python+pytorch学习点滴记录
1、enumerate
python内置的函数,遍历一个数据对象并返回索引列表,同时列出数据下标和数据
list = ["a", "b", "c"]
for i,elem in enumerate(list):
print(i, elem)
返回:
0 a
1 b
2 c
2、tqdm
它是一个可以显示进度条的模块
当tqdm和enumerate结合时,比如
from tqdm import tqdm
list = ["a", "b", "c"]
for i,elem in enumerate(tqdm(list)):
print(i, elem)
返回:
0 a
1 b
2 c
100%|██████████| 3/3 [00:00
3、word embedding
将源数据映射到另外一个空间,一对一映射。可以将自然语言所表示的单次或短语转换为计算机所能理解的由实数构成的向量或矩阵形式。这样得到一个向量以后,就可以通过计算向量之间的相似度来得出语义的相关性。
torch.nn.Embedding(num_embeddings, embedding_dim)
num_embeddings: 嵌入字典的大小(词的个数)
embedding_dim: 每个嵌入向量的大小(每个词对应的维度)
该方法定义了一个简单的存储固定大小的词典的嵌入向量的查找表,即这个返回的是一个词典。如果要访问查找表,需要给定一个编号,嵌入层就能返回这个编号对应的嵌入向量。
注意:初始化的时候,里面的值都是随机的,后续需要训练模型。
示例一:初始化一个embedding并进行值索引
import torch
import torch.nn as nn
word1 = torch.LongTensor([0,1,2])
word2 = torch.LongTensor([3,1,2])
embedding = nn.Embedding(4, 5)
print(embedding.weight)
print("word1:")
print(embedding(word1))
print("word2:")
print(embedding(word2))
返回:
tensor([[ 0.0514, -1.0414, 0.2586, -0.8766, -0.1747],
[-0.8588, 0.4468, 0.7430, -0.7781, -1.5827],
[-2.0571, 0.0059, 0.3309, -0.0148, -1.8753],
[ 0.4409, 0.8645, 0.2430, 0.4251, -0.2876]], requires_grad=True)
word1:
tensor([[ 0.0514, -1.0414, 0.2586, -0.8766, -0.1747],
[-0.8588, 0.4468, 0.7430, -0.7781, -1.5827],
[-2.0571, 0.0059, 0.3309, -0.0148, -1.8753]],
grad_fn=
word2:
tensor([[ 0.4409, 0.8645, 0.2430, 0.4251, -0.2876],
[-0.8588, 0.4468, 0.7430, -0.7781, -1.5827],
[-2.0571, 0.0059, 0.3309, -0.0148, -1.8753]],
grad_fn=
示例二:embedding模型训练更新权重
import torch
from torch.nn import Embedding
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = Embedding(5, 10)
def forward(self, vec):
input = torch.tensor([0, 1, 2, 3, 4])
emb_vec1 = self.emb(input)
print(emb_vec1)
output = torch.einsum('ik, kj -> ij', emb_vec1, vec)
return output
def simple_train():
model = Model()
vec = torch.randn((10, 1))
label = torch.Tensor(5, 1).fill_(3)
loss_fn = torch.nn.MSELoss()
opt = torch.optim.SGD(model.parameters(), lr=0.05)
for iter_num in range(100):
output = model(vec)
loss = loss_fn(output, label)
print('iter:%d loss:%.2f' % (iter_num, loss))
opt.zero_grad()
loss.backward(retain_graph=True)
opt.step()
if __name__ == '__main__':
simple_train()
model中的参数就是一个embedding,前向传播总是编码同一个词汇表,然后乘上输入的向量。经果训练滞后embedding乘上向量可以得到全为3的向量。优化器中的参数仅有embedding,所以bedding是会被训练的。
4、torch.distributions.normal.Normal
torch.distributions定义了正态分布
import torch
from torch.distributions import Normal
mean = torch.Tensor([0, 2]) #此处有两个均值
normal = Normal(mean, 1)
c = normal.sample()
c_log_prob = normal.log_prob(c).exp()
print("c:", c)
print("c log_prob:", c_log_prob)
其中, sample()就是直接在定义的正态分布(均值为mean,标准差为std)上采样。
log_prob(value)是计算value在定义的正态分布(mean, std)中对应的概率密度函数的对数值。
概率密度函数,对其取log的公式分别如下:
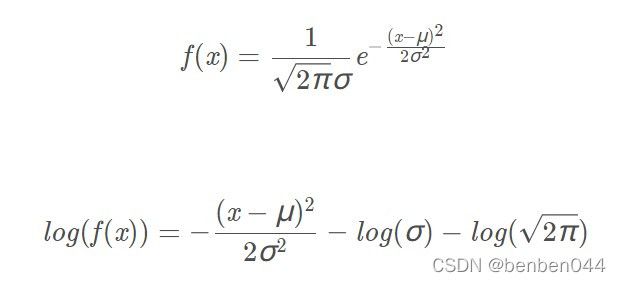
返回值:
c: tensor([0.0274, 1.0780])
c log_prob: tensor([0.3988, 0.2608])
以上为已知mean和std的情况下求解某个x的概率密度值,假如我们已知模型和x值但是不知道mean和std,此时依然可以通过上述方法进行似然估计。
似然定义:通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
所以我们可以将mean和std以及x代入函数中,然后计算概率值,我们希望概率值越大越好,即概率值的负数(loss)越小越好。
5、torch.nn.LSTM
参考文档:
LSTM细节分析理解(pytorch版) - 知乎
LSTM cell结构的理解和计算_songhk0209的博客-CSDN博客_lstm的cell
pack_padded_sequence 和 pad_packed_sequence - 知乎
LSTM一共有3个门:
输入门:控制输入(新记忆)的输入幅度
遗忘门:控制之前记忆状态的输入幅度
输出门:控制最终记忆的输出幅度
LSTM的输出有2个,细胞状态c和隐状态h。c是经输入、遗忘门的产物,也就是当前cell本身的内容;经过输出门得到h,就是想输出什么内容给下一单元。
torch.nn.LSTM关键参数说明:
- input_size:输入特征的数目,即输入的隐层维度,比如embedding_dim。
- hidden_size:隐层的特征数目,以这个size设置所有W的对应维度。
- batch_first:默认为假。若为真,则输入、输出的tensor格式为(batch, seq, feature)。为什么要这么做可参考第一个链接的内容。
LSTM的一次forward对应一个time step,如下图所示,一个红色方框对应一次forward操作。

针对输入序列长度不定的问题,LSTM通过pack进行操作。
(1)rnn.pack_padded_sequence:为了保证样本序列长度相同,使用pad_sequence函数(其他填充方式亦可)对序列进行填充。填充之后的样本序列,虽然长度相同了,但是序列里面可能填充了很多无效值0,将填充值0喂给RNN进行forward计算,不仅浪费计算资源,最后得到的值可能还会存在误差。因此在将序列送给RNN进行处理之前,需要采用pack_padded_sequence进行压缩,压缩掉无效的填充值。
(2)rnn.pad_packed_sequence:序列经过RNN处理之后的输出仍然是压紧的序列,需要采用pad_packed_sequence把压紧的序列再填充回来,便于进行后续的处理。
代码示例:
a = torch.tensor([[1,2,3], [6,0,0], [4,5,0]]) # (batch_size, max_length)
lengths = torch.tensor([3,1,2])
# 排序
a_lengths, idx = lengths.sort(0, descending=True)
print(a_lengths, idx)
# 获取返回原顺序需要的索引值,比如a(0,1,2,3)排序后变b(0,3,1,2),则返回原样的顺序需要是c(0,2,3,1)即对b的sort的结果
_, un_idx = torch.sort(idx, dim=0)
print(un_idx)
a = a[idx]
print(a)
# 定义层
emb = torch.nn.Embedding(20, 2, padding_idx=0)
lstm = torch.nn.LSTM(input_size=2, hidden_size=4, batch_first=True)
a_input = emb(a)
print(a_input)
a_packed_input = pack_padded_sequence(input=a_input, lengths=a_lengths, batch_first=True)
packed_out, (h, c) = lstm(a_packed_input)
print(packed_out)
out, _ = pad_packed_sequence(packed_out, batch_first=True)
print(out)
out = torch.index_select(out, 0, un_idx)
print(out)以上代码整体流程说明:
- 3个序列,分别转化为embedding的格式,embedding之后的维度size是2
- 序列长度按照LSTM要求将lengths从大到小排序,并且计算从新序列到原有序列的映射坐标,即un_idx索引号
- 序列放到pack_padded_sequence中进行压紧
- 压紧后的序列放到LSTM中求输出值
- 输出值通过pad_packed_sequence重新进行0填充
- 通过index_select方法将输出值按照原有顺序排列
6、pandas.read_csv函数
file_path:文件地址
sep:制定分隔符
index_col:用作行索引的列编号或者列名
parse_dates:解析日期
- boolean. True -> 解析索引获得日期字段
- list of ints or names. [1,2,3] -> 解析1,2,3列的值作为独立的日期列
- list of lists. [[1,3]] -> 合并1,3列作为一个日期列使用
decimal:字符中的小数点。默认为'.',欧洲数据使用','作为小数点。
示例:data_frame = pd.read_csv('D:\\temp\\test.txt', sep=';', index_col=0, parse_dates=True, decimal=',')
7、pandas.resample函数
该函数为根据时间序列的降采样、升采样操作。
示例举例:series.resample(rule='5T', closed='right', label='right').sum()
参数说明:
rule:重构规则,5T指的是5分钟
closed:闭合的位置,可选参数:left / right。比如right对应(3, 6]
label:所选标签在区间的位置,可选参数:left / right。比如对于(3,6]区间,left就是标签为3,right就是标签为6.
8、scipy.stats.zscore函数
计算zscore分数,对应数据计算公式为:

使用示例:
import numpy as np
from scipy import stats
a = np.array([1, 2, 3])
stats.zscore(a)
结果:array([-1.22474487, 0. , 1.22474487])
9、data(type=np.ndarray) > 0含义
元素级操作,不管data的shape是怎样的,都是data中的每一个元素与0判断的布尔值
10、tqdm的函数
最主要的是两个方法,tqdm.tqdm(iterable)和tqdm.trange函数,两者用法和效果相似,只是前者输入iterable的数据。

11、python的filter函数
过滤序列,过滤掉不符合条件的元素
语法:filter(function, iterbale)
function:判断函数
iterable: 可迭代对象
def is_odd(n):
return n % 2 == 1
newlist = filter(is_odd, [1,2,3,4,5,6,7,8,9,10])
print(newlist)
返回:[1,3,5,7,9]
12、torch.autograd.Variable类
它用来包装Tensor,将Tensor转换为Variable之后,可以装载梯度信息。
pytorch的一个重要特点就是动态计算图,计算图中的每一个节点代表一个变量,变量间建立运算关系并且可以修改,而不像tensorflow中的计算图是固定不可变的。
.data-------- 获得该节点的值,即Tensor类型的值
.grad-------- 获得该节点处的梯度信息
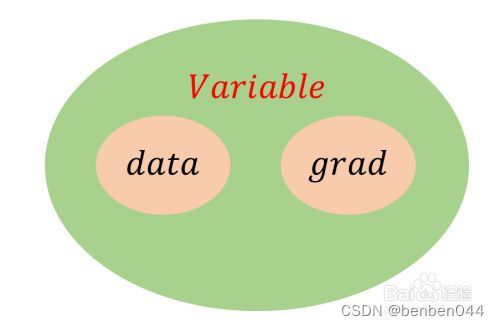
Variable的参数:requires_grad和grad_fn
(1)requires_grad的值:True和False,True代表Tensor变量需要计算梯度。
(2)grad_fn的值:该变量是否是一个计算结果,即该变量是不是一个函数的输出值。若是,则grad_fn返回一个与该函数相关的对象,否则是None。
最终变量执行.backward()计算梯度,由梯度计算的链式法则算所有的结果变量(graph leaves)。
13、torch.topk
取数组的前k个元素进行排序。该函数返回2个值,第1个值为排序的数组,第2个值为该数组中获取到的元素在原数组中的位置标号。
示例:
import torch
tensor1=torch.tensor([[10,1,2,1,1,1,1,1,1,1,10],
[3,4,5,1,1,1,1,1,1,1,1],
[7,8,9,1,1,1,1,6,1,1,1],
[1,4,7,1,1,1,1,1,1,1,1]],dtype=torch.float32)
tensor2 = torch.topk(tensor1, k=3, dim=1)
tensor2返回如下,因为dim=1,所以在列维度上进行排序,并取top3的值,同时indices返回列信息。
torch.return_types.topk(
values=tensor([[10., 10., 2.],
[ 5., 4., 3.],
[ 9., 8., 7.],
[ 7., 4., 1.]]),
indices=tensor([[ 0, 10, 2],
[ 2, 1, 0],
[ 2, 1, 0],
[ 2, 1, 0]]))tensor3 = torch.topk(tensor1, k=2, dim=0)
tensor3返回如下,因为dim=0,所以在行维度上进行排序,并取top2,同时indices返回行信息
torch.return_types.topk(
values=tensor([[10., 8., 9., 1., 1., 1., 1., 6., 1., 1., 10.],
[ 7., 4., 7., 1., 1., 1., 1., 1., 1., 1., 1.]]),
indices=tensor([[0, 2, 2, 0, 0, 0, 0, 2, 0, 0, 0],
[2, 1, 3, 1, 1, 1, 1, 0, 1, 1, 1]]))14、torch.nn.Parameter()函数
torch.nn.Parameter继承自torch.Tensor,其作用将一个不可训练的类型为Tensor的参数转化为可训练的类型为parameter的参数,并将这个参数绑定到module里面,成为module中可训练的参数。
torch.nn.Parameter(Tensor data, bool requires_grad),其中:data为传入Tensor类型参数,requires_grad默认值为True,表示可训练,False表示不可训练。
在pytorch中,变量类型是tensor的话是无法修改的,而Parameter()函数可以看作为一种类型转变函数,将不可改值的tensor转换为可训练可修改的模型参数,即与model.parameters绑定在一起,register_parameter的意思是 是否将这个参数放到model.parameters,None的意思是没有这个参数。
15、F.pad()函数
(1)功能:pad填充所用
(2)函数原型:pad(input, pad, mode='constant', value=0),其中pad=[左边, 右边, 上边, 下边]的元素个数
(3)举例说明:
import torch
import torch.nn.functional as F
x = torch.randn([1, 3, 2, 2])
print(x)
x2 = F.pad(x, [1, 2, 2, 3])
print(x2.shape)
print(x2)
说明:
最开始x的shape为[1,3,2,2],它的值为:
tensor([[[[-1.1957, 1.5045],
[ 1.7703, 0.2941]],
[[-0.8893, -0.2073],
[ 0.1383, -1.9287]],
[[-1.0069, -0.6409],
[ 0.5521, -0.3301]]]])
Pad的值为左1右2上2下3,左右都是针对最后一个维度填充的,上下是针对倒数第二个维度进行填充的。填充后的shape为[1,3,7,5]。7=2+2(上绿色)+3(下灰色),5=2+1(左红色)+2(右蓝色)。填充后的值为:
tensor([[[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -1.1957, 1.5045, 0.0000, 0.0000],
[ 0.0000, 1.7703, 0.2941, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.8893, -0.2073, 0.0000, 0.0000],
[ 0.0000, 0.1383, -1.9287, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -1.0069, -0.6409, 0.0000, 0.0000],
[ 0.0000, 0.5521, -0.3301, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]])
16、nn.ConvTranspose2d反卷积操作
(1)参考链接:
反卷积通俗详细解析与nn.ConvTranspose2d重要参数解释_iioSnail的博客-CSDN博客_nn.transpose
(2)举例说明:
import torch
import torch.nn as nn
inputs = torch.rand(1, 1, 3, 3)
outputs = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=3, padding=0, stride=2)(inputs)
print(outputs.size())
返回: torch.Size([1, 1, 7, 7])
17、nn.Upsample上采样函数
(1)函数原型:
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
size:根据不同的输入制定输出大小
scale_factor:指定输出为输入的多少倍数
mode:可使用的上采样算法,有nearest,linear,bilinear,bicubic和trilinear,默认使用nearest
align_corners:如果为True,输入的角像素将与输出张量对齐,因此保存下来这些像素的值
(2)nearest举例:
import torch
import torch.nn as nn
input = torch.arange(1, 5, dtype=torch.float32).view(1,1,2,2)
sample = nn.Upsample(scale_factor=2, mode='nearest')
print(input)
print(sample(input))
显示:
tensor([[[[1., 2.],
[3., 4.]]]])
tensor([[[[1., 1., 2., 2.],
[1., 1., 2., 2.],
[3., 3., 4., 4.],
[3., 3., 4., 4.]]]])
(3)bilinear举例
import torch
import torch.nn as nn
input = torch.arange(1, 5, dtype=torch.float32).view(1,1,2,2)
sample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
print(input)
print(sample(input))
显示:
tensor([[[[1., 2.],
[3., 4.]]]])
tensor([[[[1.0000, 1.3333, 1.6667, 2.0000],
[1.6667, 2.0000, 2.3333, 2.6667],
[2.3333, 2.6667, 3.0000, 3.3333],
[3.0000, 3.3333, 3.6667, 4.0000]]]])
18、nn.MaxPool2d(k)只有一个参数
(1)当MaxPool2d只有一个参数的时候,则kernel_size=stride_size=k
(2)举例说明:
import torch
import torch.nn as nn
m = nn.MaxPool2d(3)
input = torch.randn(1,1,6,6)
print(input)
print(m)
output = m(input)
print(output)
显示:
tensor([[[[-1.4206e+00, -4.6664e-01, 9.4361e-01, -4.9276e-01, 1.5512e+00,
-3.8033e-01],
[ 1.4935e+00, 1.8228e+00, 1.9869e+00, -2.2509e-01, 1.4214e+00,
1.6135e+00],
[-9.3966e-01, 1.9989e-01, -6.0042e-01, -2.7753e-01, 3.6198e-01,
1.1186e-01],
[-1.4253e-01, 2.0428e+00, -1.6797e-01, 5.8265e-01, -6.2981e-01,
-1.7255e+00],
[-2.6995e-04, 1.6666e+00, -3.6827e-01, 3.7731e-01, 5.9518e-01,
1.1199e+00],
[-1.2230e+00, -4.6017e-01, -1.1438e+00, -7.0442e-01, -1.6101e+00,
3.6412e-02]]]])
MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)
tensor([[[[1.9869, 1.6135],
[2.0428, 1.1199]]]])
19、BCELoss和BCEWithLogitsLoss损失函数
(1)Binary CrossEntropy 二分类交叉熵损失函数
在二分类种,我们只有两种样本(正样本和负样本),一般正样本的标签y=1,负样本的标签y=0.
因为二分类只有正样本和负样本,并且两者的概率之和为1,所以不需要预测一个向量,只需要输出一个概率值就好了。损失函数的输出一般是经过sigmoid激活函数之后,采用交叉熵损失函数计算Loss,即:
![]()
二分类采用sigmoid激活函数和BCE损失函数;
多分类采用softmax激活函数和多类别交叉熵损失函数;
对于多标签分类,采用sigmoid激活函数和BCE损失函数。
因为多标签分类种有多个类别,不能单纯地输出一个值,而是应该输出一个向量。用sigmoid激活函数分别将输出向量地每个元素转换为概率值。对于损失函数,对输出向量地每个元素单独使用交叉熵损失函数,然后计算平均值。

(2)举例说明:
参考文档:https://www.likecs.com/show-203588988.html
input = torch.FloatTensor([[-0.4089, -1.2471, 0.5907],
[-0.4897, -0.8267, -0.7349],
[0.5241, -0.1246, -0.4751]])
m = nn.Sigmoid()
input = m(input)
target = torch.FloatTensor([[0, 1, 1],
[0, 0, 1],
[1, 0, 1]])
loss = nn.BCELoss()
print(loss(input, target))
显示:tensor(0.7193)
(3)BCEWithLogitsLoss说明:
将预测结果输出自动进行sigmoid操作
(4)BCEWithLogitsLoss举例说明:
input = torch.FloatTensor([[-0.4089, -1.2471, 0.5907],
[-0.4897, -0.8267, -0.7349],
[0.5241, -0.1246, -0.4751]])
target = torch.FloatTensor([[0, 1, 1],
[0, 0, 1],
[1, 0, 1]])
loss = nn.BCEWithLogitsLoss()
print(loss(input, target))
显示:tensor(0.7193)
20、torchvision.utils.save_image保存图片
(1)使用说明:
输入的图像tensor值需要在0到1的范围内,如果图像的值大于1会出现问题。
在save_image的实现源码中,通过grid.mul(255)使值重新在255之内。
所以输入图像值=1对应255白色。
(2)使用示例:
import torchvision
pic = torch.zeros([1,1,160, 160], dtype=torch.float32)
print(pic.shape)
pic[0, 0, 0:50, 0:10] = 1.0
torchvision.utils.save_image(pic, f"pic.png")
显示:

21、torchvision.transforms.functional.resize
(1)根据期望大小调整图片width和height
(2)举例说明:
import torchvision.transforms.functional as TF
x = torch.randn([1,1,4,4])
print(x)
x2 = TF.resize(x, [6,6])
print(x2)
结果显示:
tensor([[[[ 0.3015, 0.5728, 1.2903, 0.5087],
[ 0.7782, -1.6224, 0.4027, 0.4576],
[-0.2877, 0.3393, 0.1629, -0.5763],
[-2.1579, 1.0210, 0.5487, -0.4131]]]])
tensor([[[[ 0.3015, 0.4372, 0.6924, 1.1707, 0.8995, 0.5087],
[ 0.5399, 0.0075, -0.2962, 0.6180, 0.6648, 0.4831],
[ 0.6005, -0.3475, -1.0191, 0.0864, 0.3240, 0.2853],
[-0.1101, -0.0489, 0.0441, 0.1711, -0.1005, -0.4040],
[-1.2228, -0.2713, 0.6261, 0.4099, -0.0694, -0.4947],
[-2.1579, -0.5684, 0.9423, 0.6275, 0.0678, -0.4131]]]])
可以看到:
除了四个顶点外,其他数值均发生了变化。
22、python *args用法
在def语句中使用*args,即可令函数接受数量可变的位置参数,在最后的位置参数前加*表示可以跟随任意数量的位置参数。
如果拿到的是个列表,需要在调用函数传参数时给列表前加个星号。
def log(message, *values):
if not values:
print(message)
else:
value_str = ", ".join(str(x) for x in values)
print(f"{message}:{value_str}")
log("My numbers are: ", 1, 2)
log("My numbers are: ", *[1,2])
返回:
My numbers are: :1, 2
My numbers are: :1, 2
23、python getattr获取属性
class Object:
def level0(self):
print('level0')
def level1(self):
print('level1')
def level2(self):
print('level2')
def test(self):
obj_print = getattr(self, 'level1')
obj_print()
obj = Object()
obj.test()
显示:level1
24、python globals()
以字典类型返回当前位置的全部全局变量。
def global_level1():
print('global level1')
def global_level2():
print('global level2')
print(globals())
globals()['global_level1']()
显示:
![]()
25、torch的gather()用法
gather的用法就是原shape输出数据,但是dim维的替换成index中对应的数字,其他维度的索引保持不变
import torch
b = torch.Tensor([[1,2,3], [4,5,6]])
index_1 = torch.LongTensor([[0,1], [2,0]])
index_2 = torch.LongTensor([[0,1,1], [0,0,0]])
print(torch.gather(b, dim=1, index=index_1))
print(torch.gather(b, dim=0, index=index_2))
对于index_1,输出索引为:(0,0),(0,1),(1,2),(1,0)
对于index_2,输出索引为:(0,0),(1,0),(1,0),(0,0),(0,1),(0,2)
显示结果为:
tensor([[1., 2.],
[6., 4.]])
tensor([[1., 5., 6.],
[1., 2., 3.]])
26、python sort(key lambda ...)
list.sort(key=lambda x: (-len(x), x), reverse=True)
reverse=True,按照降序排列
lambda x是指具有排序规则, (-len(x), x)是指首先用x的长度排序,如果长度相同则用出现的先后排序。
举例:
list = ['hugh', 'ynzhao', 'suiqibabab', 'lizaee']
list.sort(key=lambda x: (len(x), x), reverse=True)
print(list)
显示结果为:
['suiqibabab', 'ynzhao', 'lizaee', 'hugh']
27、pytorch查看内部信息
model.modules():
这个函数返回模型的所有组成模块信息,包括子模块的组成模块。
model.named_modules():
此函数返回的东西和modules()差不多,只不过每个模块的实例的名称也返回。
model.parameters():
通过此函数访问模型的可训练参数,例如卷积层的权重weights和偏置bias。可以通过p.requires_grad=False来冻结参数。
model.named_parameters():
此函数相比于parameters(),还会返回每个参数的名称。
state_dict()函数:
这个返回是一个字典,而前面几个返回的是一个迭代器。
字典的key是参数名称,value是参数值,其实和named_parameters()的输出差不多。
28、python的*list
用于迭代取出list中的内容。
x = [1,2,2,2,2,2] print(*x) 得到:1 2 2 2 2 2
29、nn.Sequential()
序列容器,它允许将整个容器作为单个模块(即相当于把多个模块封装成一个模块),forward()方法接收输入之后,nn.Sequential()按照内部模块的顺序自动依次计算并输出结果.
使用方法1:
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
使用方法2:
layers = [nn.Conv2d(1,20,5), nn.ReLU(), nn.Conv2d(20,64,5), nn.ReLU()]
model = nn.Sequential(*layers)
30、np.argwhere
返回满足条件的索引值
x = np.arange(6).reshape(2,3)
print(x)
print(np.argwhere(x > 1))
返回:
[[0 1 2]
[3 4 5]]
[[0 2]
[1 0]
[1 1]
[1 2]]
31、np.squeeze
从数组的形状中删除单维度条目,即把shape中为1的维度去掉。
a = np.arange(10).reshape(1, 10)
print(a.shape)
print(np.squeeze(a))
print(np.squeeze(a).shape)
显示:
(1, 10)
[0 1 2 3 4 5 6 7 8 9]
(10,)