课程向:深度学习与人类语言处理 ——李宏毅,2020 (P28-2)
Audio BERT
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
图片均截自课程PPT、且已得到李宏毅老师的许可:)
考虑到部分英文术语的不易理解性,因此笔记尽可能在标题后加中文辅助理解,虽然这样看起来会乱一些,但更好读者理解,以及文章内部较少使用英文术语或者即使用英文也会加中文注释,望见谅
深度学习与人类语言处理 P28-2 系列文章目录
- Audio BERT
- 前言
- I Audio BERT
-
- 1.1 Introduction 概述
- 1.2 wav2vec 第一类语音BERT应用
- 1.3 SLU BERT 第二类语音BERT应用
- 1.4 Mockingjay 第三类语音BERT应用1
-
- 1.4.1 MASK 掩码操作
- 1.4.2 Input 输入处理
- 1.4.3 Architecture 模型结构
- 1.4.4 Downstream Tasks 后续任务
-
- 1.4.4.1 Feature Extraction 抽取特征
- 1.4.4.2 WS 每层都加权和
- 1.4.4.3 Fine-tune 微调
- II State-of-Art 前沿研究
-
- 2.1 Adversarial Defense 语音攻防
-
- 2.1.1 Adversarial Attack 敌手攻击
- 2.1.2 Attack 攻击
- 2.1.3 Defence 防御
前言
在上半篇P28-1中,我们学习了过去自监督学习在语音中的应用,主要分为两大类:CPC和APC,两类是根据不同的损失函数划分的。在下一半篇P28-2中将讲解BERT在语音中如何自监督使用。
而下半篇P28-2本篇中,我们将学习BERT预训练模型在语音上的应用,主要有三大类:wav2vec、SLU BERT、Mockingjay,以及语音BERT的前沿研究热点。
I Audio BERT
1.1 Introduction 概述

CPC和APC这两大类已在上半篇讲完,本篇将开始进入BERT应用在语音上的方法。
方法五花八门,如上图,我们会一个接一个进行学习它们的差异和不同。
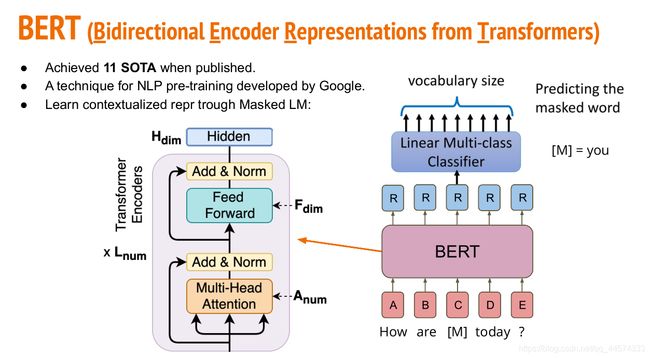
首先,让我们回顾一下文字中BERT的训练方法,就是预测[MASK]词汇。在BERT模型里面就是Transformer Encoder。
使用BERT辅助有监督学习其实也算是一种半监督学习方式,因此以下的各种方法都是半监督学习。
1.2 wav2vec 第一类语音BERT应用

如上图a,通过CNN+GRU对声音讯号编码得到向量Z,中间通过wav2vec来处理向量得到一个语音版的token,再通过这个语音版token去做后面语音的token预测。
wav2vec,如上图右下,核心思想就是通过Gumbel、argmax等操作,将编码后的语音向量用有限个token中的一个表示,相当于为我们的语音做了一个语音词汇表,在FaceBook中用了三万多个token,就是上图右下的e。
在经过wav2vec后,语音向量就变成了一个个token组成的序列,如上图左下,通过wav2vec得到语音的语音token向量表示。这时我们就可以通过一个文字版的BERT,这个BERT的词汇表就是上述的三万多个token。训练方式和文字一样,训练完成后这个BERT就可以当作语音的Encoder或者是用来提取特征等等。
总结而言,wav2vec就是把语音变成有限个token表示,再根据这些token来训练一个文字版的BERT。
但注意的是,这是个两阶段训练,我们要先训练wav2vec后再训练BERT。之后讲的将都是一阶段的训练,一次就可以把BERT应用在模型上。
1.3 SLU BERT 第二类语音BERT应用
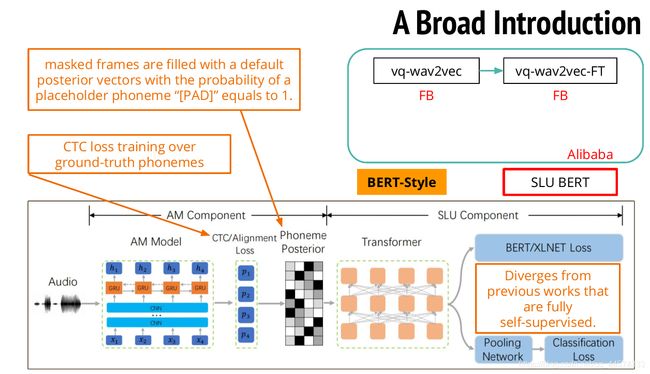
SLU BERT ,第二类语音BERT应用,它也是很特别的一种,因为上述应用BERT的wav2vec的损失函数和CPC一样,之后要将的第三类语音BERT应用的损失函数和APC一样。
SLU BERT的处理方式是这样的,输入一段声音讯号,经过一个Acoustic Model 声学模型,该模型是由CNN和GRU组成,会训练一个CTC Alignment的损失值,当然这里是需要label标签的。经过CTC方式训练后可得到每个音素的概率表,而此时就可以用BERT来做MASK,预测被MASK掉的概率值。
SLU BERT和其他的模型方法不同,它并不是一个完全的自监督模型,因为它需要标签来先训练一个声学模型,之后才能再通过BERT进行自监督学习。
1.4 Mockingjay 第三类语音BERT应用1
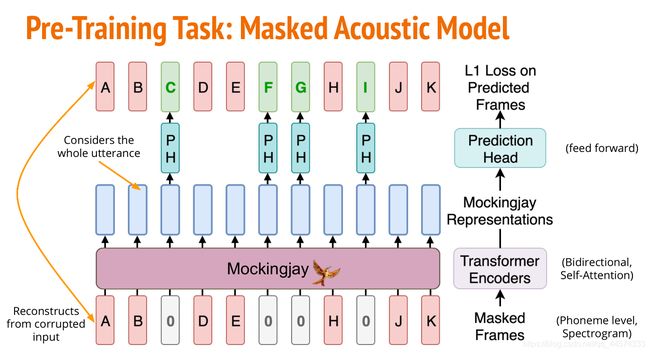
1.4.1 MASK 掩码操作
对于一串真实的Frames声音序列,我们就可以用MASK方法,将其中一些frame掩码为0。再将这些声音序列通过Mockingjay,也就是Transformer Encoders进行编码得到对应的声音向量表示。再通过Prediction Head预测还原出原本MASK掉的原本的frame,损失函数便是原本输入和重构还原的差别。
其中MASK的操作和BERT使用的一样,每次随机选15%的frames进行三种可能的操作:
- Mask:80%,将随机选择的frames进行MASK操作,都改为0
- Replace:10%,替换被随机选择的frame
- Nothing:10%,不变
1.4.2 Input 输入处理

和离散的文字不同的是,我们需要对于连续的语音进行特殊处理。因为语音讯号可能非常长且稀疏,因此我们需要这样两种处理方式:
- Downsampling :比如我们有一排长度为9的输入,就把每三个叠起来,这样长度就缩短成3,且没有丢失讯息。
- Consecutive masking :如果我们仅仅随机MASK掉一个frame的话,很可能这个被MASK掉的左右两边frame包含了这个frame的讯息,这样模型是学不到什么的,因此我们MASK掉一定长度的frame。
1.4.3 Architecture 模型结构
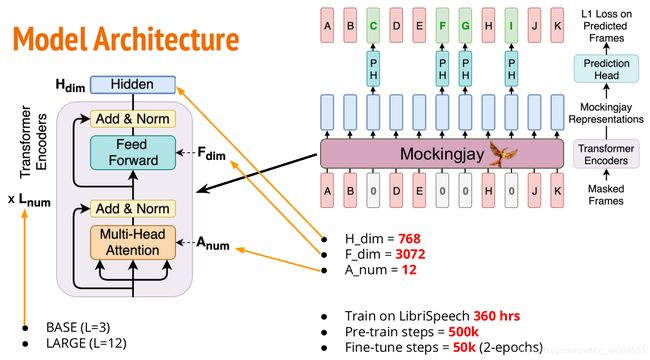 模型的结构和详细参数请见上图
模型的结构和详细参数请见上图
1.4.4 Downstream Tasks 后续任务
1.4.4.1 Feature Extraction 抽取特征

类似于文字版BERT,语音版的BERT在预训练结束后,也有各种用法。
第一种方法是提取特征,如上图,输入的是声音讯号,经过预训练好的Mockingjay得到语音向量表示,且这个过程是锁定的,不再对Mockingjay进行微调。这些语音向量就直接被用作下游任务的输入。
1.4.4.2 WS 每层都加权和

第二种方法是对Mockingjay中的很多层中对每一层都取出语音向量表示,再对每一层都做加权求和得到最终的语音向量,这个权重参数是训练得来的。
1.4.4.3 Fine-tune 微调
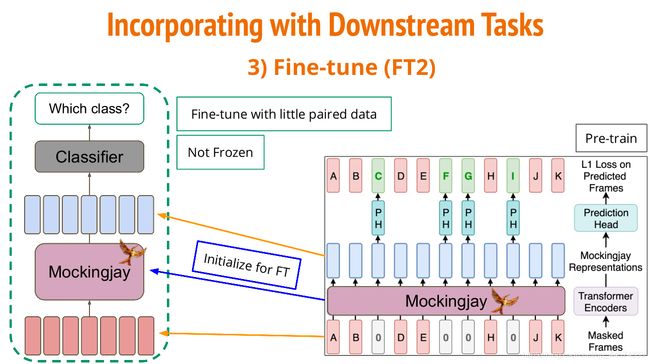
第三个方法就是Fine-tune微调,也是大家熟悉的类似的BERT微调方式,在预训练好Mockingjay后,拿来初始化,然后在具体任务中进行整个模型的训练。
Mockingjay还有一个进阶版的模型TERA,原本的BERT是作用在时间轴上的,但其实还有两个轴的:Channel 和 Magnitude,将MASK扩展到这两轴上。核心思想就是由一个轴的MASK延伸到三个轴。
II State-of-Art 前沿研究
2.1 Adversarial Defense 语音攻防
2.1.1 Adversarial Attack 敌手攻击

首先,让我们先来了解什么是Adversarial Attack 敌手攻击,如上图,假如我们有一张熊猫的图片,人为添加一定比例的噪音,对于人类观察而言这张照片还是熊猫,但是此时模型可能就辨识为长臂猿,甚至可能性非常高,这就是一种成功的敌手攻击。
这样的技术可以用在各种不同的AI安全系统上,如面部识别、语音识别等,这还是一个蛮热门的主题,有人研究怎么做攻击,有人研究怎么做防御。

而在语音上的攻防是类似上图这样的,某人的声音是可以用来设置声纹锁。这样别人的声音是无法解锁这个声纹锁的,但是我们今天如果用录音或者TTS合成的声音是有可能解锁的。
所以在声纹锁上还会再加上两个模型:
- Anti-Spoofing Model:将一段声音里的录音或者是合成的声音剔除掉,并将剩下的声音再输入给下一个语者验证模型中。
- Speaker Verification Model:判断剔除后的声音进行语者辨识。
那我们该怎么攻击上述的声纹锁呢?
2.1.2 Attack 攻击

原本我们的 Audio Playback 录音会被Anti-Spoofing模型判断为Spoofing伪音,但是我们想要这个模型辨识为非伪音。我们会在录音上加入一定的噪音得到一段攻击声音,而我们的训练目标便是通过梯度下降方法更新优化这个噪音,使得录音加噪音被判断为非伪音的概率更高,其实这个方法的成功率还是蛮高的。
2.1.3 Defence 防御

而我们刚刚将的Mockingjay就可以做到防御作用,将Mockingjay放在Anti-Spoofing前面。
以上便是本篇,BERT预训练模型在语音上的应用,主要有三大类:wav2vec、SLU BERT、Mockingjay,以及语音BERT的前沿研究热点。