pytorch简单神经网络搭建和训练实例
文章目录
- 1. 背景
- 2. 数据格式转换
- 3. 网络搭建
- 4. 模型训练
- 5. 预测
- 6. 总结
1. 背景
使用pytorch的框架搭建一个简单多分类神经网络模型,解决水果分类问题。本文包括对数据格式的转换、网络构架、模型训练、预测,并未进行后续的优化,目的在于对流程的熟悉。
2. 数据格式转换
从原始数据到标准格式的一系列处理
#导入包
import pandas as pd
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder,MinMaxScaler, StandardScaler
import torch.nn as nn
import torch.nn.functional as F
import torch
from torch import optim
from torch.utils.data import Dataset,DataLoader
# 加载数据
data=pd.read_csv('/Users/guidongzhang/Desktop/Data Mining/fruit/Date_Fruit_Datasets.csv')
# 数据标准化
def normalize(x):
scaler = StandardScaler()
return scaler.fit_transform(x)#fit_transform 是fit和transform的结合
# 特征选择
def selectFeatures(x,y,n):
select=SelectKBest(k=n)#chi2
return select.fit_transform(x,y)
# 提取特征和标签
y=data['Class'].values
X=data.drop('Class',1)
X=normalize(X)
SelectedFeatures=selectFeatures(X,y,10)
# target one-hot编码
encoder = OneHotEncoder()
encoder.fit(y.reshape(len(y), 1))
y = encoder.transform(y.reshape(len(y), 1))
y=y.toarray()
# 分隔训练集测试集
x_train,x_test,y_train,y_test=train_test_split(SelectedFeatures,y,test_size=0.2)
# 转换为tensor张量
x_train=torch.tensor(x_train,dtype=torch.float)
x_test=torch.tensor(x_test,dtype=torch.float)
y_train=torch.tensor(y_train,dtype=torch.float)
y_test=torch.tensor(y_test,dtype=torch.float)
下面要进行一步重要的转换,为了训练的方便,我们先要将数据转化为torch.utils.data中的Dataset类,再转化为DataLoader类。
首先创建一个Dataset的子类,必须包含__init__ __getitem__ __len__。其中__getitem__ 的作用是给定index能输出对应的特征及标签, __len__ 输出数据的长度。DataLoader将Dataset对象或自定义数据类的对象封装成一个迭代器,同时可以实现多进程、shuffle、不同采样策略,数据校对等等处理过程。
由于我的数据并非图像数据,流程做了一定简化,详细查看Pytorch构建数据集。
# 构建Dataset数据集
class MyDataset(Dataset):#需要继承torch.utils.data.Dataset
def __init__(self,feature,target):
super(MyDataset, self).__init__()
self.feature =feature
self.target = target
def __getitem__(self,index):
item=self.feature[index]
label=self.target[index]
return item,label
def __len__(self):
return len(self.feature)
# 封装成DataLoader对象
bs=64
train_data=MyDataset(x_train,y_train)
train_data=DataLoader(train_data, batch_size=bs, shuffle=True)
3. 网络搭建
典型的卷积神经网络通常由以下三种层结构共同组成:卷积层(Convolution)、下采样池化层(Pooling)、全连接层(Fully connected),以及激活函数。由于我们的例子是简单多分类问题,不需要卷积和池化操作,使用线性全连接层和非线性激活函数即可。
在这里使用两层全连接层,第一层的激活函数使用ReLU,第二层使用Sigmoid。
class Model(nn.Module):#继承nn.Module
def __init__(self,in_features,out_features):
super().__init__()
self.linear1 = nn.Linear(in_features, 10, bias = True)
self.linear2 = nn.Linear(10, out_features, bias = True)
self.relu=nn.ReLU()
self.sig=nn.Sigmoid()
def forward(self, x):
s=self.linear1(x)
s=self.relu(s)
s=self.linear2(s)
s=self.sig(s)
return s
打印出的网络结构:
Model(
(linear1): Linear(in_features=20, out_features=10, bias=True)
(relu): ReLU()
(linear2): Linear(in_features=10, out_features=7, bias=True)
(sig): Sigmoid()
)
4. 模型训练
模型训练分为几个流程:
- 定义损失函数和优化器
- 完成向前传播
- 计算损失
- 反向传播
- 梯度更新
- 梯度清零
损失函数使用平均绝对误差(MAE),优化算法使用随机梯度下降(SGD)。我们将这个流程封装起来。batchdata为dataloader类数据,lr为学习率,gamma为优化算法参数,epochs为遍历次数。
def fit(net, batchdata, lr, gamma, epochs):
# 损失函数
criterion = nn.L1Loss()
# 优化算法
opt = optim.SGD(net.parameters(), lr = lr, momentum = gamma)
# 监视进度
samples = 0
# 监视准确度
corrects = 0
# 全数据训练几次
for epoch in range(epochs):
# 对每个batch进行训练
for batch_idx, (x,y) in enumerate(batchdata):
# 正向传播
sigma = net.forward(x)
# 计算损失
loss = criterion(sigma, y)
# 反向传播
loss.backward()
# 更新梯度
opt.step()
# 梯度清零
opt.zero_grad()
# 监视进度:每训练一个batch,模型见过的数据就会增加x.shape[0]
samples += x.shape[0]
#每200个batch和最后结束时,打印模型的进度
if (batch_idx + 1) % 200 == 0 or batch_idx == (len(batchdata) - 1):
# 监督模型进度
print("Epoch{}:[{}/{} {: .0f}%], Loss:{:.6f} ".format(
epoch + 1
, samples
, epochs*len(batchdata.dataset)
, 100*samples/(epochs*len(batchdata.dataset))
, loss.data.item()))
设置参数并开始训练:
# 设置随机种子
torch.manual_seed(51)
# 实例化模型
net = Model(10,7)
# 学习率
lr = 0.15
# 优化算法参数
gamma = 0.8
# 每次小批次训练个数
bs = 64
# 整体数据循环次数
epochs = 50
# 生成数据
train_data=MyDataset(x_train,y_train)
train_data=DataLoader(train_data, batch_size=bs, shuffle=True)
# 训练模型
fit(net, train_data, lr, gamma, epochs)
打印进度及损失:
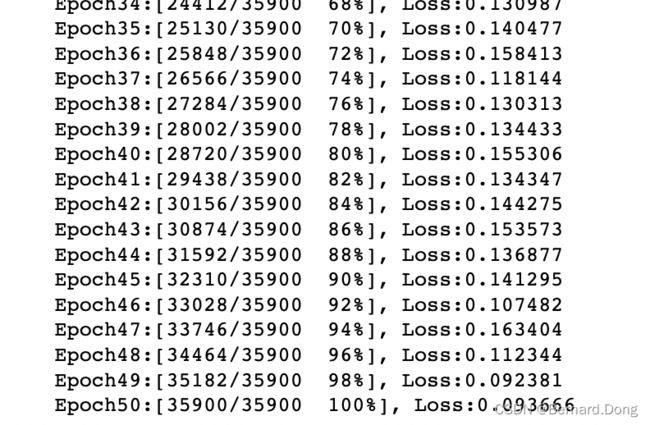
5. 预测
预测的方法就是将待预测数据输入训练好的模型,进行向前传播,net.forward(x_test)。我们有七个种类,之前的one-hot编码中,将每一个种类用一维、长度为7的向量表示,对应的位置为1,其余位置为0。
输出的结果也是这样 7 × 1 7\times1 7×1的向量,我们选取其最大数对应的位置作为预测结果,计算准确率。
# 计算准确率的函数
def Accuracy(l1,l2):
l1,l2=np.array(l1),np.array(l2)
s=np.count_nonzero(l1-l2,axis=None)/len(l1-l2)
return 1-s
最终我们模型的准确率达到了0.62。

6. 总结
本文提供了用pytorch构建神经网络解决实际问题的一个案例,介绍了pytorch使用的大致流程,可以作为学习的参考。如果想进一步了解神经网络的原理及pytorch使用的更多细节,建议观看视频系统学习。