【IJCAI2021】《Graph Learning based Recommender Systems:A Review》论文笔记
《Graph Learning based Recommender Systems:A Review》
《图学习推荐系统:回顾/综述》
目录
文章目录
- 《Graph Learning based Recommender Systems:A Review》
- 目录
- 两个版本
- 缩写和翻译
- 摘要 Abstract
- 1.简介Introduction
-
- 动机:为什么将图学习引入推荐系统
- 形式:图学习如何助力推荐系统
- 本文贡献
- 2.数据特性和挑战
-
- 2.1 一般交互数据 GLRS Built on General Interaction Data
- 2.2 序列交互数据 GLRS Built on Sequential Interaction Data
- 2.3 结合辅助信息 GLRS Incorporating Side Information Data
-
- 2.3.1 结合属性信息 GLRS Incorporating Attribute Information
- 2.3.2 结合社交信息 GLRS Incorporating Social Information
-
- 用于社交推荐 Social Recommendation
- 用于朋友推荐 Friend Recommendation
- 2.3.3 结合外部知识 GLRS Incorporating External Knowledge
-
- 本体知识 GLRS incorporating ontology knowledge.
- 常识 GLRS incorporating common knowledge.
- 3.推荐系统中的图学习方法
-
- 3.1 随机游走 RandomWalk Approach
- 3.2 图表示学习 Graph Embedding Approach
-
- 3.2.1 图因子模型 Graph Factorization based RS (GFRS).
- 3.2.2 图分布式表示Graph Distributed Representation based RS (GDRRS).
- 3.2.3 图神经网络嵌入 Graph Neural Embedding based RS (GNERS).
- 3.3 图神神经网络 Graph Neural Network Approach
-
- 3.3.1 图注意力网络 Graph ATtention network based RS (GATRS).
- 3.3.2 门控图网络 Gated Graph Neural Network based RS (GGNNRS).
- 3.3.3 图卷积神经网络 Graph Convolutional Network based RS (GCNRS).
- 3.4 知识图谱Knowtedge-Graph Approach (*仅预发布版本*)
- 4. 图学习推荐系统中的算法和数据集
-
- 开源算法
- 通用数据集
- 5.开放的研究领域
两个版本
-
预发布
Graph Learning Approaches to Recommender Systems :A Review
arXiv:2004.11718v1 [cs.IR] 22 Apr 2020
https://arxiv.org/abs/2004.11718 -
JCAI2021(本文主线)
Graph Learning based Recommender Systems:A Review
arXiv:2105.06339v1 [cs.IR] 13 May 2021
https://arxiv.org/abs/2105.06339

缩写和翻译
Graph Learning based Recommender Systems(GLRS) 图学习推荐系统
摘要 Abstract
Recent years have witnessed the fast development of the emerging topic of Graph Learning based Recommender Systems (GLRS).
最近几年(我们)见证了图学习推荐系统这一新兴领域的快速发展。
GLRS employ advanced graph learning approaches to model users’ preferences and intentions as well as items’ characteristics for recommendations.
图学习推荐系统使用了先进的图学习方法,对用户的喜好、意图,以及物品的特性进行了建模。
Differently from other RS approaches, including content-based filtering and collaborative filtering, GLRS are built on graphs where the important objects, e.g., users, items, and attributes, are either explicitly or implicitly connected.
不同于其他的推荐系统,包括内容滤波或协同滤波,图学习推荐系统建立在一个图结构上。在这个图结构上,用户、物品、属性等各种重要对象,以显示或隐式的方式连接。
With the rapid development of graph learning techniques, exploring and exploiting homogeneous or heterogeneous relations in graphs are a promising direction for building more effective RS.
随着图学习技术的飞速发展,对图网络中的同质/异质关系,进行探索和利用,成为一个值得期待的研究方向,可以用于建立更加有效的推荐系统。
In this paper, we provide a systematic review of GLRS, by discussing how they extract important knowledge from graph-based representations to improve the accuracy, reliability and explainability of the recommendations.
这篇论文中,我们对图学习推荐系统进行了一次系统性的回顾,讨论了其如何借助图表示学习的方法,提取重要信息,提升推荐系统的准确性、可信度和可解释性。
First, we characterize and formalize GLRS,
首先,我们描述了图学习推荐系统,定义了其基本形式;
and then summarize and categorize the key challenges and main progress in this novel research area.
然后,对这个新颖的研究领域中,存在的主要挑战和应对策略,进行了总结和分类;
Finally, we share some new research directions in this vibrant area.
最后,我们分享了这一朝阳领域中的一些新的研究方向。
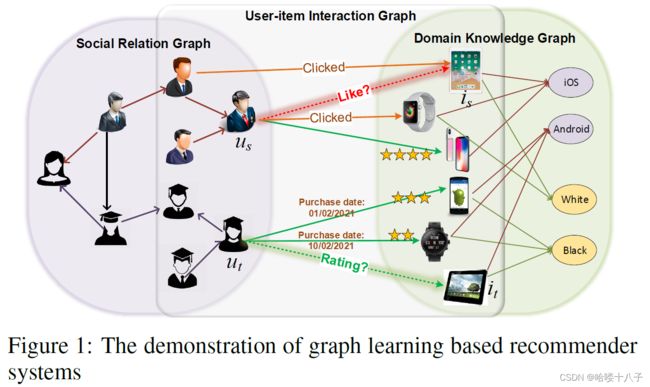
1.简介Introduction
动机:为什么将图学习引入推荐系统
Motivation:why graph learning for RS?
-
推荐系统中各种的数据,本质上有着图的结构。
Most of the data in RS has essentially a graph structure. -
我们生活在一个图结构的世界。
we are living in a world of graphs -
图学习拥有学习复杂关系的能力。
Graph learning has the capability to learn complex relations. -
图学习有着很大的潜力,对嵌入在各种图结构中知识,进行提取。具体的,有很多图学习技术,例如随机游走和图神经网络,······
GL has shown great potential in deriving knowledge embedded in different kinds of graphs. Specifically, many GL techniques, such as random walk and graph neural networks, … -
图学习有助于构建可解释的推荐系统。(仅预发布版本提及,正式版本中已删除)
Graph learning helps in building explainable RS.
形式:图学习如何助力推荐系统
Formalization: how does graph learning can help RS?
-
我们从一个高层次的视角,定义图学习推荐系统的基本形式。
We generally formalize GLRS from a high-level perspective. -
我们用图结构的形式,将推荐系统中的数据(对于其他场景一般也是这样定义的)描述为: G = { V , E } G=\{V, E\} G={V,E}; 其中 V V V表示节点或研究对象,例如用户、物品等;E表示对象间的关系,例如购买。
We construct a graph G = { V , E } G=\{V, E\} G={V,E} with the data of an RS where the objects, e.g., users and items, are represented as nodes in V V V and the relations between them, e.g., purchases, are represented as edges in E E E. -
接下来,构建图学习推荐系统 M ( Θ ) M(\Theta) M(Θ),并训练以得到最优的推荐结果 R R R,以及最优的模型参数 Θ \Theta Θ。模型参数从图结构中的的拓补结构和内容信息中习得。较正式地,可记作:
Then, a GLRS model M ( Θ ) M(\Theta) M(Θ) is constructed and trained to generate optimal recommendation results R R R with optimized model parameters Θ \Theta Θ that are learned from the topological and content information of G G G. Formally,
R = a r g m a x Θ f ( M ( Θ ) ∣ G ) R=\underset{\Theta}{argmax} f\big(M(\Theta)|G\big) R=Θargmaxf(M(Θ)∣G)
-
根据具体的推荐数据和场景,图结构 G G G和推荐目标 R R R可以定义为多种形式,例如:
Depending on the specific recommendation data and scenarios, the graph G G G and the recommendation target R R R can be defined in various forms,e.g., -
图结构 G G G可以使同质的或异质的,推荐目标 R R R可以是物品预测打分或排序;
G G G can be homogeneous sequences or heterogeneous networks while R R R can be predicted ratings or ranking over items. -
优化目标 f f f可以是最大效用[Wang et al.,2019f],或者概率最大化,用于成节点之间的连接。(这里可以理解为转移概率最大化)
The objective function f f f can be the maximum utility [Wang et al., 2019f] or the maximum probability to form links between nodes [Verma et al., 2019].
本文贡献
Contributions.
-
系统分析了GLRS中不同图结构带来的关键挑战,从数据的角度对之进行了分类,对于深刻理解GLRS的重要特性,提供了一个有用的视角。
We systematically analyze the key challenges presented by various GLRS graphs and categorize them from a data driven perspective, providing a useful view to better understand the important characteristics of GLRS. -
总结了最近的GLRS研究进展,从技术最优的角度,对相关文献进行了系统分类;
We summarize the current research progress in GLRS by systematically categorizing the more technical state-of-the-art literature. -
分享了一些GLRS开放性研究,供参考。
We share and discuss some open research directions of GLRS for giving references to the community.
2.数据特性和挑战
Data Characteristics and Challenges

-
三个核心对象:用户,物品,用户-物品交互行为;
It is well known that the three key objects managed by an RS are user, item and user-item interaction -
两类数据:用户-物品交互数据(例如点击、评分),辅助信息(例如用户偏好、物品属性);
There are two broad types of data: user-item interaction data, e.g., clicks and ratings of users
(对于第一类数据,即交互数据,又可以细分为两类:)
- 根据交互行为的时序关系是否被记录,交互数据可分为:序列交互数据、一般交互数据;
Depending on whether the temporal order of the interactions is recorded or not, interaction data can be classified into sequential interaction data and general interaction data.
2.1 一般交互数据 GLRS Built on General Interaction Data
- 交互矩阵 interaction matrix
用户和物品之间的交互可表示为交互矩阵,每一行对应一个用户,每一列对应一个物品,其中每一项表示交互出现的可能性。
Interactions between users and items are usually represented as an interaction matrix,where each row indicates one user and each column indicates one item. Each entry in the matrix captures an information about the type of occurred interaction.
- 交互类型
根据交互类型,交互行为可分为两种,显式交互(例如用户对物品的打分)和隐式交互(例如,点击,查看)(即没有明确表态,只是留意过或看了看)
Depending on the interaction type, the interaction data can be divided into the explicit (i.e., users’ ratings on items) and the implicit (e.g., click, view) [Zhang et al., 2019b].
- 二部图 bipartite graph
交互矩阵可以自然得表示为用户-物品二部图。
An interaction matrix can be naturally represented as a user-item bipartite graph [Zha et al., 2001].
二部图中,用户节点和物品节点分别构成两个部分,(用户和物品之间的)交互被表示为图中的边,连接这两个部分;
In this graph, the user nodes and the item nodes constitute the two “parts” respectively, while the interactions are represented as edges connecting two nodes in different parts.
进一步,显式交互矩阵可以被表示为加权二部图,每一条边对应一个权重,表示交互的分值 (可理解为交互出现的概率);
Furthermore, an explicit interaction matrix can be represented as a weighted bipartite graph where each edge is labeled with a weight to indicate the rating value.
隐式交互矩阵可以被表示为无权二部图,其中每条边表示一次隐式得交互。
An implicit interaction matrix can be represented as an unweighted bipartite graph where an edge indicates a implicit interaction.
- 优势 advantage
···矩阵补全的方式往往面临着数据稀疏和冷启动的问题。基于二部图的方式,缓解了这些问题,通过信息在节点之间的广泛传播,丰富了冷启动用户或物品的(描述)信息。
…matrix completion methods generally face data sparsity related and cold-start problems as discussed in [Jamali and Ester, 2009]. A bipartite graph based approach mitigates these issues by enabling the information propagating widely among nodes to enrich the information of those users and items with less interactions [Wu et al., 2020b].
- 挑战 challenge
如何让用户和物品之间的信息准确、高效地传播,这是有挑战的。尤其是在二部图中,用户和物品之间没有直接的连接,信息的传播需要借助很多层级的相邻节点(才能够实现)。
it is challenging how to effectively and efficiently propagate the information between users or items.This is particularly challenging in a bipartite graph since no direct links exist between users or items, and thus the information should be propagated via multi-hop neighbour nodes.
-
解决方案(示例) Solution
-
对于加权二部图 For weighted bipartite graphs
- graph auto-encoder (e.g., graph convolutional matrix completion [Berg et al., 2017]),
- Graph Convolutional Networks (GCN) (e.g., multi-graph convolutional neural networks [Monti et al.,2017],
- stacked and reconstructed GCN [Zhang et al., 2019a]), and
- Graph SAmple and aggre-GatE (GraphSage) (e.g., inductive graph-based matrix completion [Zhang and Chen, 2020]).
-
对于无权二部图 For unweighted bipartite graphs
- random walk (e.g.,RecWalk [Nikolakopoulos and Karypis, 2019]),
- graph embedding (e.g., high-order proximity for implicit recommendation [Yang et al., 2018],
- collaborative similarity embedding [Chen et al., 2019]),
- GCN (e.g., spectral collaborative filtering [Zheng et al.,2018],
- lightGCN [He et al.,20201],
- low-pass collaborative filter [Yu and Qin, 2020],
- multi-behavior GCN [Jin et al., 2020]), and
- GraphSage (e.g.,neural graph collaborative filtering [Zheng et al., 2018]).
-
2.2 序列交互数据 GLRS Built on Sequential Interaction Data
根据一个序列中的交互类型数量,交互数据可分为
According to the number of interaction types included in a sequence, a sequential interaction data set can be divided into
- 单类型交互数据 single-type interaction data set
- 通常被表示为交互物品(记作v)组成的序列,例如{v1, …, vn},
usually recorded as a sequence of interacted with items (denoted as v), e.g., {v1, …, vn},
- 多类型交互数据 multi-type interaction data set
- 一个多类型交互序列,通常被表示为一系列 <交互类型、物品>对 的形式,例如 {click v1, click v2, …, purchase vn}.
a multi-type interaction sequence is recorded as a sequence ofpairs, e.g., {click v1, click v2, …, purchase vn}. - 实际上,多种类型的交互,例如查看、点击、购买,经常同时初现在同一个序列中,这种现象很常见;
Multi-type interactions like view, click and purchase co-happening in one sequence are very common in practice [Wang et al., 2020b].
建立在序列交互数据上的推荐系统被定义为序列交互系统(SRS),以历史交互序列为输入,用于预测下一次交互的的概率分布。
An RS built on sequential interaction data is formalized as a Sequential Recommender System (SRS) which takes a sequence of historical interactions as input to predict the possible next interaction(s)[Quadrana et al., 2018; Wang et al., 2019e].
序列交互数据可以被表示为有向图
A sequential interaction data set can be represented as a directed graph
- 每个交互序列,对应图中的一条路径
here each interaction sequence corresponds to one path in the graph [Wu et al., 2019b]. - 每条路径中,(每个)交互行为对应图中(每个)节点
In each path, the interactions serve as the nodes and - 两个相邻节点之间的有向边,表示交互的顺序
a directed edge between any adjacent nodes indicates the order of interactions. - 值得指出,有时候某个用户可能在一次交互序列中,存在多次相同的交互行为(例如,多次点击了某个物品),于是一条路径中可能包含一个或多个环。
Note that in some cases one user may have multiple identical interactions happening in a sequence (e.g., click the same items multiple times), resulting in a path consisting of one or more loops [Wu et al., 2019b].
在有向图上建立SRS的优势The advantages of building SRS on directed graph
- 图学习方法有着强大能力,即使对于交互序列中最复杂的转移关系,也可以(用图学习)进行表示和建模
the strong capability of graph learning to represent and model even the most complicated transitions in a sequence of interactions.
挑战 challenge
- 如何构建图结构,有效地表示系列交互数据,同时信息损失尽量小
how to construct a graph to effectively represent the sequential interaction data with minimal information loss, - 如何在图结果中实现信息传播,模拟复杂转移关系
how to propagate information on the graph to effectively model even the most complicated transitions.
一些解决方案
大多数研究方案集中在单类型交互数据,包括:
Most of the studied approaches focus on single-type interaction data, including:
- Gated Graph Neural Networks (GGNN) (e.g.,
- session-based recommendation with GNN [Wu et al., 2019b] and
- graph contextualized self-attention networks [Xu et al., 2019]),
- GraphSage (e.g.,memory augmented GNN [Ma et al., 2020]), and
- Graph ATtention networks (GAT) (e.g., full graph neural network [Qiuet al., 2019]).
少数方案适用于多类型交互数据,包括:
Limited approaches for multi-type interaction data include
- GraphSage (e.g., multi-relational GNN forsession-based prediction [Wang et al., 2020b]).
2.3 结合辅助信息 GLRS Incorporating Side Information Data
交互数据通常是稀疏的,因此通常不足以正确捕获到用户喜好和物品特性;
Interaction data is often sparse [Hu et al., 2019], thus is not sufficient for correctly capturing the users’ preferences and item characteristics.
于是,多种类型的辅助信息被使用,例如 属性信息、社会关系等,用于缓解这个问题。
Hence, various types of side information, e.g., attribute information and social information, have been used to alleviate such an issue.
这一节中,我们讨论三种主要的辅助信息:
In this section, we discuss three main types of side information:
- 属性信息 attribute information,
- 社交关系 social information, and
- 外部知识 external knowledge.
2.3.1 结合属性信息 GLRS Incorporating Attribute Information
给定一组数据集,交互数据和属性数据的组合,自然地构成一个异质图。
Given a data set, the combination of interaction data and attribute data naturally results in a heterogeneous graph.
其中,存在三种类型的节点(用户节点、物品节点、属性节点),和至少两个钟类型的边:
In such a graph, three types of nodes, i.e., user node, item node and attribute value node, and at least two types of edges exist.
-
对于一般交互数据和属性信息的结合
in the combination of general interaction data and attribute data,- 用户到物品的边 user-item edges (cf. Sec. 2.1),
- 用户(或物品)到其属性的边,表示其属性关系 user (or item)-attribute value edge representing the relations between user (or item) and attributes.
-
对于序列交互数据和属性数据的结合
In the combination of sequential interaction data and attribute data,- 交互到交互的有向边 directed interaction-interaction edges (cf. Sec. 2.2),
- 物品到属性的边 item-attribute value edges.
优点 advantage
异质图结合了两类不同信息(交互信息&属性信息),因此信息能够在多种节点之间传播,较好地应对了之前提到的数据稀疏问题
Heterogeneous graphs combine two different types of information, i.e., interaction information and attribute information, hence enabling information propagation among different types of nodes, and better coping with the mentioned data sparsity problem.
挑战 challenging
如何有选择性地聚合有用的属性信息,提高推荐性能。
However, it is challenging to selectively aggregate those useful attribute information to improve the recommendation performance.
方案 approach
- (异质)图嵌入,例如:(heterogeneous) graph embedding (e.g.,
- entity2rec [Palumbo et al., 2017] based on node2vec,
- heterogeneous preference embedding [Chen et al., 2016] and
- heterogeneous network embedding for recommendation [Shi et al., 2018]),
- 图注意力网络 GAT (e.g., knowledge graph attention network [Wang et al., 2019f]).
2.3.2 结合社交信息 GLRS Incorporating Social Information
用户之间的某种社交关系,自然地构成一个同质的社交图结构,每个用户对应一个节点,两个用户间的社交联系(例如朋友关系)对应一条边
A particular type of social relation among the users in a data set naturally forms a homogeneous social graph where each user corresponds to a node and each social link (e.g., friend relation) between two users corresponds to an edge.
推荐系统中,社交关系图主要用于两类任务:
In an RS, the social graph can be mainly used for two tasks:
- 社交推荐(推荐物品给用户,利用社交信息)
social recommendation (recommending items to users by incorporating social information) [Fan et al., 2019], and - 朋友推荐(推荐用户给另一用户,通过预测社交关联概率)
friend recommendation (recommending users to a given user by predicting the possible social links) [Huang et al., 2015]
用于社交推荐 Social Recommendation
社交信息和 一般/序列 用户-物品交互信息结合,构成一个异质图,包含两部分:
The combination of social information and general or sequential user-item interaction data naturally results in a heterogeneous graph comprising two parts.
- 由一般交互信息导出的二部图(Sec. 2.1),或者由序列交互信息导出的有向图(Sec. 2.2)
由The first is the bipartite graph derived from the general interaction data (cf. Sec. 2.1) or the directed graph extracted from the sequential interaction data (cf. Sec. 2.2), - 用户之间的社会关系图
while the second part is the social graph connecting the users.
社会关系图中,考虑用户相邻节点,可以有助于理解用户偏好。
Such an approach helps better understand a user’s preference by considering the influence of her neighbours in a social graph.
然而,一方面,多少级的相邻节点需要纳入考虑范围,并不明确;另一方面,不同的相邻节点通常对用户有不同程度的影响。
However, on one hand, it is not clear how many orders of neighbours should be considered to correctly compute this influence on a given user. On the other hand, different
neighbours usually influence a user to different degrees [Wu et al., 2020b].
挑战 challenge
其他用户对给定用户的影响,这一过程如何建模
Hence, it is a challenge to appropriately model the influence of other users to a given user.
方案 approach
Typical approaches targeting this challenge include
- random walk (e.g., Trust-walker [Jamali and Ester, 2009]),
- graph embedding [Wen et al., 2018] and
- GAT (e.g., GraphRec [Fan et al., 2019] and
- improved diffusion network [Wu et al., 2020a]).
这些方案大多聚焦社会关系图和一般交互行为,很少结合了社会关系图和序列交互行为。
All these works focus on combining social graph and general interactions, while limited works combine social graph and sequential interactions [Song et al., 2019].
用于朋友推荐 Friend Recommendation
结合上述同质的社会关系图,朋友推荐可表示为连接概率预测问题。
By using the aforementioned homogeneous social graph, friend recommendation is performed as a link prediction task on such graph [Yin et al., 2010].
具体的,给定一个目标用户和已知的社交联系,朋友推荐:
Specifically, given a target user and the known social links on the graph, friend recommendation
- 首先推断其他用户和目标用户之间的连接概率,
first infers the possible links between other users and the target user - 然后将高概率用户推荐给目标用户
and then recommends those users with high probabilities to link with the target user to her.
优点 advantage
如何建模用户之间的多重影响
The main challenge lies in how to appropriately model the mutual-influence between users.
方案 approach
- random walk based approaches [Backstrom and Leskovec, 2011; Bagci and Karagoz, 2016] are more common in order to address this challenge.
- Other approaches include graph embedding [Verma et al., 2019].
2.3.3 结合外部知识 GLRS Incorporating External Knowledge
关于用户和物品的外部知识,例如物品的分类、概念上的语义联系,通常有助于深入理解用户偏好和物品特性,最终提高推荐性能。
External knowledge, e.g., item taxonomy and semantic relations between concepts, related to users and items usually contributes to a deeper understanding of the users’ preference and item characteristics [Wang et al., 2018a], and ultimately improving recommendation performance.
上述知识通常表示为知识图谱,多种类型的对象(例如用户、电影、电影导演)被表示为节点,多种对象之间的关系(例如电影-导演)被表示为(图谱的)边。
Such knowledge is usually represented as a knowledge graph where various types of objects (e.g., users, movies, movie directors) are represented as nodes and the relations between them (e.g., movie-director relation) are represented as edges [Wang et al., 2019f].
外部知识主要分为两类:本体知识(暂定) 和 常识
There are mainly two types of external knowledge commonly utilized in RS: item/user ontology and common knowledge.
本体知识 GLRS incorporating ontology knowledge.
用户或物品的本体知识,通常表示为多层次的树状图,记录着物品或用户之间的级别关系。
The ontology of users or items is usually represented as a hierarchical tree-like graph where the hierarchical relations between users or items are recorded.
推荐系统中,一种常用的本体知识图谱,是物品类别信息。
A type of commonly utilized ontology knowledge for recommendations is item taxonomy information [Huang et al., 2019].
上述树状图的一个例子,亚马逊网站,该(购物)平台利用了商品的分类信息,将所有物品组织到一起。
An example of such a tree graph is used in Amazon.com, where the category information of products is used to organize all the items offered by the platform.
杉树树状图中,根节点对应最粗粒度的类目,叶子节点对应某个物品。
In that graph, the root node corresponds to the coarsest-grained category and the leaf nodes represent specific items.
优点 advantage
能够更好地理解,用户对物品的多级别偏好,因而提高推荐系统的可解释性
The incorporation of item ontology knowledge enables a better understanding of the users’ multi-level preferences towards items, and thus helps improving the explainability of the recommendations [Gao et al., 2019].
挑战 challenge
如何沿着层次结构树形图,传播用户对物品的偏好,来提取多层级的偏好信息
However, it remains a challenge to propagate users’ preferences over items along the hierarchy tree graph to extract the multi-level preferences.
方案 approach
Representative works targeting such a challenge include
- graph embedding based approaches [Wang et al., 2018b; Gao et al., 2019], aimed at learning more informative item embedding for general recommendations, and
- memory network on graphs to learn coarse-grained-preference representation for sequential recommendations [Huang et al., 2019].
常识 GLRS incorporating common knowledge.
包括但不限于:
It includes, but is not limited to,
- 实体间的一般语义联系,例如面包、食品、面包店
general semantic relations between entities (e.g., the relations among bread, food, bakery item from Microsoft Concept Graph1) [Sheu and Li, 2020], and - 实体间的特定领域关系,例如电影、导演、风格
domain-specific relations between entities (e.g., the relations between movies, directors, genre) [Gao et al., 2020].
优点 advantage
公共知识的结合,有利于探索和利用 用户和/或物品 之间的各种外部隐性关系
The incorporation of common knowledge benefits the exploration and exploitation of various external implicit relations between users and/or items,
挑战 challenge
如何通过不同类型的实体之间的不同链接,在不同类型的实体之间有效传播信息,从而为推荐系统获取一致的、有用的信息
However, it remains a challenge to effectively propagate information between different types of entities via different types of links between them, to obtain coherent and useful information for the recommendations.
方案 approach
- 图嵌入方法,精细地学习异质实体和关系的嵌入表示
graph embedding methods [Wang et al., 2019c] (especially meta-path based embedding [Zhao et al., 2017; Sun et al., 2018; Shi et al., 2018; Wang et al., 2019g]) to wisely learn the embedding of heterogeneous entities and relations, and - 图神经网络,迭代地(理解为递归地)从相邻接点聚合信息
GNN based methods (especially GCN [Wang et al., 2019b] an GAT [Wang et al., 2019f]) to iteratively aggregate the information from neighbour nodes.
3.推荐系统中的图学习方法
Graph Learning Approaches for RS
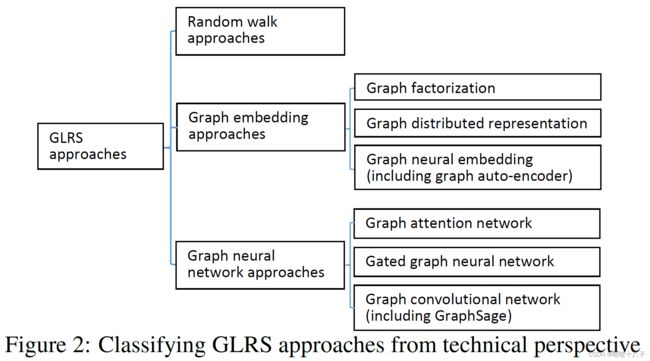
3.1 随机游走 RandomWalk Approach
基于随机游走的推荐系统,在最近15年里被广泛研究,也被广泛应用到多种图结构中(例如,用户间的社交网络、物品间的共现网络),用于捕获节点之间的复杂关系,用于(后续)推荐。
Random walk based RS have been extensively studied in the past 15 years and have been widely employed on various graphs (e.g., social graphs between users, co-occurrence graph between items) to capture complex relations between nodes for recommendations.
-
基础形式 basic random walk
- 预设的转移概率 predefined transition probability
- 捕获复杂、高阶、间接的关系capturing the complex, higher-order and indirect relations
- 可经受同质或异质的图结构带来的挑战address important challenges in homogeneous or heterogeneous graphs to generate recommendations
-
随机重置 restart
- 以固定概率跳回初始节点constant probability to jump back to the starting node
- 多用于节点众多的图结构,避免游走过远,跳出初始节点的上下文范围it is generally used in graphs containing many nodes to avoid moving out of the particular context of the starting node
-
转移概率定制化(仅预发布版本)
- 为了提供更个性化的推荐,一些使用随机游走的RS,根据用户特性定制转移概率
To provide more personalized recommendations, some random walk based RS [Eksombatchai et al., 2018] calculate a user-specific transition probability for each step.
- 为了提供更个性化的推荐,一些使用随机游走的RS,根据用户特性定制转移概率
虽然广泛应用,使用随机游走的推荐系统,依然有一些明显缺点:
Although widely applied, the drawbacks of random walk based RS are also obvious:
-
对于每一个用户和所有的候选物品,对每一步都需要排序评分,因此效率低下,难以适用于大规模图结构;
they need to generate ranking scores on all candidate items at each step for each user,
and thus they are hard to be applied on large-scale graphs due to the low efficiency, -
不同于学习型方法,随机游走属于启发型,因此参数量较少,优化推荐目标时难以发挥较大作用(可理解为表达能力有限),严重减低了推荐系统的性能。
unlike most learning-based paradigm, random walk based RS are heuristic-based, lacking model parameters to optimize the recommendation objective, which greatly reduces the recommendation performance.
3.2 图表示学习 Graph Embedding Approach
图嵌入是一种有效技术,用于分析图结构中隐含的复杂关系,在最近几年中得到发展快速。它将每一节点映射成为一个低维表示向量,同时图结构信息也被编码于其中。
Graph embedding is an effective technique to analyze the complex relations embedded on graphs and has been rapidly developing in recent years. It maps each node into a low-dimension embedding vector which encodes the graph structure information.
3.2.1 图因子模型 Graph Factorization based RS (GFRS).
GFRS首先基于图上的元路径分解节点间交换矩阵,以获得每个节点(如用户或项目)的嵌入,然后将其作为后续推荐任务的输入。
GFRS first factorizes the inter-node commuting matrix based on meta-path on the graph in order to obtain the embedding of each node (e.g., a user or an item), which are then used as input of the subsequent recommendation task [Wang et al., 2019h].
优点 advantage
图中节点之间的复杂关系被编码到嵌入中,以改进推荐。
By doing so, the complex relations between nodes in the graph are encoded into the embedding to improve the recommendations.
由于其能够处理节点的异构性,GFRS被广泛应用于捕捉不同类型节点(如用户和项目)之间的关系。
Due to their capability to handle the heterogeneity of the nodes, GFRS have been widely applied to capture relations between different types of nodes, e.g., users and items.
问题 problem
然而,这种模型虽然简单有效,却容易受到观测数据稀疏性的影响。
However, although being simple and effective, such models may easily suffer from the sparsity of the observed data.
3.2.2 图分布式表示Graph Distributed Representation based RS (GDRRS).
与GFRS不同,GDRRS通常遵循Skip-gram模型,以便学习图中每个用户或物品的分布式表示。
Differently from GFRS, GDRRS usually follow Skip-gram model [Mikolov et al., 2013] in order to learn a distributed representation of each user or item in a graph.
它们(相关方法)将有关用户或物品,及其邻近关系的信息,编码成一个低维向量,然后用于后续的推荐步骤。
They encode information about the user or item and its adjacent relations into a low-dimensional vector [Shi et al., 2018], which is then used for the subsequent recommendation step.
具体地,GDRRS通常首先使用随机游走,沿原路径生成一个节点序列,然后使用skip-gram或类似的模型,生成节点表示,用于推荐。
Specifically, GDRRS usually first use random walk to generate a sequence of nodes that co-occurred in one meta-path and then employ the skip-gram or similar models to generate node representations for recommendations.
优点 advantage
基于强大的编码能力,可以对图中的节点间的连接关系进行编码,GDRRS广泛应用于同构图和异构图,用于捕获推荐对象之间的关联关系。
By exploiting its powerful capability to encode the inter-node connections in a graph, GDRRS are widely applied to both homogeneous and heterogeneous graphs for capturing the relations between the objects managed by the RS [Cen et al., 2019].
近年来,GDRRS显示出了巨大的潜力,得益于其简单、高效、有效等特点。
GDRRS have shown their great potential in recent years due to their simplicity, efficiency and efficacy.
3.2.3 图神经网络嵌入 Graph Neural Embedding based RS (GNERS).
GNERS利用神经网络,如多层感知器、自动编码器,来学习用户或物品的嵌入表示。
GNERS utilize neural networks, like Multilayer-perceptron, autoencoder, to learn users or items embedding.
优点 advantage
神经网络嵌入模型,易于与其他下游神经网络推荐模型集成到一起(例如基于RNN的模型),构建端到端的推荐系统。
Neural embedding models are easy to integrated with other downstream neural recommendation models (e.g., RNN based ones) to build an end-to-end RS [Han et al., 2018].
为此,GNERS已被广泛应用于各种图结构中,例如属性图,结合知识图谱进行交互(?)。
To this end, GNERS have been widely applied to a variety of graphs like attributed graphs [Han et al., 2018], interaction combined with knowledge graphs [Hu et al., 2018; Cen et al., 2019].
3.3 图神神经网络 Graph Neural Network Approach
3.3.1 图注意力网络 Graph ATtention network based RS (GATRS).
GATRS基于图注意力网络(GAT),用于精确学习用户或物品之间的关系。
GATRS are based on GAT for precisely learning inter-user or item relations.
其中,针对某个用户或物品,对之产生重要影响的用户或项目将得到强调,这更符合实际情况,而且已被证明有利于推荐系统。
In such a case, the influence of the more important users or items, w.r.t. a specific user or item, is emphasized, which is more in line with the real-world cases and this has been shown to be beneficial for the recommendations.
由于其具有良好的区别对待能力,GAT广泛应用于多种类型的图结构中,例如社交图、物品会话图、知识图谱等。
Due to their good discrimination capability, GAT are widely used in different kinds of graphs including social graphs [Fan et al., 2019], item session graphs [Xu et al., 2019], and knowledge graphs [Wang et al., 2019f].
3.3.2 门控图网络 Gated Graph Neural Network based RS (GGNNRS).
门控图神经网络(gnnn)将门控循环单元(GRU)引入到GNN中,学习最优的节点表示,通过迭代地将图中其他节点纳入考量范围,全面捕捉节点间的关系。
Gated graph neural networks (GGNN) introduce the Gated Recurrent Unit (GRU) into GNN to learn the optimized node representations by iteratively absorbing the influence of other nodes in a graph to comprehensively capture the inter-node relations.
由于其拥有 捕获复杂节点间关系 的能力,GGNN被广泛应用于 模型复杂的物品在一个序列图之间的转换顺序建议(吴et al ., 2019 b),或模型之间的复杂交互进行不同类别的时尚产品的时尚建议(崔et al ., 2019),他们已经取得了卓越的推荐性能。
Due to their capability to capture the complex relations between nodes, GGNN are widely used to
- 在序列图结果中,建模物品间的复杂转移模式,用于序列推荐
model the complex transitions between items in a sequence graph for sequential recommendations [Wu et al., 2019b], or to - 在不同种类的爆款商品中,建模复杂的交互模式,用于爆款商品推荐
model the complex interactions between different categories of fashion products for fashion recommendations [Cui et al., 2019]
3.3.3 图卷积神经网络 Graph Convolutional Network based RS (GCNRS).
图卷积网络(GCN)通常用于学习如何迭代地实现信息聚合,从图结构的相邻节点中提取特征信息,综合利用图结构信息和节点特征信息,
Graph Convolutional Networks (GCN) generally learn how to iteratively aggregate feature information from local graph neighbor nodes by leveraging both graph structure and node feature information.
由于其强大的特征提取和学习能力,特别是能够结合图结构和节点内容信息的优势,GCN被广泛应用于多种图结构中,用于构建推荐系统,并被证明是非常有效的。
Thanks to the powerful feature extraction and learning capability, particularly their strength in combining the graph structure and node content information, GCN are widely applied to a variety of graphs in RS to build GCNRS and are demonstrated to be very effective.
例如,GCN被用于:
For instance, GCN are used
- 社交关系图中,建模影响的扩散过程,用于社交推荐
for influence diffusion on social graphs in social recommendations [Wu et al., 2019a], - 用户-物品交互图中,挖掘隐藏的用户-物品连接信息
for mining the hidden user-item connection information on user-item interaction graphs, - 协同过滤方法中,缓解数据稀疏问题
for alleviating the data sparsity problemn in collaborative filtering [Wang et al., 2019a], and - 知识图谱中,挖掘物品间的关联属性,捕获物品间的相关性
for capturing inter-item relatedness by mining their associated attributes on knowledge graphs [Wang et al., 2019b].
3.4 知识图谱Knowtedge-Graph Approach (仅预发布版本)
4. 图学习推荐系统中的算法和数据集
GLRS Algorithms and Datasets
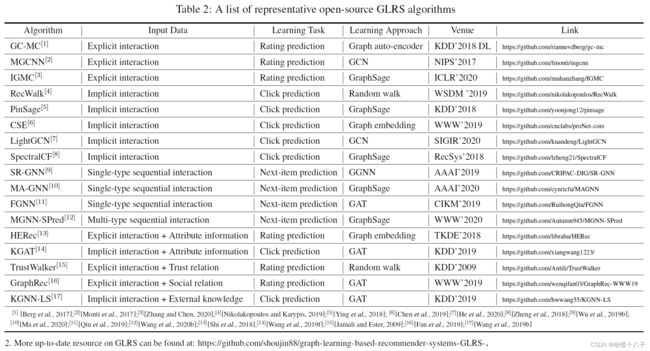
开源算法
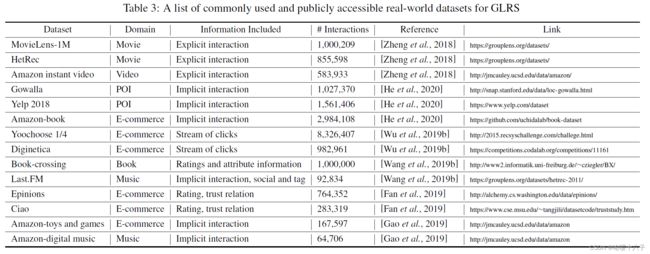
通用数据集
5.开放的研究领域
Open Research Directions
- 动态图学习,实现自我进化的RS | Self-evolutionary RS with dynamic-graph learning.
- 因果图学习,实现可解释的RS | Explainable RS with causal graph learning.
- 多模态图学习,实现跨领域的RS | Cross-domain RS with multiplex graph learning.
- 大规模图学习,实现高效率的RS | High-efficiency online RS with large-scale graph learning.