卷王登场:yoloV5视频流处理LoadImages与box_label
目录
预测部分:detect.py
超参数讲解:
寻找与视频流有关的函数
LoadImages函数讲解:
拆分解读:
第一个模块:
第二个模块:
第三个模块:
第四个模块:
第五个模块:
Annotator函数
解读box_label函数:
一年级的小demo:
结果:
结语:
引言:人生不是一场短跑,在失败的过程中还需要不断看向远方
预测部分:detect.py
要找到对视频流或者图片流处理的函数,首先要知道它被用于什么地方。就像烹饪一份的美食要知道什么时候放入调味料。
# YOLOv5 by Ultralytics, GPL-3.0 license
"""
Run inference on images, videos, directories, streams, etc.
Usage - sources:
$ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
"""
import argparse
import os
import sys
from pathlib import Path
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
@torch.no_grad()
def run(
weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Stream results
im0 = annotator.result()
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=r'E:\yolov5-master\runs\train\exp3\weights\best.pt',
help='model path(s)')
parser.add_argument('--source', type=str, default=r'C:\Users\m\Desktop\img/',
help='file/dir/URL/glob, 0 for webcam') # 图片
parser.add_argument('--data', type=str, default=r'E:\yolov5-master\data\myvoc.yaml',
help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.7, help='confidence threshold') # 置信度 原0.25
parser.add_argument('--iou-thres', type=float, default=0.5, help='NMS IoU threshold') # iou 原0.45
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
超参数讲解:
这里挑几个重点参数:
weights: --需要的模型地址
source: --图片或视频的存放地址
data: --训练数据集的配置文件
imgsz: --图片的大小
conf_thres: --置信度的阈值
iou_thres: --最大值抑制的阈值
max-det: --最大的搜索框数量
device: --指定gpu或cpu训练
project: --保存指定的文件目录
name: --保存的文件名字
通过以上参数可以知道有关视频流图片流的参数为:source
寻找与视频流有关的函数
通过ctrl+f全局查找source可以看到有16个有关选项
is_file 与 is_url 适用于判断数据是以网页的形式下载还是通过本地文件夹的形式传输
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs通过这里可以看到,我们的图片是通过LoadImages这一函数进行处理 ctrl+左键进入函数内部
LoadImages函数讲解:
该函数主要负责的是图片或者视频的处理
拆分解读:
第一个模块:
p = str(Path(path).resolve()) # os-agnostic absolute path
if '*' in p:
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p):
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p):
files = [p] # files
else:
raise Exception(f'ERROR: {p} does not exist')这个模块主要是用于判断加载文件的位置,判断句:如果采用正则表达式提取图片或视频,可以使用glob获取文件路径,如果path是一个文件夹,使用glob获取这个文件夹路径,如果他是一个文件(这里的文件则只单张图片或者单个视频)则直接获取,如果以上都没有,则提示报错信息:文件不存在
第二个模块:
images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
ni, nv = len(images), len(videos)
self.img_size = img_size
self.stride = stride
self.files = images + videos
self.nf = ni + nv # number of files
首先分别提取图片和视频的路径images,videos
获取图片和视频的数量ni,nv
定义输入图片的尺寸,将图片和视频整合到一个列表中,随后罗列出总数
第三个模块:
self.video_flag = [False] * ni + [True] * nv
self.mode = 'image'
self.auto = auto
if any(videos):
self.new_video(videos[0]) # new video
else:
self.cap = None
assert self.nf > 0, f'No images or videos found in {p}. ' \
f'Supported formats are:\nimages: {IMG_FORMATS}\nvideos: {VID_FORMATS}'判断是否为视频,方便后面单独做视频处理
如果是视频,那么对视频模块做初始化,cap=cv2.videoVaoture() 否则 为None
第四个模块:
def __next__(self):
if self.count == self.nf: # ==self.nf代表视频读取结束
raise StopIteration
path = self.files[self.count] #获取视频的路径
if self.video_flag[self.count]: # 日自拍该文件是视频
# Read video
self.mode = 'video' #修改mode为video
ret_val, img0 = self.cap.read()#获取视频画面,直到视频结束
while not ret_val: #循环读取下一个没有获取的视频
self.count += 1
self.cap.release() #释放资源
if self.count == self.nf: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
self.frame += 1 #当前读取的帧数
s = f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: '改模块为视频流的处理段落,详细请看注释视频中比如早期的人流量检测划分区域,就这这里进行。
第五个模块:
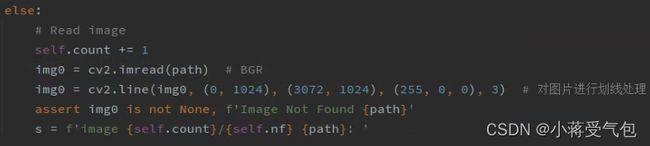
else:
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR
img0 = cv2.line(img0, (0, 0), (1000, 1000), (255, 0, 0), 3) # 对图片进行划线处理
assert img0 is not None, f'Image Not Found {path}'
s = f'image {self.count}/{self.nf} {path}: '
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride, auto=self.auto)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)这里是对图片的处理跟上述一样 这里我随便对图像做了一个处理

视频流的划线部分处理以及坐完 接下来看一下Annotator部分
Annotator函数
同理找到我们预测位置的坐标也是在detasets中查找
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)代码中这里是关于预测结果的框框,那么框框的x,y,w,h,那么我们在哪里寻找。
annotator.box_label函数,ctrl+左键进入到box_label函数中
解读box_label函数:
def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
# Add one xyxy box to image with label
# 参数box参数为X,Y,W,H
#if判断标签是否为二进制的读取,如果是的话,利用二进制的形式进行绘制
if self.pil or not is_ascii(label):
self.draw.rectangle(box, width=self.lw, outline=color) # box
if label:
w, h = self.font.getsize(label) # text width, height
outside = box[1] - h >= 0 # label fits outside box
#绘制矩形
self.draw.rectangle(
(box[0], box[1] - h if outside else box[1], box[0] + w + 1,
box[1] + 1 if outside else box[1] + h + 1),
fill=color,
)
# self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
else: # cv2 否则利用opencv进行绘制 这里的P1,P2为坐标的位置
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
# print(p1,p2) #######
cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
if label:
tf = max(self.lw - 1, 1) # font thickness
w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
outside = p1[1] - h - 3 >= 0 # label fits outside box
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
cv2.putText(self.im,
label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
0,
self.lw / 3,
txt_color,
thickness=tf,
lineType=cv2.LINE_AA)一年级的小demo:
解读完后我们可以稍微做一个一年级的小demo:

结果:

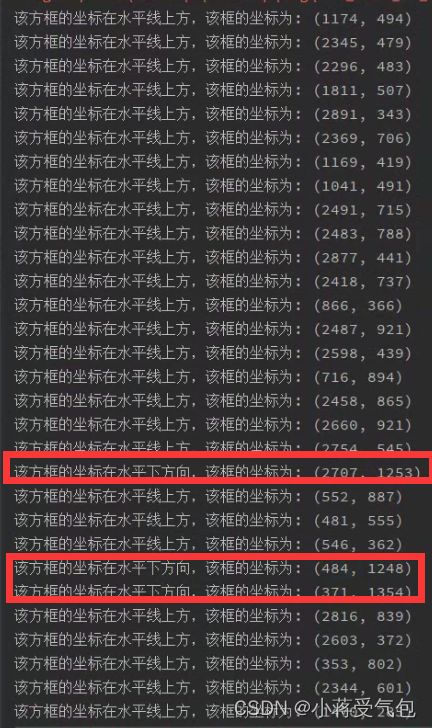
根据图片我们可以看到,有三个anocher框在下方,跟我们得到的结果一样,有聪明的同学发现右下方一个最大号的anocher出于改蓝色水平线的交界处为何按照上方处理,这里是因为我们的坐标点是anocher的左上方标记处,所以判断为该水平线的上方。
这里主要看一下判断里面的东西,其中else的判断中P1,P2为box的x,y,w,h 利用好box的坐标就以与我们上面对图像处理的部分做结合,关于如何判断,可以参考我的另一篇博客高空抛物这里是采用最基本的opencv做的一个针对性不强的目标检测,但是里面可供学习的东西还是比较不错的希望这篇博客的东西给大家一点启发
结语:
在这里提前祝大家五一假期愉快。别忘了点个赞哦·~
