Fast RCNN算法详解
Fast RCNN算法详解
-
- 论文背景
- 算法对比
- 算法背景
- 算法详解
-
- ROI Pooing
- 初始化预训练神经网络
- 微调
- 多任务损失函数
- Mini-batch sampling
- Back-propagation through RoI pooling layers.
- SGD hyper-parameters
- 实验
论文背景
论文名称:Fast R-CNN
论文链接:https://arxiv.org/abs/1504.08083
论文日趋:2015.9.27
算法对比
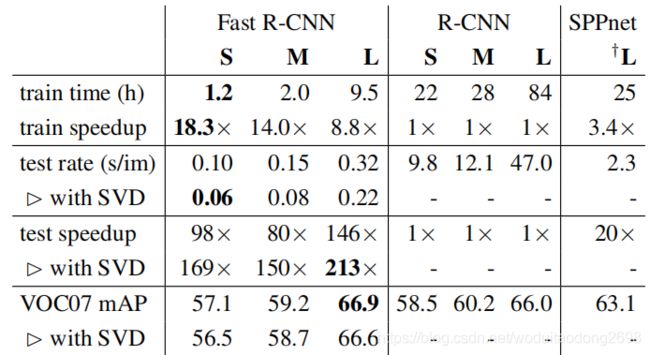
Fast R-CNN是在RCNN的基础上进行了改进,在识别准确率以及速度上都有了很大的提升,尤其是识别速度,采用VGG16神经网络的Fast R-CNN与采用简单的4层卷积层+2层全连接层的RCNN相比,训练时快9倍,测试时快213倍,与SPP-Net比,训练时快3倍,测试时快9倍。
RCNN的缺点:
-
训练过程是一个多阶段进程。首先在提取的候选区域上利用CNN进行微调,然后利用SVM分类器进行目标检测,而不是直接在微调之后加上softmax分类。因为微调需要大量的数据,为了获得更多的样本,对于正、负样本的选择时,阈值设为0.5,只进行了粗略的边界框筛选,而SVM只对特定样本进行检测,样本要求更高,准确率更高。
-
训练过程耗时、耗空间。对于每一个候选区域,都要输入到CNN和SVM中训练,这是非常耗时间的。同时对于每一张图片,都要提取2000个候选区域,这是非常占用内存空间的。
-
测试过程很慢。利用VGG16神经网络在GPU上检测,每张图片要花费47s。
算法背景
由于目标检测的复杂性,目前的使用多阶段线程的算法太耗时且不优雅;
目标检测有两个挑战:
- 大量的候选区域需要提取,需要利用Selective Search提取2000个候选区域;
- 进行粗略定位的候选区域必须进行提炼来得到更准确的定位。
改进方法:
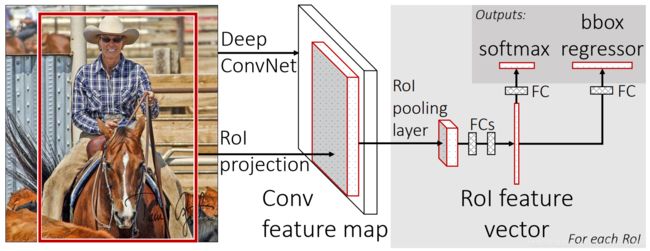
首先将整张图片输入到神经网络中,计算得到一个卷积特征映射(convolution feature map),然后使用从共享的特征映射中提取出来的特征向量来分类每一个候选区域(对于每一个候选区域,映射到特征映射上去,通过一个RoI pooling层,从而进行分类)。候选区域不需要再进入神经网络中进行卷积与池化,节省大量时间。
目标检测流程:
- 输入是一个完整的图片和候选区域;
- 首先利用神经网络(几个卷积层+最大池化层)处理完整的图片得到一个卷积特征映射;
- 接着对于每一个候选区域利用一个Region of interest(RoI)池化层从特征映射中提取一个混合长度的特征向量;输入是conv5的输出和候选区域。
- 每一个特征向量输入到一串全连接层;
- 最后通过两个分支输入到输出层。其中一个是softmax层进行对物体种类进行大致估计,共有n+1类;另一个是regressor层进行定位,每一个类别都有一个对应regressor,用softmax代替原来的SVM,对N个类别的物体会进行都会输出4个值。
算法详解
ROI Pooing
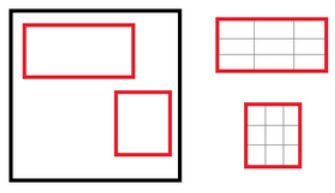
使用的是最大池化(max pooling),将ROI中的特征转换到一个更小的特征映射上,这个映射有一个H*W的混合空间拓展,ROI定义为4个参数(r,c,h,w),(r,c)是左上角的坐标值,(h,w)是高度和宽度。
将hw的窗口分割成HW格,ROI是矩形窗口,使用(h/H)*(w/W)的大概滑动窗口尺寸,对于每一个特征映射通道,池化层都是独立应用的。
首先整张图图片通过神经网络输出最后的feature map,然后将同张图片的RoIs(Selective Search的输出)映射到feature map,取每个格子里面的最大值,得到输入全连接层的feature vector。
初始化预训练神经网络
试验测试了3中类型的预训练神经网络,CaffeNet(S:RCNN的基础AlexNet);VGG_CNN_M_2014(M);VGG16(L)。每一个都有五个最大池化层,和2~3个卷积层,当使用一个预训练神经网路初始化Fast-RCNN时,它都会经历3次转换。
最后的池化层被ROI池化替代,将特征映射转换为W*H尺寸输入到全连接层。
神经网络的最后全连接层和softmax层被两个分支替代。
神经网络的输入被修改为整张图片和ROI的列表。
微调
SPP无法更新金字塔池化层之后的参数,由于每一个训练模型都来自不同的图片,反向传播是非常无效的,因为每个ROI可能具有很大的感受野,通常包含整个图片,而正向传播必须处理整个感受野,输入是非常巨大的。
在fast-rcnn中,采用SGD与mini-batch结合的方法分层采样,首先随机取样N张图片,然后每张图片取样 R / N 个RoIs 。关键的是,来自相同图像的RoI在向前和向后传播中共享计算和内存。
首先减少采样的图片数量N,然后通过从每个图像采样R/N个 RoIs。关键的是,来自同一图像的RoI在向前和向后传播中共享计算和存储器。减小N,减少了minibatches计算。例如,当N = 2和R = 128时,得到的训练方案比从128幅不同的图采样一个RoI快64倍。
多任务损失函数
损失函数分为分类损失和回归定位损失函数两部分的加权和:
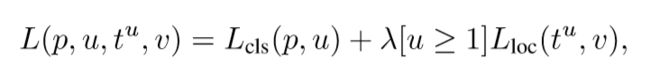
p:每一个RoI的离散可能性(softmax的k+1个输出);u:真实正确标签的类别;
t:真实正确标签的回归补偿;v:真实正确标签的边界框回归目标;
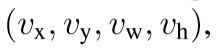
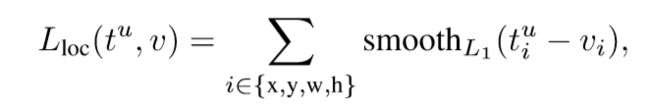
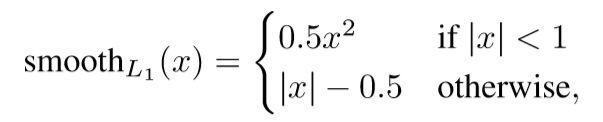
在定位的损失函数中,使用L1正则化比L2正则化效果更好,因为回归目标是无边界的,L2正则化要求对学习率更微小的调整,为了网址梯度爆炸,而smooth方程的L1正则化则消除了这一敏感性。
超参数平衡了分类与定位两个损失函数,我们归一化了v,使所有的v的平均值为0,方差为1。所有的实验中使用超参数的值为1。
Mini-batch sampling
在微调时,每一个随机梯度下降的mini-batch训练时,都选用N=2张图片,选择随机统一,mini-batch的尺寸为128,每一个图片都采样64个RoI,选用25%的IoU至少为0.5的RoI。
同时使用数据增强,每张图片有50%的可能性进行水平翻转。
Back-propagation through RoI pooling layers.
假设每一次Mini-batch都只有一张图片(N=1)。FastRCNN论文详解
SGD hyper-parameters
初始化使用高斯分布,分类的初始化为平均值为0,标准差为0.01;边界框回归的初始化为平均值为0,标准差为0.001。偏差初始化为0,每一层的学习率为权值为1,偏差为2,全局学习率为0.001,训练30k个mini-batch之后学习率下降为0.0001并且训练另外的10k个mini-batch。当训练更大的样本时,我们使用Momentum,初始化为0.9,且下降的参数为0.0005(权值与偏差)。
实验
-
在VOC 2007 test数据集上进行测试实验,所有的算法均使用VGG16作为预训练网络:

07: VOC07 trainval;
07 \ diff: 07 without “difficult” examples;
07+12: union of 07 and VOC12 trainval -
在VOC 2010 test数据集上进行测试实验,除BabyLearning以外,所有的算法均使用VGG16作为预训练网络:

Prop.: proprietary dataset;
12+seg: 12 with segmentation annotations;
07++12: union of VOC07 trainval, VOC07 test, and VOC12 trainval. -
在VOC 2010 test数据集上进行测试实验,除BabyLearning与NUS NIN c2000以外,所有的算法均使用VGG16作为预训练网络:

Unk.: unknown. -
比较Fast R-CNN, R-CNN, 与 SPPnet三种算法的运行时长:
-
微调对结果的影响:

-
多任务训练相对于单独分类训练,提高了纯分类精度。

-
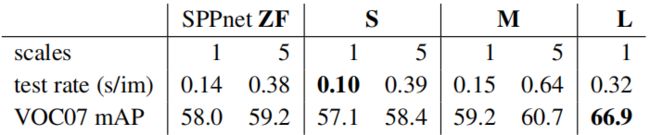
多尺度训练与单一尺寸训练对比:
-
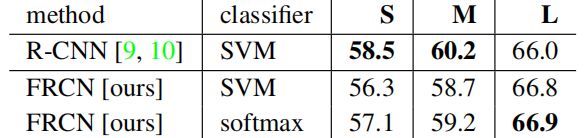
分类器对比: