整理学习之深度可分离卷积
一、分组卷积
分组卷积Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。
普通卷积:
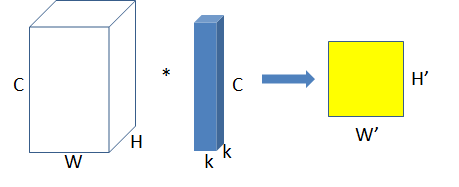
分组卷积
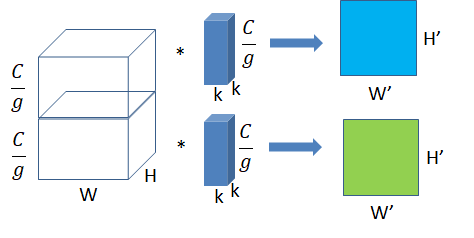
将图一卷积的输入feature map分成g组,每个卷积核也相应地分成组,在对应的组内做卷积
图中分组数,即上面的一组feature map只和上面的一组卷积核做卷积,下面的一组feature map只和下面的一组卷积核做卷积。每组卷积都生成一个feature map,共生成2个feature map。
输入feature map尺寸: 分别对应feature map的宽,高,通道数;
单个卷积核尺寸: 分别对应单个卷积核的宽,高,通道数;
输出feature map尺寸 :输出通道数等于卷积核数量,输出的宽和高与卷积步长有关。
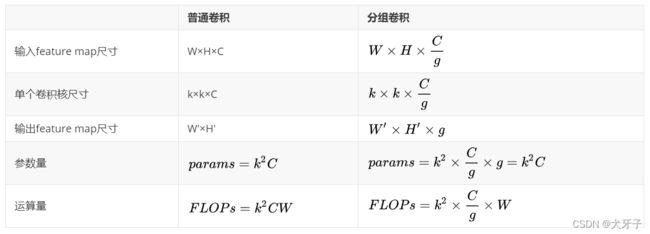
可以看到,分组卷积可以用同等的参数量运算量生成g个feature map
group conv常用在轻量型高效网络中,因为它用少量的参数量和运算量就能生成大量的feature map,大量的feature map意味着能够编码更多的信息!
从分组卷积的角度来看,分组数g就像一个控制旋钮,最小值是1,此时g=1的卷积就是普通卷积;最大值是输入feature map的通道数C,此时g=C的卷积就是depthwise sepereable convolution,即深度分离卷积,又叫逐通道卷积。
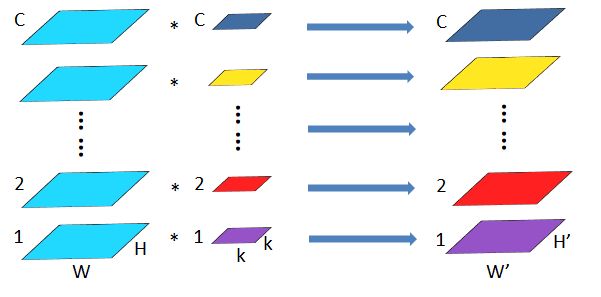
深度分离卷积是分组卷积的一种特殊形式,其分组数是feature map的通道数。即把每个feature map分为一组,分别在组内做卷积为,组内一个卷积核生成一个feature map。这种卷积形式是最高效的卷积形式,相比普通卷积,用同等的参数量和运算量就能够生成个feature map,而普通卷积只能生成一个feature map。
所以深度分离卷积几乎是构造轻量高效模型的必用结构。
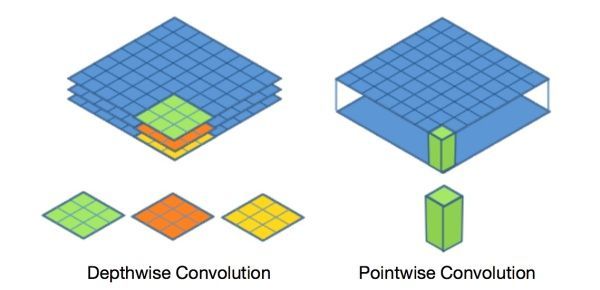
深度可分离卷积
深度可分离卷积 = 深度卷积(Depthwise Convolution) + 逐点卷积(Pointwise Convolution)。
深度可分离卷积将一个核分裂成两个独立的核,分别做两个卷积:深度卷积和点向卷积。
为什么一定要同时考虑图像区域和通道?我们为什么不能把通道和空间区域分开考虑?
深度可分离卷积提出了一种新的思路:对于不同的输入channel采取不同的卷积核进行卷积,它将普通的卷积操作分解为两个过程。
常规普通卷积
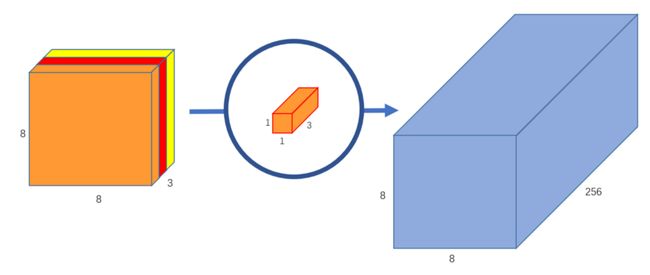
假设我们有一个12x12x3像素的输入图像,我们对图像做一个5×5的卷积,不加填充,步幅为1。如果我们只考虑图像的宽度和高度,卷积过程是这样的:12×12 – (5×5) – >8×8。我们最终得到一个8×8像素的图像。
由于图像有3个通道,卷积核也需要有3个通道。这意味着,不是做5×5=25次乘法,而是内核每移动一次时做5x5x3=75次乘法。
我们对每25个像素做标量矩阵乘法,输出一个数字。在经过5x5x3内核之后,12x12x3图像将变成8x8x1图像。
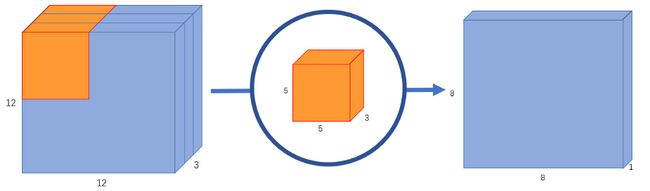
如果我们想增加输出图像中的通道数量呢?如果我们想要大小为8x8x256的输出呢?
我们可以创建256个内核来创建256个8x8x1图像,然后将它们堆叠在一起,创建出8x8x256图像输出。

这就是正常卷积的工作原理。
深度可分离卷积将这个过程分为两部分:深度卷积和点向卷积。
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map
第1部分-深度卷积:
在第一部分深度卷积中,我们在不改变深度的情况下,对输入图像进行了分组卷积。我们使用3个5x5x1形状的内核。
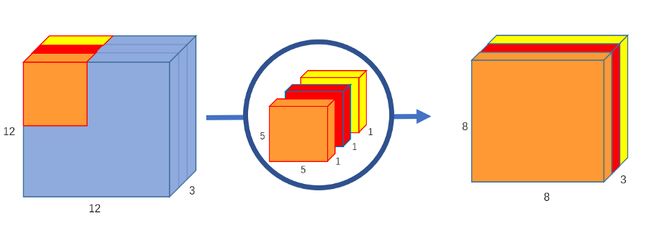
每个5x5x1内核迭代图像的1个通道(注意:1个通道,而不是所有通道),得到每25个像素组的标量积,得到3个8x8x1图像。将这些图像叠加在一起可创建8x8x3图像。
第2部分-点向卷积:
逐点卷积就是1x1的普通卷积。
因为深度卷积没有融合通道间信息,所以需要配合逐点卷积使用。
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map
原始卷积将12x12x3图像转换为8x8x256图像。目前,深度卷积已经将12x12x3图像转换为8x8x3图像。现在,我们需要增加每个图像的通道数。
点向卷积之所以如此命名是因为它使用了一个1×1内核,我们通过1x1x3内核迭代8x8x3图像,得到8x8x1图像。
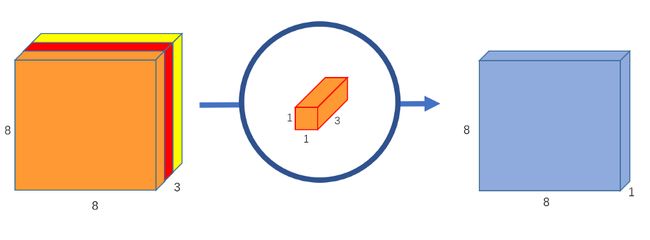
我们可以创建256个1x1x3内核,每个内核输出一个8x8x1图像,全部叠加到一起得到形状为8x8x256的最终图像。
就这样,我们把卷积分解成2步:深度卷积和点向卷积。
更抽象地说,如果原始卷积函数是12x12x3 – (5x5x3x256)→8x8x256,
我们可以将这个新的卷积表示为12x12x3 – (5x5x1x3) →8x8x3 – > (1x1x3x256) – >8x8x256。
三、深度可分离卷积的优势
我们来计算一下计算机在原始卷积中要做的乘法的个数。有256个5x5x3内核可以移动8×8次。这是256x5x5x3x8x8 = 1228800 次乘法。
可分离卷积呢? 在深度卷积中,我们有3个5x5x1的内核它们移动了8×8次。也就是3x5x5x1x8x8 = 4800。在点向卷积中,我们有256个1x1x3的内核它们移动了8×8次。这是256x1x1x3x8x8 = 49152。把它们加起来,就是53952次乘法。
52,952比1,228,800小很多。计算量越少,网络就能在更短的时间内处理更多的数据。
在普通卷积中,我们对图像进行了256次变换。每个变换都要用到5x5x3x8x8=4800次乘法。在可分离卷积中,我们只对图像做一次变换——在深度卷积中。然后,我们将转换后的图像简单地延长到256通道。不需要一遍又一遍地变换图像,可以节省计算能力。
主要参考:
https://www.jianshu.com/p/a936b7bc54e3
https://blog.csdn.net/zwqjoy/article/details/103384367