yolov5学习笔记(毕业设计)
yolov5学习笔记
- 一,基本准备
-
- 1.配置基本环境
- 2.程序跑起来
- 3.核心代码解读和自定义训练目标
- 二,训练yolov5神经网络
-
- (1,本地训练yolov5
-
- 1, 首先把进程改为0,不然有的电脑会出错
- 2,基本参数设置及解析
- 1.1
- 2,利用云端GPU训练yolov5
-
- 1.1
- 1.1
- 1.1
- 创建一个表格
-
- 设定内容居中、居左、居右
- SmartyPants
- 创建一个自定义列表
- 如何创建一个注脚
- 注释也是必不可少的
- KaTeX数学公式
- 新的甘特图功能,丰富你的文章
- UML 图表
- FLowchart流程图
- 导出与导入
-
- 导出
- 导入
一,基本准备
你好! 这是我第一次使用 yoloV5,首先下载yolov5开源代码,
附加网址:https://github.com/ultralytics/yolov5
1.配置基本环境
pycharm终端输入下载的解压文件 requirements.txt 里面第一句话,批量安装所需要的库
附:如果你有多个版本python,可以指定python版本安装库
3.6版本安装:pip3.6 install -U -r requirements.txt
3.7版本安装:pip3.7 install -U -r requirements.txt
2.程序跑起来
- 选择下载的文件包解压,点击detect.py文件运行,程序就首先跑起来了.
3.核心代码解读和自定义训练目标
add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
参数解释:
name or flags - 一个命名或者一个选项字符串的列表,以-开头
action - 命令行遇到参数时的动作,默认值是 store,store_const,表示赋值为const;
nargs - 应该读取的命令行参数个数,可以是具体的数字,或者是?号,当不指定值时对于 Positional argument 使用 default,对于 Optional argument 使用 const;或者是 * 号,表示 0 或多个参数;或者是 + 号表示 1 或多个参数
type - 参数类型,如int
default - 当参数未在命令行中出现时使用的默认值
dest - 用来指定参数的位置
choices - 用来选择输入参数的范围。例如choice = [1, 5, 10], 表示输入参数只能为1,5 或10
help - 用来描述这个选项的作用
————————————————————————————————————————————————————————————————————————————————————————
```javascript
关键代码:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5x.pt', help='model.pt path')
#需要训练的源文件地址,想要训练其他文件可以拷贝到改文件夹下面或者更改下面文件路径即可
parser.add_argument('--source', type=str, default=r'inference\images', help='source') # file/folder, 0 for webcam
#训练结果输出地址
parser.add_argument('--output', type=str, default='inference/output', help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
#概率大于多少显示识别结果 如0.4表示权重大于0.4显示识别结果
parser.add_argument('--conf-thres', type=float, default=0.4, help='object confidence threshold')
#default=0.5表示只有大于0.5重合才才显示框框重合
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--fourcc', type=str, default='mp4v', help='output video codec (verify ffmpeg support)')
#device表示训练设备
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
#action只要设置了action就变为True
parser.add_argument('--view-img', action='store_true', help='display results')
#训练结果保存为.txt文件
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
#指定多个赋值
parser.add_argument('--classes', nargs='+', type=int, help='filter by class')
#增强的nms
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
#
parser.add_argument('--augment', action='store_true', help='augmented inference')
opt = parser.parse_args()
二,训练yolov5神经网络
(1,本地训练yolov5
1, 首先把进程改为0,不然有的电脑会出错
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
改为
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
————————————————————————————————————————————
2,基本参数设置及解析
#参数初始化,yolov5s.pt表示已经训练好的文件,若从头开始则选择为空
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
改为:
parser.add_argument('--weights', type=str, default=' ', help='initial weights path')
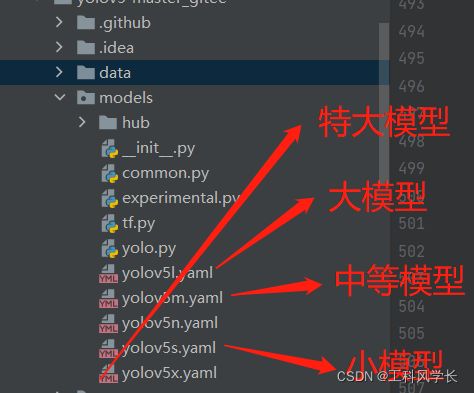
为了训练快一点,选择小模型吧
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
————————————————————————————————————————————
#
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
1.1
2,利用云端GPU训练yolov5
1.1
1.1
1.1
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。1
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎