R. J. Weiss, Y. Cao, C.-C. Chiu, N. Ari et al., “Leveraging weakly supervised data to improve endto-end speech-to-text translation,” in Proc. ICASSP, 2019.
- [22] A. Haque, M. Guo, and P. Verma, “Conditional end-to-end audio transforms,” in Proc. Interspeech, 2018.
- [23] J. Zhang, Z. Ling, L.-J. Liu, Y. Jiang, and L.-R. Dai, “Sequenceto-sequence acoustic modeling for voice conversion,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019.
- [24] F. Biadsy, R. J. Weiss, P. J. Moreno, D. Kanevsky, and Y. Jia, “Parrotron: An end-to-end speech-to-speech conversion model and its applications to hearing-impaired speech and speech separation,” arXiv:1904.04169, 2019.
- [25] M. Guo and A. Haque, “End-to-end spoken language translation,” Stanford University, Tech. Rep., 2017. [Online]. Available: http://web.stanford.edu/class/cs224s/reports/Michelle Guo.pdf
- [26] J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang et al., “Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions,” in Proc. ICASSP, 2017.
- [27] A. F. Machado and M. Queiroz, “Voice conversion: A critical survey,” in Proc. Sound and Music Computing, 2010, pp. 1–8.
- [28] C.-C. Chiu, T. Sainath, Y. Wu, R. Prabhavalkar, P. Nguyen, Z. Chen, A. Kannan, R. Weiss, K. Rao et al., “State-of-the-art speech recognition with sequence-to-sequence models,” in Proc. ICASSP, 2018.
- [29] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. NeurIPS, 2017.
- [30] Y. Wang, R. Skerry-Ryan, D. Stanton, Y. Wu, R. J. Weiss, N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio, Q. Le et al., “Tacotron: Towards end-to-end speech synthesis,” in Proc. Interspeech, 2017.
- [31] Y. Wu, M. Schuster, Z. Chen, Q. V. Le, M. Norouzi, W. Macherey, M. Krikun, Y. Cao, Q. Gao, K. Macherey et al., “Google’s neural machine translation system: Bridging the gap between human and machine translation,” arXiv:1609.08144, 2016.
- [32] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” in Proc. ICLR, 2015.
- [33] D. Krueger, T. Maharaj, J. Kramar, M. Pezeshki, N. Ballas, N. R. ´ Ke, A. Goyal, Y. Bengio et al., “Zoneout: Regularizing RNNs by randomly preserving hidden activations,” in Proc. ICLR, 2017.
- [34] N. Shazeer and M. Stern, “Adafactor: Adaptive learning rates with sublinear memory cost,” in Proc. ICML, 2018, pp. 4603–4611.
- [35] D. Griffin and J. Lim, “Signal estimation from modified short-time Fourier transform,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 32, no. 2, pp. 236–243, 1984.
- [36] N. Kalchbrenner, E. Elsen, K. Simonyan, S. Noury, N. Casagrande, E. Lockhart, F. Stimberg, A. v. d. Oord, S. Dieleman et al., “Efficient neural audio synthesis,” in Proc. ICML, 2018.
- [37] A. Zhang, Q. Wang, Z. Zhu, J. Paisley, and C. Wang, “Fully supervised speaker diarization,” arXiv:1810.04719, 2018.
- [38] M. Post, G. Kumar, A. Lopez, D. Karakos, C. Callison-Burch et al., “Improved speech-to-text translation with the Fisher and Callhome Spanish–English speech translation corpus,” in Proc. IWSLT, 2013.
- [39] J. Shen, P. Nguyen, Y. Wu, Z. Chen et al., “Lingvo: a modular and scalable framework for sequence-to-sequence modeling,” 2019.
- [40] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” in ACL, 2002.
- [41] K. Irie, R. Prabhavalkar, A. Kannan, A. Bruguier, D. Rybach, and P. Nguyen, “Model unit exploration for sequence-to-sequence speech recognition,” arXiv:1902.01955, 2019.
- [42] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “LibriSpeech: an ASR corpus based on public domain audio books,” in Proc. ICASSP, 2015.
- [43] A. van den Oord, Y. Li, I. Babuschkin, K. Simonyan, O. Vinyals, K. Kavukcuoglu, G. van den Driessche et al., “Parallel WaveNet: Fast high-fidelity speech synthesis,” in Proc. ICML, 2018.
- [44] M. Wester, J. Dines, M. Gibson, H. Liang et al., “Speaker adaptation and the evaluation of speaker similarity in the EMIME speech-to-speech translation project,” in ISCA Tutorial and Research Workshop on Speech Synthesis, 2010.
- [45] Y. Lee and T. Kim, “Robust and fine-grained prosody control of end-to-end speech synthesis,” arXiv:1811.02122, 2018.
- [46] Y. Wang, D. Stanton, Y. Zhang, R. Skerry-Ryan, E. Battenberg, J. Shor et al., “Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis,” in Proc. ICML, 2018.
- [47] W.-N. Hsu, Y. Zhang, R. J. Weiss, H. Zen, Y. Wu, Y. Wang, Y. Cao, Y. Jia, Z. Chen, J. Shen et al., “Hierarchical generative modeling for controllable speech synthesis,” in Proc. ICLR, 2019