生成对抗网络GAN&CycleGAN
GAN简介
生成对抗网络GAN主要由两部分组成:生成网络和判别网络。每个网络都可以是任何神经网络,比如普通的人工神经网络(artificial neural network,ANN)、卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)或者长短期记忆(long short term memory,LSTM)网络。判别网络则需要一些全连接层,并且以分类器收尾。生成对抗网络的基本结构图如图所示,对于生成对抗网络的具体描述如下:
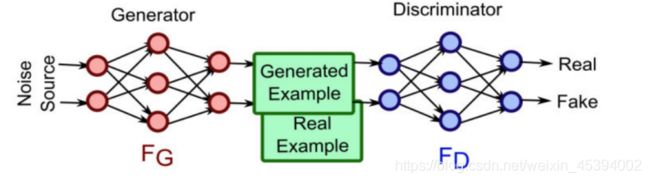
生成网络
对于GAN中的生成器而言,它会接收一个噪声输入,这个噪声输入可以来自于正太分布或其他任意分布,经过生成器复杂的神经网络变换,输出的数据可以组成一种复杂的分布,最小化这个分布与真是分布的差异即可。输入给生成器的数据其分布不用太在意,因为生成器是一个复杂的神经网络,它有能力将输入的数据“改造成”各式各样的数据分布,直观如图3所示。

判别网络
使用真实数据与生成数据来训练判别器、训练的目标是让判别器可以分辨出哪些数据是真实数据哪些数据是判别数据,即对真实数据数据打高分,给生成数据打低分,其公式如下:
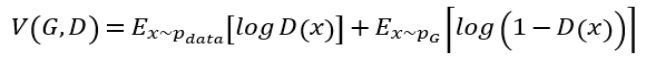
GAN的目标函数
为了使生成网络生成的图像能以假乱真,应尽量提高生成网络所生成数据和真实数据之间的相似度。可使目标函数测量这种相似度。生成网络和判别网络各有目标函数,训练过程中也分别试图最小化各自的目标函数。GAN最终的目标函数如下所示。
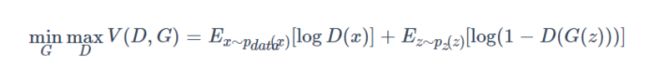
其中,D(x)是判别网络模型,G(z)是生成网络模型,p(x)是真实数据 分布,p(z)是生成网络生成的数据分布,E是期望输出。
在训练过程中,D(判别网络,discriminator)试图最大化公式的最终取值,而G(生成网络,generator)试图最小化该值。如此训练出来的GAN中。生成网络和判别网络之间会达到一种平衡,此时模型即“收敛”了,这种平衡状态就是纳什均衡。训练完成之后,就得到了一个可以生成逼真数据的生成网络。
GAN相关的概念
KL散度
KL散度,也称相对熵,用于判定两个概念分布之间的相似度。它可以测量一个概率分布p相对于另一个概率分布q的偏离。如下公式用于计算两个概率分布p(x)和q(x)之间的KL散度。
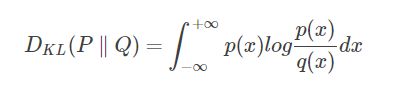
如果p(x)和q(x)处处相等,则此时KL散度为0,达到最小值。由于KL散度具有不对称性,因此不用对于测量两个概率分布之间的距离,因此也不用作距离的度量(metric)。
JS散度
JS散度,也称信息半径(information radius,IRaD)或者平均值总偏离(total divergence to the average),是测量两个概率分布之间相似度的另一种方法。它基于KL散度,但具有对称性,可用于测量两个概率分布之间的距离。对JS散度开平方即可得到JS距离,所以它是一种距离度量。
计算两个概率分布p和q之间JS散度的公式如下。
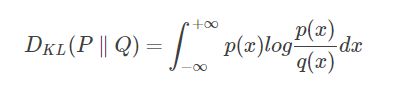
评分算法
Inception分数
Inception分数(IS)是应用最广泛的GAN评分算法。它使用一个在Imagnet上训练过的Inception3 V3网络分别提取真实图像和生成图像的特征。Shane Barrat和Rishi Sharma在论文“A Note on the Inception Score”中首次提出了该方法。IS测量生成图片的质量和多样性。计算IS的公式如下。
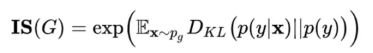
其中,Pg表示一个概率分布,X~Pg表示X是该概率分布中的一个抽样。p(y|X)是条件类别分布,p(y)是边缘类别分布。IS越高,说明模型质量越好。IS虽然是重要的测度(measure),却也存在一些问题。比如模型对于每个类别只生成一个结果,其IS仍然可以很高,但这样的模型缺乏多样性。
FID分数
为了克服Inception分数的一些缺陷,Martin Heusel等人在论文“GANs Trained by a Two Time-Scale Update Rule Converage to a Local Nash EquilibriuM”中提出FID。计算FID的公式如下。
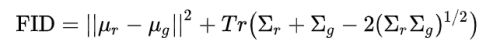
FID分数优于IS之处在于对噪声的抵抗力较好,并且可以更好地测量生成数据的多样性。
工作原理
- 生成器目标:最大化判别器将生成器结果误分类为真的可能性。
- 判别器目标:优化的目标概率为0.5,即判别器无法区分真实图片和生成图片。
在GAN的框架中,生成器需要在判别器的协调工作下进行训练,而判别器需要在对抗训练前预先进行几轮训练,以具备能够真实区分图片的能力。整个架构还需要一个重要的组成部分,那就是损失函数。损失函数提供了生成器和判别器训练过程的停止标准。
基本构建块——生成器
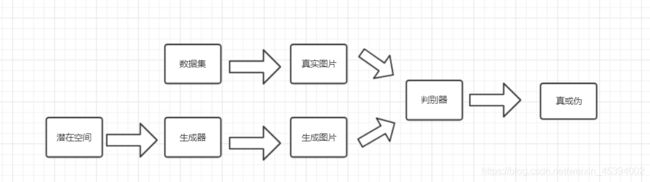
生成器组件架构图:潜在空间、生成器及其生成图片
步骤
- 生成器从潜在空间进行采样,并建立潜在空间和输出的映射关系。
- 创建一个神经网络,将输入(潜在空间)转换成输出(大部分情况下是图片)。
- 通过模型连接生成器和判别器,并以对抗的方式训练生成器。
- 生成器在训练后可以用来生成新的数据。
生成器的基本构成:
class Generator:
def __init__(selt):
self.iniVariable = 1
def lossFunction(self):
return
def buildModel(self):
return
def trainModel(self,inputX,inputY):
return
lossFunction函数定义了模型训练中的自定义损失函数(某个特定的实现可能需要自定义实现)。buildModel函数构建模型真实的神经网络。特定的训练序列可以在trainModel中进行定义;不过大部分情况下,除了判别器,我们不需要自定义训练方法的内部实现。
基本构建块——判别器

判别器用来判断一张图片的真伪。判别器通常是一个最基本的卷积神经网络。(图片领域)。
步骤
- 首先,创建一个卷积神经网络来对图片的真伪进行二分类。
- 接下来创建真实数据的数据集,之后使用生成器来创建伪造的数据集。
- 在真实数据和伪造数据上训练判别器模型。
- 我们将会学习如何平衡判别器和生成器的训练——如果判别器过于出色,则生成器将无法收敛。
工作原理
判别器将会区分真实图片和生成图片。在训练之初,真实图片的评分会高,而生成图片的评分会低。最终,判别器将无法区分真实图片和生成图片。盘本期会依赖于一个初始的损失函数来构建模型。
判别器的架构模型
class Discriminator:
def __init__(selt):
self.iniVariable = 1
def lossFunction(self):
return
def buildModel(self):
return
def trainModel(self,inputX,inputY):
return
基本构建块——损失函数
每个神经网络都需要结构化的组件来进行训练。训练的过程通常会根据特定的问题域调整参数的权重来优化损失函数。被选中的损失函数对于神经网络的结果是否优秀、能否收敛骑着重要的作用。
对于涉及有缺陷的损失函数,梯度消失,即梯度在学习过程中接近0,导致学习无法完成的问题会经常出现。因此,生成器损失函数的选择也十分重要。
判别器会作为整个架构中的一个学习损失函数。当我们构建每个模型并在GAN架构中组合它们时,需要用到多个损失函数。在这个例子里,我们定义了一个损失函数类模板来存储多个损失函数:
损失函数模板类
class LOSS:
def __init__(self):
self.initVariable = 1
def lossBaseFunction(self):
return
def lossBaseFunction2(self):
return
def lossBaseFunction3(self):
return
使用有限的数据——风格转换器
经常有类似于将照片转换成某个著名画家风格图片的神经网络。GAN架构经常被用于实现这一类网络,这类网络又被称为风格转换器。这也是我们可以快速上手的最简单的一类GAN架构应用。

这个例子的独特性在于,相对于典型深度学习技术,这个网络的训练只需要少量的数据。对于著名的画家,我们并没有海量的训练数据来学习他们的风格,只能使用有限的数据集;
创作新场景——DCGAN
利用深度卷积生成对抗网络架构可以让神经网络以一种和常规相反的反向进行操作。网络的输入是一个短语,输出是一张图片。产生输出图片的网络会尝试和一个基于经典CNN架构的判别器对抗。
当生成器跨过某个临界点之后,判别器停止训练。最终,DCGAN会接收一些列的随机数字(或者从短语生成的数字)并生成一张图片。
GAN通过损失函数来判断何时该停止训练。这也是这个架构的威力所在
- 所有的GAN都有相同的架构吗?
- GAN会以各种形式出现,有的实现简单,有的复杂。这主要取决于你的问题域以及你对生成数据准确性的要求。
- 在GAN架构中还有新的概念吗?
- GAN高度依赖于与深度学习和深度网络相关的先进技术。GAN的先进性一部分来源于其架构,另一部分来源于同时训练两个(或更多)网络的对抗性。
- 我们在实践中是如何构建GAN架构的?
- 生成器、判别器和损失函数是最为基础的构建块。
要点
- 生成器和判别器是以独立配置启动的神经网络
- 损失函数是确保架构训练可以收敛的关键组件
数据准备工作
对于一个项目,数据的准备和处理往往会花费大量的时间,只有输入数据的质量保证了,模型的输出才能够保证。数据决定了项目的成败。我们必须努力探索已有数据,并使用有效的数据来进行学习。
工作流程
- 数据预处理
- 异常数据梳理
- 平衡数据
- 数据强化
数据处理流水线
- 将数据以NumPy数组的形式加载。
- 检查数据分布及异常点。
- 针对学习的过程平衡数据集。
- 抛弃异常数据。
- 以结构化和智能化的方式强化数据。
切记:数据的重要性远远大于架构的重要性!!!
异常数据处理
单变量方法
这个方法专注于移除那些在某个属性上偏离平均值过多的数据点。评估的指标被称为清理参数。这个参数可用于定义哪些值需要从分布中被移除。选择激进的清理参数将会移除更多的异常数据,而选择容忍度较高的清理参数则不会过多地影响数据的整体分布。
例子
x = linspace(-5,5,200)
y = exp(-x**2)+randn(200)/10
s = UnivariateSpline(x,y,s=1)
xs = linspace(-5,5,1000)
ys= s(xs)
plt.plot(x,y,'.-')
plt.plot(xs,ys)
plt.show()0
numpy.linspace的使用详解
用100行代码实现第一个GAN
工作流程
- Discriminator基类
- Generator基类
- GAN基类
Discriminator基类
class Discrimininator(object):
def __init__(self,width =28,height = 28,channels = 1,latent_size = 100):
def model(self):
return model
def summary(self):
# 在屏幕中打印模型的总结信息
def save_model(self):
# 在data目录下保存模型结构
Generator基类
class Generator(object):
def __init__(self,width =28,height = 28,channels = 1,latent_size = 100):
def model(self):
return model
def summary(self):
# 在屏幕中打印模型的总结信息
def save_model(self):
# 在data目录下保存模型结构
GAN基类
class GAN(object):
def __init__(self,discriminator_model,generator_model):
# 初始化变量
def model(self):
return model
def summary(self):
# 在屏幕中打印模型的总结信息
def save_model(self):
# 在data目录下保存模型结构