李沐动手学深度学习笔记---网络中的网络(NiN)
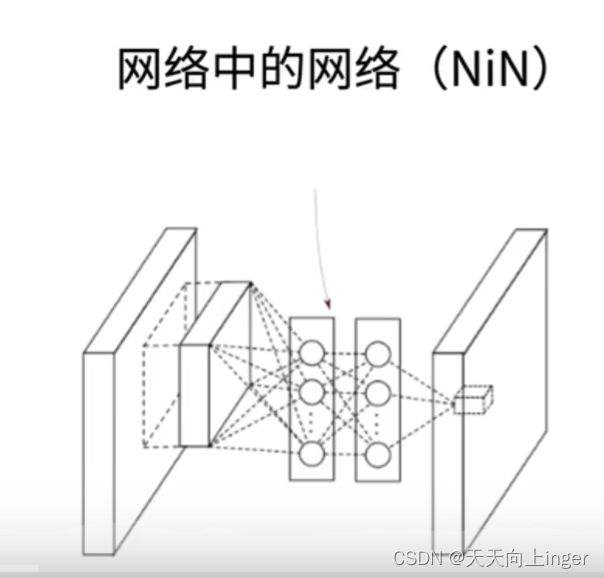
背景:
全连接层需要较多的参数,卷积层需要较少的参数。占用内存多,带宽大。很容易过拟合。

NiN的思想:
完全不要全连接层。
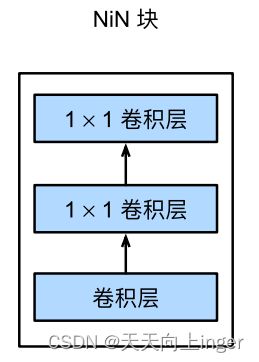
NiN块:
1*1的卷积层可以等价为一个全连接层。NiN块以一个普通卷积层开始,后⾯是两个1 × 1的卷积层。这两个1 × 1卷积层充当带有ReLU激活函数的逐像素全连接层。第⼀层的卷积窗口形状通常由用户设置。随后的卷积窗口形状固定为1 × 1。
NiN架构:

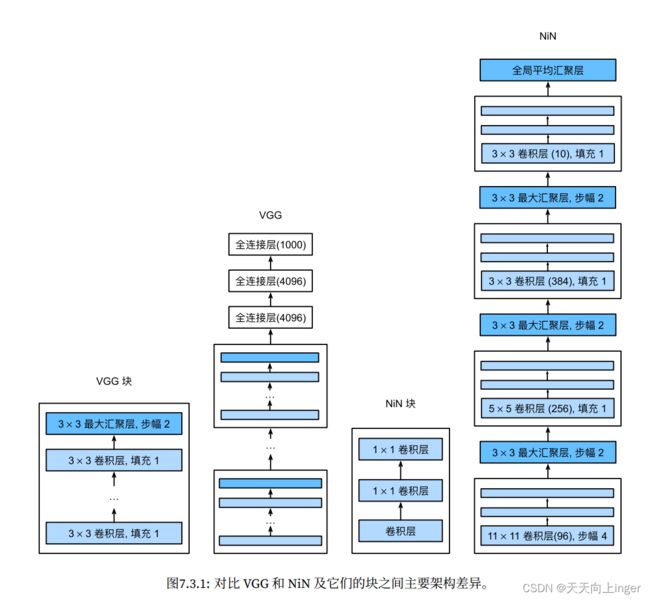
总结:

代码实现:
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels,out_channels,kernel_size,strides,padding):
return nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size,strides,padding),
nn.ReLU(),nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU(),nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU()
)
net=nn.Sequential(
nin_block(1,96,kernel_size=11,strides=4,padding=0),
nn.MaxPool2d(3,stride=2),
nin_block(96,256,kernel_size=5,strides=1,padding=1),
nn.MaxPool2d(3,stride=2),
nin_block(256,384,kernel_size=3,strides=1,padding=1),
nn.MaxPool2d(3,stride=2),nn.Dropout(0.5),
nin_block(384,10,kernel_size=3,strides=1,padding=1),
nn.AdaptiveAvgPool2d((1,1)),
# 将四维的输出转成⼆维的输出,其形状为(批量⼤⼩,10)
nn.Flatten()
)
#创建⼀个数据样本来查看每个块的输出形状
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
#使⽤Fashion-MNIST来训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())