遗传算法优化随机森林参数(geatpy包)
前言
- 最近因为非线性规划问题,学习了geatpy包,使用遗传算法求解非线性规划问题。想到可以用遗传算法优化机器学习参数。
- 这里使用的是单目标差分进化算法,对随机森林算法参数进行调优。
- 建议在阅读本文前详细查看geatpy官方API,有助于理解算法原理。
- 我尽量在代码中穿插注释,如果有疑问或者认为有问题的地方请私信我
- 参考资料:geatpy入门、sklearn计算分类效果指标、sklearn生成各类数据集
geatpy包安装
pip install geatpy
导入包
#加载包
import numpy as np
import pandas as pd
from plotnine import*
import seaborn as sns
from scipy import stats
import matplotlib as mpl
import matplotlib.pyplot as plt
#中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# notebook嵌入图片
%matplotlib inline
# 提高分辨率
%config InlineBackend.figure_format='retina'
# 切分数据
from sklearn.model_selection import train_test_split
# 评价指标
from sklearn.metrics import mean_squared_error
# 交叉检验
from sklearn.model_selection import cross_val_score
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
分类数据生成
from sklearn.datasets import make_classification
x, y = make_classification(n_samples=1000, # 样本个数
n_features=10, # 特征个数
n_informative=4, # 有效特征个数
n_redundant=3, # 冗余特征个数(有效特征的随机组合)
n_repeated=3, # 重复特征个数(有效特征和冗余特征的随机组合)
n_classes=4, # 样本类别
n_clusters_per_class=2, # 簇的个数
random_state=42)
# 可视化分类数据集,只选择前两个特征
plt.figure(dpi = 600,figsize = (6,4))
plt.scatter(x[:,0],x[:,1],c = y)
划分数据集
- 训练集占比80%(800个样本),测试集20%(200个样本)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=45, test_size=0.2)
随机森林分类
- 使用默认参数建立随机森林分类模型,输出算法在训练集与测试集上准确率
# 随机森林分类
from sklearn.ensemble import RandomForestClassifier
rf_ori = RandomForestClassifier(oob_score=True, random_state=42)
rf_ori.fit(x_train,y_train)
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
print('训练集准确率:{:.2f}'.format(accuracy_score(y_train, rf_ori.predict(x_train))))
print('测试集准确率:{:.2f}'.format(accuracy_score(y_test, rf_ori.predict(x_test))))
输出
训练集准确率:1.00
测试集准确率:0.79
- 从结果来看貌似出现了过拟合现象
遗传算法优化参数
定义优化目标
multiprocessing多进程包,借助这个包,可以完成从单进程到并发执行的转换。可以加速遗传算法优化参数的运行速度- 需要注意的是
self.data和self.dataTarget这个地方一定要将训练集传到类定义中,否则会报错 - 目标函数为随机森林算法在训练集上10折交叉检验
f1_macro的平均值,优化目标为最大化
import geatpy as ea
from multiprocessing import Pool as ProcessPool
import multiprocessing as mp
from multiprocessing.dummy import Pool as ThreadPool
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self,PoolType):
name = 'MyProblem' # 初始化name(函数名称,可以随意设置)
M = 1 # 初始化M(目标维数)
maxormins = [-1] # 初始化目标最小最大化标记列表,1:min;-1:max
Dim = 5 # 初始化Dim(决策变量维数)
varTypes = [1] * Dim # 初始化决策变量类型,0:连续;1:离散
lb = [100,2,2,100,2] # 决策变量下界
ub = [600,50,50,1000,10] # 决策变量上界
lbin = [1,1,1,1,1] # 决策变量下边界
ubin = [1,1,1,1,1] # 决策变量上边界
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb,ub, lbin, ubin)
# 这个地方一定要将训练集传给类变量
self.data = x_train
self.dataTarget = y_train
# 设置用多线程还是多进程
self.PoolType = PoolType
if self.PoolType == 'Thread':
self.pool = ThreadPool(2) # 设置池的大小
elif self.PoolType == 'Process':
num_cores = int(mp.cpu_count()) # 获得计算机的核心数
self.pool = ProcessPool(num_cores) # 设置池的大小
def evalVars(self, Vars): # 目标函数,采用多线程加速计算
N = Vars.shape[0]
args = list(zip(list(range(N)),[Vars] * N,[self.data] * N,[self.dataTarget] * N))
if self.PoolType == 'Thread':
f = np.array(list(self.pool.map(subAimFunc, args)))
elif self.PoolType == 'Process':
result = self.pool.map_async(subAimFunc, args)
result.wait()
f = np.array(result.get())
return f
def subAimFunc(args):
i = args[0]
Vars = args[1]
data = args[2]
dataTarget = args[3]
rf_model = RandomForestClassifier(n_estimators = Vars[i, 0],
min_samples_split = Vars[i, 1],
min_samples_leaf = Vars[i, 2],
max_leaf_nodes = Vars[i, 3],
max_features = Vars[i, 4],
random_state=42,
oob_score = True).fit(data,dataTarget)
scores = cross_val_score(rf_model,data,dataTarget,scoring='f1_macro',cv=10) # 计算交叉验证的得分
ObjV_i = [scores.mean()] # 把交叉验证的平均得分作为目标函数值
return ObjV_i
定义算法模板
- 这里我选择的是单目标差分进化算法,也有其他算法模板可以选择,具体可以参考官方算法模板说明
- 算法中各参数作用与选择可以参考官方API,也可以直接读模板源代码,这里建议查看算法源代码,对参数调节会有更深理解,GitHub地址
- 算法源代码在geatpy-master → \to →geatpy → \to →algorithms下,其中mops文件夹中存储多目标优化模板,sops文件夹中存储单目标优化模板
"""============================实例化问题对象========================"""
problem = MyProblem(PoolType='Thread') # 实例化问题对象
"""==============================种群设置==========================="""
Encoding = 'RI' # 编码方式
NIND = 50 # 种群规模
Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges,problem.borders) # 创建区域描述器
population = ea.Population(Encoding, Field, NIND) # 实例化种群对象(此时种群还没被真正初始化,仅仅是生成一个种群对象)
"""===========================算法参数设置=========================="""
myAlgorithm = ea.soea_DE_best_1_L_templet(problem, population) # 实例化算法模板对象
myAlgorithm.selFunc = 'ecs' # 采用精英复制选择
myAlgorithm.MAXGEN = 30 # 最大进化代数
myAlgorithm.mutOper.F = 0.5 # 差分进化中的参数F
myAlgorithm.recOper.XOVR = 0.7 # 设置交叉概率
myAlgorithm.logTras = 1 # 设置每隔多少代记录日志,若设置成0则表示不记录日志
myAlgorithm.verbose = True # 设置是否打印输出日志信息
myAlgorithm.trappedValue=1e-6 # 单目标优化陷入停滞的判断阈值。
myAlgorithm.maxTrappedCount=10 # 进化停滞计数器最大上限值。
myAlgorithm.drawing = 1 # 设置绘图方式(0:不绘图;1:绘制结果图;2:绘制目标空间过程动画;3:绘制决策空间过程动画)
"""==========================调用算法模板进行种群进化==============="""
[BestIndi, population] = myAlgorithm.run() # 执行算法模板,得到最优个体以及最后一代种群
BestIndi.save() # 把最优个体的信息保存到文件中
"""=================================输出结果======================="""
print('评价次数:%s' % myAlgorithm.evalsNum)
print('时间花费 %s 秒' % myAlgorithm.passTime)
if BestIndi.sizes != 0:
print('最优的目标函数值为:%s' % BestIndi.ObjV[0][0])
print('最优的控制变量值为:')
count = 0
for i in range(BestIndi.Phen.shape[1]):
print(BestIndi.Phen[0, i])
else:
print('此次未找到可行解。')
输出:
==================================================================================
gen| eval | f_opt | f_max | f_avg | f_min | f_std
----------------------------------------------------------------------------------
0 | 50 | 7.63755E-01 | 7.63755E-01 | 6.73293E-01 | 5.72781E-01 | 4.88142E-02
1 | 100 | 7.75028E-01 | 7.75028E-01 | 7.21321E-01 | 5.95548E-01 | 4.23839E-02
2 | 150 | 7.75028E-01 | 7.75028E-01 | 7.40628E-01 | 6.33135E-01 | 3.29428E-02
3 | 200 | 7.75028E-01 | 7.75028E-01 | 7.54157E-01 | 6.43969E-01 | 2.56128E-02
4 | 250 | 7.75028E-01 | 7.75028E-01 | 7.61468E-01 | 6.50528E-01 | 2.12210E-02
5 | 300 | 7.75028E-01 | 7.75028E-01 | 7.65539E-01 | 6.50528E-01 | 1.80670E-02
6 | 350 | 7.75028E-01 | 7.75028E-01 | 7.70115E-01 | 7.59079E-01 | 3.64143E-03
7 | 400 | 7.75028E-01 | 7.75028E-01 | 7.70977E-01 | 7.60948E-01 | 2.66358E-03
8 | 450 | 7.75028E-01 | 7.75028E-01 | 7.71782E-01 | 7.64347E-01 | 2.11301E-03
9 | 500 | 7.75028E-01 | 7.75028E-01 | 7.72191E-01 | 7.67464E-01 | 1.56715E-03
10| 550 | 7.75028E-01 | 7.75028E-01 | 7.72412E-01 | 7.67464E-01 | 1.55444E-03
11| 600 | 7.75028E-01 | 7.75028E-01 | 7.72624E-01 | 7.69829E-01 | 1.36533E-03
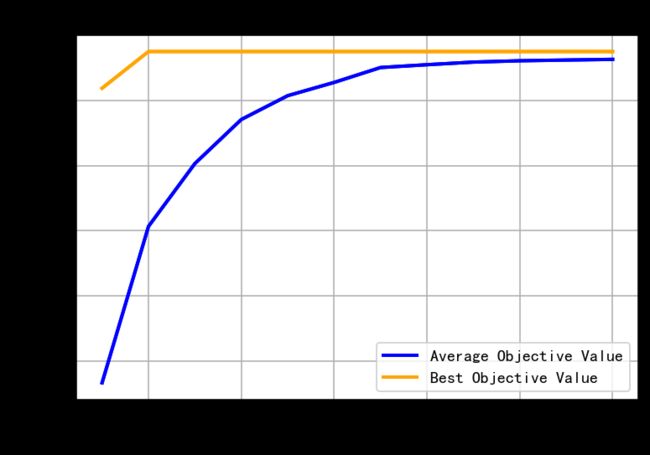
评价次数:600
时间花费 10897.077802181244 秒
最优的目标函数值为:0.7750278687764522
最优的控制变量值为:
544
6
2
185
5
- 由此得到最优参
使用最优参
rf_new = RandomForestClassifier(n_estimators = 544,
min_samples_split = 6,
min_samples_leaf = 2,
max_leaf_nodes = 185,
max_features = 5,
random_state=42,
oob_score = True)
rf_new.fit(x_train,y_train)
from sklearn.metrics import accuracy_score
print('训练集准确率:{:.2f}'.format(accuracy_score(y_train, rf_new.predict(x_train))))
print('测试集准确率:{:.2f}'.format(accuracy_score(y_test, rf_new.predict(x_test))))
输出:
训练集准确率:0.97
测试集准确率:0.81
- 可以看到训练集准确率有所下降,测试集准确率上升。在一定程度上避免了过拟合。同时说明经过遗传算法优化后参数,提高了模型泛化能力,优化效果显著。