【Python】字符串、列表和字典的查找、修改和排序
三月里刷了一些华为机试的算法题,想就三个经常处理的数据对象字符串、列表和字典做些小结,以促掌握。
主要关注查找类、修改类和排序类这三类操作。
如何创建?
| 对象 | 索引 | 描述 |
|---|---|---|
| 字符串 | .index(a) 返回第一个符合a的下标值 | ‘ABC’ |
| 列表 | .index(a) 返回第一个符合a的下标值 | [1,2,3] |
| 字典 | .key( ) 返回键列表 \quad .value( )返回值列表 | {1:‘A’,2:‘B’,3:‘C’} |
简单地说:
字符串 就是用一对单引号或一对双引号括起来的任意内容。
列表 就是用一对方括号括起来的任意内容彼此以逗号为间隔的排列。
字典 就是用一对花括号括起来的键值对,其中键和值可以分别视作两个列表,但键中的元素是不可迭代的,即通常选择字符或数字作为唯一的键。
下面展示一下如何将一个字符串和列表拼接为一个字典。
输入:
# 采用zip方法
a,b = 'A2C',[1,'B',3]
c = dict(zip(a,b))
print(c)
print(c.items())
print(list(c.values()))
# 也可采用循环迭代
d = {}
for i in range(3):
d[a[i]] = b[i]
print(d)
输出:
{'A': 1, '2': 'B', 'C': 3}
dict_items([('A', 1), ('2', 'B'), ('C', 3)])
[1, 'B', 3]
{'A': 1, '2': 'B', 'C': 3}
两点说明:
一是zip()方法将可迭代的对象打包成了元组,而通过对元组的转换就能得到相应的字典,这较写一个循环迭代结构去实现操作更简洁了。
二是许多方法的返回值是特定的对象,将其转换为我们熟悉的类型,要加一步转换函数,如dict()、list( )。
查找类
Q1:如何在字符串中查找某个字符串并统计个数?
仅就这两项功能而言,in操作和count()方法提供了简洁的实现方案,而这种实现对于列表也是可行的。
输入:
string = 'abcyhfaxvhwsadADAXQ'
# string = list('abcyhfaxvhwsadADAXQ')
if 'a' in string:
print('true')
print(string.count('a'))
输出:
true
3
从上例推测,字符串很可能只是元素均为字符的一种列表,又如当你尝试拆分和拼接这类字符元素时,split()和join()方法提供出的简洁性。
输入:
a = 'Good morning, Xiao Ming!'.split(' ')
print(' '.join(a))
输出:
Good morning, Xiao Ming!
Q2:如何在字符串中查找某些含不确定性的字符?
在涉及更高级的字符串的操作时,往往可以考虑re模块提供的正则表达式。
例如现在考虑这样一个问题,找出 ‘adexaHFQhbcweyaXVWVaecce’ 中满足’a?‘的所有字符,其中’?'表示一个任意字符。
输入:
import re
put = 'adexaHFQhbcweyaXVWVaecce'
result = re.findall(pattern='a.',string=put)
print(result)
输出:
['ad', 'aH', 'aX', 'ae']
应当提醒:正则表达式将会给字符串的操作带来极大便利。
Q3:如何查找字典的元素在列表中的对应值?
这并不是一个困难的问题,利用索引index即可解决。而在无法确定字典是否含该key时,使用get()方法,因若直接使用[ ]将可能产生KeyError。
输入:
a,b = 'A2C',[1,'B',3]
c = dict(zip(a,b))
d = ['right','wrong','done']
# 找到 b中元素c['2']的索引值,再查找出d中对应的元素
print(d[b.index(c['2'])])
输出:
wrong
利用平行索引解决列表间的对应问题,其中隐藏了一个预先的平行编号机制,即第index号的各项属性应是如何如何的。而这就好比一个隐性字典,即列表在考虑index后,就像是一种以数字作为键值的特殊字典。
一个关系图
于是,笔者就此做了一个以列表为核心,常见Python数据对象间的关系图。
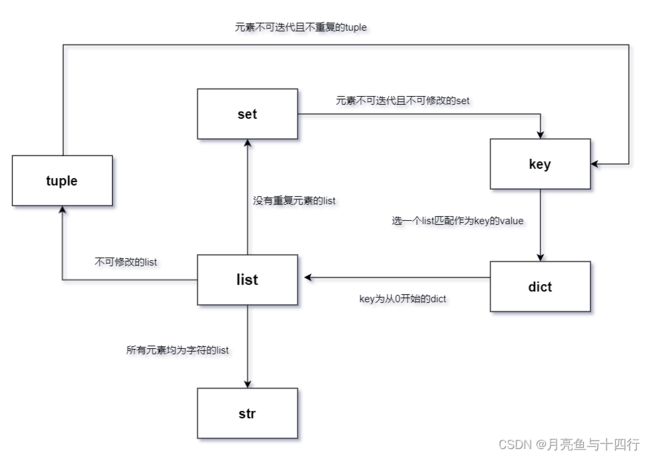
修改类
所谓修改,即增、删、换,数据对象本身的内置函数通常就可解决这些问题。
Q4:如何实现字符串的增删换操作?
首先讨论增的问题,字符串支持‘+’运算,可在末尾直接加上新字符,这种拼接同样也可使用join()方法实现。
将字符串转换成列表后,用insert()方法可实现在指定位置处的元素增加。当然也可将进一步转换成元素替换的问题,但这样会有一定局限性,如采用str.replace()方法时,某次只能局限在前k个的元素添加。不过,问题的这种相互转换性正是尤其值得我们关注的。
输入:
a = 'cecdva'
# 直接用+号,末尾+
a += 'a'
print(a)
# 如果在指定位置添加,需转换列表后用insert()方法添加
b = list(a)
b.insert(2,'6')
print(''.join(b))
# 或考虑为一种特殊的替换操作
# 在第一个c后加入一个‘W’
c = a.replace('c','cW',1)
print(c)
输出:
cecdvaa
ce6cdvaa
cWecdvaa
接下来再讨论删的问题,strip()方法常用于删除字符串两端的特定元素,可视作只删除左端lstrip()方法和只删除右端rstrip()的方法的组合。
考虑到字符串其实是一种特殊的字符列表,所以其实也可以通过索引来进行一些修改和拼接。
输入:
a = 'cecdva'
# 删除两端的'c'
b = a.strip('c')
print(b)
# 后两步均实现删除'd'
# 利用索引修改,需先转换成列表
c = list(a)
c[3] = ''
print(''.join(c))
# 索引拼接
d = a[:3]+a[-2:]
print(d)
输出:
ecdva
cecva
cecva
既然增可转换成一种特殊的换,删亦然,即对于字符串而言,核心的问题其实就是换。为此我们有必要关注re.sub()方法和str.translate()方法,它们同str.replace方法一样,都是换的方法。
输入:
import re
# 将'c'和'v'替换成'A'
a = 'cecdva'
b = re.sub(pattern=r'[^ad-e]',repl='A',string=a)
print(b)
# 将'acdev'逐次映射为'12345'
intab = 'acdev'
outtab = '12345'
trantab = str.maketrans(intab,outtab)
c = a.translate(trantab)
print(c)
输出:
AeAdAa
242351
深入运用sub()方法和translate()方法,可进一步了解正则表达式和bytes对象,可以说:这两种方法足够实现字符串的增删换操作,因为本质上所谓增删换都是换概念下的映射关系。即:
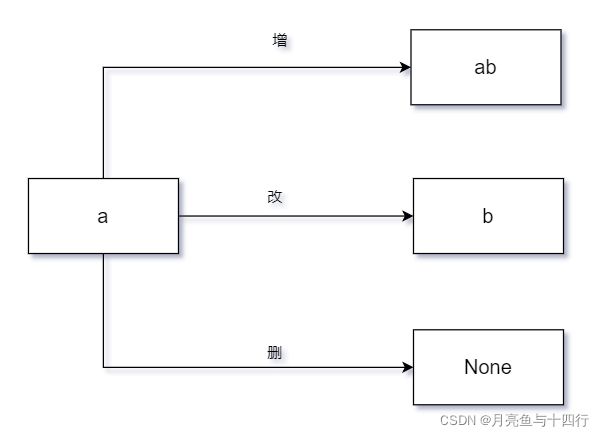
Q5:如何实现列表的增删换操作?
增加列表元素一般有3种方法,即append()方法,extend()方法和insert()方法。
append()方法将添加的项目视作整体加入列表,extend()方法则对元组和列表网开一面,会将其中的每个元素逐个加入列表,但它们都只在列表末尾加入新元素。insert()方法在指定索引位置处加入新元素。
输入:
a = [1,2,3,4,5]
#添加单个元素
a.append(10)
print(a)
# append()将列表视作一个整体
a.append([8,9,10])
print(a)
# extend()逐个添加进元组中的元素
a.extend((8,9,10))
print(a)
# 在末尾前加入一个新元素
a.insert(-1,100)
print(a)
输出:
[1, 2, 3, 4, 5, 10]
[1, 2, 3, 4, 5, 10, [8, 9, 10]]
[1, 2, 3, 4, 5, 10, [8, 9, 10], 8, 9, 10]
[1, 2, 3, 4, 5, 10, [8, 9, 10], 8, 9, 100, 10]
删除列表元素一般有4种方法,即del指令,pop()方法,remove()方法和clear( )方法。
del方法依据索引进行删除,pop()方法也依据索引删除,remove()方法可删除特定元素,clear()方法清空列表。
输入:
a = [1,2,3,4,5]
# 删除索引为0的元素
del a[0]
print(a)
# 删除索引为1的元素
a.pop(1)
print(a)
# 删除元素5
a.remove(5)
print(a)
# 清空列表
a.clear()
print(a)
输出:
[2, 3, 4, 5]
[2, 4, 5]
[2, 4]
[]
修改列表元素既可以直接从索引出发进行修改,也可以借助列表迭代式生成一个新的列表。
输入:
a = [1,2,3,4,5]
# 将索引1处的元素改成20
a[1] = 20
print(a)
# 偶数乘上10,奇数减去1
b = [x*10 if x%2 == 0 else x-1 for x in a]
print(b)
输出:
[1, 20, 3, 4, 5]
[0, 200, 2, 40, 4]
不难看出,对于小规模的列表操作,如单条件单循环下,列表迭代式将能保持住一行代码的简洁。
前文表达了列表在数据对象中居于核心地位的观点,所以对于其他数据对象如集合和字典,概念也就大同小异,只是实现方法名称略有不同。
一个比较表
| 操作 | 列表 | 集合 | 字典 |
|---|---|---|---|
| 增 | append(),extend(),insert() | add(),update() | 键值对,update() |
| 删 | del,pop(),remove(),clear( ) | del,pop(), discard() , remove(),clear() | del, pop(),clear() |
| 换 | 索引,列表迭代式 | 先删后加 | 键值对,update() |
排序类
Q6:如何实现列表的排序操作?
常见的两种方法是sort()方法和sorted()函数。
sort()方法不会创建新列表,sorted()函数则是返回一个排序过后的列表对象。
输入:
a = [2,7,5,6,3,4]
# reverse后为降序
b = sorted(a,reverse=True)
# 默认升序
a.sort()
print(a)
print(b)
输出:
[2, 3, 4, 5, 6, 7]
[7, 6, 5, 4, 3, 2]
但一般情况下你可能碰到更复杂的情形,比如对于字符串’xedrewgt413245>?{’,要求你按照ASCALL表排序重新输出。
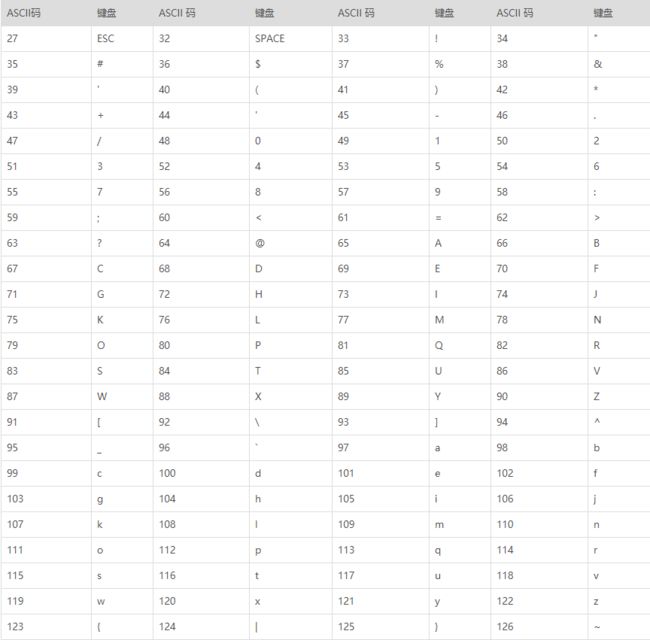
当然转换成list后排序,结果似乎没得说,因为我们依旧可以使用列表的排序功能。
输入:
a = list('xedrewgt413245>?{')
# reverse后为降序
b = sorted(a,reverse=True)
print(b)
输出:
{xwtrgeed?>544321
但以上的排序均内置了一个排序标准,即要么是数字的大小顺序,要么是ASCALL表中的前后顺序,即一个内置的前后顺序对于排序函数的使用是必要的。
但如果再随意些,是我们自定义生成了一个码簿,那么运用列表迭代式将实现得更灵活。比如:‘acdev’→’16345’,要求将字符串’cecdvadac’重新升序排列后输出。
输入:
a = 'cecdvadac'
# 将'acdev'逐次映射为'16345'
intab = 'acdev'
outtab = '16345'
# 法一:用映射
# 编码
trantab = str.maketrans(intab,outtab)
b = list(a.translate(trantab))
b.sort()
b = ''.join(b)
# 解码
trantab = str.maketrans(outtab,intab)
c = b.translate(trantab)
print(c)
# 法二:列表迭代
# 编码
b = [outtab[intab.index(x)] for x in a]
b.sort()
# 解码
c = [intab[outtab.index(x)] for x in b]
print(''.join(c))
输出:
aaddevccc
aaddevccc
如果进一步宣布码簿中的某些码字无效,那么在列表迭代式中用 if语句 也将很容易地实现。
Q7:如何实现对字典的排序操作?
在关于字典的排序问题中,如何分离键和值进行排序是一个基本命题。
通过.keys()和.values()方法,我们能比较轻松地拆分出这两个列表,而这两个分离出的列表其实恰恰对应了原先的一种码簿,所以一种可行的解决思路就会是:

当然sorted()函数也提供了常见的解决方案,此时需借助lambda匿名函数实现分选键和值的作用。
输入:
# 需确保为同一类型
a,b = 'A2C',['1','B','3']
c = dict(zip(a,b))
print(c)
# 按键降序
c1 = sorted(c.items(),key = lambda d:d[0],reverse = True)
print(dict(c1))
# 按值降序
c2 = sorted(c.items(),key = lambda d:d[1],reverse = True)
print(dict(c2))
输出:
{'A': '1', '2': 'B', 'C': '3'}
{'C': '3', 'A': '1', '2': 'B'}
{'2': 'B', 'C': '3', 'A': '1'}