《吴恩达机器学习》学习笔记008_聚类(Clustering)
http://www.ai-start.com/ml2014/html/week8.html
聚类(Clustering)
K-Means聚类
用 μ 1 μ^1 μ1, μ 2 μ^2 μ2,…, μ k μ^k μk 来表示聚类中心,用 c ( 1 ) c^{(1)} c(1), c ( 2 ) c^{(2)} c(2),…, c ( m ) c^{(m)} c(m)来存储与第 i i i个实例数据最近的聚类中心的索引,K-均值算法的伪代码如下:
Repeat {
for i = 1 to m
c(i) := index (form 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk := average (mean) of points assigned to cluster k
}
算法分为两个步骤,第一个for循环是赋值步骤,即:对于每一个样例 i i i,计算其应该属于的类。第二个for循环是聚类中心的移动,即:对于每一个类 K K K,重新计算该类的质心。
优化目标
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为:
J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K ) = 1 m ∑ m i = 1 ∣ X ( i ) − μ c ( i ) ∣ 2 J(c^{(1)},...,c^{(m)},μ_1,...,μ_K)=\dfrac {1}{m}\sum^{m}{i=1}\left| X^{\left( i\right) }-\mu{c^{(i)}}\right| ^{2} J(c(1),...,c(m),μ1,...,μK)=m1∑mi=1∣∣∣X(i)−μc(i)∣∣∣2
其中 μ c ( i ) {{\mu }_{{{c}^{(i)}}}} μc(i)代表与 x ( i ) {{x}^{(i)}} x(i)最近的聚类中心点。 我们的的优化目标便是找出使得代价函数最小的 c ( 1 ) c^{(1)} c(1), c ( 2 ) c^{(2)} c(2),…, c ( m ) c^{(m)} c(m)和 μ 1 μ^1 μ1, μ 2 μ^2 μ2,…, μ k μ^k μk:
回顾刚才给出的: K-均值迭代算法,我们知道,第一个循环是用于减小 c ( i ) c^{(i)} c(i)引起的代价,而第二个循环则是用于减小 μ i {{\mu }_{i}} μi引起的代价。迭代的过程一定会是每一次迭代都在减小代价函数,不然便是出现了错误。
随机初始化
在运行K-均值算法的之前,我们首先要随机初始化所有的聚类中心点,下面介绍怎样做:
我们应该选择 K < m K
随机选择 K K K个训练实例,然后令 K K K个聚类中心分别与这 K K K个训练实例相等
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
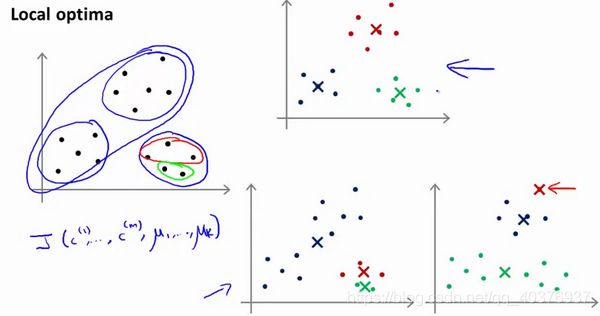
为了解决这个问题,我们通常需要多次运行K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果。这种方法在 K K K较小的时候(2–10)还是可行的,但是如果 K K K较大,这么做也可能不会有明显地改善。
聚类数的选择
当人们在讨论,选择聚类数目的方法时,有一个可能会谈及的方法叫作“肘部法则”。关于“肘部法则”,我们所需要做的是改变 K K K值,也就是聚类类别数目的总数。我们用一个聚类来运行K均值聚类方法。这就意味着,所有的数据都会分到一个聚类里,然后计算成本函数或者计算畸变函数 J J J。 K K K代表聚类数字。
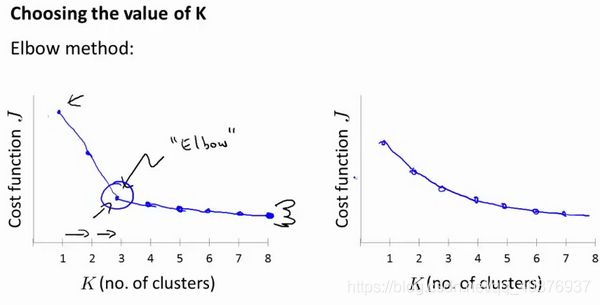
我们可能会得到一条类似于这样的曲线。像一个人的肘部。这就是“肘部法则”所做的,让我们来看这样一个图,看起来就好像有一个很清楚的肘在那儿。好像人的手臂,如果你伸出你的胳膊,那么这就是你的肩关节、肘关节、手。这就是“肘部法则”。你会发现这种模式,它的畸变值会迅速下降,从1到2,从2到3之后,你会在3的时候达到一个肘点。在此之后,畸变值就下降的非常慢,看起来就像使用3个聚类来进行聚类是正确的,这是因为那个点是曲线的肘点,畸变值下降得很快, K = 3 K=3 K=3之后就下降得很慢,那么我们就选 K = 3 K=3 K=3。当你应用“肘部法则”的时候,如果你得到了一个像上面这样的图,那么这将是一种用来选择聚类个数的合理方法。
降维(Dimensionality Reduction)
动机一:数据压缩
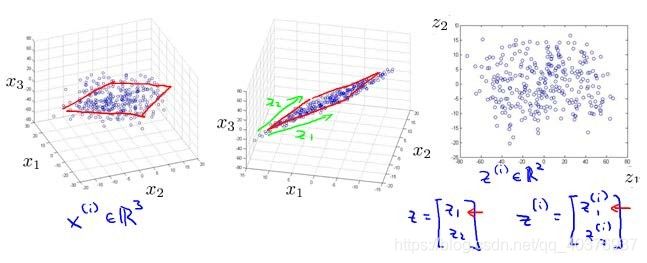
动机二:数据可视化
主成分分析(PCA)
主成分分析(PCA)是最常见的降维算法。
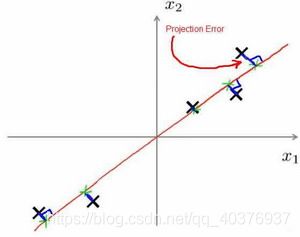
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
面给出主成分分析问题的描述:
问题是要将 n n n维数据降至 k k k维,目标是找到向量 u ( 1 ) u^{(1)} u(1), u ( 2 ) u^{(2)} u(2),…, u ( k ) u^{(k)} u(k)使得总的投射误差最小。主成分分析与线性回顾的比较:
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投射误差(Projected Error),而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。
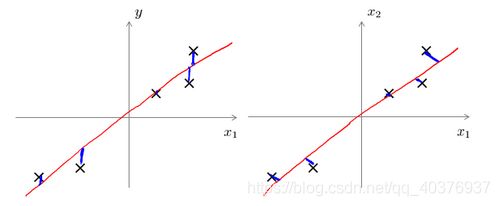
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。
PCA将 n n n个特征降维到 k k k个,可以用来进行数据压缩,如果100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩。但PCA 要保证降维后,还要保证数据的特性损失最小。
PCA技术的一大好处是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
主成分分析算法
PCA 减少 n n n维到 k k k维:
第一步是均值归一化。我们需要计算出所有特征的均值,然后令 x j = x j − μ j x_j= x_j-μ_j xj=xj−μj。如果特征是在不同的数量级上,我们还需要将其除以标准差 σ 2 σ^2 σ2。
第二步是计算协方差矩阵(covariance matrix) Σ Σ Σ: ∑ = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T \sum=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T} ∑=m1∑i=1n(x(i))(x(i))T
第三步是计算协方差矩阵 Σ Σ Σ的特征向量(eigenvectors):
在 Octave 里我们可以利用奇异值分解(singular value decomposition)来求解,[U, S, V]= svd(sigma)。

S i g m a = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T Sigma=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T} Sigma=m1i=1∑n(x(i))(x(i))T

对于一个 n × n n×n n×n维度的矩阵,上式中的 U U U是一个具有与数据之间最小投射误差的方向向量构成的矩阵。如果我们希望将数据从 n n n维降至 k k k维,我们只需要从 U U U中选取前 k k k个向量,获得一个 n × k n×k n×k维度的矩阵,我们用 U r e d u c e U_{reduce} Ureduce表示,然后通过如下计算获得要求的新特征向量 z ( i ) z^{(i)} z(i): z ( i ) = U r e d u c e T ∗ x ( i ) z^{(i)}=U^{T}_{reduce}*x^{(i)} z(i)=UreduceT∗x(i)
其中 x x x是 n × 1 n×1 n×1维的,因此结果为 k × 1 k×1 k×1维度。注,我们不对方差特征进行处理。
选择主成分的数量
主要成分分析是减少投射的平均均方误差:
训练集的方差为: 1 m ∑ i = 1 m ∣ x ( i ) ∣ 2 \dfrac {1}{m}\sum^{m}_{i=1}\left| x^{\left( i\right) }\right| ^{2} m1∑i=1m∣∣x(i)∣∣2
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 k k k值。
如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。
我们可以先令 k = 1 k=1 k=1,然后进行主要成分分析,获得 U r e d u c e U_{reduce} Ureduce和 z z z,然后计算比例是否小于1%。如果不是的话再令 k = 2 k=2 k=2,如此类推,直到找到可以使得比例小于1%的最小 k k k 值(原因是各个特征之间通常情况存在某种相关性)。
还有一些更好的方式来选择 k k k,当我们在Octave中调用“svd”函数的时候,我们获得三个参数:[U, S, V] = svd(sigma)。
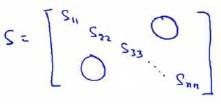
其中的 S S S是一个 n × n n×n n×n的矩阵,只有对角线上有值,而其它单元都是0,我们可以使用这个矩阵来计算平均均方误差与训练集方差的比例: 1 m ∑ m i = 1 ∣ x ( i ) − x ( i ) a p p r o x ∣ 2 1 m ∑ m i = 1 ∣ x ( i ) ∣ 2 = 1 − Σ k i = 1 S i i Σ m i = 1 S i i ≤ 1 \dfrac {\dfrac {1}{m}\sum^{m}{i=1}\left| x^{\left( i\right) }-x^{\left( i\right) }{approx}\right| ^{2}}{\dfrac {1}{m}\sum^{m}{i=1}\left| x^{(i)}\right| ^{2}}=1-\dfrac {\Sigma^{k}{i=1}S_{ii}}{\Sigma^{m}{i=1}S{ii}}\leq 1% m1∑mi=1∣∣x(i)∣∣2m1∑mi=1∣∣x(i)−x(i)approx∣∣2=1−Σmi=1SiiΣki=1Sii≤1
也就是: Σ k i = 1 s i i Σ n i = 1 s i i ≥ 0.99 \frac {\Sigma^{k}{i=1}s{ii}}{\Sigma^{n}{i=1}s{ii}}\geq0.99 Σni=1siiΣki=1sii≥0.99
在压缩过数据后,我们可以采用如下方法来近似地获得原有的特征: x ( i ) a p p r o x = U r e d u c e z ( i ) x^{\left( i\right) }{approx}=U{reduce}z^{(i)} x(i)approx=Ureducez(i)