(三-1)随机森林分类器(共3小节,完整代码即文章中所有代码)
1.集成算法概述
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通 过在数据上构建多个模型,集成所有模型的建模结果。基本上所有的机器学习领域都可以看到集成学习的身影,在 现实中集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预 测疾病的风险和病患者的易感性。在现在的各种算法竞赛中,随机森林,梯度提升树(GBDT),Xgboost等集成 算法的身影也随处可见,可见其效果之好,应用之广。
1.1集成算法的目标
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或 分类表现。
多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器(base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。
装袋法的核心思想是构建多个相互独立的评估器,然后对其预测进行平均或多数表决原则来决定集成评估器的结果。装袋法的代表模型就是随机森林。 提升法中,基评估器是相关的,是按顺序一一构建的。其核心思想是结合弱评估器的力量一次次对难以评估的样本 进行预测,从而构成一个强评估器。提升法的代表模型有Adaboost和梯度提升树。
2.复习一下sklearn中的决策树
决策树的核心问题有两个,一个是如何找出正确的特征来进行提问,即如何分枝,二是树生长到什么时候应该停 下。
对于第一个问题,我们定义了用来衡量分枝质量的指标不纯度,分类树的不纯度用基尼系数或信息熵来衡量,回归树的不纯度用MSE均方误差来衡量。每次分枝时,决策树对所有的特征进行不纯度计算,选取不纯度最低的特征进 行分枝,分枝后,又再对被分枝的不同取值下,计算每个特征的不纯度,继续选取不纯度最低的特征进行分枝。
每分枝一层,树整体的不纯度会越来越小,决策树追求的是最小不纯度。因此,决策树会一致分枝,直到没有更多的特征可用,或整体的不纯度指标已经最优,决策树就会停止生长。 决策树非常容易过拟合,这是说,它很容易在训练集上表现优秀,却在测试集上表现很糟糕。为了防止决策树的过 拟合,我们要对决策树进行剪枝,sklearn中提供了大量的剪枝参数
3.随机森林部分(RandomForestClassifer)
class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树,分类树组成的森林就叫做随机森 林分类器,回归树所集成的森林就叫做随机森林回归器。这一节主要讲解RandomForestClassifier,随机森林分类器。
3.1 重要参数
3.1.1控制基评估器的参数
criterion 不纯度的衡量指标,有基尼系数和信息熵两种选择
max_depth 树的最大深度,超过最大深度的树枝都会被剪掉
min_samples_leaf 一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf 个训练样 本,否则分枝就不会发生
min_samples_split 一个节点必须要包含至少min_samples_split个训练样本,这个节点 才允许被分枝,否则分枝就不会发生
max_features max_features 限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃, 默认值为总特征个数开平方取整
min_impurity_decrease 限制信息增益的大小,信息增益小于设定数值的分枝不会发生
注* 单个决策树的准确率越高,随机森林的准确率也会越高,因为装袋法是依赖于平均值或 者少数服从多数原则来决定集成的结果的。
3.1.2 n_estimators
这是森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越 大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的 精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越 长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。 n_estimators的默认值在现有版本的sklearn中是10,但是在即将更新的0.22版本中,这个默认值会被修正为 100。这个修正显示出了使用者的调参倾向:要更大的n_estimators。
这里以红酒数据为例
#1. 导入我们需要的包
%matplotlib inline
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
#2. 导入需要的数据集
wine = load_wine()
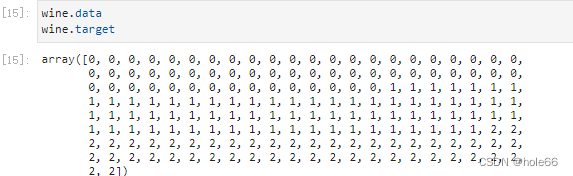
wine.data
wine.target
1.复习:sklearn建模的基本流程
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print("Single Tree:{}".format(score_c)
,"Random Forest:{}".format(score_r)
)
###Single Tree:0.9444444444444444 Random Forest:1.02.画出随机森林和决策树在一组交叉验证下的效果对比
#交叉验证:是数据集划分为n分,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10)
plt.plot(range(1,11),rfc_s,label = "RandomForest")
plt.plot(range(1,11),clf_s,label = "Decision Tree")
plt.legend()
plt.show()
可以看出的是随机森林的效果是远远好于单个决策树的
3.画出随机森林和决策树在十组交叉验证下的效果对比
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11),rfc_l,label = "Random Forest")
plt.plot(range(1,11),clf_l,label = "Decision Tree")
plt.legend()
plt.show()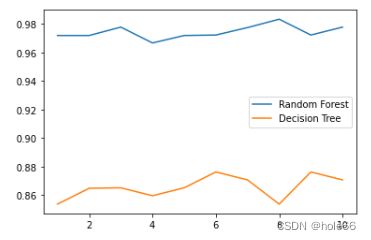
随机森林的在十组交叉下是好于单个决策树的
4.n_estimators的学习曲线
#####【TIME WARNING: 2mins 30 seconds】#####
superpa = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,201),superpa)
plt.show()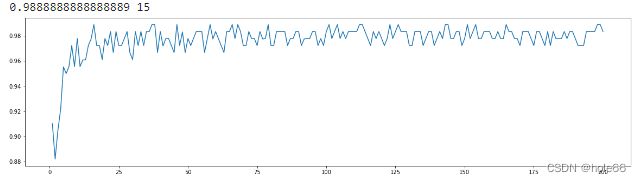
我们可以看到就是随着基评估器数量增加,在0-20内就达到平衡了,之后就是震荡。
随机森林用了什么方法,来保证集成的效果一定好于单个分类器?
3.1.3 random_state
随机森林的本质是一种装袋集成算法(bagging),装袋集成算法是对基评估器的预测结果进行平均或用多数表决 原则来决定集成评估器的结果。在刚才的红酒例子中,我们建立了25棵树,对任何一个样本而言,平均或多数表决 原则下,当且仅当有13棵以上的树判断错误的时候,随机森林才会判断错误。单独一棵决策树对红酒数据集的分类 准确率在0.85上下浮动,假设一棵树判断错误的可能性为0.2(ε),那20棵树以上都判断错误的可能性是:
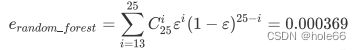
其中,i是判断错误的次数,也是判错的树的数量,ε是一棵树判断错误的概率,(1-ε)是判断正确的概率,共判对 25-i次。采用组合,是因为25棵树中,有任意i棵都判断错误。
import numpy as np
#这里的SciPy库是与numpy结合使用的。用于数学、科学、工程领域的常用软件包,可以处理最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理、图像处理、常微分方程求解器等。
from scipy.special import comb #comb组合累加
np.array([comb(25,i)*(0.2**i)*((1-0.2)**(25-i)) for i in range(13,26)]).sum()
###0.00036904803455582827可见,判断错误的几率非常小,这让随机森林在红酒数据集上的表现远远好于单棵决策树。 那现在就有一个问题了:我们说袋装法服从多数表决原则或对基分类器结果求平均,这即是说,我们默认森林中的 每棵树应该是不同的,并且会返回不同的结果。设想一下,如果随机森林里所有的树的判断结果都一致(全判断对 或全判断错),那随机森林无论应用何种集成原则来求结果,都应该无法比单棵决策树取得更好的效果才对。但我们使用了一样的类DecisionTreeClassifier,一样的参数,一样的训练集和测试集,为什么随机森林里的众多树会有 不同的判断结果?
问到这个问题,很多小伙伴可能就会想到了:sklearn中的分类树DecisionTreeClassifier自带随机性,所以随机森林中的树天生就都是不一样的。我们在讲解分类树时曾提到,决策树从最重要的特征中随机选择出一个特征来进行 分枝,因此每次生成的决策树都不一样,这个功能由参数random_state控制。 随机森林中其实也有random_state,用法和分类树中相似,只不过在分类树中,一个random_state只控制生成一 棵树,而随机森林中的random_state控制的是生成森林的模式,而非让一个森林中只有一棵树。
rfc = RandomForestClassifier(n_estimators=20,random_state=2)
rfc = rfc.fit(Xtrain, Ytrain)
#随机森林的重要属性之一:estimators,查看森林中树的状况
rfc.estimators_
我们可以观察到,当random_state固定时,随机森林中生成是一组固定的树,但每棵树依然是不一致的,这是 用”随机挑选特征进行分枝“的方法得到的随机性。并且我们可以证明,当这种随机性越大的时候,袋装法的效果一 般会越来越好。用袋装法集成时,基分类器应当是相互独立的,是不相同的。
但这种做法的局限性是很强的,当我们需要成千上万棵树的时候,数据不一定能够提供成千上万的特征来让我们构 筑尽量多尽量不同的树。因此,除了random_state。我们还需要其他的随机性。
#随机森林的重要属性之一:estimators,查看森林中树的状况
rfc.estimators_[2].random_state
###111352301for i in range(len(rfc.estimators_)):
print(rfc.estimators_[i].random_state)
3.1.4 bootstrap & oob_score
要让基分类器尽量都不一样,一种很容易理解的方法是使用不同的训练集来进行训练,而袋装法正是通过有放回的 随机抽样技术来形成不同的训练数据,bootstrap就是用来控制抽样技术的参数。 在一个含有n个样本的原始训练集中,我们进行随机采样,每次采样一个样本,并在抽取下一个样本之前将该样本 放回原始训练集,也就是说下次采样时这个样本依然可能被采集到,这样采集n次,最终得到一个和原始训练集一 样大的,n个样本组成的自助集。由于是随机采样,这样每次的自助集和原始数据集不同,和其他的采样集也是不 同的。这样我们就可以自由创造取之不尽用之不竭,并且互不相同的自助集,用这些自助集来训练我们的基分类 器,我们的基分类器自然也就各不相同了。
bootstrap参数默认True,代表采用这种有放回的随机抽样技术。通常,这个参数不会被我们设置为False。

然而有放回抽样也会有自己的问题。由于是有放回,一些样本可能在同一个自助集中出现多次,而其他一些却可能 被忽略,一般来说,自助集大约平均会包含63%的原始数据。因为每一个样本被抽到某个自助集中的概率为:1-(1-1/n)**n
当n足够大时,这个概率收敛于1-(1/e),约等于0.632。因此,会有约37%的训练数据被浪费掉,没有参与建模, 这些数据被称为袋外数据(out of bag data,简写为oob)。除了我们最开始就划分好的测试集之外,这些数据也可 以被用来作为集成算法的测试集。也就是说,在使用随机森林时,我们可以不划分测试集和训练集,只需要用袋外 数据来测试我们的模型即可。当然,这也不是绝对的,当n和n_estimators都不够大的时候,很可能就没有数据掉 落在袋外,自然也就无法使用oob数据来测试模型了。
如果希望用袋外数据来测试,则需要在实例化时就将oob_score这个参数调整为True,训练完毕之后,我们可以用 随机森林的另一个重要属性:oob_score_来查看我们的在袋外数据上测试的结果:
#无需划分训练集和测试集
rfc = RandomForestClassifier(n_estimators=25,oob_score=True)
rfc = rfc.fit(wine.data,wine.target)
#重要属性oob_score_
rfc.oob_score_
###0.98314606741573034.1 重要属性和接口
至此,我们已经讲完了所有随机森林中的重要参数,为大家复习了一下决策树的参数,并通过n_estimators, random_state,boostrap和oob_score这四个参数帮助大家了解了袋装法的基本流程和重要概念。同时,我们还 介绍了.estimators_ 和 .oob_score_ 这两个重要属性。除了这两个属性之外,作为树模型的集成算法,随机森林 自然也有.feature_importances_这个属性。 随机森林的接口与决策树完全一致,因此依然有四个常用接口:apply, fit, predict和score。除此之外,还需要注 意随机森林的predict_proba接口,这个接口返回每个测试样本对应的被分到每一类标签的概率,标签有几个分类 就返回几个概率。如果是二分类问题,则predict_proba返回的数值大于0.5的,被分为1,小于0.5的,被分为0。 传统的随机森林是利用袋装法中的规则,平均或少数服从多数来决定集成的结果,而sklearn中的随机森林是平均 每个样本对应的predict_proba返回的概率,得到一个平均概率,从而决定测试样本的分类。
#大家可以分别取尝试一下这些属性和接口
rfc = RandomForestClassifier(n_estimators=25)
rfc = rfc.fit(Xtrain, Ytrain)
rfc.score(Xtest,Ytest)
rfc.feature_importances_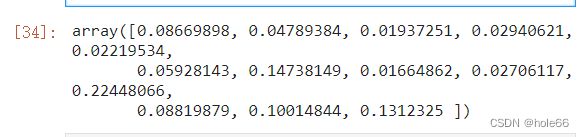
rfc.apply(Xtest)#返回这个样本在这棵树种所在的叶节点所在的索引
#预测结果
rfc.predict(Xtest)
rfc.predict_proba(Xtest) #每一个样本对应的每一类标签的概率
Bonus:Bagging的另一个必要条件
在使用袋装法时要求基评估器要尽量独立。其实,袋装法还有另一个必要条件:基分类器的判断准 确率至少要超过随机分类器,即时说,基分类器的判断准确率至少要超过50%。之前我们已经展示过随机森林的准 确率公式,基于这个公式,我们画出了基分类器的误差率ε和随机森林的误差率之间的图像。大家可以自己运行一 下这段代码,看看图像呈什么样的分布。
import numpy as np
x = np.linspace(0,1,20)
y = []
for epsilon in np.linspace(0,1,20):
E = np.array([comb(25,i)*(epsilon**i)*((1-epsilon)**(25-i))
for i in range(13,26)]).sum()
y.append(E)
plt.plot(x,y,"o-",label="when estimators are different")
plt.plot(x,x,"--",color="red",label="if all estimators are same")
plt.xlabel("individual estimator's error")
plt.ylabel("RandomForest's error")
plt.legend()
plt.show()
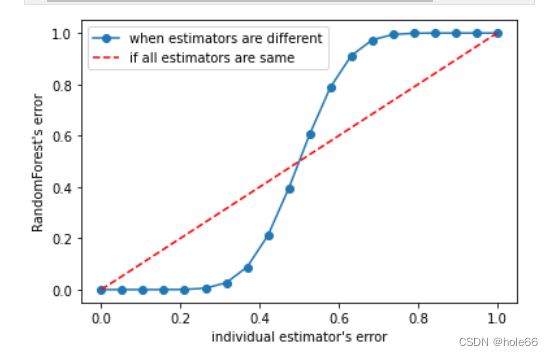
可以从图像上看出,当基分类器的误差率小于0.5,即准确率大于0.5时,集成的效果是比基分类器要好的。相反, 当基分类器的误差率大于0.5,袋装的集成算法就失效了。所以在使用随机森林之前,一定要检查,用来组成随机 森林的分类树们是否都有至少50%的预测正确率。