机器学习模型评估与预测
模型评估与预测
- 1.1经验误差与过拟合
- 1.2 评估方法
-
- 1.2.1留出法(hold-out)
- 1.2.2交叉验证法
- 1.2.3 自助法
- 1.3性能度量
-
- 1.3.1 查准率,查全率,准确率
- 1.3.2 P-R曲线、平衡点和F1度量
-
- 1.3.2.1 P-R曲线
- 1.3.2.2 平衡点(BEP)
- 1.3.2.3 F1度量
- 1.3.3 ROC与AUC
- 1.4 偏差与方差
- 1.5正则化线性回归的偏差-方差模型
-
- 1.5.1 正则化线性回归
-
- 1.5.1.1可视化数据集
- 1.5.1.2 正则化线性回归的代价函数
- 1.5.1.3 正则化线性回归梯度
- 1.5.1.4 拟合线性回归
- 1.5.2 偏差与方差
-
- 1.5.2.1 学习曲线
- 1.5.2.2 多项式回归
1.1经验误差与过拟合
定义几个概念:
⋅ \cdot ⋅ 错误率(error rate)
E = a m E=\frac{a}{m} E=ma
其中a表示样本分类错误数,m是样本总数
⋅ \cdot ⋅ 精度(accuracy)为 1 − a m 1-\frac{a}{m} 1−ma
⋅ \cdot ⋅ 学习器的实际预测输出与样本的真实输出之间的差异称为 “误差”。
⋅ \cdot ⋅ 学习器在训练集上的误差称为 “训练误差”或“经验误差”。
⋅ \cdot ⋅ 在新样本上的误差称为 “泛化误差”。
把训练样本本身一些特点当作所有潜在样本都会具有的一般性质,导致泛化性能下降,这种现象称为 “过拟合”。
1.2 评估方法
通常,可以通过实验测试来对学习器泛化误差进行评估并进而做出选择,为此,需要使用一个人“测试集”来测试学习器对此新样本的判别能力,然后以测试集的“测试误差”作为泛化误差的近似。
1.2.1留出法(hold-out)
留出法直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另外一个作为测试集T,即D=S∪T,S∩T=空集。在S上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计。
需要注意的问题:
1.训练/测试集的划分要尽可能的保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。
2.在给定训练/测试集的样本比例后,仍然存在多种划分方式对初始数据集D进行划分,可能会对模型评估的结果产生影响。因此,单次使用留出法得到的结果往往不够稳定可靠,在使用留出法时,一般采用若干次随机划分、重复进行实验评估后取得平均值作为留出法的评估结果。
3.此外。我们希望评估的是用D训练出的模型的性能,但是留出法需划分训练/测试集,这就会导致一个窘境:若另训练集S包含大多数的样本,则训练出的模型可能更接近于D训练出的模型,但是由于T比较小,评估结果可能不够稳定准确;若另测试集T包含多一些样本,则训练集S与D的差别更大,被评估的模型与用D训练出的模型相比可能就会有较大的误差,从而降低了评估结果的保真性(fidelity)。因此,常见的做法是:将大约2/3~4/5的样本用于训练,剩余样本作为测试。

对于留出法,除了划分为测试集,验证集还有两种划分方式。
⋅ \cdot ⋅ 训练数据,验证数据和测试数据按照6:2:2的方式划分数据集
⋅ \cdot ⋅ 当数据量非常大时,可以使用 98 : 1 : 1 的比例划分训练数据,验证数据和测试数据
1.2.2交叉验证法
k 折交叉验证通过对 k 个不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不那么敏感。
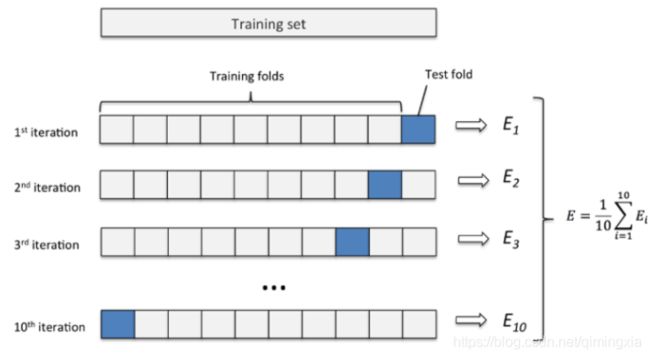
⋅ \cdot ⋅ 第一步,不重复抽样将原始数据随机分为 k 份。
⋅ \cdot ⋅ 第二步,每一次挑选其中 1 份作为测试集,剩余 k-1 份作为训练集用于模型训练。
⋅ \cdot ⋅ 第三步,重复第二步 k 次,这样每个子集都有一次机会作为测试集,其余机会作为训练集。在每个训练集上训练后得到一个模型,用这个模型在相应的测试集上测试,计算并保存模型的评估指标,
⋅ \cdot ⋅ 第四步,计算 k 组测试结果的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标。
1.2.3 自助法
在统计学中,自助法(Bootstrap Method,Bootstrapping或自助抽样法)是一种从给定训练集中有放回的均匀抽样,也就是说,每当选中一个样本,它等可能地被再次选中并被再次添加到训练集中。
数据集D中存在m个样本,运用自助抽样法,对数据集进行有放回的抽样m次后,其中始终不被采到的概率为 ( 1 − 1 m ) m (1-\frac{1}{m})^m (1−m1)m,取极限得到:
lim ( 1 − 1 m ) m = 1 e ≈ 0.368 \lim(1-\frac{1}{m})^m=\frac{1}{e}\approx0.368 lim(1−m1)m=e1≈0.368
即通过自主采样,初始训练集D中约有36.8%的样本未出现在采样数据集D’中。于是可将D’用作训练集,D/D’用作测试集。
自助法在数据集小,难以划分训练/测试集时有用。
1.3性能度量
对学习器的泛化性能进行评估,不仅需要有效可行的实验评估方法,还需要有衡量模型泛化能力的评价标准,即性能度量。
在预测任务中,给定样例集D={ ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . . . . , ( x m , y m ) (x_1,y_1),(x_2,y_2),......,(x_m,y_m) (x1,y1),(x2,y2),......,(xm,ym)},其中 y y y是示例 x x x的真实标记。要评估学习器 f f f的性能,就要把学习器的预测结果 f ( x ) f(x) f(x)与真实标记 y y y进行比较。
均方误差
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 E(f;D)=\frac{1}{m}\sum_{i=1}^{m}(f(x_i)-y_i)^2 E(f;D)=m1∑i=1m(f(xi)−yi)2
1.3.1 查准率,查全率,准确率
错误率和精度常用,但是并不能满足所有任务需求。对二分类问题,可以将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive),假正例(false positive),真反例(true negative),假反例(false negative)四种情形,令TP,FP,TN,FN分别表示其对应的样例数,则显然有TP+FP+TN+FN=总样本数。分类结果的混淆矩阵如下
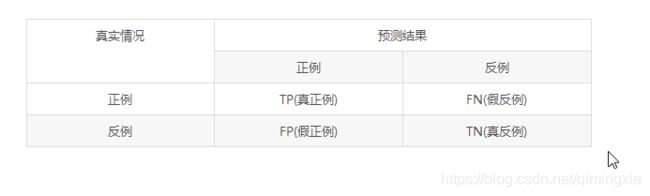
查准率(Pricision)与查全率(Recall)分别定义为:
P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
\space
R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
查准率是针对我们预测结果而言的,它表示的是预测为正的样例中有多少是真正的正样例。查全率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率低。
准确率(Accuracy):
A = T P + T N T P + T N + F P + F N A=\frac{TP+TN}{TP+TN+FP+FN} A=TP+TN+FP+FNTP+TN
精确度则是分类正确的样本数占样本总数的比例。Accuracy反应了分类器对整个样本的判定能力(即能将正的判定为正的,负的判定为负的)。
1.3.2 P-R曲线、平衡点和F1度量
1.3.2.1 P-R曲线
算法对样本进行分类时,都会有置信度,即表示该样本是正样本的概率,比如99%的概率认为样本A是正例,1%的概率认为样本B是正例。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例。
通过置信度就可以对所有样本进行排序,再逐个样本的选择阈值,在该样本之前的都属于正例,该样本之后的都属于负例。每一个样本作为划分阈值时,都可以计算对应的precision和recall,那么就可以以此绘制曲线。
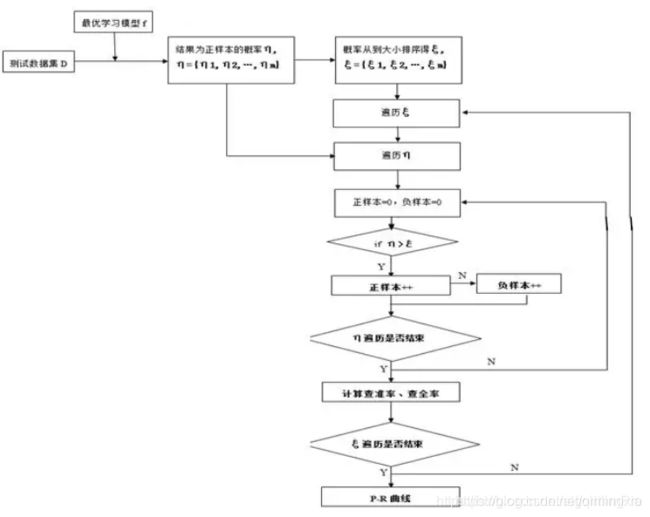
由流程图得到的P-R曲线图
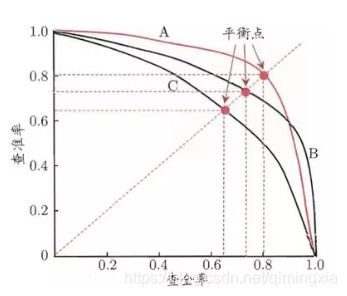
P-R曲线的特性
1,根据逐个样本作为阈值划分点的方法,可以推敲出:
⋅ \cdot ⋅ recall值是递增的(但并非严格递增),随着划分点左移,正例被判别为正例的越来越多,不会减少。
⋅ \cdot ⋅ 而精确率precision并非递减,二是有可能振荡的,虽然正例被判为正例的变多,但负例被判为正例的也变多了,因此precision会振荡,但整体趋势是下降。
2,P-R曲线肯定会经过(0,0)点
⋅ \cdot ⋅ 比如讲所有的样本全部判为负例,则TP=0,那么P=R=0,因此会经过(0,0)点,但随着阈值点左移,precision初始很接近1,recall很接近0,因此有可能从(0,0)上升的线和坐标重合,不易区分。
3,曲线最终不会到(1,0)点
4,较合理的P-R曲线应该是(曲线一开始被从(0,0)拉升到(0,1),并且前面的都预测对了,全是正例,因此precision一直是1。
P-R图直观地显示出学习器在样本总体上的查全率、查准率。在进行比较时,若一个学习器的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者,例如图1中学习器A的性能优于学习器C;如果两个学习器的P-R曲线发生了交叉,例如图1中的A和B,则难以一般性地断言两者孰优孰劣,只能在具体的查准率或查全率条件下进行比较。然而,在很多情形下,仍然希望把学习器A与B比出个高低。这时,一个比较合理的判断依据是比较P-R曲线下面积的大小,它在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例。但这个值不太容易估算,因此,设计了一些综合考虑查准率、查全率的性能度量,比如BEP度量、F1度量。
1.3.2.2 平衡点(BEP)
“平衡点”(Break-Even-Point,简称BEP)就是这样一个度量,它是“查准率=查全率”时的取值,例如图1中学习器C的BEP是0.64,而基于BEP的比较,可认为学习器A优于B。
1.3.2.3 F1度量
BEP曲线还是过于简化了些,更常用的是F1度量。F1度量的由来是加权调和平均。
\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space F β = ( 1 + β ) 2 × P × R ( β 2 × P ) + R F_\beta=\frac{(1+\beta)^2\times P\times R}{(\beta^2\times P)+R} Fβ=(β2×P)+R(1+β)2×P×R
当 β = 1 \beta=1 β=1时
\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space\space F 1 = 2 × P × R P + R F_1=\frac{2\times P\times R}{P+R} F1=P+R2×P×R
其中,β>0度量了查全率对查准率的相对重要性。β=1时,退化为标准的F1;β>1时查全率有更大影响;β<1时,查准率有更大影响。
1.3.3 ROC与AUC
与P-R曲线相似,ROC曲线也是根据预测结果对样例进行排序。按照顺序逐个把样本作为正例进行预测,以“真正例率”(TPR)为纵轴,以“假正例率”(FPR)为横轴绘制ROC曲线。
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
F P R = F P T N + F P FPR=\frac{FP}{TN+FP} FPR=TN+FPFP
对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签,如神经网络,得到诸如0.5,0,8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的为0类,大于等于0.4的为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1,0.2等等。取不同的阈值,得到的最后的分类情况也就不同。
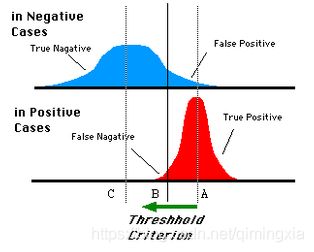
我们取一条直线,直线左边分为负类,直线右边分为正类,这条直线也就是我们所取的阈值。阈值不同,可以得到不同的结果,但是由分类器决定的统计图始终是不变的。这时候就需要一个独立于阈值,只与分类器有关的评价指标,来衡量特定分类器的好坏。
ROC曲线的动机: 在类不平衡的情况下,如正样本有90个,负样本有10个,直接把所有样本分类为正样本,得到识别率为90%,但这显然是没有意义的,这就是ROC曲线的动机。
ROC曲线: 接收者操作特征曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,roc曲线上每个点反映着对同一信号刺激的感受性。
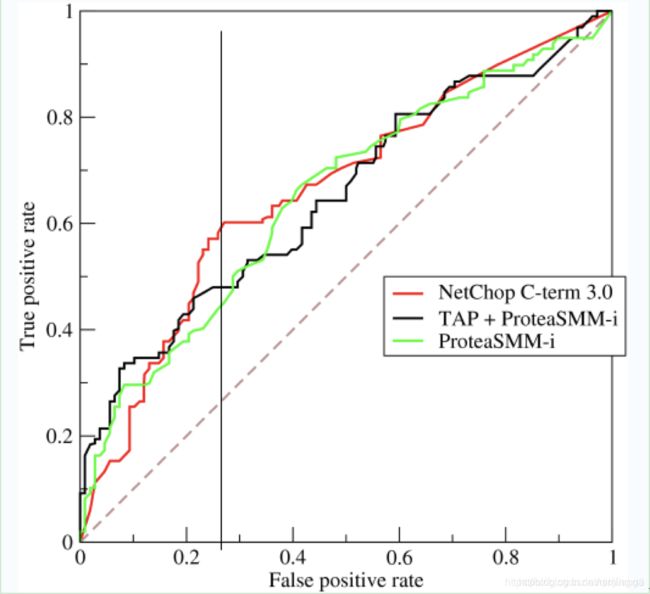
1)横轴FPR:1-TNR,1-Specificity,FPR越大,预测正类中实际负类越多。
(2)纵轴TPR:Sensitivity(正类覆盖率),TPR越大,预测正类中实际正类越多。
(3)理想目标:TPR=1,FPR=0,即图中(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好,Sensitivity、Specificity越大效果越好。
(4)如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的低FPR=0.23的情况下,红色分类器得到更高的PTR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化他。
AUC (Area Under Curve) 被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围一般在0.5和1之间。
⋅ \cdot ⋅ AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
⋅ \cdot ⋅ 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
⋅ \cdot ⋅ AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
⋅ \cdot ⋅ AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
1.4 偏差与方差
对于 预测函数,我们通常会使用以下几种手段来改进:
1,采集更多的样本数据
2,减少特征数量,去除非主要的特征
3,引入更多的相关特征
4,采用多项式特征
5,减小正则化参数 λ
6,增加正则化参数 λ
盲目地使用改进策略,为此耗费了大量的时间和精力,却没什么效果。所以我们需要一些依据来帮助我们选择合适的策略。
当模型表现不佳时,通常是出现两种问题,一种是 高偏差 问题,另一种是 高方差 问题。识别它们有助于选择正确的优化方式,所以先来看下 偏差 与 方差 的意义。
- 偏差: 描述模型输出结果的期望与样本真实结果的差距。
- 方差: 描述模型对于给定值的输出稳定性。 、
评价数据拟合程度好坏,通常用代价函数J(平方差函数)。如果只关注Jtrain(训练集误差)的话,通常会导致过拟合,因此还需要关注Jcv(交叉验证集误差)。
高偏差: Jtrain和Jcv都很大,并且Jtrain≈Jcv。对应欠拟合。
高方差: Jtrain较小,Jcv远大于Jtrain。对应过拟合。
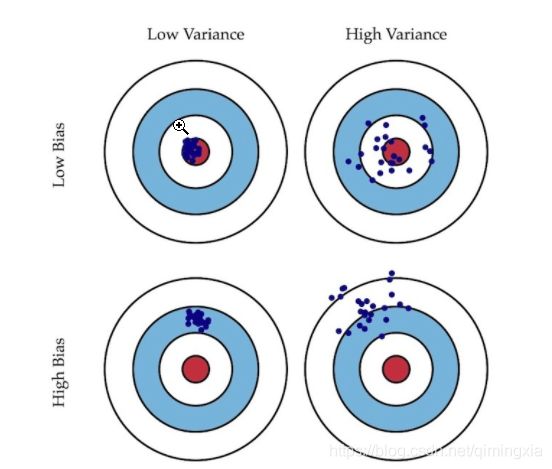
就像打靶一样,偏差描述了射击总体是否偏离了目标,而方差描述了射击准不准。接下来通过各种情况下 训练集 和 交叉验证集 的误差曲线来直观地理解高偏差与高方差 的意义。
对于 多项式回归,当次数选取较低时,我们的训练集误差和交叉验证集误差都会很大;当次数选择刚好时,训练集误差 和 交叉验证集误差 都很小;当次数过大时会产生过拟合,虽然训练集误差很小,但 交叉验证集误差会很大( 关系图如下 )。

所以我们可以计算 Jtrain(θ) 和 Jcv(θ),如果他们同时很大的话,就是遇到了高偏差问题,而 Jcv(θ) 比 Jtrain(θ) 大很多的话,则是遇到了高方差问题。
对于 正则化 参数,使用同样的分析方法,当参数比较小时容易产生过拟合现象,也就是高方差问题。而参数比较大时容易产生欠拟合现象,也就是高偏差问题。
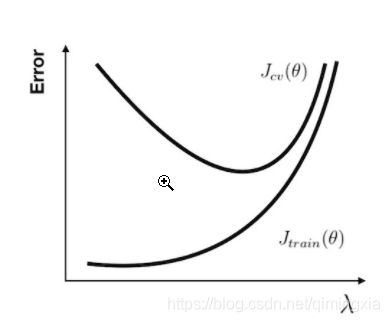
学习曲线
无论是要检查你的学习算法是否正常工作或是要改进算法的表现,学习曲线 都是一个十分直观有效的工具。学习曲线 的横轴是样本数,纵轴为 训练集 和 交叉验证集 的 误差。所以在一开始,由于样本数很少,Jtrain(θ) 几乎没有,而 Jcv(θ)则非常大。随着样本数的增加,Jtrain(θ) 不断增大,而 Jcv(θ) 因为训练数据增加而拟合得更好因此下降。所以 学习曲线 看上去如下图:
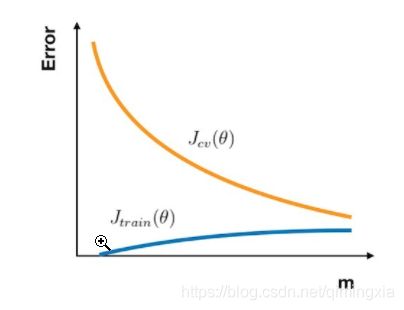
⋅ \cdot ⋅ 在高偏差的情形下:
Jtrain(θ)与 Jcv(θ)已经十分接近,但是 误差 很大。这时候一味地增加样本数并不能给算法的性能带来提升。
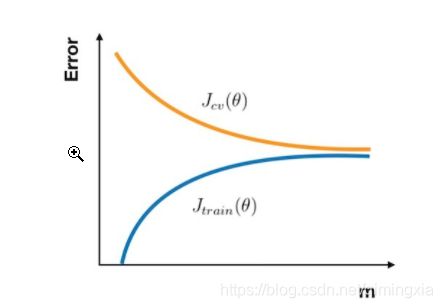
⋅ \cdot ⋅ 在高方差的情形下:
Jtrain(θ)的 误差 较小,Jcv(θ) 比较大,这时搜集更多的样本很可能带来帮助。
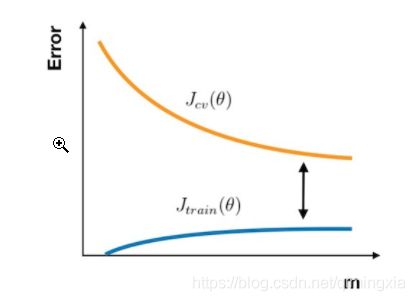
有了以上的分析手段,就能够得出在何种场景下使用改进策略:
[高方差] 采集更多的样本数据
[高方差] 减少特征数量,去除非主要的特征
[高偏差] 引入更多的相关特征
[高偏差] 采用多项式特征
[高偏差] 减小正则化参数 λλ
[高方差] 增加正则化参数 λ
1.5正则化线性回归的偏差-方差模型
实现正则化的线性回归和多项式回归,并使用它来研究具有不同偏差-方差属性的模型。
1.5.1 正则化线性回归
1.5.1.1可视化数据集
将从可视化数据集开始,其中包含水位变化的历史记录,x,以及从大坝流出的水量,y。
这个数据集分为了三个部分:
training set 训练集:训练模型
cross validation set 交叉验证集:选择正则化参数
test set 测试集:评估性能,模型训练中不曾用过的样本
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat
import scipy.optimize as opt
path = 'ex5data1.mat'
data = loadmat(path)
#Training set
X, y = data['X'], data['y']
#Cross validation set
Xval, yval = data['Xval'], data['yval']
#Test set
Xtest, ytest = data['Xtest'], data['ytest']
#Insert a column of 1's to all of the X's, as usual
X = np.insert(X ,0,1,axis=1)
Xval = np.insert(Xval ,0,1,axis=1)
Xtest = np.insert(Xtest,0,1,axis=1)
print('X={},y={}'.format(X.shape, y.shape))
print('Xval={},yval={}'.format(Xval.shape, yval.shape))
print('Xtest={},ytest={}'.format(Xtest.shape, ytest.shape))
X=(12, 2),y=(12, 1)
Xval=(21, 2),yval=(21, 1)
Xtest=(21, 2),ytest=(21, 1)
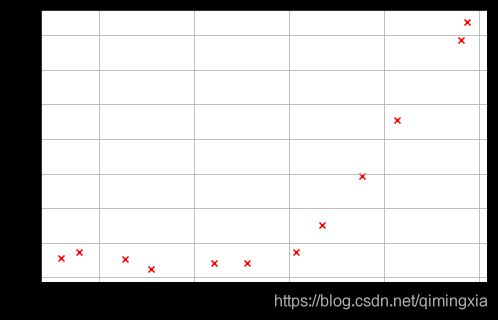
def plotData():
plt.figure(figsize=(8,5))
plt.scatter(X[:,1:], y, c='r', marker='x')
plt.xlabel('Change in water level (x)')
plt.ylabel('Water flowing out of the dam (y)')
plt.grid(True)
plotData()
1.5.1.2 正则化线性回归的代价函数

def costReg(theta, X, y, l):
'''do not regularizethe theta0
theta is a 1-d array with shape (n+1,)
X is a matrix with shape (m, n+1)
y is a matrix with shape (m, 1)
'''
cost = ((X @ theta - y.flatten()) ** 2).sum()
regterm = l * (theta[1:] @ theta[1:])
return (cost + regterm) / (2 * len(X))
1.5.1.3 正则化线性回归梯度

def gradientReg(theta, X, y, l):
"""
theta: 1-d array with shape (2,)
X: 2-d array with shape (12, 2)
y: 2-d array with shape (12, 1)
l: lambda constant
grad has same shape as theta (2,)
"""
grad = (X @ theta - y.flatten()) @ X
regterm = l * theta
regterm[0] = 0 # #don't regulate bias term
return (grad + regterm) / len(X)
# Using theta initialized at [1; 1] you should expect to see a
# gradient of [-15.303016; 598.250744] (with lambda=1)
print(gradientReg(theta, X, y, 1))
1.5.1.4 拟合线性回归
def trainLinearReg(X, y, l):
theta = np.zeros(X.shape[1])
res = opt.minimize(fun=costReg,
x0=theta,
args=(X, y ,l),
method='TNC',
jac=gradientReg)
return res.x
fit_theta = trainLinearReg(X, y, 0)
plotData()
plt.plot(X[:,1], X @ fit_theta)
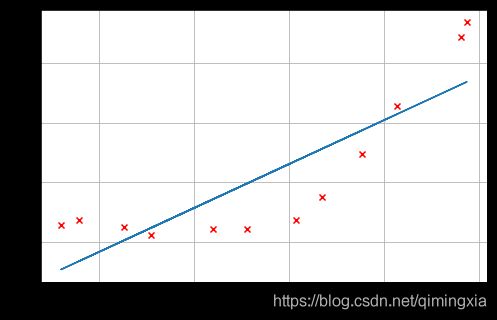
这里我们把 λ = 0 \lambda= 0 λ=0,因为我们现在实现的线性回归只有两个参数,这么低的维度,正则化并没有用。
从图中可以看到,由拟合最好的这条直线可知这个模型并不适合这个数据。
1.5.2 偏差与方差
机器学习中一个重要的概念是偏差(bias)和方差(variance)的权衡。高偏差意味着欠拟合,高方差意味着过拟合。
1.5.2.1 学习曲线

训练样本X从1开始逐渐增加,训练出不同的参数向量θ。接着通过交叉验证样本Xval计算验证误差。
⋅ \cdot ⋅使用训练集的子集来训练模型,得到不同的theta。
⋅ \cdot ⋅通过 θ \theta θ计算训练代价和交叉验证代价,切记此时不要使用正则化,将 λ = 0 \lambda = 0 λ=0。
⋅ \cdot ⋅计算交叉验证代价时记得整个交叉验证集来计算,无需分为子集。
def plot_learning_curve(X, y, Xval, yval, l):
"""画出学习曲线,即交叉验证误差和训练误差随样本数量的变化的变化"""
xx = range(1, len(X) + 1) # at least has one example
training_cost, cv_cost = [], []
for i in xx:
res = trainLinearReg(X[:i], y[:i], l)
training_cost_i = costReg(res, X[:i], y[:i], 0)
cv_cost_i = costReg(res, Xval, yval, 0)
training_cost.append(training_cost_i)
cv_cost.append(cv_cost_i)
plt.figure(figsize=(8,5))
plt.plot(xx, training_cost, label='training cost')
plt.plot(xx, cv_cost, label='cv cost')
plt.legend()
plt.xlabel('Number of training examples')
plt.ylabel('Error')
plt.title('Learning curve for linear regression')
plt.grid(True)
learningCurve(X, y, Xval, yval, 0)

从图中看出来,随着样本数量的增加,训练误差和交叉验证误差都很高,这属于高偏差,欠拟合。
1.5.2.2 多项式回归
线性模型对于数据来说太简单了,导致了欠拟合(高偏差)。在这一部分的练习中,将通过添加更多的特性来解决这个问题。
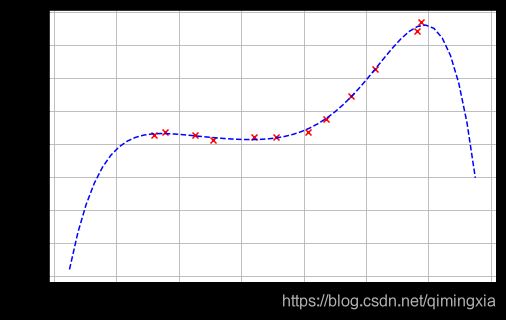
假设函数形式为:
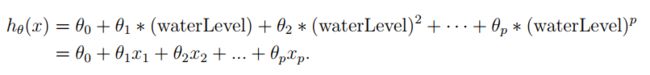
利用之前博客讨论过的特征映射的方法将X,Xval,Xtest特征映射到6次幂。
def genPolyFeatures(X, power):
"""添加多项式特征
每次在array的最后一列插入第二列的i+2次方(第一列为偏置)
从二次方开始开始插入(因为本身含有一列一次方)
"""
Xpoly = X.copy()
for i in range(2, power + 1):
Xpoly = np.insert(Xpoly, Xpoly.shape[1], np.power(Xpoly[:,1], i), axis=1)
return Xpoly
def get_means_std(X):
"""获取训练集的均值和误差,用来标准化所有数据。"""
means = np.mean(X,axis=0)
stds = np.std(X,axis=0,ddof=1) # ddof=1 means 样本标准差
return means, stds
def featureNormalize(myX, means, stds):
"""标准化"""
X_norm = myX.copy()
X_norm[:,1:] = X_norm[:,1:] - means[1:]
X_norm[:,1:] = X_norm[:,1:] / stds[1:]
return X_norm
def plot_fit(means, stds, l):
"""画出拟合曲线"""
theta = trainLinearReg(X_norm,y, l)
x = np.linspace(-75,55,50)
xmat = x.reshape(-1, 1)
xmat = np.insert(xmat,0,1,axis=1)
Xmat = genPolyFeatures(xmat, power)
Xmat_norm = featureNormalize(Xmat, means, stds)
plotData()
plt.plot(x, Xmat_norm@theta,'b--')
power = 6 # 扩展到x的6次方
train_means, train_stds = get_means_std(genPolyFeatures(X,power))
X_norm = featureNormalize(genPolyFeatures(X,power), train_means, train_stds)
Xval_norm = featureNormalize(genPolyFeatures(Xval,power), train_means, train_stds)
Xtest_norm = featureNormalize(genPolyFeatures(Xtest,power), train_means, train_stds)
plot_fit(train_means, train_stds, 0)
plot_learning_curve(X_norm, y, Xval_norm, yval, 0)

上图可以看到 λ = 0 \lambda=0 λ=0时,训练误差太小了,明显过拟合了。
继续调整 λ = 1 \lambda= 1 λ=1时:
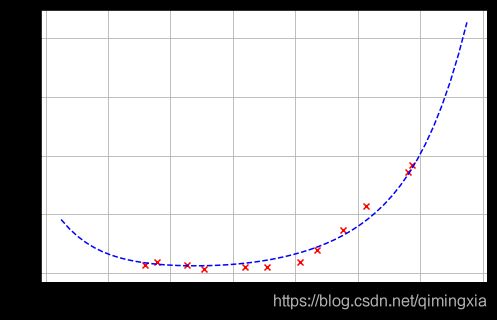

继续调整λ \lambdaλ = 100 时,很明显惩罚过多,欠拟合了

