python+opencv+TESSERT-OCR实现车牌的检测与识别
python+opencv+TESSERT-OCR实现车牌的检测与识别
开学花了十天时间0基础搞出来的,分享给大家,如果有什么错误希望大家给我指正。python师从小甲鱼,opencv师从贾志刚,B站都有视频,也参考了论坛上很多大佬的博客。话不多说,先上运行结果。
当然,这只是一个简易的识别或者说算不上一个车牌识别的系统,因为你可能换一张图片它就识别不出来,但是其中对图像处理的方法还是有通用性的。
1.配置环境
我们需要用到的包如下
import cv2 as cv
import numpy as np
import pytesseract as tess
from PIL import Image
2.打开图片
打开图片并压缩大小,图像不宜太大
src = cv.imread("D:/opencv/image/license.png") # 打开要识别的照片,不能有中文路径
print(src.shape)#输出粗一下原图的大小
license = cv.resize(src, (800, int(800 * src.shape[0] / src.shape[1])))#压缩一下图片,保持了原图的宽高的比例
print(license.shape)#输出一下压缩过后的大小
cv.namedWindow('inputImage', 0)#第二个参数为0,可以改变窗口的大小
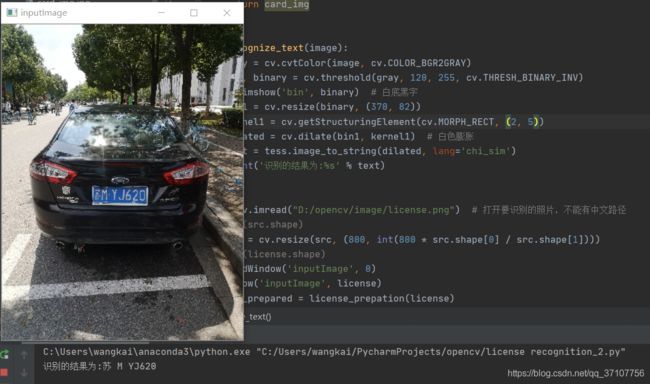
我们来看一下结果

第一行为原图的大小,第二行为压缩过后的大小,参数的含义为宽,高,三通道
![]()
3.图像处理
图像处理的目的是为了能够找出车牌所在的区域。人一眼就能在这张图片中找出车牌的位置,但计算机不行,图片在计算机眼里只是一个个数字。我的思路如下:色彩空间转换——提取蓝色区域——高斯模糊——转为灰度图片——二值化——开闭操作。这一块有很多种方法,步骤也不相同。
def license_prepation(image):
image_hsv = cv.cvtColor(image, cv.COLOR_BGR2HSV) # 从RGB图像转为hsv色彩空间
low_hsv = np.array([108, 43, 46]) # 设置颜色
high_hsv = np.array([124, 255, 255])
mask = cv.inRange(image_hsv, lowerb=low_hsv, upperb=high_hsv) # 选出蓝色的区域
cv.imshow('mask', mask)
image_dst = cv.bitwise_and(image, image, mask=mask) # 取frame与mask中不为0的相与,在原图中扣出蓝色的区域,mask=mask必须有
cv.imshow('license_dst', image_dst)
image_blur = cv.GaussianBlur(image_dst, (7, 7), 0)#高斯模糊,消除噪声。第二个参数为卷积核大小,越大模糊的越厉害
cv.imshow('license_blur',image_blur)
image_gray = cv.cvtColor(image_blur, cv.COLOR_BGR2GRAY)#转为灰度图像
ret, binary = cv.threshold(image_gray, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)#二值化
cv.imshow('binary', binary)
kernel1 = cv.getStructuringElement(cv.MORPH_RECT, (4, 6))#得到一个4*6的卷积核
image_opened = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel1)#开操作,去一些干扰
cv.imshow('license_opened', image_opened)
kernel2 = cv.getStructuringElement(cv.MORPH_RECT, (7, 7))#得到一个7*7的卷积核
image_closed = cv.morphologyEx(image_opened, cv.MORPH_CLOSE, kernel2)#闭操作,填充一些区域
cv.imshow('license_closed', image_closed)
return image_closed
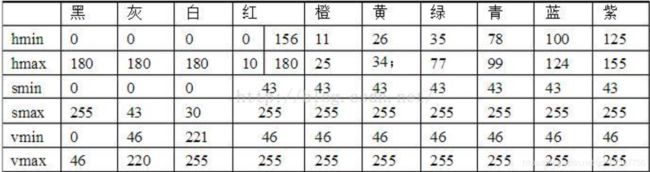
各个颜色在hsv空间中的表示如下图所示,我为了识别效果做了适当的调整。
看一下在每一步操作之后的效果






到这一步为止我们可以看出车牌所在的那一块矩形轮廓已经很清晰了。下一步我们用cv.findContoursl来找出图中的轮廓,此API的会将找到的轮廓返回到contours中
license_prepared = license_prepation(license)
contours, hierarchy = cv.findContours(license_prepared, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
轮廓筛选
找出的轮廓可能不止一个,我们要对这些轮廓进行筛选。参考了别的博主的方法。首先设置了一个MIN_Area为2000来将一些很小的轮廓去掉,同时矩形轮廓的长和宽的比例进行筛选,车牌的比例在4左右。
def choose_license_area(contours, Min_Area):
temp_contours = []
for contour in contours:
if cv.contourArea(contour) > Min_Area: # 面积大于MIN_AREA的区域保留
temp_contours.append(contour)
license_area = []
for temp_contour in temp_contours:
rect_tupple = cv.minAreaRect(temp_contour)
# print(rect_tupple)
rect_width, rect_height = rect_tupple[1] # 0为中心点,1为长和宽,2为角度
if rect_width < rect_height:
rect_width, rect_height = rect_height, rect_width
aspect_ratio = rect_width / rect_height
# 车牌正常情况下宽高比在2 - 5.5之间
if aspect_ratio > 2 and aspect_ratio < 5.5:
license_area.append(temp_contour)
return license_area
在原图中扣出车牌的区域
通过上面的步骤,车牌的位置我们已经能够确定。下面我们要在原图中把车牌给抠出来。
license_area = choose_license_area(contours, Min_Area)
def license_segment(license_area):
if (len(license_area)) == 1:
for car_plate in license_area:
row_min, col_min = np.min(car_plate[:, 0, :], axis=0) # 行是row 列是col
row_max, col_max = np.max(car_plate[:, 0, :], axis=0)#这两行代码为了找出车牌位置的坐标
card_img = license[col_min:col_max, row_min:row_max, :]
# cv.imshow("card_img", card_img)
cv.imwrite("card_img.jpg", card_img)
return card_img
result = license_segment(license_area)
cv.imshow('result', result)#将检测到的车牌显示出来
看一下结果

识别
到这一块我们的工作已经完成一半了,车牌已经检测出来了,下面进行识别。
车牌的识别我们需要用到tessert-ocr,因为车牌有中文,所以我们还要下载OCR的中文包chi_sim.traineddata并将其放在tessert-ocr安装目录下有一个 tessdata文件夹中,随后就可以正常使用了。tessert-ocr安装包和中文包都在本文最后的链接中。
def recognize_text(image):
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)#转为灰度图片
ret, binary = cv.threshold(gray, 120, 255, cv.THRESH_BINARY_INV)#二值化
cv.imshow('bin', binary) #显示二值过后的结果, 白底黑字
bin1 = cv.resize(binary, (370, 82))#改变一下大小,有助于识别
kernel1 = cv.getStructuringElement(cv.MORPH_RECT, (2, 5))#获取一个卷积核,参数都是自己调的
dilated = cv.dilate(bin1, kernel1) # 白色区域膨胀
text = tess.image_to_string(dilated, lang='chi_sim')#识别
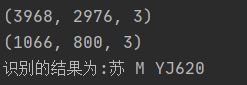
print('识别的结果为:%s' % text)
我们看一下结果

总结
到此,整个设计就结束了。说一下,图像处理的步骤有很多种方法,各有优点,大家可以自己去研究。目的就是为了找去我们要的那一块矩形区域。同时,我们用到的卷积核大小,都是自己调的,不一定要按照我这个来。本文所用的完整代码,原图片,tessert-ocr安装包以及中文库我都已经上传了,大家可以自行在以下链接下载。
https://download.csdn.net/download/qq_37107756/12897928
最后大家有什么疑问可以给我留言,一起加油