pytorch深度学习实战lesson28
第二十八课 resnet的梯度计算(如何缓解梯度问题)
沐神说:“假设你在卷积神经网络里面,只要了解一个神经网络的话,你就了解 rest net 就行了。 rest net 是一个很简单的也是很好用的一个网络。这也是大家会经常在实际中使用的一个网络。”
目录
理论部分
实践部分
理论部分

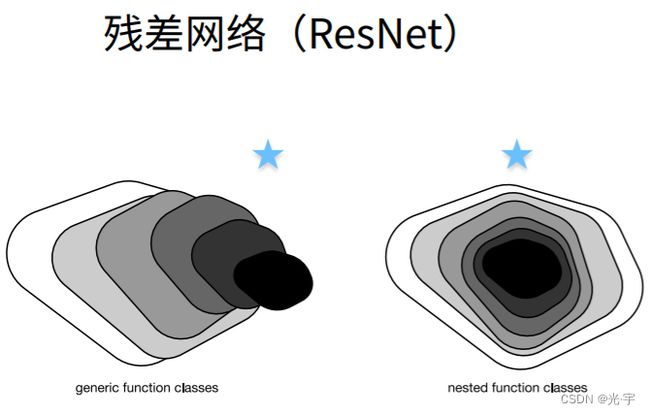
如果不断地去加深神经网络,其实不一定会带来好处吗的。举个例子,假设上图的星星是最优值的位置,然后F 1是一个函数,可以认为函数区域的大小代表了这个函数的复杂程度。按照左图来看,就是模型越复杂,学得越偏,就是说虽然f6这个模型更加复杂了,但是实际上你学偏了,还不如一个小模型和最优离得近呢。
那么应该怎么做呢?就是如果每一次增加模型的复杂度,每一次那个更复杂的模型包含前面的小模型的话,模型就不会变差。

具体来讲就是不光要新加网络层,还要引出一条残差连接与新加层的结果相加。

上图是resnet的具体设计细节。
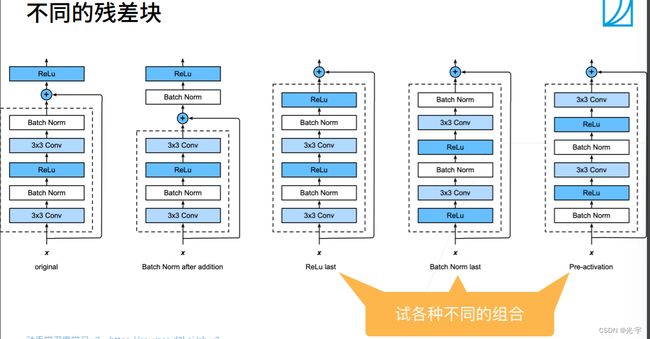
残差连接的加入位置可以进行调换。

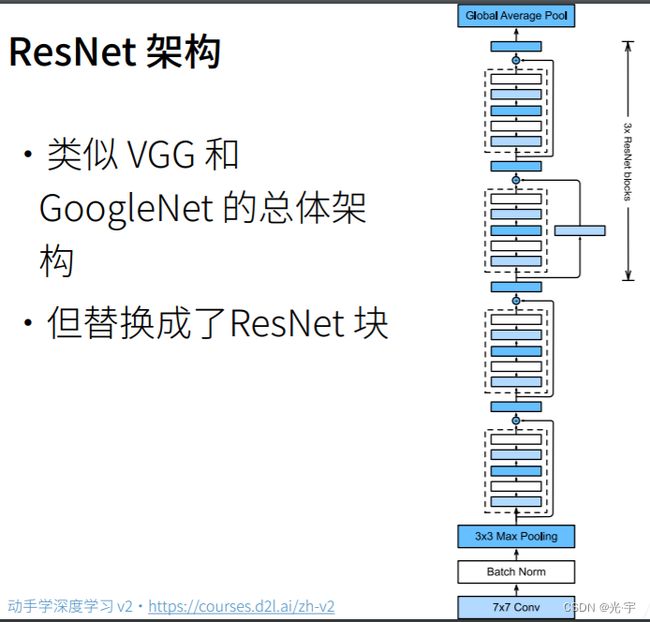
整个restnet的架构:restnet最核心的就是通过残差连接加入了一个加法。就是说就它有两种 resnet block 第一种是高宽减半的 resnet block ,所谓的高宽减半,就是说在第一个卷积层里面幅度等于2,就等于是把高宽减半了。然后通常来说也会把通道数增加一倍。然后通过调整 rest net 块以及它的输出通道数,可以得到不同的 resnet 的架构。


再回顾一下 resnet 是怎么来处理梯度消失,使得能够训练1000层的样子。其实resnet的基本思想就是将乘法变加法。

蓝字和紫字是没有残差连接的网络,就是说在之后的更新时,会出现梯度消失的现象;但是如绿色字所示,加上残差连接后,就它的梯度的计算方法从原来的乘法改成了加法,这就使得梯度不会急剧减小,可以保持层数多的情况下的梯度。
实践部分


#残差网络(ResNet)
#残差块
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import matplotlib.pyplot as plt
class Residual(nn.Module):
'''第一个卷积层的话你可以直接那个 strat 第二个第二个就是 strata 就是不变了。然后你的 padding 因为你的 kernel 数都是等于,
我就把这个回撤回下来。 kernel 数等于3,你 padding 等于1,就是高宽不变。就第一个是可以指定 strat 你可以等于2剩下的就是说这一个是不会让你指定 strat 它就等默认等于1了。
如果你要使用1乘1的卷积层的话,我会再构造一个空3出来,它就是一个,就是它会把你的 input channel 变成你的 output channel 就1如果你这两个东西不一样的话,
所以这个东西是必须的,所以它把你 input 那个 channel 数给变换到 output channel 数克动差异等于1, thread 也会是等于你要的那个 thread 这样子你能够 match 到你的高宽。'''
'''ResNet沿用了VGG完整的卷积层设计。 残差块里首先有2个有相同输出通道数的卷积层。
每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,
将输入直接加在最后的ReLU激活函数前。 这样的设计要求2个卷积层的输出与输入形状一样,
从而使它们可以相加。
如果想改变通道数,就需要引入一个额外的卷积层来将输入变换成需要的形状后再做相加运算。 '''
def __init__(self, input_channels, num_channels, use_1x1conv=False,strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
#输入和输出形状一致
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
print(Y.shape)
#增加输出通道数的同时,减半输出的高和宽
blk = Residual(3, 6, use_1x1conv=True, strides=2)
print(blk(X).shape)
#ResNet模型
'''ResNet的前两层跟之前介绍的GoogLeNet中的一样: 在输出通道数为64、步幅为2的7*7卷积层后,
接步幅为2的3*3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。'''
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
'''GoogLeNet在后面接了4个由Inception块组成的模块。 ResNet则使用4个由残差块组成的模块,
每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。
由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。
之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
下面我们来实现这个模块。注意,我们对第一个模块做了特别处理。'''
def resnet_block(input_channels, num_channels, num_residuals,first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True,strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
#接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, 10))
#最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
#观察一下ResNet中不同模块的输入形状是如何变化的
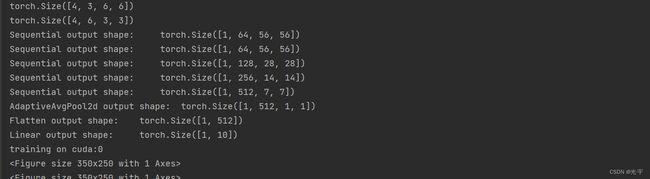
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
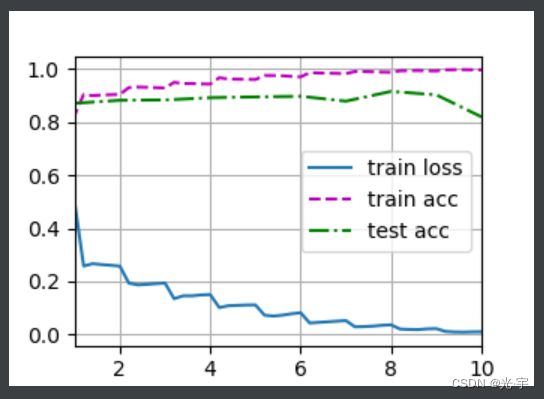
#训练模型
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
#每个模块有4个卷积层(不包括恒等映射的卷积层)。 加上第一个卷积层和最后一个全连接层,共有18层。
# 因此,这种模型通常被称为ResNet-18。 通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,
# 例如更深的含152层的ResNet-152。 虽然ResNet的主体架构跟GoogLeNet类似,
# 但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。torch.Size([4, 3, 6, 6])
torch.Size([4, 6, 3, 3])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
training on cuda:0
。。。。
loss 0.010, train acc 0.998, test acc 0.820
2106.3 examples/sec on cuda:0进程已结束,退出代码0