TextCNN文本分类(Pytorch实现)
使用textCNN进行文本分类
介绍论文的主要参数和意义
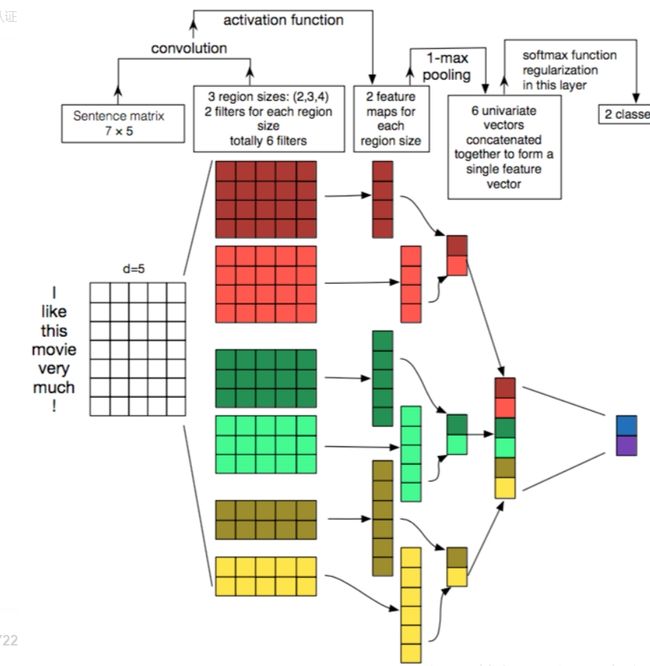
图中,句子的长度是7,每个字的维度是5,我们可以通过nn.Embedding(vocab_num, 5)可以构建;其次图中第二部分一共有6个矩阵,主要是分为3个块(卷积核),在代码中可构建一个类来表示;然后,得到卷积后的结果;接着通过最大池化层输出最大值;最后,进行拼接,进行分类。(下文会介绍具体变化过程)
读取数据和构建数据迭代器
读取数据
数据保存在txt文件中,其格式如下:
中华女子学院:本科层次仅1专业招男生 3 两天价网站背后重重迷雾:做个网站究竟要多少钱 4 东5环海棠公社230-290平2居准现房98折优惠 1 卡佩罗:告诉你德国脚生猛的原因 不希望英德战踢点球 7
def read_data(train_test, num=None):
# num的意义在于可以选择部分数据,进行切分
with open(os.path.join('..', 'data', train_test + '.txt'), 'r', encoding='utf-8') as f:
all_data = f.read().split('\n')
all_texts = []
all_labels = []
for data in all_data:
if data:
t, l = data.split('\t')
all_texts.append(t)
all_labels.append(l)
if num is None:
return all_texts, all_labels
else:
return all_texts[:num], all_labels[:num]返回所有的文本和标签(在该数据集中,一共有10个类别)
构建word2index
def build_corpus(texts):
word_2_index = {'UNK': 0, 'PAD': 1}
for text in texts:
for word in text:
if word not in word_2_index:
word_2_index[word] = len(word_2_index)
return word_2_index, list(word_2_index)构建数据迭代器
class TextDataset(Dataset):
def __init__(self, all_texts, all_labels, word_2_index, max_len, ):
self.all_texts = all_texts
self.all_labels = all_labels
self.word_2_index = word_2_index
self.max_len = max_len
def __getitem__(self, item):
text = self.all_texts[item][:self.max_len]
text_idx = [self.word_2_index.get(i, 0) for i in text]
text_idx = text_idx + [1] * (self.max_len - len(text))
label = int(self.all_labels[item])
return torch.tensor(text_idx), torch.tensor(label)
def __len__(self):
return len(self.all_texts)构建TextCNN模型的卷积部分
1、输入部分
self.cnn = nn.Conv2d(1, out_channel, kernel_size=(kernel_s, embed_num))使用CNN时,文本类型的数据和图像类型的数据。在构建字向量的时候,我们会产生一个二维的矩阵(seq_len,embedding_dim),但是nn.Conv2d中,我们需要人为的设定,in_channels=1,所以在后续数据的处理过程中,我们需要加一个维度1,使其形状为(batch_size,1,max_len, embedding_dim)
如:
output = self.emb(batch_idx)
output = output.unsqueeze(dim=1)2、卷积部分
self.cnn = nn.Conv2d(1, out_channel, kernel_size=(kernel_s, embed_num))out_channel就是输出的通道数,也是卷积核的个数,在该论文中,卷积核的个数是2(我们也可以自己进行参数的改变)
例如:本文中维度是:7*5,通过卷积之后,获得2个(4*1,5*1,6*1)的矩阵,如何得来的? 第一个维度:4 = 7 - kernel_s + 1;5 = 7 - kernel_s + 1;6 = 7 - kernel_s + 1; 第二个维度:1 = 5 - embed_num + 1 所以,kernel_size=(kernel_s, embed_num)的第二个维度需要和词向量维度相同,才会输出最后结果为1维。
3、最大池化层(MaxPool1d)
MaxPool1d的输入输出,由下图可以看出,MaxPool1d主要是改变最后一维的大小。
self.maxp = nn.MaxPool1d(kernel_size=(max_lens - kernel_s + 1))
这里kernel_size是滑动窗口的大小
当卷积核大小为:4*5,得到 输出为:4*1,此时, MaxPool1d(kernel_size=(max_lens - kernel_s + 1))----kernel_size=(7 - 4 + 1=4),也就是在4*1的矩阵中,划出一个窗口为4的内容,从中选取最大值。
在代码中,我们经过cnn卷积得到的维度是output.shape = torch.Size([1, 2, 6, 1])
但是,最大池化层我们需要2或者3个维度,所以,最后的1维去掉需要去掉
output1 = output.squeeze(3) output2 = self.maxp(output1)
 最后,我们需要将最终的输出进行拼接,得到一个6*1的矩阵
最后,我们需要将最终的输出进行拼接,得到一个6*1的矩阵
在最大池化之后,维度变成===batch*2*1,因为需要拼接,所以,需要将池化层维度进行改变
output2 = self.maxp(output1) return output2.squeeze(dim=-1) # 去掉1维的内容
4、cnn代码
class Block(nn.Module):
def __init__(self, out_channel, max_lens, kernel_s, embed_num):
super(Block, self).__init__()
# 这里out_channel是卷积核的个数
self.cnn = nn.Conv2d(1, out_channel, kernel_size=(kernel_s, embed_num))
self.act = nn.ReLU()
self.maxp = nn.MaxPool1d(kernel_size=(max_lens - kernel_s + 1))
def forward(self, emb):
# emb.shape = torch.Size([1, 7, 5]),我们需要加一个维度1,来达到输入通道要求
output = self.cnn(emb)
# output.shape = torch.Size([1, 2, 6, 1])
output1 = self.act(output)
# 最大池化我们2-3个维度,所以,最后的1需要去掉
output1 = output1.squeeze(3)
output2 = self.maxp(output1)
return output2.squeeze(dim=-1)构建TextCNN模型
1、完整代码
class TextCnnModel(nn.Module):
def __init__(self, vocab_num, out_channel, max_lens, embed_num, class_num):
super(TextCnnModel, self).__init__()
self.emb = nn.Embedding(vocab_num, embed_num)
self.block1 = Block(out_channel, max_lens, 2, embed_num)
self.block2 = Block(out_channel, max_lens, 3, embed_num)
self.block3 = Block(out_channel, max_lens, 4, embed_num)
self.classifier = nn.Linear(3 * out_channel, class_num)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, batch_idx, batch_label=None):
output = self.emb(batch_idx)
output = output.unsqueeze(dim=1)
b1 = self.block1(output)
b2 = self.block2(output)
b3 = self.block3(output)
feature = torch.cat([b1, b2, b3], dim=1)
pre = self.classifier(feature)
if batch_label is not None:
loss = self.loss_fn(pre, batch_label)
return loss
else:
return torch.argmax(pre, dim=-1)注意:
self.classifier = nn.Linear(3 * out_channel, class_num)
为什么是 (3 * out_channel)?
先解释3这个参数。是因为在论文中分别使用了三次卷积,在上面代码部分(构建TextCNN模型)中有b1-3 = self.block1-3(output);如果你增加卷积块,那么就要改变这个参数!
再解释out_channel这个参数。这个也就是你卷积核的个数,你有几个卷积核,就会有几个输出。在文中,卷积核的个数是2,那么每次输出的结果就会有2个矩阵
最后,将三个卷积块的结果拼接起来,就会得到 (3 * out_channel)!
所以,分类器的参数为nn.Linear(3 * out_channel, class_num)
class_num是分类的类别
完整代码
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from tqdm import tqdm
import os
# 读取数据
def read_data(train_test, num=None):
with open(os.path.join('..', 'data', train_test + '.txt'), 'r', encoding='utf-8') as f:
all_data = f.read().split('\n')
all_texts = []
all_labels = []
for data in all_data:
if data:
t, l = data.split('\t')
all_texts.append(t)
all_labels.append(l)
if num is None:
return all_texts, all_labels
else:
return all_texts[:num], all_labels[:num]
# 构建词编码
def build_corpus(texts):
word_2_index = {'UNK': 0, 'PAD': 1}
for text in texts:
for word in text:
if word not in word_2_index:
word_2_index[word] = len(word_2_index)
return word_2_index, list(word_2_index)
# 构建数据类
class TextDataset(Dataset):
def __init__(self, all_texts, all_labels, word_2_index, max_len, ):
self.all_texts = all_texts
self.all_labels = all_labels
self.word_2_index = word_2_index
self.max_len = max_len
def __getitem__(self, item):
text = self.all_texts[item][:self.max_len]
text_idx = [self.word_2_index.get(i, 0) for i in text]
text_idx = text_idx + [1] * (self.max_len - len(text))
label = int(self.all_labels[item])
return torch.tensor(text_idx), torch.tensor(label)
def __len__(self):
return len(self.all_texts)
# 构建模型
class Block(nn.Module):
def __init__(self, out_channel, max_lens, kernel_s, embed_num):
super(Block, self).__init__()
# 这里out_channel是卷积核的个数
self.cnn = nn.Conv2d(1, out_channel, kernel_size=(kernel_s, embed_num))
self.act = nn.ReLU()
self.maxp = nn.MaxPool1d(kernel_size=(max_lens - kernel_s + 1))
def forward(self, emb):
# emb.shape = torch.Size([1, 7, 5]),我们需要加一个维度1,来达到输入通道要求
output = self.cnn(emb)
# output.shape = torch.Size([1, 2, 6, 1])
output1 = self.act(output)
# 最大池化我们2-3个维度,所以,最后的1需要去掉
output1 = output1.squeeze(3)
output2 = self.maxp(output1)
return output2.squeeze(dim=-1)
class TextCnnModel(nn.Module):
def __init__(self, vocab_num, out_channel, max_lens, embed_num, class_num):
super(TextCnnModel, self).__init__()
self.emb = nn.Embedding(vocab_num, embed_num)
self.block1 = Block(out_channel, max_lens, 2, embed_num)
self.block2 = Block(out_channel, max_lens, 3, embed_num)
self.block3 = Block(out_channel, max_lens, 4, embed_num)
self.classifier = nn.Linear(3 * out_channel, class_num)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, batch_idx, batch_label=None):
output = self.emb(batch_idx)
output = output.unsqueeze(dim=1)
b1 = self.block1(output)
b2 = self.block2(output)
b3 = self.block3(output)
feature = torch.cat([b1, b2, b3], dim=1)
pre = self.classifier(feature)
if batch_label is not None:
loss = self.loss_fn(pre, batch_label)
return loss
else:
return torch.argmax(pre, dim=-1)
if __name__ == '__main__':
train_text, train_label = read_data('train')
dev_text, dev_label = read_data('dev')
word_2_index, _ = build_corpus(train_text)
batch_size = 32
max_len = 32
epochs = 10
out_channel = 2
embed_num = 50
lr = 2e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
train_set = TextDataset(train_text, train_label, word_2_index, max_len)
train_loader = DataLoader(train_set, batch_size)
dev_set = TextDataset(dev_text, dev_label, word_2_index, max_len)
dev_loader = DataLoader(dev_set, batch_size)
model = TextCnnModel(len(word_2_index), out_channel, max_len, embed_num, len(set(train_label))).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr)
for e in range(epochs):
model.train()
for batch_idx, batch_label in tqdm(train_loader):
loss = model(batch_idx.to(device), batch_label.to(device))
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f'epoch:{e},loss={loss:.3f}')
model.eval()
right_num = 0
for batch_idx, batch_label in tqdm(dev_loader):
pre = model(batch_idx.to(device))
batch_label = batch_label.to(device)
right_num += torch.sum(pre==batch_label)
print(f'acc = {right_num/len(dev_text)*100:.3f}%')