彻底Sparse!基于稀疏交互机制的端到端检测器
摘要:
Sparse R-CNN基于R-CNN框架,其提出了一种一对一稀疏交互的机制,同时借鉴了DETR的可学习候选目标的思想,并且结合二分匹配的标签分配策略和集合预测的形式,实现了端到端目标检测的效果,整个过程无需RPN和NMS。
前言
这段时间的paper不是E2E(End-to-End)就是Transformer,什么都拿Transformer往上套,然后个个都声称自己E2E,看得CW都有点“审美疲劳”。
吾以为,Transformer并非关键,更不是E2E的必需所在,从NLP拓展到CV来应用,可以表扬下Transformer从单纯的“器”发展成为一种“术”,但是否成为“道”还请拭目以待。
至于是否E2E,有个很直观的关键点在于是否干掉了NMS,而追溯下导致NMS的原因,无非还是Label-Assignment!因为当下流行的大多数目标检测方法都是one-to-many的标签分配策略,这是导致NMS的最直接原因之一。
在近期众多E2E系列的目标检测方法中,CW之所以选中了 Sparse R-CNN 这个R-CNN家族的新晋小生,是因为它并未用到Transformer,同时又实现了E2E,原因也正如上面所说:它采用的是one-to-one的Label-Assignment。
有点搞笑的是,虽说它隶属于R-CNN家族,但从思想以及方法(甚至代码实现)上来看,其更像是 DETR: End-to-End Object Detection with Transformers(文末提取链接a) 的小弟,为何?
因为它采用了DETR的optimal bipartite matching(二分匹配)的标签分配策略和set prediction形式,同时又借鉴了DETR中learnable object query的思想,从而无需设计密集的目标候选(如anchor)。
当然,它的得意之处在于摒弃了DETR中让object query和全局特征图(密集)交互(即每个object query都和特征图的每个位置交互计算,这本质上属于dense)的Transformer attention机制,而是提出了一种稀疏(sparse)的交互形式。
基于上述,Sparse R-CNN之所以自称'sparse'在于两方面:sparse candidates & sparse feature interaction。
附:Paper & Code(文末提取链接b)
1
研究动机与主要贡献
在正式讲解Sparse R-CNN的方法前,先来“吹吹水”,了解下作者的研究动机是什么,这其实是很重要的一part。只有发现了以往方法的问题所在,你才能(创造性地去)解决问题!
可惜的是,从小到大,学校往往只是不问缘由地教给我们解决问题的手段,却根本没有教我们如何发现问题。
因此,在学习一种新方法的同时,还需要了解这种方法诞生的背景,再倒回来评估新方法的合理性,甚至提出自己的猜想并且进行实验,最终再对这个过程总结归纳。CW认为,不断重复这样的学习方式,能够有效地培养我们的洞察力和创造力。
作者很优秀,他发现当前目标检测的主流方法往往存在dense属性:anchor-boxes(anchor-based系列)、 reference-points(anchor-free系列)、dense RoIs(2-stage系列),这伴随着诸如以下的“麻烦事”:
1. prior candidates(如anchors)的设计;
2. one(gt)-to-many(positive)的标签分配策略;
3. nms后处理(由于第2点)
于是,作者很自然地想到能不能设计一种sparse的框架。幸运的是,DETR的出现给出了一种启发:candidates可以是一组sparse的learnable object queries,标签分配策略是one-to-one的optimal bipartite matching,这样就无需nms。
然而,如前文所述,DETR在特征交互计算时本质上也是使用了dense的方法。抓住这点,作者觉得可以发paper了(原谅我说得那么露骨哈哈哈)!
除了sparse candidates,他还想实现sparse feature interaction,结合自身天赋并且通过努力,最终提出了Sparse R-CNN。作者也自豪地认为,他延续了目标检测方法的“生态史”:dense -> dense-to-sparse -> (thoroughly)sparse:
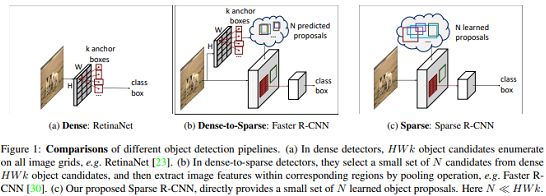
Sparse R-CNN的创新点有以下:
1. 使用可学习的proposal boxes充当RoI角色,从而无需RPN;
2. 引入维度更高(相比proposal boxes)的可学习proposal features,用于弥补粗糙的proposal boxes提取出来的RoI features不足以表征丰富的物体特征(如姿态和位置等)的缺点;
3. 改进了原生的r-cnn head,设计出dynamic instance interactive head,主要用于对RoI feautures与proposal features执行一对一的稀疏交互(而非DETR那种全局密集交互),其中前者相当于Key、后者相当于Query的角色。
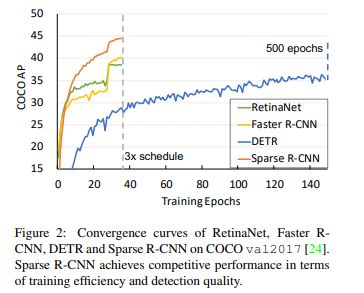
整体来看,其特点和贡献也多多:没有anchors和reference points、没有rpn、无需正负样本采样、无需nms后处理、效果比他家族老大Faster R-CNN好、收敛速度远远快于他老哥DETR。
在标准的COCO benchmark上使用ResNet-50 FPN单模型在标准3 x training schedule的情况下达到了44.5 AP 和 22 FPS。
2
整体架构与算法pipeline
吹了一波,是时候讲下Sparse R-CNN是怎么操作的了。先概述下整体的架构设计,并且把算法pipeline过一遍,然后再具体到各方面去剖析吧。
既然Sparse R-CNN隶属于R-CNN家族,那么它的网络设计原型就和R-CNN系列相似:第一阶段先得到RoI(只不过这里不需要RPN,而是直接设置一个可学习的嵌入向量,同时也没有对RoI做前背景的二分类和采样);第二阶段结合backbone提取的feature map通过池化得到统一大小的RoI特征图,输入检测头部做最终的分类和回归预测。
以上是它在R-CNN家族中继承的性质,至于其它方面,概括地来说,主要以下几点:
(1). Backbone是ResNet,Neck使用FPN;
(2). Head使用一组级联的Dynamic Instance Interactive Head,这个头部是对原R-CNN Head的改进。在级联组中,上一个head的输出特征和预测框分别作为下一个head的Proposal Features和Proposal Boxes。
另外,Proposal Features在与RoI Features交互之前会先经过Multi-Head-Self-Attention(此处和Transformer的Decoder十分类似,在交互之后还会经过FFN,即整个过程是:self-attention+cross-attention+ffn);
(3). 训练的损失函数是基于optimal bipartite matching的set prediction loss,沿用了DETR那一套,只不过在代码实现中,针对使用focal loss的情况做了改动。
整体的框架设计基本就这样,现在来过下算法的pipeline:
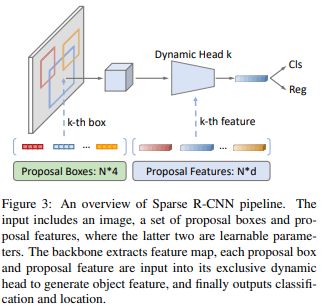
i. 设置N个可学习候选框Proposal Boxes用于提供RoI坐标(可使用Pytorch的nn.Embedding(N, 4)实现);
ii. 设置N个可学习的候选实例特征Proposal Features来表征更丰富的物体信息(特征),例如姿态和形状等等(可使用Pytorch的nn.Embedding(N, hidden_dim)实现);
iii. 将任意大小的图片输入CNN,得到输出特征图(包含多尺度的FPN特征);
iv. 通过RoIPooling(Align)将每个Proposal Boxes池化到统一大小的RoI Features;
v. 将RoI Features与Proposal Features进行一对一交互,从而增强前景特征;
vi. 增强后的特征Object Features作为表征各个目标对象的特征,经过全连接层得到固定大小的特征向量,输出N个无序集合,每个集合中包括预测类别和预测框;
vii. 采用Casecase R-CNN的级联思想,不断对预测框进行refine。其中,前一阶段的预测框和Object Features分别作为下一阶段的Proposal Boxes和Proposal Features
训练期间,对每个级联阶段的输出信息都使用匈牙利双边匹配计算分类及回归loss来进行训练(深监督)。
3
具体方法
pipeline过完,现在来具体讲讲里面的主要部分。当然,这次同样按照CW一贯的风格,会结合核心代码来解析。
Learnable Proposal Boxes: 稀疏的目标候选
可学习Proposal Boxes维度是(N,4),其中N是预设的超参,代表每张图片最多可检测出多少个物体,也就是目标候选数量;4对应的是候选框坐标信息(cxcywh or xyxy)。这些设置作者经过了实验测试:
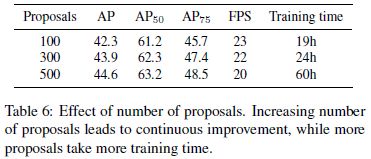
考虑到性能与训练时间,最终作者选择将N设置为300。
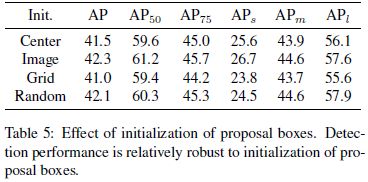
-center表示将proposal boxes初始化在图像中心位置,中心坐标为(0.5,0.5),wh全部设置为0.1(图像尺寸为1,这里是将wh设置为图像的0.1倍),即所有框的大小都是原图的0.01(0.1x0.1)倍,最终1个proposal box表示为(0.5,0.5,0.1,0.1);
-Image表示将proposal boxes初始化为图像本身,此时size=1,于是表示为(0.5,0.5,1,1);
-Grid表示RoI按照类似anchor一样密集排列在原图上,例如[(0,0,0.1,0.1), (0,1,0.1,0.1), ..., (32/图片w,32/图片h,0.1,0.1)...],和G-CNN中使用的方法相同;
-Random表示中心坐标和宽、高均采用高斯分布随机初始化
而Proposal Boxes的初始化方式对性能的影响相对较小,这应该得益于可学习性,使得整体框架也更灵活和鲁棒。最终,作者采用了和DETR相同的表示方式:归一化的cxcywh值,值域是0-1。
需要注意的是,Proposal Boxes是不包括batch信息的,也就是说这个(N,4)矩阵存储的不是当前一张图片信息,而是要学习整个数据集相关的RoI统计信息,学到的是训练集中潜在的目标物体位置的统计分布,其被视作对图像中目标物体最可能存在区域的初始猜测。
作者认为,使用RPN来得到RoI是非常“奢侈”的(相当于多加了一个模型做预测),而RoI的主要作用是提供丰富的候选框位置,保证召回率,并不需要十分精确,只要满足合理的相关分布即可。
因此,作者觉得能得到一个合理的和数据集相关的统计信息就足够了,最终就采用了这可学习的Proposal Boxes来充当RoI的角色,从而在整体架构中无需RPN。
作者采用了Pytorch的nn.Embedding进行代码实现:

也可以用以下这种方式:
self.init_proposal_boxes = nn.Parameter
(torch.Tensor(self.num_proposals, 4))
Learnable Proposal Features: 更给力地表征物体特性
可学习的Proposal Features维度是(N,256),其中N的意义和Proposal Boxes中一致,它和Proposal Boxes是一对一的关系,同时也表征了整个数据集实例特征的统计信息。
之所以引入Proposal Features,是因为作者考虑到仅靠4d的Proposal Boxes提供的RoI Features难免过于粗糙,不足以表征物体深层次的特征信息(如物体姿态和形状等),于是有必要额外引入这个高维度(256d)的Proposal Features,目的是希望通过这个可学习的嵌入向量编码更丰富的实例的特征。
Proposal Features在这里类似于DETR中Object Query的角色,Object Query在DETR中是可学习的位置编码(position encoding),指导Decoder关注全局特征图的哪些位置,同时全局特征图还要加上位置编码,否则性能会大幅下降。
然而,在Sparse R-CNN中,Proposal Features和Proposal Boxes(对应的RoI Features)一对一进行交互(而非DETR中让Object Query和全局特征图的每个位置进行交互),并且Proposal Boxes本身已包含了在全局特征图中的位置信息,Proposal Features则作为Proposal Boxes对应(位置)的物体的丰富特征,因而在不需要空间位置编码的同时也能够实现特征过滤与增强。

同样地,对于Proposal Features的代码实现,作者也采用了Pytorch的nn.Embedding:
![]()
Dynamic Instance Interactive Head: 稀疏的特征交互
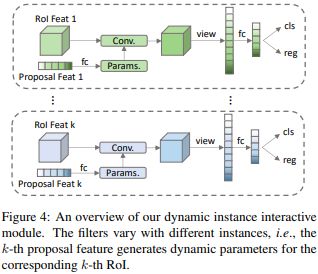
该模块是对R-CNN Head的改进:在RoI池化后插入了动态实例交互(Dynamic Instance Iteractive)模块,用于将RoI Features和Proposal Features进行一对一交互,目的是实现特征过滤和增强。
前面说过,Proposal Features的角色相当于DETR的Object Query,由于Object Query是和全局特征图(作为Key)交互,和全局特征图一样,RoI Features也提供了位置信息,因而RoI Features也可看作是Key。
但是DETR中的交互是为了让各目标物体关注其在全局特征图中的有效特征位置,而这里的RoI Features如前面所述已经包含了在全局特征图的对应位置信息,这些特征本身就对应各个局部位置,同时和Proposal Features又是一对一交互,那么这里的交互究竟是在做甚?
其实,RoI Features中本身还有“更进一步”的位置信息:RoI Features是池化特征,通常为统一的7x7大小,这7x7个bin就是进一步的位置信息!
因此,这里Proposal Features和RoI Features进行交互是为了关注7x7个bin中对前景更有贡献的那些位置,从而更有利于之后的分类和回归。
核心思想已明确,现在举个例子来形象说明下整个交互过程:
1). 暂时不考虑batch对应的维度,假设RoI Features的shape是(300,7,7,256),300是proposals个数,7x7是统一后的池化特征大小,256是表示每个特征空间位置的表征向量维度;Proposal Features的shape是(300,256);
2). 将Proposal Features先经过自注意力模块,这是为了推理出各物体相互之间的关系(和DETR中一样);
3). 然后由Proposal Features生成卷积参数:使用全连接层将最后一维由256变为2x64x256,接着切分成shape为(300,256,64)和(300,64,256)两部分,这也是称为“动态交互”的原因,因其参数是动态生成的;
4). 接着进行交互:将shape为(300,7x7,256)的RoI Features按序和以上两部分进行矩阵乘法,输出的shape是(300,7x7,256),这个结果就隐含了各目标对应的7x7个位置中哪些位置才是应该关心的,对前景更有贡献的位置将有更高的输出值。
注意,在第一个维度(300)上RoI Features和Proposal Features是一对一进行交互计算的!因此这也是称为“实例级交互”的原因;
以上3&4这种交互操作称为动态卷积,作者是受到 Dynamic filter networks 启发。
5). 最后,这个结果(先经过全连接层变换维度)还要加(element-wise add)在Proposal Feautures上(并且归一化),得到过滤和增强后的特征表示,作为抽象的物体特征。
仔细品味下以上过程,不觉得和Transformer的Decoder十分相似吗!?
其中2是一样的,将Query先经过self-attention;3+4实质上就是Query和Key的交互计算,为的是实现特征过滤和增强,只不过这里将Multi-Head-Attention替换成动态卷积的方式(同时也没有Value,因为这里计算出来的结果本身就是过滤和增强后的特征表示,而非权重系数,所以不需要将计算结果应用在Value上);5就相当于是Add&Norm。
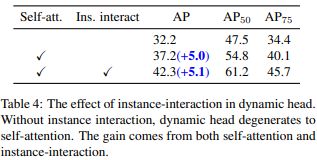
所以说嘛,Sparse R-CNN就像是DETR的小老弟,虽然没有用Transformer,但套路是一样的。作者通过实验证实了2~4过程对性能带来的提升:
以上过程的代码实现如下:
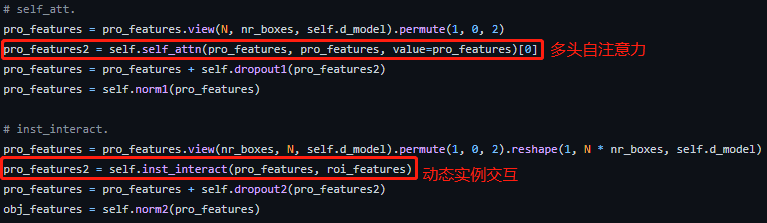
其中N代表batch size,nr_boxes代表预设的目标数量(300),d_model是嵌入维度(256)。至于自注意力层和实例交互则如下:

现在来看看最关键的动态卷积是如何实现的:

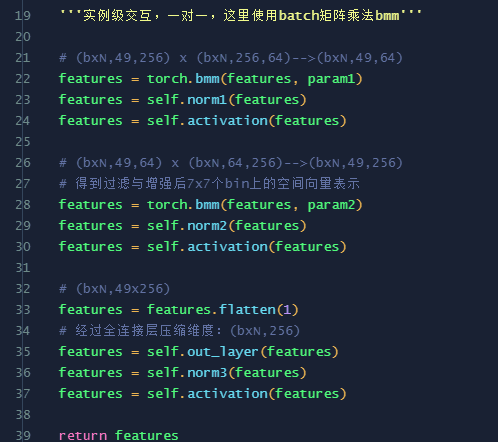
代码非常简单易懂,CW的注释应该已经足够说明了。返回的features就是上面pro_features2。
交互之后还会经过一个FFN(前向反馈网络),真的和DETR那套太像了..

其实连作者也觉得像,于是他还与Transformer对比了一把:

结果证明,它这个动态头部比较牛逼。
最后,既然它是个头部,那么肯定需要进行预测(分类+回归):
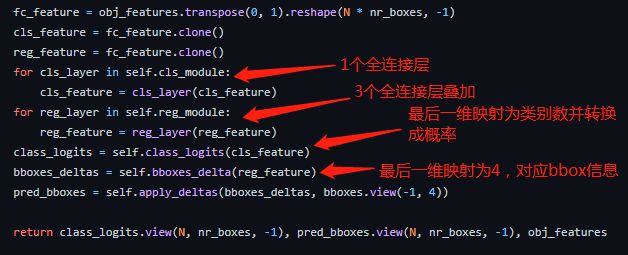
代码也非常直观易懂,看注释就OK。
这一节该说的就这些了,最后我想吐槽下这节最上面那幅图。从图上看,每个RoI Features和Proposal Features一对一交互后都会分别送入独立的头部进行预测,作者在paper中也是这么说的:
Each RoI feature is fed into its own exclusive head for object location and classification, where each head is conditioned on specific proposal feature.
但实际是,代码中并不是这么写的!通过上述就可以知道,想要仔细印证的话也可以自己去看看这部分源码:DynamicHead(文末提取链接c),如果是CW看错了,还望反馈给我,并且狠狠抽我一巴掌,谢谢!
Cascade R-CNN Head: 级联大法好,Coarse-to-Fine
级联大法好哇,作者在paper中也是这么说的:
Iteratively updating the boxes is an intuitive idea to improve its performance.
对于级联本身,并没有什么好说的,就拿上一个头部的输出送入到下一头部再进行预测呗,整个相当于是由粗到细(Coarse-to-Fine)的过程。
另外,每个头部的参数是独立的。但是,关键就在于应该拿上一个头部输出的什么送入到下一个头部?
理所当然地,我们会想到预测框,但仅仅如此的话,作者发现带来的性能提升并不明显:
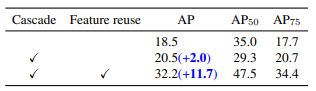
作者观察到,一个候选框对应的目标在整个级联迭代过程中通常是不变的,那么为何不把上一个头部输出的目标特征也一并送入下一个头部呢!毕竟这些目标特征可是编码了丰富的物体特征信息(如姿态、形状和位置等)啊!
这么想之后,作者也试了一把,果然,飞涨了11.7个点(见上图中Feature reuse打钩那行)!
此外还有个细节,需要看代码才知道:

注意到红框部分,上一个head的预测框在输入到下一个head前要取消梯度!这样的话,就只有第一个head的梯度能够回传至proposal boxes,而后面的head只能让proposal features进行学习。对于这个问题,CW是这么看的:
你想想,Sparse R-CNN是R-CNN家族的,也就是说它带有2-stage性质。第一阶段会学习RoI,但第二阶段RoI已经作为先验的角色(相当于anchor),也是不再进行学习的。作者在这里的设置或多或少也有这样的味道。
这么看来,Proposal Boxes和RPN的RoI一样,只需提供一个粗糙的结果即可,后面会有第二阶进行精调(这里是级联head,不断学习Proposal Features)。
在github上看到有的人疑惑:即使是第一个head,Proposal Boxes由于经过了RoI Pooling/Align,因此这部分是无法回传梯度的,那么到底是怎么让Proposal Boxes进行学习的呢?
RoI Pooling/Align确实无法回传梯度,但是在bbox解码时会需要Proposal Boxes参与计算啊,这时候就能够回传梯度了,Proposal Boxes也是在此获得学习的机会的(其实Faster R-CNN在第二阶段也可以的,只不过其将解码过程写在no_grad过程里了,而这里并没有)。
这部分代码就是上一节展示的预测部分中的self.apply_deltas()方法,和常规的bbox解码无异,这里就不再展示了。
另外,作者还实验了级联头部的数量对最终性能的影响:
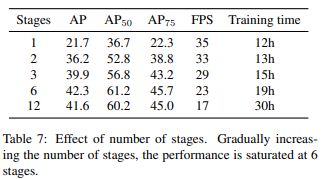
根据实验结果,最终选择级联6个头部。
4
总结与思考
我们知道,R-CNN系列的2-stage方法通常有更高的精度,但是检测速度也相对不如1-stage,毕竟其需要前一个阶段(RPN)来预测RoI。
然而,Sparse R-CNN受到DETR的learnable object query启发,直接开挂般设置一组可学习的嵌入向量作为RoI,从而干掉了RPN,也是十分大胆!
另外,在最近万物皆Transformer的形势下,Sparse R-CNN保持了自己的个性,使用动态卷积的方式来做交互计算,并且是局部而非Transformer般的全局交互(因此也不需要全局空间的位置编码)!
进一步提升了计算效率,也彻底地做到了SPARSE(必须大写以表扬下~)。这篇paper的思想给R-CNN方法乃至E2E Object Detection领域无疑都是能带来创造性的启发。
另外,CW突然想到一个点,如上所述,虽然Sparse R-CNN在没有加入空间位置编码的情况下依然能做到特征过滤和增强,但是不妨猜想下,如果是加入“局部”空间位置编码呢:即对池化特征7x7个bin附加对应的位置编码(这个位置编码看作是数据集池化特征中隐含的局部位置的统计分布),会不会达到更强的特征过滤和增强效果?如果有兴趣,各位哥们儿也可是实验下,同时也欢迎反馈交流!
作者简介
CW,毕业于中山大学(SYSU)数据科学与计算机学院,就职于腾讯技术工程与事业群(TEG)从事Devops工作,曾在AI LAB实习,实操过道路交通元素与医疗病例图像分割、视频实时人脸检测与表情识别、OCR等项目。
目前在一些自媒体平台上参与外包项目的研发工作,项目专注于CV领域(传统图像处理与深度学习方向)。
参考链接
a.https://arxiv.org/pdf/2005.12872.pdf
b.Paper & Code:
https://arxiv.org/abs/2011.12450
https://github.com/PeizeSun/SparseR-CNN
c.https://github.com/PeizeSun/SparseR-CNN/blob/main/projects/SparseRCNN/sparsercnn/head.py
本文来自作者CW的原创投稿,如有任问题请及时留言,我们会第一时间处理。