卷积神经网络的基础——LeNet网络详解
文章目录
- 1 卷积神经网络的出世
- 2 卷积神经网络的发展
- 3 全连接神经网络
-
- 3.1 反向传播是什么呢?
- 4 Pytorch实现的LeNet网络
-
- 4.1 注意点
- 4.2 代码
- 4.3 Con2d 源代码
写在前面:研究生的自我修养,就是不断在看论文——看网络原理——看最前沿的算法之间反复横跳!
本文适合有一定深度学习的童鞋学习,是自己第N次学习的记录~~
1 卷积神经网络的出世
CNN最早的雏形就是1998年由LeCun提出的LeNet网络!
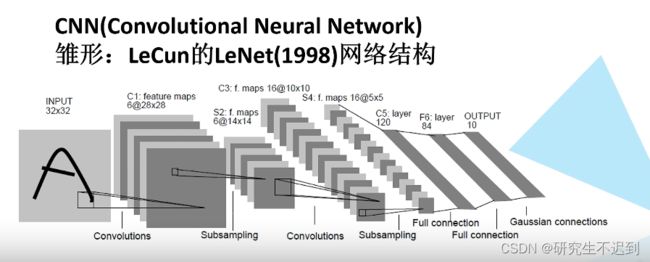
目前对于卷积神经网络,一个比较泛化的定义就是“含有卷积层的神经网络,都可以称为是卷积神经网络~”
2 卷积神经网络的发展
- 可以说,卷积神经网络是在2012年成为热点!

3 全连接神经网络
Fully Connected(FC)是CNN、LSTM、RNN等神经网络的基础,最基础的原理都是反向传播
定位:全连接网络可能不是最常用的,但是是最基础的。 至少包括一个隐藏层和一个输出层。
3.1 反向传播是什么呢?
是输出值Y_pred与真实值Y至今的损失Loss。整个网络的训练过程就是不断缩小损失Loss的过程。
整个过程可以称为梯度下降算法。
4 Pytorch实现的LeNet网络
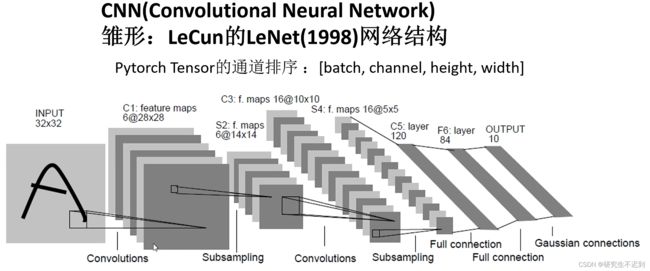
4.1 注意点
- LeNet是使用的灰度图像,但是我们实现的时候是用的彩色图片。
- Pytorch Tensor的通道排序:[batch, channek, height, width]
- LeNet的网络结构很简单,一个卷积层,一个下采样层,一个卷积层,一个下采样层, 和三个全连接层。
4.2 代码
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = x.view(-1, 32*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
4.3 Con2d 源代码
最常用的参数就是前五个!
(1)in_channels:int 代表输入数据的C(channel)
(2)out_channels:int 代表输出数据的C(channel)
(3) kernel_size 代表的是卷积核的大小, kernel_size=5就代表5×5的卷积核,如果输入数据是7×7的,输出的数据就是3×3的。【如果这里看不明白的话,可能就要补一下CNN基础啦。5/2=2,上下左右都要减去2,所以就变成5×5了】
(4)stride 步长,表示每次移动的数目
(5)padding 考虑到每次卷积之后,边缘部分都会由于卷积核的存在而损失信息,所以在边缘添加padding,使得卷积前后的尺寸(size)不变
- 举个例子:如果输入数据是:
b×3×32×32,那么经过self.conv1 = nn.Conv2d(3, 16, 5)就会输出 b×16×
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: _size_2_t,
stride: _size_2_t = 1,
padding: Union[str, _size_2_t] = 0,
dilation: _size_2_t = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros', # TODO: refine this type
device=None,
dtype=None
) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
kernel_size_ = _pair(kernel_size)
stride_ = _pair(stride)
padding_ = padding if isinstance(padding, str) else _pair(padding)
dilation_ = _pair(dilation)
super(Conv2d, self).__init__(
in_channels, out_channels, kernel_size_, stride_, padding_, dilation_,
False, _pair(0), groups, bias, padding_mode, **factory_kwargs)