【Ryo】Python:随机森林及参数优化——基于Kaggle的实战详解
机器学习在目前数字金融领域具有重要的地位,因此学习各类ML方法对于解决金融识别、信用评估、政策判断有很大的帮助作用。本文是我偶然间发现Kaggle上最新的一个dataset,基于此贷款数据loandata进行了相关的Python操作,利用随机森林的集成方法解决金融政策判断的问题,同时进行了调参优化(无手撕推导 非算法)。
| 研究内容 | 软件 | 日期 |
|---|---|---|
| 机器学习;随机森林;调参 | Python3 | 2021年7月25日 |
一、数据背景
我之前利用Modeler完成了一个关于信贷风险的贝叶斯神经网络建模项目。【链接:SPSS Modeler:贝叶斯网络在预测银行信贷风险中的应用】该项目也是应用为主,对于机器学习原理没有过多介绍,因此在特定情况下调参优化会成为一个难题。本次项目我选择从Python出发,利用sklearn机器学习撸代码解决类似的问题。
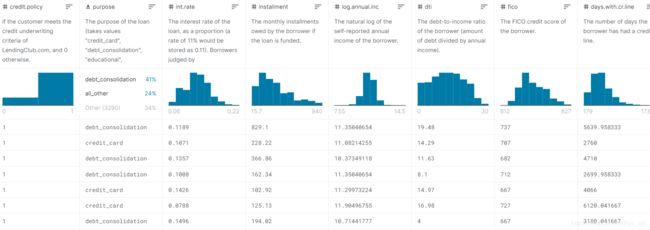
关于数据:这个贷款数据是我在kaggle挑选的最新的一个数据集,它是来自LendingClub.com 的公开数据。该俱乐部将需要钱的人(借款人)与有钱的人(投资者)联系起来。有希望地,作为投资者,您希望投资那些表现出很有可能回报您的人。我将使用 2007-2010 年的贷款数据,并尝试对借款人是否全额偿还贷款进行分类和预测。该数据集共14个字段,9600条记录,字段描述如下所示:

target是credit policy,如果客户符合LendingClub.com的信用承保标准,则为1,否则为0。本身这是一个针对因变量为0-1二元选择的一个求解问题,我们可以参考两种思路,一种是进行逻辑回归,把他当做一个寻找回归器regressor的问题,当然最优解还是把他当做二元的分类问题寻找一个classifier。
最后,以下是该数据集部分的一个简单概览,准备动手吧!
二、数据准备与特征选择
首先数据导入并导一些简单的数据操作包。
#1.导包 数据准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("D:\\py\\loan_data.csv")
接着进行数据清洗,我们可以发现purpose是目的是一个分类别的字段,要用分类器则将6个类别转化为数字1-6。导入编码包encoder进行编码。
#2.数据清洗
from sklearn.preprocessing import LabelEncoder
data['purpose']= LabelEncoder().fit_transform(data['purpose'])
再进行描述性统计,查看数据的基本情况,如缺失、分布、类别等。
#3.描述性统计及相关性分析
data.info() # 展示data的概览信息 无缺失值
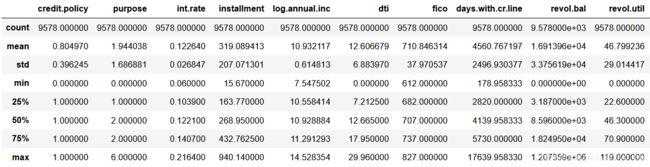
data.describe() # 展示data描述性统计
均已转化为整型或者浮点了,并且无缺失值可以直接开始特征选择。

查看数据的相关性,寻找相关性高的变量予以剔除。(注:本步骤其实进行了很多次调整,不是简单的因为fico与int.rate的高相关性而删除了int.rate变量)
data.corr() #相关性显示fico 和 int.rate 相关性0.7较高,模型中考虑删除某项
figure, ax = plt.subplots(figsize=(12, 12))
sns.heatmap(data.corr(), square=True, annot=True, ax=ax)
plt.show()
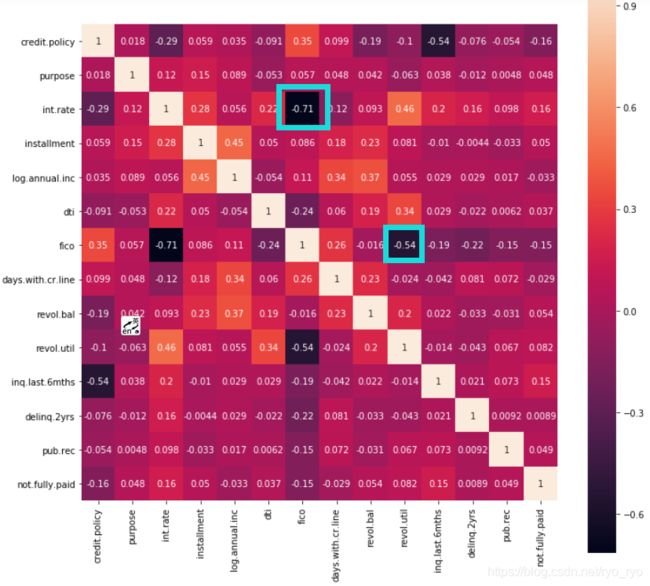
可以看出0.71属于一个高相关性,对这两个变量需要进行取舍,中间进行了逻辑回归并且验证了向后剔除法是去掉rate变量后更优因此后续删除了该变量获得最终结果。x3为输入的自变量字段,y3为target。
#4.删除int.rate以后 继续优化
data_del2 = data.drop('int.rate', axis = 1)
x3 = np.array(data_del2.iloc[:,1:13])
y3 = np.array(data_del2['credit.policy'])
三、建立模型
这一部分就是最主要建模部分了,分割数据后先建立一个随机森林模型,最大深度设置为4,其余默认。拟合完成后利用交叉验证(cv=10)查看精确度为0.975。(已经是一个较好的结果了,逻辑回归仅为0.81,调参后为0.84)
#5.模型——随机森林
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x3, y3, test_size=0.3, random_state=200) #分割数据集为训练集和测试集
from sklearn.ensemble import RandomForestClassifier
RFC = RandomForestClassifier(n_estimators=100,random_state=0,max_depth=4)
RFC.fit(x_train,y_train)
RFC_pred = RFC.predict(x_test) #预测
from sklearn import metrics
from sklearn.model_selection import cross_val_score #交叉验证
RFC_accuracy = metrics.accuracy_score(y_test,RFC_pred)
print('RFC_accuracy 模型综合评估矩阵如下:%.3f'% RFC_accuracy)
score_pre = cross_val_score(RFC,x3,y3,cv=10).mean() #利用所有数据,进行交叉验证以后0.976变差了
score_pre
四、参数优化
这一部分主要进行调参优化模型的精度。随机森林最主要就是优化n_estimators树的棵数,深度、信息计算方法、叶子结点等等都是辅助调参。将n_estimators设置在0-200之间,每一步都储存他的得分score然后画出图像。
#6.调参优化
## 随机森林调整的第一步:无论如何先来调n_estimators,以10为分隔点
scorel = []
for i in range(0,200,10):
RFC = RandomForestClassifier(n_estimators=i+1,
n_jobs=-1,
random_state=90)
score = cross_val_score(RFC,x3,y3,cv=10).mean()
scorel.append(score)
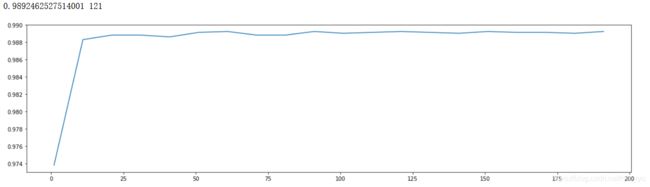
print(max(scorel),(scorel.index(max(scorel))*10)+1) #作图反映出准确度随着估计器数量的变化,121的附近最好
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.show()
结果显示在121附近10格存在最好的参数,得分为0.98924。
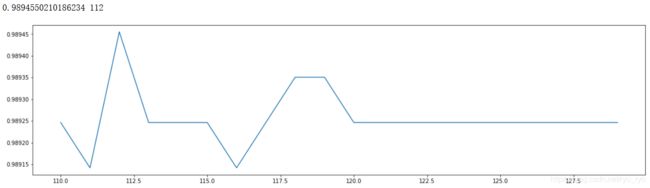
根据上面的显示最优点在121附近,进一步细化学习曲线,在110-130之间寻找具体数值。
## 根据上面的显示最优点在121附近,进一步细化学习曲线
scorel = []
for i in range(110,130):
RFC = RandomForestClassifier(n_estimators=i,
n_jobs=-1,
random_state=90)
score = cross_val_score(RFC,x3,y3,cv=10).mean()
scorel.append(score)
print(max(scorel),([*range(110,130)][scorel.index(max(scorel))])) #112是最优的估计器数量 #最优得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(range(110,130),scorel)
plt.show()
结果显示112为最佳树的数量,得分为0.98945,略大于0.98924。同时也说明其他参数调整的提升可能性不大了。
 一次次进行网格搜索验证参数,没有装包同时验证,因为多个参数如果幂叠加就运行很久,因此一个个来寻找在112树情况下的最优解。
一次次进行网格搜索验证参数,没有装包同时验证,因为多个参数如果幂叠加就运行很久,因此一个个来寻找在112树情况下的最优解。
## 调整max_features
param_grid = {'max_features':['auto', 'sqrt','log2']}
RFC = RandomForestClassifier(n_estimators=112
,random_state=90
)
GS = GridSearchCV(RFC,param_grid,cv=10)
GS.fit(x3,y3)
GS.best_params_ #最佳最大特征方法为auto 不用更改默认
## 调整min_samples_split(1)
param_grid = {'min_samples_split':[np.arange(2, 11, 1),np.arange(0.1, 1, 0.1]} #这个数要么是2-N的整数,要么是0-1之间的浮点数,比较2-11和0.1-1具体哪个好
RFC = RandomForestClassifier(n_estimators=112
,random_state=90
)
GS = GridSearchCV(RFC,param_grid,cv=10)
GS.fit(x3,y3)
GS.best_params_ #最佳 最小分割点为2 不用更改默认
## 调整min_samples_leaf
param_grid = {'min_samples_leaf':np.arange(1, 11, 1)}
RFC = RandomForestClassifier(n_estimators=112
,random_state=90
)
GS = GridSearchCV(RFC,param_grid,cv=10)
GS.fit(x3,y3)
GS.best_params_ #最佳 最小叶子为1,不用更改默认
## 调整criterion
param_grid = {'criterion':['gini', 'entropy']}
RFC = RandomForestClassifier(n_estimators=112
,random_state=90
)
GS = GridSearchCV(RFC,param_grid,cv=10)
GS.fit(x3,y3)
GS.best_params_ #在这种情况下,最佳判别标准为entropy 信息熵比基尼要好!需要改变。
## 优化max_depth
from sklearn.model_selection import GridSearchCV
param_grid = {'max_depth':np.arange(1, 20, 1)} # 一般根据数据的大小来进行一个1~20这样的试探,更应该画出学习曲线,来观察深度对模型的影响
RFC = RandomForestClassifier(n_estimators=112
,random_state=90
)
GS = GridSearchCV(RFC,param_grid,cv=10)
GS.fit(x3,y3)
GS.best_params_ #最佳深度为17
结果均已标注,需要注意的是,最佳深度17反而降低了分数,可能存在过拟合的情况,因此最佳深度我们保持默认。
五、结果与讨论
最终结果n_estimators=112,criterion=‘entropy’,最优得分为0.98966,提升了1.4%左右。
#7.结果
RFCfinal = RandomForestClassifier(n_estimators=112,criterion='entropy',random_state=90,)
score = cross_val_score(RFCfinal,x3,y3,cv=10).mean()
score #最优结果为0.98966
up = score-0.975
print("精确度提升为 %.4f"% up) #精确度提升为 0.0147
作为对比,展示一下cart回归树的结果,这个是最优模型,精确度突破了0.99(无交叉验证),只是在当初选择上首选了随机森林,如果进一步优化该模型或许能达到0.993。
#8。对比最优解——CART回归树
from sklearn.tree import DecisionTreeClassifier
cartreg = DecisionTreeClassifier(criterion='entropy')# 信息熵
cartreg.fit(x_train,y_train)
from sklearn import metrics
pred = cartreg.predict(x_test)
accuracy = metrics.accuracy_score(y_test,pred)
print("精确度为 %.4f"% accuracy) #精确度高达0.991,其实是最好的
写在最后,虽然本次调包调参、模型选择和特征工程比较简陋,但流程还算完整,要进一步优化需要设计算法设计从源头改变树的结构,另一个思路是通过多元回归观察VIF或者结构模型中首先对特征进行删选。(变量选取7-10个最好)