异常检测综述(Anomaly Detection: A Survey)
Anomaly Detection: A Survey
异常检测综述:
异常检测是一个重要的问题,已经在不同的研究领域和应用领域进行了研究。许多异常检测技术是专门为某些应用领域开发的,而其他技术则更为通用。本综述试图对异常检测的研究提供一个结构化和全面的概述。我们根据每种技术所采用的基本方法,将现有技术分为不同的类别。对于每个类别,我们都确定了关键假设,这些假设被技术用来区分正常和异常行为。当将给定的技术应用于特定领域时,这些假设可以用作评估该领域技术有效性的指南。对于每一个类别,我们都提供了一种基本的异常检测技术,然后展示了该类别中不同的现有技术是如何与基本技术不同的。该模板提供了对属于每个类别的技术的更简单、简洁的理解。此外,对于每个类别,我们确定了该类别中技术的优缺点。我们还讨论了这些技术的计算复杂性,因为这是实际应用领域中的一个重要问题。我们希望这项调查能够更好地了解关于这一主题的研究的不同方向,以及在一个领域开发的技术如何应用于它们原本不打算应用的领域
关键词:Anomaly Detection, Outlier Detection
1. 背景
(1)会议/刊物级别
Chandola V, Banerjee A, Kumar V. Anomaly detection: A survey[J]. ACM computing surveys (CSUR), 2009, 41(3): 1-58.
CCF None
(2)作者团队
Varun Chandola:纽约州立大学布法罗分校计算机科学系副教授
(3)研究背景
异常检测指的是在数据中发现不符合预期行为的模式的问题。在不同的应用领域中,这些不一致模式通常被称为异常、异常值、不一致观察、异常、畸变、意外、特殊性或污染物。其中,异常和异常值是异常检测中最常用的两个术语;
有时可以互换。异常检测广泛应用于各种各样的应用,如信用卡欺诈检测、保险或医疗保健、网络安全入侵检测、安全关键系统的故障检测,以及对敌方活动的军事监视。
异常检测的重要性在于,数据中的异常会转化为各种应用领域中重要的(通常是关键的)可操作信息。例如,计算机中的异常流量模式可能意味着被黑客攻击的计算机正在向未经授权的目的地发送敏感数据[Kumar 2005]。异常的MRI图像可能表明存在恶性肿瘤[Spence et al.2001]。信用卡交易数据的异常可能表明信用卡或身份盗窃[Aleskerov等人,1997年],或者航天器传感器的异常读数可能表明航天器的某些部件存在故障[Fujimaki等人,2005年]。
早在19世纪,统计界就对数据中的异常值或异常进行了研究[Edgeworth 1887]。随着时间的推移,各种异常检测技术已在多个研究社区得到发展。其中许多技术是专门为某些应用领域开发的,而其他技术则更为通用。
本综述试图对异常检测的研究提供一个结构化和全面的概述。我们希望,这有助于更好地理解在这一主题上进行研究的不同方向,以及在一个领域开发的技术如何应用于它们原本不打算开始的领域。
2. 异常检测定义
2.1什么是异常?
异常是数据中不符合正常行为定义的模式。图1显示了一个简单的二维数据集中的异常情况。
数据有两个正常区域,N1和N2,因为大多数观测位于这两个区域。距离区域足够远的点,例如点o1和o2,以及区域O3中的点,是异常。

由于各种原因,例如恶意活动,例如信用卡欺诈、网络入侵、恐怖活动或系统故障,数据中可能会出现异常情况,但所有这些原因都有一个共同特点,即分析人员感兴趣。异常的“趣味性”或现实生活中的相关性是异常检测的一个关键特征。
异常检测与噪声消除相关,但不同于噪声消除[Teng等人,1990]和噪音调节[Rousseeuw和Leroy 1987],这两家公司都达成了协议数据中有不必要的噪音。噪声可以被定义为数据中的一种现象,分析人员对其不感兴趣,但会妨碍数据分析。
噪声消除的驱动力是在对数据进行任何数据分析之前,需要去除不需要的对象。噪声调节指的是使统计模型估计不受异常观测的影响[Huber 1974]。
与异常检测相关的另一个主题是新颖性检测[Markou and Singh 2003a;2003b;Saunders and Gero 2000],其目的是检测数据中以前未观察到的(突发的、新颖的)模式,例如,新闻组中讨论的新主题。新模式和异常之间的区别在于,新模式通常在被检测到后被纳入正常模型。
应注意的是,上述相关问题的解决方案通常用于异常检测,反之亦然,因此本综述也将对此进行讨论。
2.2 挑战
在抽象层面上,异常被定义为不符合预期正常行为的模式。因此,一种简单的异常检测方法是定义一个代表正常行为的区域,并将数据中不属于该正常区域的任何观察结果声明为异常。但有几个因素使得这种看似简单的方法非常具有挑战性:
- 定义一个包含所有可能正常行为的正常区域是非常困难的。此外,正常行为和异常行为之间的界限通常并不精确。因此,靠近边界的异常观测实际上可能是正常的,反之亦然。
- 当异常是恶意行为的结果时,恶意对手通常会调整自己,使异常观察看起来像正常的,从而使定义正常行为的任务更加困难。
- 在许多领域中,正常行为不断演变,目前的正常行为概念在未来可能不具有足够的代表性。
- 对于不同的应用领域,异常的确切概念是不同的。例如,在医学领域,与正常值的微小偏差(例如体温波动)可能是异常,而股市领域的类似偏差(例如股票价值波动)可能被视为正常。因此,将一个领域开发的技术应用到另一个领域并不简单。
- 异常检测技术所用模型的培训/验证所需的标记数据的可用性通常是一个主要问题。
- 通常,数据包含的噪声往往与实际异常相似,因此难以区分和消除。
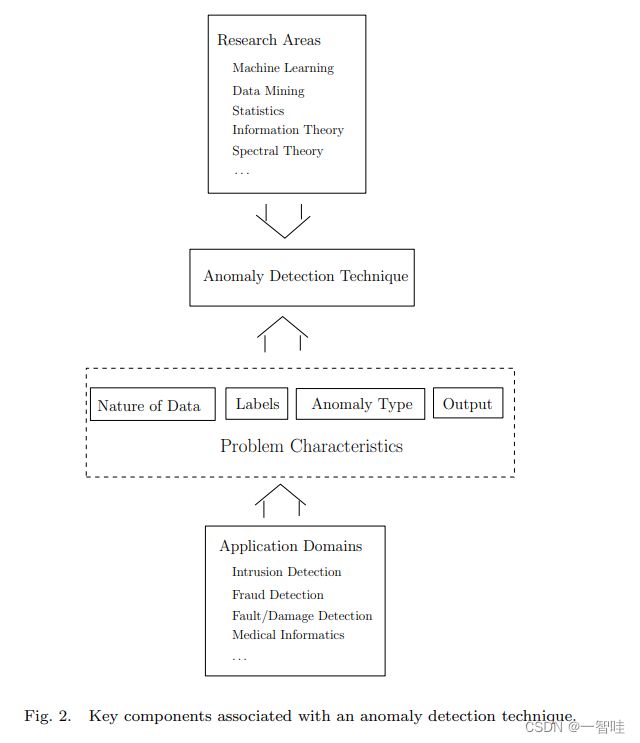
由于上述挑战,最普遍的异常检测问题并不容易解决。事实上,大多数现有的异常检测技术都解决了这一问题的具体表述。公式由各种因素引起,如数据的性质、标记数据的可用性、要检测的异常类型等。通常,这些因素由应用领域决定需要检测哪些异常。研究人员采纳了统计学、机器学习、数据挖掘、信息论、光谱理论等不同学科的概念,并将其应用于具体的问题公式。
图2显示了与任何异常检测技术相关的上述关键组件。
3.相关工作
异常检测一直是许多调查和评论文章以及书籍的主题。Hodge和Austin[2004]对机器学习和统计领域中开发的异常检测技术进行了广泛的调查。Agyemang等人[2006]对数字和符号数据的异常检测技术进行了广泛的回顾。Markou和Singh[2003a]以及Markou和Singh[2003b]分别对使用神经网络和统计方法的新颖性检测技术进行了广泛的回顾。Patca and Park[2007]和Snyder[2001]介绍了异常检测技术的专门用于网络入侵检测的概况。大量关于异常值检测的研究已经在统计学中完成,并在几本书[Rousseeuw and Leroy 1987;Barnett and Lewis 1994;Hawkins 1980]以及其他调查文章[Beckman and Cook 1983;Bakar et al.2006]中进行了审查。
表一显示了我们的调查和上述各种相关调查文章所涵盖的一系列技术和应用领域。

4.主要贡献
本综述试图对跨越多个研究领域和应用领域的异常检测技术的广泛研究提供一个结构化和广泛的概述。
现有的异常检测研究大多集中在特定的应用领域或单一的研究领域。[Agyemang et al.2006]和[Hodge and Austin 2004]是两个相关的工作,它们将异常检测分为多个类别,并在每个类别下讨论技术。这项调查以这两部作品为基础,从几个方面显著扩展了讨论。
我们又增加了两类异常检测技术,即:。,根据[Agyemang et al.2006]和[Hodge and Austin 2004]中讨论的四类信息理论和光谱技术。对于这六个类别中的每一个,我们不仅讨论了技术,还确定了关于该类别中技术产生的异常性质的独特假设。这些假设对于确定该类别中的技术何时能够检测到异常以及何时会失败至关重要。对于每一个类别,我们都提供了一种基本的异常检测技术,然后展示了该类别中不同的现有技术是如何与基本技术不同的。该模板提供了对属于每个类别的技术的更简单、简洁的理解。此外,对于每个类别,我们确定了该类别中技术的优缺点。我们还讨论了这些技术的计算复杂性,因为这是实际应用领域中的一个重要问题。
虽然一些现有调查提到了异常检测的不同应用,但我们详细讨论了使用异常检测技术的应用领域。对于每个领域,我们讨论异常的概念、异常检测问题的不同方面,以及异常检测技术面临的挑战。我们还提供了应用于每个应用领域的技术列表。
现有的调查讨论了异常检测技术,可以检测最简单的异常形式。我们区分了简单异常和复杂异常。对异常检测应用的讨论表明,对于大多数应用领域,有趣的异常本质上是复杂的,而大多数算法研究都集中在简单的异常上。
5.文章结构
本次调查分为三个部分,其结构如图2所示。在第2节中,我们确定了决定问题形成的各个方面,并强调了与异常检测相关的丰富性和复杂性。我们区分了简单异常和复杂异常,并定义了两种类型的复杂异常,即:。,背景和集体异常。在第3节中,我们简要描述了应用异常检测的不同应用领域。在接下来的章节中,我们将根据异常检测技术所属的研究领域对其进行分类。大多数技术可分为基于分类(第4节)、基于最近邻(第5节)、基于聚类(第6节)和统计技术(第7节)。有些技术属于信息论(第8节)和光谱理论(第9节)等研究领域。对于每一类技术,我们还讨论了它们在训练和测试阶段的计算复杂性。在第10节中,我们将讨论各种上下文异常检测技术。我们将在第11节讨论各种集体异常检测技术。我们在第12节中对各种现有技术的局限性和相对性能进行了一些讨论。第13节包含结束语。
6.异常检测问题的不同方面
本节确定并讨论异常检测的不同方面。如前所述,问题的具体表述取决于几个不同的因素,如输入数据的性质、标签的可用性(或不可用性)以及应用领域引起的约束和要求。本节介绍了问题领域的丰富性,并证明了对广泛异常检测技术的需要。
6.1 输入数据的属性
任何异常检测技术的一个关键方面是输入数据的性质。
输入通常是一组数据实例(也称为对象、记录、点、向量、模式、事件、案例、样本、观察、实体)[Tan等人,2005年,第2章]。每个数据实例都可以使用一组属性(也称为变量、特征、特征、字段、维度)来描述。属性可以是不同的类型,如二进制、分类或连续。每个数据实例可能只包含一个属性(单变量)或多个属性(多变量)。对于多变量数据实例,所有属性可能属于同一类型,也可能是不同数据类型的混合。
属性的性质决定了异常检测技术的适用性。例如,对于统计技术,必须对连续和分类数据使用不同的统计模型。类似地,对于基于最近邻的技术,属性的性质将决定要使用的距离度量。通常,实例之间的成对距离可能以距离(或相似性)矩阵的形式提供,而不是实际数据。在这种情况下,需要原始数据实例的技术不适用,例如许多基于统计和分类的技术。
输入数据也可以根据数据实例之间的关系进行分类[Tan等人,2005]。现有的大多数异常检测技术都处理记录数据(或点数据),其中假设数据实例之间没有关系。
通常,数据实例可以相互关联。例如序列数据、空间数据和图形数据。在序列数据中,数据实例是线性排序的,例如,时间序列数据、基因组序列、蛋白质序列。在空间数据中,每个数据实例与其相邻实例相关,例如,车辆交通数据、生态数据。当空间数据具有时间(顺序)成分时,它被称为时空数据,例如气候数据。在图形数据中,数据实例表示为图形中的顶点,并通过边连接到其他顶点。在本节后面,我们将讨论数据实例之间的这种关系与异常检测相关的情况。
6.2 异常类型
异常检测技术的一个重要方面是所需异常的性质。异常可分为以下三类:
(1)点异常
如果一个单独的数据实例相对于其他数据可以被视为异常,那么该实例被称为点异常。这是最简单的异常类型,也是大多数异常检测研究的重点。
例如,在图1中,点o1和o2以及区域O3中的点位于正常区域的边界之外,因此是点异常,因为它们与正常数据点不同。
作为一个真实的例子,请考虑信用卡欺诈检测。让数据集对应于个人的信用卡交易。为了简单起见,让我们假设数据仅使用一个特性定义:花费量。与该人员的正常支出范围相比,花费金额非常高的交易将是一个点异常。
(2)上下文异常
如果数据实例在特定上下文中异常(但不是其他情况),则称为上下文异常(也称为条件异常[Song et al.2007])。
上下文的概念是由数据集中的结构引起的,必须作为问题公式的一部分来指定。每个数据实例使用以下两组属性定义:
(1) 上下文属性。上下文属性用于确定该实例的上下文(或邻域)。例如,在空间数据集中,位置的经度和纬度是上下文属性。在timeseries数据中,时间是一个上下文属性,用于确定实例在整个序列中的位置。
(2) 行为属性。行为属性定义实例的非上下文特征。例如,在描述全世界平均降雨量的空间数据集中,任何位置的降雨量都是一个行为属性
异常行为是使用特定上下文中的行为属性值确定的。数据实例可能是给定上下文中的上下文异常,但相同的数据实例(就行为属性而言)在不同上下文中可能被视为正常。该属性是识别上下文异常检测技术的上下文和行为属性的关键。

时间序列数据[Weigend et al.1995;Salvador and Chan 2003]和空间数据[Kou et al.2006;
Shekhar等人,2001年]。图3显示了一个温度时间序列的例子,显示了过去几年一个地区的月温度。在那个地方的冬季(t1时间)温度为35华氏度可能是正常的,但在夏季(t2时间)相同的温度值可能是异常的。
类似的例子可以在信用卡欺诈检测领域找到。信用卡域中的上下文属性可以是购买时间。假设一个人的每周购物账单通常为100美元,但在圣诞节期间除外,当购物账单达到1000美元时。7月一周内新购买1000美元的物品将被视为背景异常,因为它不符合个人在时间背景下的正常行为(即使在圣诞节期间花费的相同金额将被视为正常)。
应用上下文异常检测技术的选择取决于上下文异常在目标应用领域中的意义。
另一个关键因素是上下文属性的可用性。在某些情况下,定义上下文很简单,因此应用上下文异常检测技术是有意义的。在其他情况下,定义上下文并不容易,因此很难应用此类技术。
(3)集体异常
如果相关数据实例的集合相对于整个数据集而言是异常的,则称为集体异常。集体异常中的单个数据实例本身可能不是异常,但它们作为一个集合一起出现是异常的。图4显示了一个显示人类心电图输出的示例[Goldberger等人,2000]。
突出显示的区域表示异常,因为相同的低值存在异常长时间(对应于房性早搏)。请注意,该低值本身并不是异常。

作为另一个示例,请考虑计算机中发生的一系列操作,如下所示:
. . . http web、缓冲区溢出、http web、http web、smtp邮件、ftp、http web、ssh、smtpmail、http web、ssh、缓冲区溢出、ftp、http web、ftp、smtp邮件、http web…
突出显示的事件序列(缓冲区溢出、ssh、ftp)对应于典型的远程计算机基于web的攻击,然后通过ftp将数据从主机复制到远程目标。应该注意的是,这些事件的集合是一个异常,但当单个事件发生在序列中的其他位置时,它们不是异常。
对层序数据的集体异常进行了探索[Forrest et al.1999;
Sun等人,2006年),图形数据[Noble and Cook 2003年],以及空间数据[Shekhar等人。
2001].
应该注意的是,尽管点异常可以发生在任何数据集中,但集体异常只能发生在数据实例相关的数据集中。相反,上下文异常的发生取决于数据中上下文属性的可用性。如果根据上下文进行分析,点异常或集体异常也可以是上下文异常。因此,通过结合上下文信息,可以将点异常检测问题或集合异常检测问题转化为上下文异常检测问题。
6.3 数据标签
与数据实例关联的标签表示该实例是正常还是异常1
.需要注意的是,获取准确且代表所有类型行为的标记数据通常成本高昂。
标记通常由人类专家手动完成,因此需要付出大量努力才能获得标记的训练数据集。通常,获取一组包含所有可能类型异常行为的标记异常数据实例比获取正常行为的标签更困难。此外,异常行为在本质上通常是动态的,例如,可能会出现新类型的异常,而没有标记的训练数据。在某些情况下,例如空中交通安全,异常情况会转化为灾难性事件,因此非常罕见。
根据标签的可用程度,异常检测技术可以在以下三种模式之一下运行:
(1)监督异常检测
在监督模式下训练的技术假设训练数据集的可用性,该数据集已标记正常和异常类的实例。在这种情况下,典型的方法是为正常和异常类别建立预测模型。任何看不见的数据实例都会与模型进行比较,以确定它属于哪个类。有监督的异常检测有两个主要问题。首先,与训练数据中的正常实例相比,异常实例要少得多。数据挖掘和机器学习文献[Joshi等人2001年;2002年;Chawla等人2004年;Phua等人。
2004; 韦斯和赫什,1998年;Villata和Ma,2002年)。其次,获得准确且具有代表性的标签,尤其是对于异常类别而言,通常是一项挑战。
已经提出了许多技术,在正常数据集中注入人工异常,以获得标记的训练数据集[Theiler and Cai 2003;Abe et al.2006;Steinwart et al.2005]。除了这两个问题之外,有监督的异常检测问题类似于建立预测模型。因此,我们不会在本次调查中讨论这类技术。
(2)半监督异常检测
在半监督模式下运行的技术,假设训练数据只标记了正常类的实例。由于它们不需要异常类的标签,因此比监督技术更适用。例如,在航天器故障检测[Fujimaki et al.2005]中,异常情况意味着发生了事故,这不容易建模。此类技术中使用的典型方法是为类建立一个与正常行为对应的模型,并使用该模型识别测试数据中的异常。
存在一组有限的异常检测技术,假设只有异常实例可用于培训[Dasgupta and Nino 2000;Dasgupta and Majumdar 2002;Forrest et al.1996]。这种技术并不常用,主要是因为很难获得涵盖数据中可能出现的所有异常行为的训练数据集。
(3)无监督异常检测
无监督异常检测。在无监督模式下运行的技术不需要训练数据,因此适用范围最广。这类技术隐含着一个假设,即测试数据中的正常情况远比异常情况更频繁。如果这一假设不成立,那么这种技术就会遭受高虚警率。
通过使用未标记数据集的样本作为训练数据,许多半监督技术可以适应在无监督模式下操作。这种适应性假设测试数据包含很少的异常,并且在训练期间学习的模型对这些异常具有鲁棒性。
6.4 异常检测的输出
任何异常检测技术的一个重要方面是异常报告的方式。通常,异常检测技术产生的输出是以下两种类型之一:
(1)分数
评分技术根据测试数据中每个实例被视为异常的程度,为每个实例分配一个异常评分。
因此,这些技术的输出是一个异常排列列表。分析员可以选择分析前几个异常,或者使用截止阈值来选择异常。
(2)标签
这类技术为每个测试实例指定一个标签(正常或异常)
基于评分的异常检测技术允许分析师使用特定于域的阈值来选择最相关的异常。为测试实例提供二进制标签的技术不直接允许分析员做出这样的选择,尽管这可以通过每种技术中的参数选择间接控制。
7. 异常检测的应用领域
在本节中,我们将讨论异常检测的几个应用。对于每个应用领域,我们讨论以下四个方面:
-异常的概念。
-数据的性质。
-与检测异常相关的挑战。
-现有的异常检测技术。
7.1 入侵检测
入侵检测是指检测计算机相关系统中的恶意活动(入侵、渗透和其他形式的计算机滥用)[Phoha 2002]。从计算机安全的角度来看,这些恶意活动或入侵很有趣。入侵行为不同于系统的正常行为,因此异常检测技术适用于入侵检测领域。
在这个领域中,异常检测的关键挑战是巨大的数据量。异常检测技术需要在计算上高效地处理这些大尺寸输入。此外,数据通常以流式方式出现,因此需要在线分析。另一个因输入量大而产生的问题是误报率。由于数据量相当于数百万个数据对象,因此,对于分析师来说,只有百分之几的假警报会让分析变得难以承受。与正常行为对应的标签数据通常可用,而入侵的标签则不可用。因此,半监督和非监督异常检测技术是该领域的首选技术。
Denning[1987]将入侵检测系统分为基于主机的入侵检测系统和基于网络的入侵检测系统。
(1)基于主机的入侵检测系统
此类系统(也称为系统调用入侵检测系统)处理操作系统调用跟踪。
侵入体以痕迹的异常子序列(集体异常)的形式存在。异常的子序列转化为恶意程序、未经授权的行为和违反政策。虽然所有记录道都包含属于同一字母表的事件,但事件的同时发生是区分正常和异常行为的关键因素。
数据本质上是连续的,字母表由单独的系统调用组成,如图5所示。这些调用可以由程序[Hofmeyr等人1998]或用户[Lane and Brodley 1999]生成。字母表通常很大(183个系统调用SunOS 4.1x操作系统)。不同的程序以不同的顺序执行这些系统调用。每个程序的序列长度各不相同。图5展示了一组操作系统调用序列示例。该领域数据的一个关键特征是,数据通常可以在不同的级别进行分析,例如程序级别或用户级别。异常检测技术应用于基于主机的入侵检测需要处理数据的连续性。此外,点异常检测技术不适用于该领域。这些技术要么对序列数据建模,要么计算序列之间的相似性。Snyder[2001]介绍了用于解决该问题的不同技术。Forrest等人[1996]和Dasgupta等人对基于主机的入侵检测的异常检测进行了比较评估。
(2)基于网络的入侵检测系统
这些系统负责检测网络数据中的入侵。侵入通常以异常模式(点异常)出现,尽管某些技术以顺序方式对数据建模,并检测异常子序列(集体异常)[Gwadera等人,2005b;
2004]. 这些异常现象的主要原因是外部黑客发起的攻击,他们希望获得未经授权的网络访问权,以窃取信息或扰乱网络。一个典型的设置是一个通过互联网连接到世界其他地方的大型计算机网络。入侵检测系统可用的数据可以具有不同的粒度级别,例如数据包级别的跟踪、CISCO网络流数据等。数据具有与之相关联的时间方面,但大多数技术通常不明确处理顺序方面。高维数据与高维属性的混合也是典型的。
异常检测技术在该领域面临的一个挑战是,随着入侵者调整其网络攻击以逃避现有的入侵检测解决方案,异常的性质会随着时间的推移而不断变化。
该领域使用的一些异常检测技术如表三所示。
7.2 欺诈检测
欺诈检测是指检测银行、信用卡公司、保险机构、手机公司、股市等商业组织中发生的犯罪活动。恶意用户可能是该组织的实际客户,也可能伪装成客户(也称为身份盗窃)。
当这些用户以未经授权的方式消耗组织提供的资源时,就会发生欺诈。这些组织有兴趣立即发现此类欺诈行为,以防止经济损失。
Fawcett和Provost[1999]引入了“活动监控”这一术语,作为这些领域欺诈检测的一般方法。异常的典型方法。
(1)信用卡欺诈检测
在这个领域,异常检测技术被应用于检测欺诈性信用卡申请或欺诈性信用卡使用(与信用卡盗窃相关)。检测欺诈性信用卡申请类似于检测保险欺诈[Ghosh和Reilly 1994]。
数据通常由多个维度定义的记录组成,如用户ID、花费的金额、连续使用卡之间的时间等。欺诈通常反映在交易记录(点异常)中,并对应于高付款、购买用户以前从未购买过的物品、高购买率、,信贷公司有完整的可用数据,也有标记记录。此外,根据信用卡用户的不同,数据分为不同的类型。因此,基于分析和聚类的技术通常用于该领域。
与检测未经授权的信用卡使用相关的挑战是,一旦欺诈交易发生,就需要在线检测欺诈行为。
为了解决这个问题,异常检测技术有两种不同的应用方式。第一种是“按所有者”模式,根据每个信用卡用户的信用卡使用历史记录对其进行分析。任何新事务都会与用户的配置文件进行比较,如果与配置文件不匹配,则标记为异常。这种方法通常很昂贵,因为每次用户进行交易时,它都需要查询中央数据存储库。另一种被称为by operation的方法是从特定地理位置发生的交易中检测异常。通过用户和操作技术检测上下文异常。在第一种情况下,上下文是用户,而在第二种情况下,上下文是地理位置。
表四列出了该领域中使用的一些异常检测技术。
(2)手机欺诈检测
(3)保险索赔欺诈检测
(4)内幕交易侦查
7.3 医疗和公共卫生异常检测
7.4 工业损伤检测
7.5 图像处理
7.6 文本数据中的异常检测
该领域的异常检测技术主要检测文档或新闻文章集合中的新主题、事件或新闻故事。异常是由于一个新的有趣的事件或异常的话题引起的。
这个领域的数据通常是高维的,非常稀疏。由于文档是随时间收集的,因此数据也具有时间方面的特征。
异常检测技术在该领域面临的一个挑战是如何处理属于一个类别或主题的文档中的巨大变化。
表XI列出了该领域中使用的一些异常检测技术.
7.7 传感器网络
7.8 其他领域
异常检测还应用于其他几个领域,如语音识别[Albrecht等人2000;Emamian等人2000],机器人行为中的新奇性检测[Crook and Hayes 2001;Crook等人2002;Marsland等人1999;2000b;
2000a],交通监控[Shekhar等人,2001],点击保护[Ihler等人。
检测web应用程序中的错误[Ide和鹿岛2004;Sun等人2005],检测生物数据中的异常[Kadota等人2003;Sun等人2006;Gwadera等人2005a;MacDonald和Ghosh 2007;Tomlins等人2005;Tibshirani和Hastie 2007],检测人口普查数据中的异常[Lu等人2003],检测犯罪活动之间的关联[Lin和Brown 2003],检测客户关系管理(CRM)数据中的异常[He等人2004年b],检测天文数据中的异常[Dutta等人2007年;Escalante 2005年;Protopaps等人2006年]和检测生态系统干扰[Blender等人1997年;Kou等人2006年;Sun和Chawla 2004年]。
8.基于分类的异常检测技术
基于分类的异常检测技术在以下一般假设下运行:
假设:可以在给定的特征空间中学习一个能够区分正常类和异常类的分类器。
根据训练阶段可用的标签,基于分类的异常检测技术可分为两大类:多类和单类异常检测技术。
基于多类分类的异常检测技术假设训练数据包含属于多个正常类的标记实例[Stefano等人,2000年;Barbara等人,2001b]。这种异常检测技术学习一个分类器来区分每个正常类和其他类。
参见图6(a)中的说明。如果测试实例未被任何分类器归类为正常,则该测试实例被视为异常。该子类别中的一些技术将置信度评分与分类器所做的预测相关联。如果没有一个分类器确信将测试实例分类为正常,则该实例被声明为异常。
基于一类分类的异常检测技术假设所有训练实例只有一个类标签。这类技术使用一类分类算法,例如一类支持向量机[Sch¨olkopf et al.2001],一类核Fisher判别式[Roth 2004;2006],学习正常实例周围的判别边界,如图6(b)所示。任何不在学习范围内的测试实例均被宣布为异常。

在以下小节中,我们将讨论使用不同分类算法构建分类器的各种异常检测技术:
8.1 基于神经网络
神经网络已被应用于多类和单类环境下的异常检测。
使用神经网络的基本多类异常检测技术分两步操作。首先,在正常训练数据上训练神经网络,以学习不同的正常类别。其次,每个测试实例都作为神经网络的输入。如果网络接受测试输入,则为正常,如果网络拒绝测试输入,则为异常[Stefano et al.2000;Odin and Addison 2000]。已经提出了几种使用不同类型神经网络的基本神经网络技术变体,如表XIII所示。
复制子神经网络已用于一类异常检测[Hawkins等人,2002年;Williams等人,2002年]。构造了一个多层前馈神经网络,该网络具有相同数量的输入和输出神经元(对应于数据中的特征)。培训包括将数据压缩为三个隐藏层。测试阶段涉及使用学习的网络重构每个数据实例xi,以获得重构的输出oi
.然后,将测试实例xi的重建误差δi计算为:
8.2 基于贝叶斯网络
贝叶斯网络已被用于多类环境下的异常检测。
使用naıve Bayes网络对单变量分类数据集进行的一项基本技术估计了观察类别标签(从一个集合中)的后验概率给出了一个测试数据实例。
选择后验值最大的类标签作为给定测试实例的预测类。根据训练数据集估计观察给定类的测试实例的可能性,以及类概率的先验值。零概率,特别是对于异常类,使用拉普拉斯平滑法进行平滑。
通过聚合每个测试实例的每个属性后验概率,并使用聚合值为测试实例分配类标签,可以将基本技术推广到多变量分类数据集。
针对网络入侵检测,已经提出了几种基本技术的变体[Barbara et al.2001b;Sebyala et al.2002;Valdes and Skinner 2000;
明明2000;Bronstein等人,2001),用于视频监控中的新颖性检测[Diehl and Hampshire 2002],用于文本数据中的异常检测[Baker等人,1999],以及用于疾病暴发检测[Wong等人,2002;2003]。
上述基本技术假设不同属性之间是独立的。已经提出了几种基本技术的变体,使用更复杂的贝叶斯网络来捕获不同属性之间的条件依赖关系[Siaterlis and Maglaris 2004;Janakiram et al.2006;
达斯和施耐德2007]
8.3 基于支持向量机
支持向量机(SVM)[Vapnik 1995]已应用于单类环境中的异常检测。此类技术使用SVM的一类学习技术[Ratsch等人,2002年],并学习包含训练数据实例的区域(边界)。核函数,如径向基函数(RBF)核,可以用来学习复杂的区域。对于每个测试实例,基本技术确定测试实例是否在学习的区域内。如果一个测试实例在学习的区域内,则将其声明为正常,否则将其声明为异常。
已针对音频信号数据中的异常检测[Davy and Godsill 2002]、发电厂中的新颖性检测[King等人,2002]和系统调用入侵检测[Eskin等人,2002;
Heller等人,2003年;Lazarevic等人,2003年]。基本技术也被扩展到检测时间序列中的异常[Ma和Perkins 2003a;2003b]。
基本技术的一种变体[Tax和Duin 1999a;1999b;Tax 2001]在内核空间中找到包含所有训练实例的最小超球体,然后确定测试实例位于该超球体的哪一侧。如果一个测试实例位于超球体之外,它将被声明为异常。
Song等人[2002]使用鲁棒支持向量机(RSVM),它对训练数据中存在的异常具有鲁棒性。RSVM已被应用于系统调用入侵检测[Hu等人,2003]。
8.4 基于规则
基于规则的异常检测技术学习捕获系统正常行为的规则。任何此类规则均未涵盖的测试实例被视为异常。基于规则的技术已经应用于多类和单类设置中。
基本的基于多类规则的技术包括两个步骤。第一步是使用规则学习算法(如RIPPER、决策树等)从训练数据中学习规则。每个规则都有一个相关的置信值,该置信值与规则正确分类的训练实例数与规则覆盖的训练实例总数之间的比率成正比。第二步是为每个测试实例找到最能捕获测试实例的规则。与最佳规则相关的置信度的倒数是测试实例的异常分数。已经提出了基本的基于规则的技术的几个小变体[Fan等人,2001年;Helmer等人,1998年;Lee等人,1997年;Salvador and Chan,2003年;Teng等人,1990年]。
1995年,一个无监督的数据挖掘类[SRIKAL]使用了关联规则来生成异常。
关联规则是从分类数据集生成的。为了确保规则对应于强模式,使用支持度阈值来修剪低支持度的规则[Tan等人,2005]。基于关联规则挖掘的技术已被用于网络入侵检测[Mahoney and Chan 2002;2003;Mahoney et al.2003;Tandon and Chan 2007;Barbara et al.2001a;Otey et al.2003],系统呼叫入侵检测[Lee et al.2000;Lee and Stolfo 1998;Qin and Hwang 2004],信用卡欺诈检测[Brause et al.1999],以及航天器内部管理数据中的欺诈检测[Yairi等人,2001年]。频繁项集是在关联规则挖掘算法的中间步骤生成的。他等人[2004a]提出了一种针对分类数据集的异常检测算法,其中测试实例的异常分数等于它出现在其中的频繁项集的数量。
计算复杂度:
基于分类的技术的计算复杂性取决于所使用的分类算法。有关训练分类器的复杂性的讨论,请参见Kearns[1990]。一般来说,训练决策树的速度更快,而涉及二次优化的技术(如支持向量机)的成本更高,尽管已经提出了具有线性训练时间的线性时间支持向量机[Joachims 2006]。分类技术的测试阶段通常非常快,因为测试阶段使用学习的模型进行分类。
基于分类的技术的优点和缺点基于分类的技术的优点如下:
(1) 基于分类的技术,尤其是多类技术,可以利用强大的算法来区分属于不同类的实例。
(2) 基于分类的技术的测试阶段很快,因为每个测试实例都需要与预先计算的模型进行比较。
基于分类的技术的缺点如下:
(1) 基于多类别分类的技术依赖于各种正常类别的准确标签的可用性,这通常是不可能的。
(2) 基于分类的技术为每个测试实例分配一个标签,当需要测试实例有意义的异常评分时,这也可能成为一个缺点。一些获得概率分布的分类技术
9. 基于最近邻的异常检测技术
最近邻分析的概念已被用于几种异常检测技术中。这些技术基于以下关键假设:
假设:正常数据实例发生在密集的社区,而异常则发生在距离最近的社区很远的地方。
基于最近邻的异常检测技术需要在两个数据实例之间定义距离或相似性度量。两个数据实例之间的距离(或相似性)可以用不同的方式计算。对于连续属性,欧几里德距离是一种流行的选择,但也可以使用其他度量方法[Tan等人。
2005年,第2章]。对于分类属性,通常使用简单的匹配系数,但可以使用更复杂的距离度量[Boriah et al.2008;Chandola et al.2008]。对于多变量数据实例,通常计算每个属性的距离或相似性,然后进行组合[Tan等人,2005年,第2章]。
本节将讨论的大多数技术,以及基于聚类的技术(第6节),都不要求距离度量是严格度量的。度量通常要求是正定的和对称的,但不要求它们满足三角形不等式。
基于最近邻的异常检测技术可以大致分为两类:
(1) 使用数据实例到其第k个最近邻居的距离作为异常分数的技术。
(2) 计算每个数据实例的相对密度以计算其异常分数的技术。
此外,还有一些技术以不同的方式使用数据实例之间的距离来检测异常,稍后将简要讨论。
9.1 使用第k个最近邻的距离
一种基本的最近邻异常检测技术基于以下定义——数据实例的异常分数定义为其到给定数据集中第k个最近邻的距离。这项基本技术已被应用于从卫星地面图像中探测地雷[Byers and Raftery 1998],并探测大型同步涡轮发电机直流磁场绕组中的短路匝数(异常)[Guttormsson等人,1999]。在后一篇论文中,作者使用k=1。通常,然后对异常评分应用阈值,以确定测试实例是否异常。另一方面,Ramaswamy等人[2000]选择异常得分最大的n个实例作为异常。
研究人员以三种不同的方式扩展了这项基本技术。第一组变量修改上述定义,以获得数据实例的异常评分。第二组变量使用不同的距离/相似性度量来处理不同的数据类型。第三组变体侧重于以不同的方式提高基本技术的效率(基本技术的复杂性为O(N2),其中N是数据大小).
9.2 使用相对密度
基于密度的异常检测技术估计每个数据实例的邻域密度。位于低密度邻域中的实例被声明为异常,而位于高密度邻域中的实例被声明为正常。
对于给定的数据实例,到其第k个最近邻的距离相当于以给定数据实例为中心的超球体的半径,该超球体包含k个其他实例。因此,给定数据实例到第k个最近邻的距离可被视为数据集中实例密度的倒数估计,且前一小节中描述的基于最近邻的基本技术可被视为基于密度的异常检测技术。
如果数据具有不同密度的区域,则基于密度的技术表现不佳。例如,考虑图7所示的二维数据集。由于集群C1的密度较低,很明显,对于集群C1内的每个实例q,实例q与其最近邻居之间的距离大于实例p2与集群C2最近邻居之间的距离,并且实例p2不会被视为异常。因此,基本技术将无法区分p2和C1中的实例。然而,可以检测到实例p1。
基于最近邻的技术的优点和缺点基于最近邻的技术的优点如下:
(1) 基于最近邻的技术的一个关键优势是,它们本质上是无监督的,并且不会对数据的生成分布做出任何假设。相反,它们纯粹是数据驱动的。
(2) 在遗漏异常方面,半监督技术比无监督技术表现更好,因为异常在训练数据集中形成紧密邻域的可能性非常低。
(3) 使基于最近邻的技术适应不同的数据类型很简单,主要需要为给定数据定义适当的距离度量。
基于最近邻的技术的缺点如下:
(1) 对于无监督技术,如果数据具有不受监督的正常实例如果数据有足够多的近邻,或者如果数据有足够多的近邻,则该技术无法正确标记它们,从而导致遗漏异常。
(2) 对于半监督技术,如果测试数据中的正常实例在训练数据中没有足够多的相似正常实例,则此类技术的假阳性率较高。
(3) 测试阶段的计算复杂性也是一个重大挑战,因为它涉及计算每个测试实例与所有属于测试数据本身或训练数据的实例之间的距离,以计算最近邻。
(4) 基于最近邻的技术的性能在很大程度上依赖于一对数据实例之间定义的距离度量,该度量可以有效区分正常和异常实例。当数据复杂时,定义实例之间的距离度量可能很有挑战性,例如图形、序列等。
10.基于聚类的异常检测技术
聚类[Jain and Dubes 1988;Tan et al.2005]用于将相似的数据实例分组到集群中。聚类主要是一种无监督的技术,尽管最近也在探索半监督聚类[Basu et al.2004]。尽管聚类和异常检测似乎有着本质上的不同,但已经开发了几种基于聚类的异常检测技术。基于聚类的异常检测技术可以分为三类。
第一类基于聚类的技术基于以下假设:
假设:正常数据实例属于数据中的一个集群,而异常则不属于任何集群。
基于上述假设的技术将已知的基于聚类的算法应用于数据集,并将不属于任何集群的任何数据实例声明为异常。可以使用几种不强制每个数据实例属于一个集群的聚类算法,例如DBSCAN[Ester等人1996]、ROCK[Guha等人2000]和SNN聚类[Ert¨oz等人2003]。FindOut算法[Yu et al.2002]是WaveCluster算法[Sheikholeslami et al.1998]的扩展,在该算法中,检测到的簇从数据中移除,剩余实例被宣布为异常。
这种技术的一个缺点是,它们没有优化以发现异常,因为底层聚类算法的主要目的是找到聚类。
第二类基于聚类的技术依赖于以下假设:
假设:正常数据实例位于其最近的聚类中心附近,而异常情况则远离其最近的聚类中心。
基于上述假设的技术包括两个步骤。在第一步中,使用聚类算法对数据进行聚类。在第二步中,对于每个数据实例,计算其到最近簇质心的距离作为其异常分数。
使用不同的聚类算法,已经提出了许多遵循这两步方法的异常检测技术。Smith等人[2002]研究了自组织映射(SOM)、K-均值聚类和期望最大化(EM)对训练数据进行聚类,然后使用聚类对测试数据进行分类。特别是,SOM[Kohonen 1997]已广泛用于在几个应用中以半监督模式检测异常,如入侵检测[Labib and Vemuri 2002;Smith et al.2002;Ramadas et al.2003]、故障检测[Harris 1993;Ypma and Duin 1998;Emamian et al.2000]和欺诈检测[Brockett et al.1998]。Barbara等人[2003]提出了一种对训练数据中的异常具有鲁棒性的技术。作者首先使用频繁项集挖掘将训练数据中的正常实例与异常分离,然后使用基于聚类的技术检测异常。还提出了几种处理序列数据的技术[Blender等人,1997年;Bejerano和Yona,2001年;Vinueza和Grudic,2004年;Budalakoti等人,2006年]。
基于聚类的技术的优点和缺点基于聚类的技术的优点如下:
(1) 基于无监督聚类的技术可以在无监督模式下运行。
(2) 这种技术通常可以通过简单地插入能够处理特定数据类型的聚类算法来适应其他复杂的数据类型。
(3) 基于集群的技术的测试阶段很快,因为每个测试实例需要与之进行比较的集群数量是一个小常数。
基于聚类的技术的缺点如下:
(1) 基于聚类的技术的性能在很大程度上取决于聚类算法捕获正常实例的聚类结构的有效性。
(2) 许多技术将异常检测作为聚类的副产品,因此没有针对异常检测进行优化。
(3) 有几种聚类算法强制将每个实例分配给某个集群。
这可能会导致异常被分配到一个大的集群,从而通过在假设异常不属于任何集群的情况下运行的技术被视为正常实例。
(4) 一些基于聚类的技术只有在异常之间没有形成显著的聚类时才有效。
(5) 对数据进行聚类的计算复杂度通常是一个瓶颈,尤其是在使用O(N2d)聚类算法的情况下。
11. 统计异常检测技术
任何统计异常检测技术的基本原理都是:“异常是一种被怀疑部分或完全无关的观察,因为它不是由假设的随机模型生成的”[Anscombe和Guttman,1960年]。统计异常检测技术基于以下关键假设:
假设:正常数据实例发生在随机模型的高概率区域,而异常发生在随机模型的低概率区域。
统计技术将一个统计模型(通常用于正常行为)与给定数据相匹配,然后应用统计推断测试来确定一个看不见的实例是否属于该模型。根据应用的测试统计数据,从学习的模型生成概率较低的实例被宣布为异常。参数技术和非参数技术都被用于拟合统计模型。虽然参数化技术假定了解基础分布,并根据给定数据估计参数[Eskin 2000],但非参数化技术通常不假定了解基础分布[Desferges等人,1998]。在接下来的两小节中,我们将讨论参数和非参数异常检测技术。
11.1 参数化技术
如前所述,参数技术假设正态数据由参数Θ和概率密度函数f(x,Θ)的参数分布生成,其中x是观测值。测试实例(或观察)的异常分数x是概率密度函数f(x,Θ)的倒数。参数Θ根据给定的数据进行估计。
或者,可以使用统计假设检验(在统计异常检测文献[Barnett and Lewis 1994]中也称为不一致性检验)。此类测试的零假设(H0)是使用估计分布(带参数Θ)生成数据实例x。如果统计测试拒绝H0,则宣布x为异常。统计假设检验与检验统计量相关联,检验统计量可用于获得数据实例x的概率异常分数。
根据假设的分布类型,参数化技术可进一步分类如下:
(1)基于高斯模型
这种技术假设数据是由高斯分布生成的。使用最大似然估计(MLE)估计参数。数据实例到估计平均值的距离就是该实例的异常分数。对异常分数应用阈值来确定异常。这一类别中的不同技术以不同的方式计算到平均值和阈值的距离。
在过程质量控制领域[Shewhart 1931]中经常使用的一种简单的异常值检测技术是,声明距离分布平均值µ3σ以上的所有数据实例,其中σ是分布的标准偏差。
µ±3σ区域包含99.7%的数据实例。
如[Barnett and Lewis 1994;Barnett 1976;Beckman and Cook 1983]所述,更复杂的统计测试也被用于检测异常。我们将在这里描述一些测试。
方框图规则(图9)是最简单的统计技术,已被用于检测医学领域数据[Laurikkala等人2000年;Horn等人2001年;Solberg和Lahti 2005年]和涡轮机转子数据[Guttomsson等人1999年]中的单变量和多变量异常。方框图用汇总属性(如最小非异常观测值(min)、下四分位(Q1)、中位数、上四分位(Q3)和最大非异常观测值(max)以图形方式描述数据。
数量Q3−Q1被称为四分位间距(IQR)。方框图还显示了超出范围的任何观察都将被视为异常。大于1.5的数据实例∗ IQR低于Q1或1.5∗ IQR高于Q3被宣布为异常。Q1和Q1之间的区域− 1.5IQR和Q3+1.5IQR包含99.3%的观测值,因此选择1.5IQR边界使得箱图规则相当于高斯数据的3σ技术。
(2)基于回归模型
对于时间序列数据,使用回归进行异常检测已经得到了广泛的研究[Abraham and Chuang 1989;Abraham and Box 1979;Fox 1972]。
基于基本回归模型的异常检测技术包括两个步骤。第一步,在数据上拟合回归模型。在第二步中,对于每个测试实例,使用测试实例的残差来确定异常评分。
残差是实例中回归模型无法解释的部分。残差的大小可以用作测试实例的异常分数,尽管已经提出了统计测试来确定具有一定置信度的异常[Anscombe和Guttman 1960;Beckman和Cook 1983;Hawkins 1980;Torr和Murray 1993]。某些技术通过分析模型拟合过程中的赤池信息含量(AIC)来检测数据集中是否存在异常[Kitagawa 1979;Kadota et al.2003]。
训练数据中出现异常会影响回归参数,因此回归模型可能无法产生准确的结果。在拟合回归模型时处理此类异常的一种流行技术称为稳健回归[Rousseeuw and Leroy 1987](在适应异常的同时估计回归参数)。作者认为,稳健回归技术不仅可以隐藏异常,还可以检测异常,因为异常往往具有更大的稳健拟合残差。自回归综合移动平均(ARIMA)模型中也采用了类似的稳健异常检测方法[Bianco等人,2001年;Chen等人,2005年]。
基于基本回归模型的技术已经被提出用于处理多元时间序列数据。Tsay等人[2000]讨论了多元时间序列相对于单变量时间序列的额外复杂性,并提出了可用于检测多元ARIMA模型异常的统计数据。
这是Fox[1972]早些时候提出的统计数据的概括。
(3)基于遗传算法的混合参数分布
这类技术混合使用参数统计分布来建模数据。这类技术可分为两个子类。第一类技术将正态实例和异常建模为单独的参数分布,而第二类技术仅将正态实例建模为参数分布的混合。
对于第一个子类技术,测试阶段涉及确定测试实例属于哪个正态分布或异常分布。Abraham和Box[1979]假设正态数据由高斯分布(N(0,σ)生成
异常也由均值相同但方差较大的高斯分布产生,N(0,k2σ)
2 ). 测试实例在两种分布上都使用Grubb测试进行测试,并相应地标记为正常或异常。[Lauer 2001;Eskin 2000;
亚伯拉罕和博克斯1979;1968年,包厢和条;阿加瓦尔[2005]。Eskin[2000]使用期望最大化(EM)算法为这两类开发了混合模型,假设每个数据点都是先验概率为λ的异常.
11.2 非参数化技术
这一类中的异常检测技术使用非参数统计模型,因此模型结构不是由prioiri定义的,而是由给定数据确定的。与参数化技术相比,此类技术通常对数据做出较少的假设,例如密度的平滑度。
(1)基于直方图
最简单的非参数统计技术是使用直方图来保持正常数据的轮廓。这种技术也被称为基于频率或基于计数。基于直方图的技术在入侵检测领域尤其流行[Eskin 2000;Eskin et al。
2001; Denning 1987]和欺诈检测[Fawcett和Provost 1999],因为数据的行为受某些配置文件(用户、软件或系统)的控制,这些配置文件可以使用直方图模型有效捕获。
基于直方图的单变量数据异常检测技术包括两个步骤。第一步是根据训练数据中该特征的不同值构建直方图。在第二步中,该技术检查测试实例是否落在直方图的任何一个容器中。如果是,则测试实例是正常的,否则是异常的。基于直方图的基本技术的一种变体是,根据每个测试实例落下的箱子的高度(频率),为每个测试实例分配一个异常分数。
(2)基于核函数
概率密度估计的非参数技术是parzen窗口估计[parzen 1962]。这涉及到使用核函数来近似实际密度。基于核函数的异常检测技术类似于前面描述的参数化方法。唯一的区别是使用的密度估计技术。Desferges等人[1998]提出了一种半监督统计技术来检测异常,该技术使用核函数来估计正常情况下的概率分布函数(pdf)。本pdf低概率区域的一个新实例被宣布为异常。
统计技术的优点和缺点统计技术的优点是:
(1) 如果有关基础数据分布的假设成立,统计技术为异常检测提供了一个统计上合理的解决方案。
(2) 统计技术提供的异常分数与置信区间相关联,该置信区间可作为有关任何测试实例的决策时的附加信息。
(3) 如果分布估计步骤对数据中的异常具有鲁棒性,则统计技术可以在无监督的环境中运行,而无需任何标记的训练数据。
统计技术的缺点是:
(1) 统计技术的主要缺点是,它们依赖于数据来自特定分布的假设。这种假设通常不成立,尤其是对于高维真实数据集。
(2) 即使统计假设是合理的,也有几种假设检验统计数据可用于检测异常;选择最好的统计数据通常不是一项简单的任务[Motulsky 1995]。特别是,为拟合高维数据集所需的复杂分布构造假设检验非常重要。
(3) 基于直方图的技术实现起来相对简单,但这种用于多元数据的技术的一个关键缺点是,它们无法捕获不同属性之间的交互。异常可能具有单独非常频繁的属性值,但它们的组合非常罕见,但基于属性的直方图技术无法检测此类异常。
12. 信息论异常检测技术
信息论技术使用不同的信息论度量(如Kolomogorov复杂性、熵、相对熵等)分析数据集的信息内容。此类技术基于以下关键假设:
假设:数据中的异常会导致数据集的信息内容不规则。
让C(D)表示给定数据集的复杂性,D。基本的信息论技术可以描述如下。给定一个数据集D,求实例的最小子集I,这样C(D)−C(D)−一) 是最大值。由此获得的子集中的所有实例都被视为异常。这个基本技术解决的问题是找到一个帕累托最优解,它没有一个最优解,因为有两个不同的目标需要优化。
在上述技术中,数据集(C)的复杂性可以用不同的方式来测量。Kolomogorov复杂性[Li和Vitanyi 1993]已经被几种技术所使用[Arning等人1996年;Keogh等人2004年]。阿宁等人。
[1996]使用正则表达式的大小来测量异常检测数据(以字符串表示)的Kolomogorov复杂性。Keogh等人[2004]使用压缩数据文件的大小(使用任何标准压缩算法)来衡量数据集的Kolomogorov复杂性。其他信息论指标,如熵、相对不确定性等,也被用来衡量分类数据集的复杂性[Lee and Xiang 2001;He et al.2005;He et al.2006;Ando 2007]。
上述基本技术涉及双重优化,以最小化子集大小,同时最大限度地降低数据集的复杂性。
因此,考虑数据集的每个可能子集的穷举方法将以指数时间运行。已经提出了几种方法来近似搜索最不规则的子集。He等人[2006]使用一种称为局部搜索算法(LSA)的近似算法[He等人2005]以线性方式近似确定此类子集,使用熵作为复杂性度量。[Ando 2007]提出了一种使用信息瓶颈度量的类似技术。
信息论技术也被用于数据集,其中数据实例自然有序,例如序列数据、空间数据。在这种情况下,数据被分解成子结构(序列的段、图的子图等),异常检测技术发现子结构I,这样C(D)− C(D)− 一) 是最大值。该技术已应用于序列[Lin等人2005;Chakrabarti等人1998;Arning等人1996]、图形数据[Noble and Cook 2003]和空间数据[Lin and Brown 2003]。这种技术的一个关键挑战是找到能够探测异常的子结构的最佳尺寸。
信息论技术的优点和缺点信息论技术的优点如下:
(1) 它们可以在无人监督的环境下运行。
(2) 他们没有对数据的基本统计分布做出任何假设。
信息论技术的缺点如下:
(1) 这些技术的性能在很大程度上取决于信息论度量的选择。通常,只有当数据中存在大量异常时,此类测量才能检测到异常的存在。
(2) 应用于序列和空间数据集的信息论技术依赖于子结构的大小,而子结构的大小通常不容易获得。
(3) 使用信息论技术很难将异常分数与测试实例关联起来。
13. 光谱异常检测技术
光谱技术试图通过组合属性来获取数据中的大部分可变性,从而找到数据的近似值。这些技术基于以下关键假设:
假设:数据可以嵌入到一个低维子空间中,在该子空间中,正常情况和异常情况出现显著不同。
因此,光谱异常检测技术采用的一般方法是确定这样的子空间(嵌入、投影等),在这些子空间中,异常实例可以很容易地识别[Agovic等人,2007]。这种技术可以在无监督和半监督的环境中工作。
有几种技术使用主成分分析(PCA)[Jolliffe 2002]将数据投影到低维空间。一种这样的技术[Parra等人。
1996]以低方差分析每个数据实例沿主成分的投影。满足数据相关性结构的正常实例的预测值较低,而偏离相关性结构的异常实例的预测值较大。Dutta等人[2007]采用这种方法来检测天文学目录中的异常。
Ide和Kashima[2004]提出了一种光谱技术来检测时间序列图中的异常。每个图都表示为给定时间的邻接矩阵。在每个时间实例中,选择矩阵的主成分作为给定图形的活动向量。将活动向量的时间序列视为一个矩阵,得到主左奇异向量,以捕捉数据中随时间变化的正态依赖关系。对于一个新的(测试)图,计算其活动向量和从之前的图中获得的主左奇异向量之间的角度,并用于确定测试图的异常分数。在类似的方法中,Sun等人[2007]提出了一种针对一系列图的异常检测技术,方法是对每个图的邻接矩阵进行紧矩阵分解(CMD),从而获得原始矩阵的近似值。对于序列中的每个图,作者执行CMD并计算原始邻接矩阵和近似矩阵之间的近似误差。作者构造了近似误差的时间序列,并在误差的时间序列中检测异常;与异常逼近误差相对应的图形被宣布为异常。
Shyu等人[2003]提出了一种异常检测技术,作者利用鲁棒PCA[Huber 1974]从正常训练数据的协方差矩阵估计主成分。测试阶段包括比较。
光谱技术的优缺点光谱异常检测技术的优点如下:
(1) 光谱技术自动执行降维,因此适用于处理高维数据集。此外,它们还可以用作预处理步骤,然后在变换空间中应用任何现有的异常检测技术。
(2) 光谱技术可以在无监督的环境中使用。
光谱异常检测技术的缺点如下:
(1) 只有当正常和异常情况在数据的低维嵌入中是可分离的时,光谱技术才有用。
(2) 光谱技术通常具有很高的计算复杂度。
14 上下文异常
前几节讨论的异常检测技术主要关注点异常的检测。在本节中,我们将讨论处理上下文异常的异常检测技术。
如第2.2.2节所述,上下文异常要求数据具有一组上下文属性(定义上下文)和一组行为属性(定义上下文,检测上下文中的异常情况)。Song等人[2007]使用了与我们的术语类似的术语环境和指标属性。可定义上下文属性的一些方式包括:
(1) 空间:数据具有空间属性,这些属性定义了数据实例的位置,从而定义了空间邻域。许多基于上下文的异常检测技术[Lu et al.2003;Shekhar et al.2001;Kou et al.2006;Sun和Chawla 2004]已被提出用于空间数据。
(2) 图:连接节点(数据实例)的边定义每个节点的邻域。Sun等人[2005]将上下文异常检测技术应用于基于图形的数据。
(3) 顺序:数据是顺序的,即数据实例的上下文属性是其在序列中的位置。
时间序列数据在背景异常检测类别中得到了广泛的探索[Abraham and Chuang 1989;Abraham and Box 1979;Rousseeuw and Leroy 1987;Bianco et al.2001;Fox 1972;Salvador and Chan 2003;Tsay et al.2000;Galeano et al.2004;Zeevi et al.1997]。
已开发出异常检测技术的另一种顺序数据形式是事件数据,其中每个事件都有一个时间戳(例如操作系统调用数据或web数据[Ilgun et al.1995;Villata and Ma 2002;Weiss and Hirsh 1998;Smyth 1994])。时间序列数据和事件序列之间的区别在于,对于后者,连续事件之间的到达时间是不均匀的。
(4) 概要:通常情况下,数据可能没有明确的空间或顺序结构,但仍然可以使用一组上下文属性将其分割或聚集到组件中。这些属性通常用于分析和分组活动监控系统中的用户,如手机欺诈检测[Fawcett and Provost 1999;Teng et al.1990]、CRM数据库[He et al.2004b]和信用卡欺诈检测[Bolton and Hand 1999]。然后在用户组内分析异常情况。
与关于点异常检测技术的丰富文献相比,对上下文异常检测的研究有限。大体上,此类技术可分为两类。第一类技术将上下文异常检测问题简化为点异常检测问题,而第二类技术对数据中的结构进行建模,并使用该模型检测异常。
14.1 归约到点异常检测问题
由于上下文异常是单个数据实例(如点异常),但仅在上下文中异常,因此一种方法是在上下文中应用已知的点异常检测技术。
基于通用约简的技术包括两个步骤。首先,使用上下文属性为每个测试实例标识上下文。其次,使用已知点异常检测技术计算上下文中测试实例的异常分数。
对于识别上下文并不简单的场景,已经提出了一个基于通用约简的技术示例[Song等人,2007]。
作者假设这些属性已经被划分为上下文属性和行为属性。因此,每个数据实例d可以表示为[x,y]。
上下文数据使用高斯混合模型(例如U)进行分区。行为数据也使用另一种高斯混合模型(例如V)进行分区。
还学习了映射函数p(Vj | Ui)。当环境部分x由Ui生成时,该映射表示数据点y的指示剂部分由混合物成分Vj生成的概率
.因此,对于给定的测试实例d=[x,y],异常分数由以下公式给出:
通用技术的另一个例子是应用于手机欺诈检测[Fawcett and Provost 1999]。本例中的数据由手机使用记录组成。数据中的一个属性是手机用户,它被用作上下文属性。然后监控每个用户的活动,以使用其他属性检测异常。计算机安全也采用了类似的技术[Teng et al.1990],其中上下文属性是:用户id、一天中的时间。其余属性将与代表正常行为的现有规则进行比较,以检测异常。同级组分析[Bolton and Hand 1999]是另一种类似的技术,用户被分组为同级,并在一个组内进行欺诈分析。He等人[2004b]提出了类别异常检测的概念,本质上是使用类别标签分割数据,然后应用已知的基于聚类的异常检测技术[He等人[2002]来检测该子集内的异常。
对于空间数据,通过使用位置坐标,可以直观、直接地检测社区[Ng和Han 1994]。基于图形的异常检测[Shekhar et al.2001;Lu et al.2003;Kou et al.2006]使用Grubb分数[Grubbs 1969]或类似的统计点异常检测技术来检测空间邻域内的异常。Sun和Chawla[2004]使用一种称为SLOM(Spatial Local Outlier measure[Sun和Chawla 2006])的基于距离的度量来检测邻域内的空间异常。
14.2 利用数据结构
在几种情况下,将数据分解为上下文并不简单。这通常适用于时间序列数据和事件序列数据。在这种情况下,时间序列建模和序列建模技术被扩展以检测数据中的上下文异常。
这一类的通用技术可以描述如下。从训练数据中学习一个模型,该模型可以预测给定环境下的预期行为。如果预期行为与观察到的行为显著不同,则宣布异常。这种通用技术的一个简单例子是回归,其中上下文属性可以通过在数据上拟合回归线来预测行为属性。
对于时间序列数据,几种基于回归的时间序列建模技术,如稳健回归[Rousseeuw and Leroy 1987]、自回归模型[Fox 1972]、ARMA模型[Abraham and Chuang 1989;Abraham and Box 1979;
Galeano等人,2004年;Zeevi等人,1997),以及ARIMA模型[Bianco等人,2001;
Tsay等人(2000年),已开发用于上下文异常检测。基于回归的技术已被扩展,通过对回归以及序列之间的相关性建模,检测一组共同进化序列中的上下文异常[Yi等人,2000]。
上下文异常检测技术的优点和缺点上下文异常检测技术的主要优点是,在许多实际应用中,当数据实例在上下文中趋于相似时,它们允许对异常进行自然定义。这种技术能够检测到数据全局视图的点异常检测技术可能无法检测到的异常。
上下文异常检测技术的缺点是,它们只适用于可以定义上下文的情况。
15. 处理集体异常
本节讨论异常检测技术,重点是检测集体异常。如前所述,集体异常是作为一个集合一起发生的实例的子集,其发生相对于正常行为而言是不正常的。属于该集合的个别实例本身并不一定是异常,但正是它们以特定形式同时出现,才使它们成为异常。集体异常检测问题比点异常检测和上下文异常检测更具挑战性,因为它涉及探索异常区域的数据结构。
集体异常检测的主要数据要求是数据实例之间存在关系。最常被利用的三种关系是顺序关系、空间关系和图形关系:
顺序异常检测技术:这些技术处理顺序数据,发现子序列作为异常(也称为顺序异常)。典型的数据集包括事件序列数据,如系统调用数据[Forrest et al.1999]或数字时间序列数据[Chan and Mahoney 2005]。
-空间异常检测技术:这些技术与空间数据一起工作,并在数据中找到作为异常的连接子区域(也称为空间异常)。异常检测技术已应用于多光谱图像数据[Hazel 2000]。
-图形异常检测技术:这些技术处理图形数据,并在数据中找到作为异常的连接子图(也称为图形异常)。异常检测技术已应用于图形数据[Noble and Cook 2003]。
在序列异常检测领域进行了大量研究;
这可以归因于在几个重要的应用领域中存在顺序数据。空间异常检测主要是在图像处理领域进行的。以下各小节详细讨论了这些类别。
16. 异常检测技术的相对优势和劣势
在前面章节中讨论的大量异常检测技术中,每一种都有其独特的优点和缺点。了解哪种异常检测技术最适合于给定的异常检测问题是很重要的。
考虑到问题空间的复杂性,为每一个异常检测问题提供一个通用方案是不可行的。在本节中,我们分析了几个简单问题设置中不同类别技术的相对优势和劣势。
例如,让我们考虑以下异常检测问题。输入是二维连续数据(图10(a))。正态分布中的二维实例是由正态分布的二维数据生成的。异常是由另一个高斯分布产生的极少数实例,其平均值与第一个分布相差甚远。还有一个代表性的训练数据集,其中包含来自正常数据集的实例。因此,第4-9节中的技术所做的假设适用于该数据集,因此,属于这些类别的任何异常检测技术都将在这种情况下检测异常。
现在让我们考虑另一个2D数据集(图10(b))。让正态实例由大量不同的高斯分布生成,平均值排列在一个圆上,方差非常小。因此,正常数据将是一组紧密排列在圆上的簇。基于一类分类的技术可能会在整个数据集周围学习到一个圆形边界,因此将无法检测到位于聚类圈内的异常。另一方面,如果每个聚类被标记为不同的类别,基于多类别分类的技术可能能够了解每个聚类周围的边界,从而能够检测中心的异常。使用混合模型方法对数据建模的统计技术可能能够检测异常。
类似地,基于聚类和最近邻的技术将能够检测异常,因为它们远离所有其他实例。在一个类似的例子中(图10(c)),如果异常实例在圆的中心形成一个很大的紧密簇,基于聚类和基于最近邻的技术都会将这些实例视为正常,从而表现出较差的性能。
对于更复杂的数据集,不同类型的技术面临不同的挑战。
当维数较高时,最近邻和基于聚类的技术会受到影响,因为高维数中的距离度量无法区分正常和异常实例。光谱技术通过将数据映射到低维投影,明确地解决了高维问题。但它们的性能在很大程度上取决于一个假设,即正常情况和异常情况在投影空间中是可以区分的。
在这种情况下,基于分类的技术可能是更好的选择。
17. 结束语和今后的工作
在本次调查中,我们讨论了文献中描述异常检测问题的不同方式,并试图对各种技术的大量文献进行概述。对于每一类异常检测技术,我们都确定了一个关于正常和异常数据概念的独特假设。当将给定的技术应用于特定领域时,这些假设可以用作评估该领域技术有效性的指南。理想情况下,对异常检测的全面调查应该让读者不仅能够理解使用特定异常检测技术背后的动机,还可以对各种技术进行比较分析。但目前的研究是以非结构化的方式进行的,不依赖于异常的统一概念,这使得从理论上理解异常检测问题非常困难。未来一项可能的工作是将不同技术对正常和异常行为的假设统一成一个统计或数学模型中学习框架。Knorr和Ng[1997]对此方向进行了有限的尝试,其中作者展示了二维数据集基于距离的异常和统计异常之间的关系。
在异常检测方面有几个很有希望的进一步研究方向。
上下文和集体异常检测技术开始在多个领域发现越来越多的适用性,在这一领域有很大的发展空间。不同分布位置的数据的存在促使人们需要分布式异常检测技术[Zimmermann and Mohay 2006]。虽然这些技术处理多个站点上可用的信息,但它们通常必须同时保护每个站点中存在的信息,因此需要隐私保护异常检测技术[Vaidya和Clifton 2004]。随着传感器网络的出现,在数据到达时对其进行处理已成为一种必要。本调查中讨论的许多技术在检测异常之前都需要完整的测试数据。最近,有人提出了可以在线操作的技术[Pokrajac等人,2007年];这类技术不仅在测试实例到达时为其分配异常分数,而且还增量地更新模型。另一个即将到来的领域是在复杂系统中,异常检测正在发现越来越多的适用性。这种系统的一个例子是具有多个组件的飞机系统。此类系统中的异常检测涉及对不同组件之间的相互作用进行建模[Bronstein et al.2001]。