【2.1】TensorRT 自定义 Layer(Plugin)
本节记录下tensorRT plugin的学习过程。
官方文档如下:
Extending TensorRT with Custom Layers
Plugin
- 1 一个极简的 demo
-
- 1.1 函数的调用顺序
- 1.2 谈谈 getNbOutputs, getOutputDimensions 和 configureWithFormat 这三个API之间的联系
- 1.3 更官方地使用 plugin
- 2 IPluginV2Ext
- 3 IPluginV2DynamicExt
-
- 3.1 动态 shape 模式下的 getOutputDimensions 接口
- 3.2 动态 shape 模式的特殊之处
- 附录-代码
1 一个极简的 demo
自定义plugin需要继承一个基类,

当然直接继承 IPluginV2 也是可以的,但是这种情况下,只能支持 implicit mode。
先直接上代码,运行起来看一看,我们写一个 leakrelu的自定义plugin,代码见附录
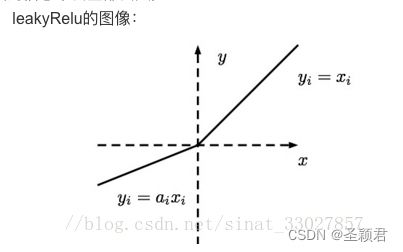
这个 leakrelu 的 plugin 我们定义得非常简单,主要定义了 序列化, clone, 反序列化, configure等函数。
定义好了之后通过下面的宏完成注册。
REGISTER_TENSORRT_PLUGIN(LReluPluginCreator);
在test.cc 我们通过这种方式使用 plugin。
// Add the plugin layer with hidden layer
IPluginV2* pluginObj = new LReLU(0.1);
执行时,由于 IPluginV2 只支持 implicit mode,所以只能使用 execute 接口,并指定 batch:
builder->setMaxBatchSize(3);
.
.
.
context->execute(batch_size, buffers);
1.1 函数的调用顺序
plugin中定义了很多接口,那么这些接口的调用顺序是什么呢,我们只需要关心几个关键API即可。
在函数中加入打印函数名,执行结果如下:
Add Plugin
getNbOutputs
getNbOutputs
clone
BuildSerializedNetwork # tensorRt的api
getOutputDimensions
clone
clone
clone
configureWithFormat
destroy
initialize
destroy
serialize
serialize
terminate
destroy
CreateInferRuntime # tensorRt的api
DeserializeCudaEngine # tensorRt的api
deserializePlugin
initialize
Execute # tensorRt的api
enqueue```
中间出现大量 clone serialize (甚至是enqueue)等的原因是, tensort 调用 BuildSerializedNetwork API 时, 会根据传入的 config 信息做优化,需要clone pluginlayer对象,做一些优化处理。优化过程中也需要调用 initialize 初始化 engine。优化完成后释放 engine时会调用 terminate。 trt 调用 DeserializeCudaEngine时,又会创建一个新的engine, initialize再次被调用。
简单来说,主要的执行顺序就是:
getNbOutputs
getOutputDimensions
configureWithFormat // 配置一下pligin
initialize // 优化过程中初始化需要的engine
terminate // 优化完成后,析构engine时会调用terminate
serialize // 序列化
deserializePlugin // 反序列化
initialize // 初始化反序列化后的engine
enqueue // 执行
enqueue // 可多次执行
主要注意的是,序列化和反序列化,只需针对一些必要的数据,并非全部数据。同时反序列化之后,会执行initialize,因此可以在initialize做一些必要的数据处理(可选的)。
如果你的Demo是这样写的,没有经历序列化和反序列化,而是直接buildEngineWithConfig。这样 engine只有一个,initialize只会被调用一次。
// 序列化和反序列化
// std::cout << "BuildSerializedNetwork" << std::endl;
// IHostMemory* serializedModel = builder->buildSerializedNetwork(*network, *config);
// std::cout << "CreateInferRuntime" << std::endl;
// IRuntime* runtime = createInferRuntime(logger);
// std::cout << "DeserializeCudaEngine" << std::endl;
// ICudaEngine* engine = runtime->deserializeCudaEngine(serializedModel->data(), serializedModel->size());
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
调用过程类似这样:
getNbOutputs
getOutputDimensions
configureWithFormat // 配置一下pligin
initialize // 初始化engine
enqueue // 执行
enqueue // 可多次执行
1.2 谈谈 getNbOutputs, getOutputDimensions 和 configureWithFormat 这三个API之间的联系
首先这三个API的调用顺序是:
getNbOutputs
getOutputDimensions
configureWithFormat
输入的信息是在组网的时候,通过addPluginV2 指定的,因此 plugin 内部是知道输入相关信息的,而输出的相关信息,就需要 上述三个API协同来获得。
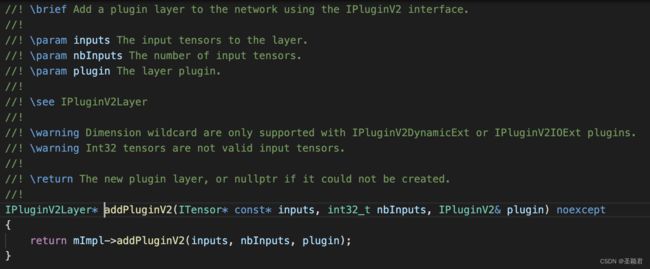
首先调用 getNbOutputs 获得输出的个数 n, 然后trt框架 n 次调用getOutputDimensions获取不同index的输出纬度,同时trt框架也应为这些输出分配tensor来存储中间结果。最后调用configureWithFormat时,所有的输入输出信息都是已知的,其中输出信息取决与getNbOutputs 和 getOutputDimensions的实现。
1.3 更官方地使用 plugin
上面的demo中, 通过
// Add the plugin layer with hidden layer
IPluginV2* pluginObj = new LReLU(0.1);
这种方式使用 plugin,虽然简单方便,但是和文档中的使用方法不一致。
为什么说是更官方地使用,因为官方文档是这这么推荐的:
For example, you can add a plug-in layer to your network as follows:
// Look up the plugin in the registry
auto creator = getPluginRegistry()->getPluginCreator(pluginName, pluginVersion);
const PluginFieldCollection* pluginFC = creator->getFieldNames();
// Populate the fields parameters for the plugin layer
// PluginFieldCollection *pluginData = parseAndFillFields(pluginFC, layerFields);
// Create the plugin object using the layerName and the plugin meta data
IPluginV2 *pluginObj = creator->createPlugin(layerName, pluginData);
// Add the plugin to the TensorRT network
auto layer = network.addPluginV2(&inputs[0], int(inputs.size()), pluginObj);
… (build rest of the network and serialize engine)
// Destroy the plugin object
pluginObj->destroy()
… (free allocated pluginData)
主要流程是,首先使用getPluginRegistry()->getPluginCreator(pluginName, pluginVersion)得到我们注册的 pluginCreator, 然后通过creator->createPlugin(layerName, pluginData)创建plugin, 简单来说,就是把直接 new plugin这个过程放在了createPlugin(layerName, pluginData)接口内, new plugin所需要的参数,通过pluginData 传入。
只需修改createPlugin函数
IPluginV2* createPlugin(const char* name, const PluginFieldCollection* fc) noexcept override {
const PluginField* fields = fc->fields;
assert(fc->nbFields == 1);
float negSlope = *(static_cast<const float*>(fields[0].data));
return new LReLU(negSlope);
}
使用时:
// Add the plugin layer with hidden layer
// IPluginV2* pluginObj = new LReLU(0.1);
auto creator = getPluginRegistry()->getPluginCreator("leak_relu", "1");
// Populate the fields parameters for the plugin layer
float mNegSlope = 0.1;
PluginField plugindata("mNegSlope", &mNegSlope);
PluginFieldCollection pluginFC{1, &plugindata};
// Create the plugin object using the layerName and the plugin meta data
IPluginV2 *pluginObj = creator->createPlugin("leak_relu", &pluginFC);
2 IPluginV2Ext
IPluginV2Ext是IPluginV2的派生类,增加了一些接口,相比 IPluginV2 ,IPluginV2Ext支持显示batch,这里提供一个 IPluginV2Ext 的demo, 只需增加几个API的实现即可,里面的逻辑与 IPluginV2 中的 demo 一致。 完整代码见附录。
3 IPluginV2DynamicExt
IPluginV2DynamicExt 支持动态shape,仅支持显示batch。附录中提供了一个完整demo,使用动态shape时,config中需要设置profile
IOptimizationProfile* profile = builder->createOptimizationProfile();
profile->setDimensions("input", OptProfileSelector::kMIN, Dims4(1, 4, 2, 2));
profile->setDimensions("input", OptProfileSelector::kOPT, Dims4(2, 4, 2, 2));
profile->setDimensions("input", OptProfileSelector::kMAX, Dims4(4, 4, 2, 2));
config->addOptimizationProfile(profile);
最后运行时,需要设置实际运行shape,
context->setBindingDimensions(inputIndex, Dims4(3, 4, 2, 2));
这和 IPluginV2 demo中的隐式batch机制很类似,隐式batch需要优化时设置最大batch数,运行时需要设置实际的batch数目。
写自定义plugin时,推荐使用 IPluginV2DynamicExt做基类。支持静态/动态shape,显示batch也更直观。
IPluginV2的隐式batch模式下,plugin内部只能看到三维的shape信息,batch信息在enqueue函数内才能看到(context->execute(batch)传入。 IPluginV2DynamicExt 显示batch模式下,可以看到四维shape信息,后面会谈这个问题的细节)
3.1 动态 shape 模式下的 getOutputDimensions 接口
相比静态shape,动态shape 的 getOutputDimensions接口里无法得到准确的 shape信息,只有在执行时才知道。因此,动态shape 执行时 会先调用 config接口,或者准备的shape信息。然后才调用enqueue函数。
3.2 动态 shape 模式的特殊之处
个人理解,由于动态shape只能在执行时才能知道准确的shape信息,所以之前clone的plugin对象中,有一些维度信息是不知道的,所以在执行的时候,需要再次调用clone接口创建一个新的plugin对象,再调用config接口进行一些配置,最后调用enqueue接口。所以需要注意的是对执行时新的clone的对象进行init操作。
附录-代码
查看个人github 仓库 tensorrt学习笔记