深度学习-Resolution-robust Large Mask Inpainting with Fourier Convolutions基于傅里叶卷积的对分辨率鲁棒的掩模修复
Resolution-robust Large Mask Inpainting with Fourier Convolutions基于傅里叶卷积的对分辨率鲁棒的掩模修复
- 0.摘要
- 1.概述
- 2.方法
-
- 2.1.早期层中的全局上下文
-
- 2.1.1快速傅立叶卷积(FFC)
- 2.1.2.FFC的能力
- 2.2.损失函数
-
- 2.2.1.高感受野感知损失(High receptive field perceptual loss/HRF Loss)
- 2.2.2.对抗损失
- 2.2.3.最终损失
- 2.3. 在训练期间生成掩模
- 3.实验
-
- 3.1.和其他基线的比较
- 3.2.消融实验
- 3.3.推广到更高分辨率
- 3.4.Big LaMa
- 4.相关工作
- 5.讨论
- 参考文献
论文地址
代码地址
0.摘要
现代图像修复系统尽管取得了重大进展,但往往难以处理大面积的缺失区域、复杂的几何结构和高分辨率图像。我们发现,其中一个主要原因是修复网络和损失功能都缺乏有效的感受野。为了缓解这个问题,我们提出了一种新的方法,称为大掩模修复(LaMa)。LaMa基于i)一种新的修复网络架构,该架构使用快速傅立叶卷积(FFC),具有图像范围的感受野;ii)高感受野知觉丧失;iii)大型训练掩模,释放前两个组件的潜力。我们的修复网络提高了一系列数据集的最新水平,即使在具有挑战性的场景中(例如完成周期性结构),也能实现优异的性能。我们的模型出人意料地很好地推广到比在训练时刻看到的分辨率更高的分辨率,并且在比竞争基线更低的参数和时间成本下实现了这一点。
1.概述
图像修复问题的解决方案缺少部分的真实填充既需要“理解”自然图像的大规模结构,也需要进行图像合成。这一课题在深度学习前[1,5,13]就已经研究过,近年来通过使用深度和广度神经网络[26,30,25]和对抗性学习加速了这一进展[34, 18, 56, 44, 57, 32, 54, 61].
通常的做法是在自动生成的大数据集上训练修复系统,该数据集是通过随机屏蔽真实图像创建的。通常使用带有中间预测的复杂两阶段模型,例如平滑图像[27,54,61]、边缘[32,48]和分割图[44]。在这项工作中,我们通过一个简单的单级网络实现了最先进的结果。
大的有效感受野[29]对于理解图像的整体结构,从而解决修复问题至关重要。此外,在大掩模的情况下,即使是大但有限的感受野也可能不足以访问生成质量修复所需的信息。我们注意到,流行的卷积结构可能缺乏足够大的有效感受野。我们仔细干预系统的每个组成部分,以缓解问题,并释放单阶段解决方案的潜力。特别是:
i) 我们提出了一种基于最近发展的快速傅立叶卷积(FFC)的修复网络[4]。FFC允许接收区域覆盖整个图像,即使是在网络的早期层。我们证明了FFCs的这一特性提高了网络的感知质量和参数效率。有趣的是,FFC的感应偏差允许网络推广到训练期间从未见过的高分辨率(图5、图6)。这一发现带来了显著的实际好处,因为需要的训练数据和计算更少。
ii)我们建议使用基于高感受野的语义分割网络的感知损失[20]。这取决于观察到的感受野不足不仅会损害修复网络,还会损害感知损失。我们的损失促进了全球结构和形状的一致性。
iii)我们引入了一种积极的训练面罩生成策略,以释放前两个组件的高感受野潜力。该过程产生宽而大的掩模,迫使网络充分利用模型的高感受野和损失函数。
这就引出了大型掩模修复(LaMa)——一种新颖的单级图像修复系统。LaMa的主要组成部分是高感受野结构(i)、高感受野丢失功能(ii)和积极的训练掩模生成算法(iii)。我们仔细地将LaMa与最先进的基线进行了比较,并分析了每个提议组成部分的影响。通过评估,我们发现LaMa在仅对低分辨率数据进行训练后,可以推广到高分辨率图像。LaMa可以捕捉并生成复杂的周期结构,并且对大型掩模具有鲁棒性。此外,与竞争性基线相比,这是通过显著更少的可训练参数和推理时间成本实现的。
2.方法
我们的目标是修复一幅被未知像素m的二值遮罩遮罩的彩色图像x,遮罩后的图像被表示为x⊙ m、 遮罩m与遮罩图像x堆叠在一起⊙ m、 产生一个四通道输入张量x′=堆栈(x⊙ m、 m)。我们使用一个前馈修复网络fθ(·),我们也将其称为生成器。以x′为例,修复网络以完全卷积的方式处理输入,并产生修复的三通道彩色图像ˆx=fθ(x′)。训练是在从真实图像和合成生成的遮罩中获得的(图像、遮罩)对数据集上进行的。
2.1.早期层中的全局上下文
在具有挑战性的情况下,例如填充大型掩模,正确修复的生成需要考虑全球环境。因此,我们认为,一个好的架构应该尽早在管道中配备具有尽可能宽的接收野的单元。传统的完全卷积模型,如ResNet[14],存在有效感受野增长缓慢的问题[29]。由于通常较小(如3×3)的卷积核,感受野可能不足,尤其是在网络的早期层。因此,网络中的许多层将缺乏全局上下文,并将浪费计算和参数来创建一个全局上下文。对于宽掩模,特定位置的生成器的整个感受野可能位于掩模内,因此只能观察到缺失的像素。对于高分辨率图像,这个问题变得尤为突出。
2.1.1快速傅立叶卷积(FFC)
[4]是最近提出的算子,允许在早期层中使用全局上下文。FFC基于通道快速傅里叶变换(FFT)[2],具有覆盖整个图像的感受野。FFC将通道分成两个并行分支:i)局部分支使用常规卷积,ii)全局分支使用实FFT来解释全局上下文。实FFT只能应用于实值信号,逆实FFT确保输出是实值的。与FFT相比,真正的FFT只使用了频谱的一半。具体而言,FFC采取以下步骤:
- a) 将实FFT2d应用于输入张量 ,并连接实部和虚部 :
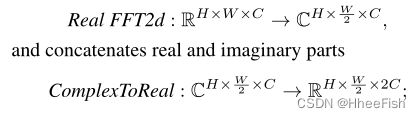
- b) 在频域中应用卷积块
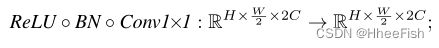
- c) 应用逆变换来恢复空间结构

最后,本地(i)和全局(ii)分支的输出被融合在一起。FFC的图示如图2所示。

图2:大型掩模修复(LaMa)的拟议方法方案。LaMa基于一个前馈的ResNetlike修复网络,该网络使用:最近提出的快速傅立叶卷积(FFC)[4],一种结合对抗性损失和高感受野感知损失的多分量损失,以及一个训练时间大的掩模生成过程。
2.1.2.FFC的能力
FFC是完全可微的,易于使用,可替代传统卷积。由于图像范围很广,FFC允许生成器从早期层开始考虑全局环境,这对于高分辨率图像修复至关重要。这也提高了效率:可训练参数可用于推理和生成,而不是“等待”信息传播。
我们发现FFC非常适合捕捉周期性结构,这在人造环境中很常见,例如砖块、梯子、窗户等(图4)。有趣的是,在所有频率上共享相同的卷积会使模型向尺度等变方向移动[4](图5、6)。
2.2.损失函数
修复问题本质上是模棱两可的。对于相同的缺失区域,可能会有许多看似合理的填充,尤其是当“洞”变得更大时。我们将讨论拟议损失的组成部分,这些组成部分共同允许处理问题的复杂性。
2.2.1.高感受野感知损失(High receptive field perceptual loss/HRF Loss)
传统的监督损失需要生成器精确地重建基本事实。然而,图像的可见部分通常不包含足够的信息来精确重建遮罩部分。因此,由于对修复内容的多个看似合理的模式进行平均,使用传统的监督会导致模糊的结果。
相比之下,感知损失[20]通过一个基本的预训练网络φ(·)评估从预测图像和目标图像中提取的特征之间的距离。它不需要精确的重建,允许重建图像的变化。大型掩模修复的重点转向了对整体结构的理解。因此,我们认为使用快速增长的感受野的基础网络是很重要的。我们介绍了高感受野知觉损失(HRF PL),它使用了高感受野基础模型φHRF(·):
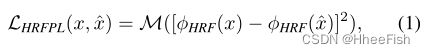
其中[·− ·]2是逐元素操作,M是连续的两阶段平均操作(层内平均值的层间平均值)。可以使用傅里叶或扩张卷积来实现φHRF(x)。如消融研究(表3)所示,HRF感知损失似乎对我们的大型掩模修复系统至关重要。
前提问题:
一个重要的前提问题是训练感知损失的基本网络。例如,使用分割模型作为感知损失的主干可能有助于关注高层信息,例如对象及其部分。相反,分类模型更关注纹理[10],这可能会引入对高级信息有害的偏见。
2.2.2.对抗损失
我们使用对抗性损失来确保修复模型fθ(x′)生成自然的局部细节。我们定义了一个鉴别器Dξ(·),它在局部补丁级别工作[19],区分“真实”和“虚假”补丁。只有与遮罩区域相交的补丁才会得到“假”标签。由于监督HRF感知损失,生成器快速学习复制输入图像的已知部分,因此我们将生成图像的已知部分标记为“真实”。最后,我们使用非饱和对抗损失:

其中x是数据集的样本,m是合成生成的掩码,xˆ=fθ*(x′)是x′=stack(x′⊙m, m)的修复结果,sgvar停止梯度w.r.t var,LAdv是要优化的联合损失。
2.2.3.最终损失
在最终损失中,我们也使用R1=Ex||∇Dξ(x)||2梯度惩罚[31,38,7],以及基于鉴别器的感知损失或所谓的特征匹配损失——鉴别器网络LDiscPL特征的感知损失[45]。众所周知,LDiscPL可以稳定训练,在某些情况下会略微提高表现。修复系统的最终损失函数

是所讨论损失的加权和,其中LAdv和LDiscPL负责生成自然外观的局部细节,而LHRFPL负责监督信号和全局结构的一致性
2.3. 在训练期间生成掩模
我们系统的最后一个组成部分是掩码生成策略。每个训练示例x′都是一张来自训练数据集的真实照片,该数据集由合成生成的遮罩叠加。与数据增强对最终性能有很大影响的判别模型类似,我们发现掩模生成策略显著影响修复系统的性能。
因此,我们选择了一种积极的大掩模生成策略。该策略统一使用从多边形链中提取的样本,该多边形链由高随机宽度(宽遮罩)和任意纵横比的矩形(长方体遮罩)展开。我们的掩模示例如图3所示。

图3:来自不同训练掩模生成策略的样本。我们认为,掩模的生成方式对系统的最终性能有很大影响。与传统做法(例如DeepFillv2)不同,我们使用了更具攻击性的大掩模生成策略,其中掩模统一来自宽掩模或盒掩模策略。大掩模策略的掩模面积大,更重要的是,更宽(直方图见补充材料)。使用我们的策略进行训练有助于模型在宽掩模和窄掩模上表现更好(表4)。在准备测试数据集的过程中,我们避免使用覆盖图像50%以上的掩模。
我们测试了几种方法的大掩模训练和窄掩模训练,发现使用大掩模策略的训练通常可以提高窄掩模和宽掩模的性能(表4)。这表明,增加掩模的多样性可能有利于各种修复系统。补充资料中提供了采样算法。
3.实验
在本节中,我们证明了所提出的技术在标准低分辨率上优于一系列强基线,并且在修补更宽的孔时,这种差异更加明显。然后我们进行消融研究,显示FFC的重要性、高感受野知觉丧失和大掩模。令人惊讶的是,该模型可以推广到高分辨率、从未见过的分辨率,而与最具竞争力的基线相比,其参数要少得多
实施细节
对于LaMa修复网络,我们使用了一种类似ResNet[14]的架构,包括3个下采样块、6-18个残差块和3个上采样块。在我们的模型中,残差块使用FFC。补充材料中提供了有关鉴别器结构的更多细节。我们使用Adam[23]优化器,修复和鉴别器网络的固定学习率分别为0.001和0.0001。除非另有说明,否则所有模型都经过100万次迭代,批量为30。在所有实验中,我们使用坐标方向的波束搜索策略选择超参数。该方案导致权重值κ=10,α=30,β=100,γ=0.001。我们将这些超参数用于所有模型的训练,损失消融研究(见第3.2节)中描述的除外。在所有情况下,超参数搜索都在单独的验证子集上执行。补充资料中提供了有关数据集拆分的更多信息。
数据集和评价指标
我们使用Places[66]和CelebAHQ[21]数据集。我们遵循最新Image2图像文献中的既定实践,并使用学习的感知图像块相似性(LPIPS)[63]和弗雷切特起始距离(FID)[15]指标。与像素级L1和L2距离相比,LPIPS和FID更适合在多个自然完成是合理的情况下测量大型掩模修复的性能。使用PyTorch[33]、PyTorchLightning[9]和Hydra[49]实现了实验管道。
3.1.和其他基线的比较

表1:Places和CelebA HQ数据集修复的定量评估。我们报告了感知图像块相似性(LPIPS)和弗雷切特起始距离(FID)度量。这个▲ 表示退化,以及▼ 表示与我们的LaMa-Fourier模型(见第一行)相比,分数有所提高。报告了测试掩码生成的不同策略的度量,即窄掩码、宽掩码和分段掩码。LaMa Fourier在很多基线上都表现出色。科莫德根[64]和马德夫[67]是唯一接近的两条基线。然而,这两个模型都比LaMa-Fourier模型重得多,平均性能更差,表明我们的方法更有效地利用了可训练参数。
我们将提出的方法与表1中给出的一些强基线进行了比较。只有公开可用的预训练模型用于计算这些指标。对于每个数据集,我们验证了基于窄、宽和分段的掩模的性能。LaMaFourier的表现始终优于大多数基线,同时比最强的竞争对手拥有更少的参数。仅有的两个竞争基线CoModGAN[64]和MADF[67]使用≈ 4×和≈ 3×更多参数。这种差异对于宽掩模尤其明显。
用户研究
为了缓解所选指标可能存在的偏差,我们进行了一项众包用户研究。用户研究的结果与定量评估有很好的相关性,并表明,与其他方法相比,我们的方法产生的修复效果更好,可检测性更低。补充材料中提供了方案和用户研究结果。
3.2.消融实验
这项研究的目的是仔细检查该方法不同组成部分的影响。在这一节中,我们将展示Places数据集的结果;CelebA数据集的其他结果见补充资料。
fθ(·)的感受野

表2:该表展示了不同LaMa架构的性能,而其他组件保持不变。这个▲ 表示退化,以及▼ 表示与基本傅里叶模型(见第一行)相比的改进。基于FFC的模型在窄掩模上可能会牺牲一点性能,但在宽掩模上显著优于具有规则卷积的较大模型。在视觉上,基于FFC的模型可以更好地恢复复杂的视觉结构,如图4所示。
FFC增加了我们系统的有效感受野。添加FFC可显著提高宽掩模修复的FID分数(表2)。
图4:512×512图像上各种修复系统的并排比较。众所周知,窗户和链环围栏等重复性结构很难修复。FFC可以更好地生成这些类型的结构。有趣的是,LaMa-Fourier即使在比较过程中使用较少的参数,也表现得最好,同时提供可行的推理时间,即LaMa-Fourier平均仅为∼ 比普通LaMa慢20%。
当模型的分辨率高于训练时,感受野的重要性最为显著。如图5所示,当分辨率超过训练时使用的分辨率时,具有规则卷积的模型会产生可见的伪影。定量验证了同样的效果(图6)。FFC还大大改进了重复结构的生成,例如windows(图4)。有趣的是,LaMa傅里叶变换只慢20%,而比LaMa常规变换小40%。

图6:基于FFC的修复模型可以转换到训练中从未见过的更高分辨率,质量下降明显更小。所有LaMa模型都以256×256分辨率进行训练。∗我们提供的最佳模型的大样本可供参考,因为它是在不同条件下训练的(第3.4节)
扩张的卷积[55,3]是另一种选择,允许感受野快速增长。与FFC类似,扩展卷积提高了修复系统的性能。这进一步支持了我们关于有效感受野快速增长对图像修复的重要性的假设。然而,扩张的卷积具有更严格的感受野,并且严重依赖于尺度,导致对更高分辨率的低泛化(图6)。扩展卷积在大多数框架中都得到了广泛的应用,在资源有限的情况下(例如在移动设备上),可以作为傅里叶卷积的实际替代。我们在补充材料中提供了LaMa-带有扩张卷积架构的更多细节。
损失

表3:不同知觉损失的LaMa正规训练的比较。这个▲ 表示退化,以及▼ 表示与使用HRF感知损失训练的模型相比,分数有所提高,该模型基于具有扩张卷积的分割ResNet50(显示在第一行)。扩大的卷积和借口问题都提高了分数。
我们验证了通过扩大卷积实现的知觉损失的高感受野确实提高了修复质量(表3)。除了使用膨胀层,前提问题和设计选择也被证明是重要的。对于每个损失变量,我们进行了权重系数搜索,以确保公平评估。
掩模生成

表4:该表显示了使用窄口罩或宽口罩培训不同修复方法的性能指标。这个▲ 表示退化,以及▼ 表示相应方法的宽面罩训练导致的分数提高。喇嘛和地区修复显然受益于宽口罩的训练。这是一个经验证据,表明积极的掩模生成可能有利于其他修复系统。
更宽的训练掩模可以改善LaMa(我们的)和局部[30]的宽洞和窄洞修复(表4)。然而,较宽的掩模可能会使结果更糟,窄掩模上的DeepFill v2[57]和EdgeConnect[32]就是这种情况。我们假设这种差异是由特定的设计选择(例如,生成器的高接收场或损失函数)造成的,这些选择使一种方法或多或少适合同时修复窄和宽掩模
3.3.推广到更高分辨率

图5:修复模型转移到更高的分辨率。所有LaMa模型都使用512×512的256×256个作物进行训练,MADF[67]直接在512×512上进行训练。随着分辨率的增加,具有规则卷积的模型迅速开始产生关键伪影,而基于FFC的模型继续生成语义一致且细节精细的图像。更多关于51M模型的正面和负面例子可以在51M模型上找到
直接以高分辨率进行训练速度慢,计算成本高。不过,大多数现实世界的图像编辑场景都需要修复才能在高分辨率下工作。因此,我们在更大的图像上评估了我们的模型,该模型使用512×512图像中的256×256种作物进行训练。我们以一种完全卷积的方式应用模型,也就是说,图像是在一次过程中处理的,而不是面片。
图6:基于FFC的修复模型可以转换到训练中从未见过的更高分辨率,质量下降明显更小。所有LaMa模型都以256×256分辨率进行训练。∗我们提供的最佳模型的大样本可供参考,因为它是在不同条件下训练的(第3.4节)
基于FFC的模型可以更好地转换到更高的分辨率(图6)。我们假设FFC在不同尺度下更为稳健,因为i)图像宽的感受野,ii)尺度变化后保留频谱的低频,iii)频域中1×1卷积的固有尺度等变。虽然所有模型都能很好地推广到512×512分辨率,但与所有其他模型相比,支持FFC的模型在1536×1536分辨率下保持了更高的质量和一致性(图5)。值得注意的是,它们以比竞争基线低得多的参数成本实现了这一质量
3.4.Big LaMa
为了验证我们的方法对真实高分辨率图像的可扩展性和适用性,我们使用更多资源训练了一个大型修复大LaMa模型
BigLaMa傅里叶与LaMa傅里叶在三个方面不同:生成的深度;训练数据集;以及批次的大小。它有18个残差块,全部基于FFC,产生51M个参数。该模型是在Places Challenge数据集[66]的450万张图像子集上训练的。就像我们的标准基础模型一样,BigLaMa只在大约512×512张图像的低分辨率256×256作物上训练。Big LaMa使用的批量更大,为120(而不是我们其他型号的30)。虽然我们认为这个模型相对较大,但它仍然比一些基线小。它在八个NVidia V100 GPU上训练了大约240小时。BigLaMa模型的修复示例如图1和图5所示。
4.相关工作
早期数据驱动的图像修复方法依赖于基于面片[5]和基于最近邻[13]的生成。深度学习时代最早的修复作品之一[34]使用了convnet,其编码器-解码器体系结构经过对抗式训练[11]。到目前为止,这种方法仍然普遍用于深度修复。完成网络的另一种流行选择是基于U-Net的架构[37],例如[26,50,59,27]。
一个共同关注的问题是网络掌握本地和全球环境的能力。为此,[18]建议合并扩张的卷积[55]以扩大感受野;此外,两个歧视者应该分别鼓励全球和地方的一致性。在[46]中,有人建议在具有不同感受野的完成网络中使用分支。为了从空间上遥远的斑块中借用信息,[56]提出了上下文注意层。[28,47,65]中提出了其他注意机制。我们的研究证实了信息在遥远地点之间有效传播的重要性。我们的方法的一个变体严重依赖于[41]所启发的扩张卷积块。作为更好的替代方案,我们提出了一种基于频域变换(FFC)的机制[4]。这也符合最近的趋势,即在计算机视觉中使用变压器[6,8],并将傅里叶变换视为自我关注的轻量级替代品[24,35]。
在更全局的层面上,[56]引入了一个由粗到精的框架,涉及两个网络。在他们的方法中,第一个网络在孔中完成粗略的全局结构,而第二个网络则使用它作为指导来细化局部细节。这样的两阶段方法遵循了结构-纹理分解[1]的一个相对古老的想法,并在随后的作品中流行起来。一些研究[40,42]修改了框架,以便同时获得粗略和精细的结果成分,而不是按顺序获得。有几项工作建议采用两阶段方法,将其他结构类型的完成作为中间步骤:在[32]中使用显著边缘,在[44]中使用语义分割贴图,在[48]中使用前景对象轮廓,在[52]中使用梯度贴图,在[36]中使用保留边缘的平滑图像。另一个趋势是渐进式方法[62,12,25,61]。与所有这些工作相比,我们证明了精心设计的单阶段方法可以取得非常好的效果。
为了处理不规则掩模,有几项工作修改了卷积层,引入了部分卷积[26]、选通卷积[57]、轻型选通卷积[54]和区域卷积[30]。研究人员探索了各种形状的训练口罩,包括随机的[18]、自由形式的[57]和物体形状的口罩[54,61]。我们发现,只要训练口罩的轮廓足够多样,口罩生成的确切方式就没有口罩的宽度那么重要。许多损失被提议用于培训修复网络。
通常,像素级(例如。ℓ1.ℓ2) 使用对抗性损失。一些方法对像素级的损失应用空间折扣加权策略[34,53,56]。使用简单卷积鉴别器[34,52]或PatchGAN鉴别器[18,59,36,28]实现对抗性损失。其他流行的选择是带有梯度惩罚鉴别器[56,54]和光谱归一化鉴别器[32,57,27,61]的瓦瑟斯坦对抗性损失。在之前的工作[31,22]之后,我们在系统中使用了r1梯度惩罚面片鉴别器。知觉丧失也很常见,通常是VGG16[26,47,25,27]或VGG-19[51,43,32,52]主干在ImageNet分类上预训练[39]。与这些作品相比,我们发现这种感知损失对于图像修复来说是次优的,并提出了一种更好的替代方案。修复框架通常包含样式[26,30,30,47,32,25]和特征匹配[51,44,32,16]损失。后者也适用于我们的系统。
5.讨论
在这项研究中,我们研究了一种简单的单阶段方法在大型掩模修复中的应用。我们已经证明,这种方法非常有竞争力,并且可以推动图像修复技术的发展,只要适当选择体系结构、损失函数和掩模生成策略。所提出的方法可以很好地生成重复的视觉结构(图1,4),这似乎是许多修复方法的一个问题。然而,当涉及到强烈的视角扭曲时,LaMa通常会有些扭曲(见补充材料)。我们想指出的是,对于来自互联网的不属于数据集的复杂图像,情况通常是这样。FFCs能否解释周期信号的这些变形仍然是一个问题。有趣的是,FFC允许该方法推广到从未见过的高分辨率,并且与最先进的基线相比,参数效率更高。傅里叶或扩张卷积不是接收高感受野的唯一选择。例如,视觉转换器[6]可以获得较高的感受野,这也是未来研究的一个激动人心的课题。我们相信,具有大接收场的模型将为高效高分辨率计算机视觉模型的开发提供新的机会。
参考文献
[1] Marcelo Bertalm´ıo, Luminita A. Vese, Guillermo Sapiro, and Stanley J. Osher. Simultaneous structure and texture image inpainting. In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2003), 16-22 June 2003, Madison, WI, USA, pages 707–712. IEEE Computer Society, 2003.
[2] E Oran Brigham and RE Morrow. The fast fourier transform. IEEE spectrum, 4(12):63–70, 1967.
[3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In Yoshua Bengio and Yann LeCun, editors, Proc. ICLR, 2015.
[4] Lu Chi, Borui Jiang, and Yadong Mu. Fast fourier convolution. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 4479–4488. Curran Associates, Inc., 2020.
[5] Antonio Criminisi, Patrick Pérez, and Kentaro Toyama. Object removal by exemplar-based inpainting. In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2003), 16-22 June 2003, Madison, WI, USA, pages 721–728. IEEE Computer Society, 2003.
[6] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[7] H. Drucker and Y. Le Cun. Improving generalization performance using double backpropagation. IEEE Transactions on Neural Networks, 3(6):991–997, 1992.
[8] Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021.
[9] WA Falcon and .al. Pytorch lightning. GitHub. Note: https://github.com/PyTorchLightning/pytorch-lightning, 3, 2019.
[10] Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. Imagenet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. In International Conference on Learning Representations, 2019.
[11] Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. arXiv preprint arXiv:1406.2661, 2014.
[12] Zongyu Guo, Zhibo Chen, Tao Yu, Jiale Chen, and Sen Liu. Progressive image inpainting with full-resolution residual network. In Proceedings of the 27th ACM International Conference on Multimedia, pages 2496–2504, 2019.
[13] James Hays and Alexei A. Efros. Scene completion using millions of photographs. ACM Trans. Graph., 26(3):4, 2007.
[14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceed ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[15] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. arXiv preprint arXiv:1706.08500, 2017.
[16] Zheng Hui, Jie Li, Xiumei Wang, and Xinbo Gao. Image fine-grained inpainting. arXiv preprint arXiv:2002.02609, 2020.
[17] Håkon Hukkelås, Frank Lindseth, and Rudolf Mester. Image inpainting with learnable feature imputation. In Pattern Recognition: 42nd DAGM German Conference, DAGM GCPR 2020, Tübingen, Germany, September 28–October 1, 2020, Proceedings 42, pages 388–403. Springer, 2021.
[18] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. Globally and locally consistent image completion. ACM Transactions on Graphics (ToG), 36(4):1–14, 2017.
[19] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on, 2017.
[20] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision, pages 694–711. Springer, 2016.
[21] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196, 2017.
[22] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019.
[23] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[24] James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santiago Ontanon. Fnet: Mixing tokens with fourier transforms. arXiv preprint arXiv:2105.03824, 2021.
[25] Jingyuan Li, Ning Wang, Lefei Zhang, Bo Du, and Dacheng Tao. Recurrent feature reasoning for image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7760–7768, 2020.
[26] Guilin Liu, Fitsum A Reda, Kevin J Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), pages 85–100, 2018.
[27] Hongyu Liu, Bin Jiang, Yibing Song, Wei Huang, and Chao Yang. Rethinking image inpainting via a mutual encoder-decoder with feature equalizations. arXiv preprint arXiv:2007.06929, 2020.
[28] Hongyu Liu, Bin Jiang, Yi Xiao, and Chao Yang. Coherent semantic attention for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4170–4179, 2019.
[29] Wenjie Luo, Yujia Li, Raquel Urtasun, and Richard Zemel. Understanding the effective receptive field in deep convolutional neural networks. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016.
[30] Yuqing Ma, Xianglong Liu, Shihao Bai, Lei Wang, Aishan Liu, Dacheng Tao, and Edwin Hancock. Region-wise generative adversarial image inpainting for large missing areas. arXiv preprint arXiv:1909.12507, 2019.
[31] Lars Mescheder, Sebastian Nowozin, and Andreas Geiger. Which training methods for gans do actually converge? In International Conference on Machine Learning (ICML), 2018.
[32] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z Qureshi, and Mehran Ebrahimi. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv preprint arXiv:1901.00212, 2019.
[33] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019.
[34] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2536–2544, 2016.
[35] Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, and Jie Zhou. Global filter networks for image classification. arXiv preprint arXiv:2107.00645, 2021.
[36] Yurui Ren, Xiaoming Yu, Ruonan Zhang, Thomas H Li, Shan Liu, and Ge Li. Structureflow: Image inpainting via structure-aware appearance flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 181–190, 2019.
[37] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. Unet: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
[38] Andrew Slavin Ros and Finale Doshi-Velez. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 1660–1669, 2018.
[39] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
[40] Min-cheol Sagong, Yong-goo Shin, Seung-wook Kim, Seung Park, and Sung-jea Ko. Pepsi: Fast image inpainting with parallel decoding network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11360–11368, 2019.
[41] René Schuster, Oliver Wasenmuller, Christian Unger, and Didier Stricker. Sdc-stacked dilated convolution: A unified descriptor network for dense matching tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2556–2565, 2019.
[42] Yong-Goo Shin, Min-Cheol Sagong, Yoon-Jae Yeo, SeungWook Kim, and Sung-Jea Ko. Pepsi++: Fast and lightweight network for image inpainting. IEEE transactions on neural networks and learning systems, 32(1):252–265, 2020.
[43] Yuhang Song, Chao Yang, Zhe Lin, Xiaofeng Liu, Qin Huang, Hao Li, and C-C Jay Kuo. Contextual-based image inpainting: Infer, match, and translate. In Proceedings of the European Conference on Computer Vision (ECCV), pages 3–19, 2018.
[44] Yuhang Song, Chao Yang, Yeji Shen, Peng Wang, Qin Huang, and C-C Jay Kuo. Spg-net: Segmentation prediction and guidance network for image inpainting. arXiv preprint arXiv:1805.03356, 2018.
[45] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018.
[46] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia. Image inpainting via generative multi-column convolutional neural networks. arXiv preprint arXiv:1810.08771, 2018.
[47] Chaohao Xie, Shaohui Liu, Chao Li, Ming-Ming Cheng, Wangmeng Zuo, Xiao Liu, Shilei Wen, and Errui Ding. Image inpainting with learnable bidirectional attention maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8858–8867, 2019.
[48] Wei Xiong, Jiahui Yu, Zhe Lin, Jimei Yang, Xin Lu, Connelly Barnes, and Jiebo Luo. Foreground-aware image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5840– 5848, 2019.
[49] Omry Yadan. Hydra - a framework for elegantly configuring complex applications. Github, 2019.
[50] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the European conference on computer vision (ECCV), pages 1–17, 2018.
[51] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li. High-resolution image inpainting using multiscale neural patch synthesis. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6721–6729, 2017.
[52] Jie Yang, Zhiquan Qi, and Yong Shi. Learning to incorporate structure knowledge for image inpainting. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12605–12612, 2020.
[53] Raymond A Yeh, Chen Chen, Teck Yian Lim, Alexander G Schwing, Mark Hasegawa-Johnson, and Minh N Do. Semantic image inpainting with deep generative models. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5485–5493, 2017.
[54] Zili Yi, Qiang Tang, Shekoofeh Azizi, Daesik Jang, and Zhan Xu. Contextual residual aggregation for ultra high-resolution image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7508–7517, 2020.
[55] Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015.
[56] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Generative image inpainting with contextual attention. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5505–5514, 2018.
[57] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4471–4480, 2019.
[58] Tao Yu, Zongyu Guo, Xin Jin, Shilin Wu, Zhibo Chen, Weiping Li, Zhizheng Zhang, and Sen Liu. Region normalization for image inpainting. In AAAI, pages 12733–12740, 2020.
[59] Yanhong Zeng, Jianlong Fu, Hongyang Chao, and Baining Guo. Learning pyramid-context encoder network for highquality image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1486–1494, 2019.
[60] Yanhong Zeng, Jianlong Fu, Hongyang Chao, and Baining Guo. Aggregated contextual transformations for highresolution image inpainting. In Arxiv, pages–, 2020.
[61] Yu Zeng, Zhe Lin, Jimei Yang, Jianming Zhang, Eli Shechtman, and Huchuan Lu. High-resolution image inpainting with iterative confidence feedback and guided upsampling. In European Conference on Computer Vision, pages 1–17. Springer, 2020.
[62] Haoran Zhang, Zhenzhen Hu, Changzhi Luo, Wangmeng Zuo, and Meng Wang. Semantic image inpainting with progressive generative networks. In Proceedings of the 26th ACM international conference on Multimedia, pages 1939– 1947, 2018.
[63] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018.
[64] Shengyu Zhao, Jonathan Cui, Yilun Sheng, Yue Dong, Xiao Liang, Eric I Chang, and Yan Xu. Large scale image completion via co-modulated generative adversarial networks. In International Conference on Learning Representations (ICLR), 2021.
[65] Chuanxia Zheng, Tat-Jen Cham, and Jianfei Cai. Pluralistic image completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1438–1447, 2019.
[66] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017.
[67] Manyu Zhu, Dongliang He, Xin Li, Chao Li, Fu Li, Xiao Liu, Errui Ding, and Zhaoxiang Zhang. Image inpainting by end-to-end cascaded refinement with mask awareness. IEEE Transactions on Image Processing, 30:4855–4866, 2021.