数据仓库笔记
理论
数据仓库
1988年,IB提出信息仓库。1991年比尔.恩门出版《Building the data warehouse》,标志数据仓库概念确立。凭借着这本书,Bill Inmon被称为数据仓库之父。数据仓库(DataWarehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化的(Time Variant)数据集合,用于支持管理决策(Decision-Making Support)。
数据仓库是位于多个数据库上的大容量存储库。它的作用是存储大量的结构化数据,并能进行频繁和可重复的分析。通常情况下,数据仓库用于汇集来自各种结构化源的数据以进行分析,通常用于商业分析目的。(注意:一些数据仓库也可以处理非结构化数据,这个不是我们的重点)。
数据仓库四大特征
- 面向主题的 :传统是面向应用。主题是信息系统中的数据综合、归类并进行分析利用的抽象;某一宏观分析领域所涉及的分析对象。(例如:销售分析就是分析领域,数据仓库主题就是“销售分析”)
- 集成的 :数据仓库中的数据是为分析服务的,而分析需要多种广泛的不同数据源以便进行比较、鉴别,数据仓库的数据是从原有的分散的多个数据库、数据文件、用户日志中抽取来的,数据来源可能既有内部数据又有外部数据。(如:客户价值分析,需要存款业务、贷款业务、信用卡业务、理财业务等)
操作型数据与分析型数据之间差别很大:
- 数据仓库的每一个主题所对应的源数据,在原有的各分散数据库中有重复和不一致的地方,且来源于不同的联机系统的数据与不同的应用逻辑捆绑在一起.
- 数据仓库中的数据很难从原有数据库系统直接得到。数据在进入数据仓库之前,需要经过统一与综合
- 稳定的 :数据仓库数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,以及基于这些快照进行统计、综合和重组的导出数据。数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。数据经加工和集成进入数据仓库后是极少更新的,通常只需要定期的加载和更新。
- 反映历史变化的:数据仓库包含各种粒度的历史数据。数据仓库中的数据可能与某个特定日期、星期、月份、季度或者年份有关。虽然数据仓库不会修改数据,但并不是说数据仓库的数据是永远不变的。数据仓库的数据也需要更新,以适应决策的需要。数据仓库的数据随时间的变化表现在以下几个方面:
1.数据仓库的数据时限一般要远远长于操作型数据的数据时限
2.业务系统存储的是当前数据,而数据仓库中的数据是历史数据
3.数据仓库中的数据是按照时间顺序追加的,都带有时间属性
数据仓库作用
- 整合企业业务数据,建立统一的数据中心;
- 产生业务报表,了解企业的经营状况;
- 为企业运营、决策提供数据支持;
- 可以作为各个业务的数据源,形成业务数据互相反馈的良性循环;
- 分析用户行为数据,通过数据挖掘来降低投入成本,提高投入效果;
- 开发数据产品,直接或间接地为企业盈利;
数据仓库与数据库的区别
数据库与数据仓库的区别实际讲的是 OLTP 与 OLAP 的区别。
- 数据仓库主要用于解决企业级的数据分析问题或者说管理和决策
- 数据仓库是为分析数据而设计,数据库是为捕获和存储数据而设计
- 数据仓库是面向分析,面向主题设计的,即信息是按主题进行组织的,属于
分析型;数据库是面向事务设计的,属于操作型
数据仓库在设计是有意引入数据冗余(目的是为了提高查询的效率),采用反范式的方式来设计;数据库设计是尽量避免冗余(第三范式),一般采用符合范式 的规则来设计 - 数据仓库较大,数据仓库中的数据来源于多个异构的数据源,而且保留了企业的 历史数据;数据库存储有限期限、单一领域的业务数据
数据仓库是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的大型数据库。
| 对比内容 | 数据库 | 数据仓库 |
|---|---|---|
| 数据内容 | 近期值、当前值 | 历史的、归档的数据 |
| 数据目标 | 面向业务操作 | 面向管理决策、面向分析(主题) |
| 数据特性 | 动态频繁更新 | 静态、不能直接更新;定时添加数据 |
| 数据结构 | 高度结构化、满足第三范式 | 简单的、冗余的、满足分析的 |
| 使用频率 | 高 | 低 |
| 数据访问量 | 访问量大;每次访问的数据量少 | 访问量小;每次访问的数据量大 |
| 对响应时间的要求 | 高 | 低(不敏感) |
数据集市(数据仓库子集)
数据仓库(DW)是一种反映主题的全局性数据组织。但全局性数据仓库往往太大,在实际应用中将它们按部门或业务分别建立反映各个子主题的局部性数据组织,即数据集市(Data Mart),有时也称它为部门数据仓库。
数据集市:可以按主体域组织划分,用于支持部门级的数据分析与决策。(如商品销售数仓:采购数据集、库存数据集和销售数据集市)
数据集市仅仅是数据仓库的某一部分,实施难度大大降低,并且能够满足企业内部部分业务部门的迫切需求,在初期获得了较大成功。但随着数据集市的不断增多,这种架构的缺陷也逐步显现。企业内部独立建设的数据集市由于遵循不同的标准和建设原则,以致多个数据集市的数据混乱和不一致,形成众多的数据孤岛。
企业发展到一定阶段,出现多个事业部,每个事业部都有各自数据,事业部之间的数据往往都各自存储,各自定义。每个事业部的数据就像一个个孤岛一样无法(或者极其困难)和企业内部的其他数据进行连接互动。这样的情况称为数据孤岛,简单说就是数据间缺乏关联性,彼此无法兼容。
数据仓库建模方法
- 性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的I/O吞吐
- 成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复 用,极大地降低大数据系统中的存储和计算成本
- 效率:良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率
- 质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性
ER模型(大型)
需要全面了解整个企业业务和数据 ; 实施周期非常长 ; 对建模人员的能力要求非常高。
釆用ER模型建设数据仓库模型的出发点是整合数据,将各个系统中的数据以整个企业角度按主题进行相似性组合和合并,并进行一致性处理,为数据分析决策服务,但是并不能直接用于分析决策。其建模步骤分为三个阶段:
- 高层模型:一个高度抽象的模型,描述主要的主题以及主题间的关系,用于描述 企业的业务总体概况
- 中层模型:在高层模型的基础上,细化主题的数据项
- 物理模型(也叫底层模型):在中层模型的基础上,考虑物理存储,同时基于性能 和平台特点进行物理属性的设计,也可能做一些表的合并、分区的设计等。
维度模型(小型、敏捷)
维度建模从分析决策的需求出发构建模型,为分析需求服务,重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。代表星型模型、雪花模型。设计分为以下步骤:
- 选择需要进行分析决策的
业务过程。业务过程可以是:单个业务事件(支付、退款);某个事件的状态(当前账户余额);一系列相关业务事件组成的业务流程。 - 选择数据的
粒度。分析需要细分的程度 - 识别
维表。选择好粒度之后,就需要基于此粒度设计维表,包括维度属性,用于分析时进行分组和筛选 - 选择事实。确定分析需要衡量的
指标
大多数企业实施数据仓库的经验说明:在不太成熟、快速变化的业务面前,构建ER模型的风险非常大,不太适合去构建ER模型。而维度建模对技术要求不高,快速上手,敏捷迭代,快速交付;更快速完成分析需求,较好的大规模复杂查询的响应性能。
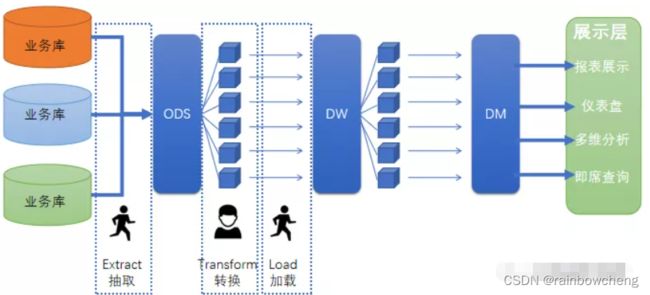
数据仓库分层
数据仓库更多代表的是一种对数据的管理和使用的方式,它是一整套包括了数据建模、ETL(数据抽取、转换、加载)、作用调度等在内的完整的理论体系流程。
分层的主要原因是在管理数据的时候,能对数据有一个更加清晰的掌控
- 清晰的数据结构:作用域
- 将复杂的问题简单化:任务分解成多个步骤完成,每层只处理单一问题,比较容易理解和维护。
- 减少重复开发:开发一些通用的中间层数据,能减少极大的重复计算。
- 屏蔽原始数据的异常:不必改一次业务就需要重新接入数据。
- 数据血缘的追踪:一个业务表来源很多,如果一张来源出问题,借助血缘最终能快速准确定位问题,并清楚它的危害范围。
| 层 | 说明 |
|---|---|
| ADS 应用数据层 | ADS (DM):汇总得到业务相关的指标或数据 |
| DW 数据仓库层 | DWS 层:数据服务层。对DWD层的数据操做轻度的汇总,得到业务汇总表或宽表 |
| DW 数据仓库层 | DWD 层:数据明细层。对ODS层的数据做一定的数据清洗和转换。 |
| ODS 数据运营层 | ODS 层:离线或准实时数据接入(业务数据、日志数据、第三方数据) |
ODS层数据的主要来源包括:
- 业务数据库。可使用DataX、Sqoop等工具来抽取,每天定时抽取一次;在实时 应用中,可用Canal监听MySQL的 Binlog,实时接入变更的数据;
- 埋点日志。线上系统会打入各种日志,这些日志一般以文件的形式保存,可以用 Flume 定时抽取;
- 其他数据源。从第三方购买的数据、或是网络爬虫抓取的数据;
DW层数据
- 业务相对简单和独立,可以将DWD、DWS进行合并
- 公共维度层(DIM):基于维度建模理念思想,建立一致性维度;(贯穿DWD和DWS)
- TMP层 :临时层,存放计算过程中临时产生的数据;(贯穿DWD和DWS)
ELT 改变是E、T、L彻底的解耦了。解耦之后好处多多,比如突破性能瓶颈、程序简化、组件替换、维护成本降低等等。
------
所以现在很多新业务中,都在弱化建模,强化效率,用的其实就是 ELT 的逻辑。
数据直接入湖,然后写个脚本扔 Spark 里跑,直接拖张宽表扔库里,然后怼到一个报表展示工具完事了
数据仓库架构
- 离线大数据架构:HDFS存储,hive、mr、spark进行离线计算的传统大数据架构;
- Lambda架构:在离线大数据架构的基础上增加新链路用于实时数据处理,需要维护离线处理和实时处理两套代码;
Kappa架构:批流合一,离线处理和实时处理整合成一套代码,运维成本小,这就是现今flink之所以火的原因。Kappa架构已成为数据仓库架构的新趋势。- 计算框架选型:storm/flink等实时计算框架,强烈推荐flink,其『批量合一』的特性及活跃的开源社区,有逐渐替代spark的趋势。
- 数据存储选型:首要考虑查询效率,其次是插入、更新等问题,可选择apache druid,不过在数据更新上存在缺陷,选型时注意该问题频繁更新的数据建议不要采用该方案。当然存储这块需要具体问题具体分析,不同场景下hbase、redis等都是可选项。
- 实时数仓分层:为更好的统一管理数据,实时数仓可采用离线数仓的数据模型进行分层处理,可以分为实时明细层写入druid等查询效率高的存储方便下游使用;轻度汇总层对数据进行汇总分析后供下游使用。
- 数据流转方案:实时数仓的数据来源可以为kafka消息队列,这样可以做到队列中的数据即可以写入数据湖或者数据仓库用于批量分析,也可以实时处理,下游可以写入数据集市供业务使用。
数据湖与数据仓库差异:
数据湖就是一个集中存储数据库,用于存储所有结构化和非结构化数据。我们将所有数据移动到数据湖中不进行转换。数据湖中的每个数据元素都会分配一个唯一的标识符,并对其进行标记,以后可通过查询找到该元素。
- 在储存方面上:数据湖中数据为非结构化的,所有数据都保持原始形式,并且仅在分析时再进行转换。数据仓库就是数据通常从事务系统中提取。在将数据加载到数据仓库之前,会对数据进行清理与转换。
在数据抓取中数据湖就是捕获半结构化和非结构化数据。而数据仓库则是捕获结构化数据并将其按模式组织。数据湖的目的就是数据湖非常适合深入分析的非结构化数据。数据科学家可能会用具有预测建模和统计分析等功能的高级分析工具。而数据仓库就是数据仓库非常适用于月度报告等操作用途,因为它具有高度结构化- 在架构方面上:数据湖通常是在存储数据
之后定义架构。使用较少的初始工作并提供更大的灵活性。在数据仓库中存储数据之前定义架构。这需要你清理和规范化数据,这意味着架构的灵活性要低不少。
其实数据仓库和数据湖是我们都需要的地方,数据仓库非常适用于业务实践中常见的可重复报告。当我们执行不太直接的分析时,数据湖就很有用。
Kappa架构
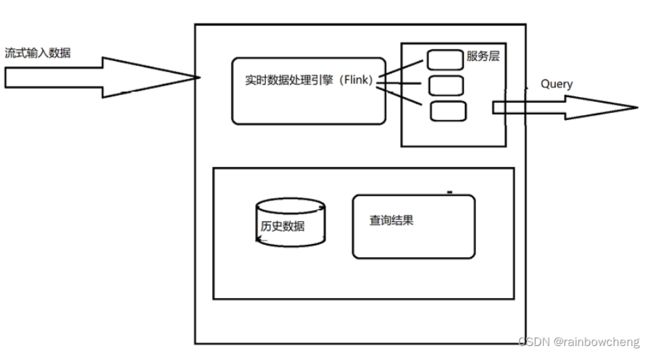
Kappa架构的核心思想包括以下三点:
1、用Kafka或类似的分布式队列保存数据,需要几天数据量就保存几天。
2、当需要全量计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个结果存储中。
3、当新的实例完成后,停止老的流计算实例,并把老的结果删除。
数据仓库模型
事实表与维度表
事实数据表的主要特点是包含数字数据(事实),并且这些数字信息可以汇总,以提供有关单位作为历史的数据。事实表的粒度决定了数据仓库中数据的详细程度。
事实表根据数据粒度分为:
- 事务事实表:事务事实表记录的事务层面的事实,保存的是最原子的数据,也称“原子事实表”。数据的粒度通常是每个事务一条记录。数据插入就不再进行更改,其更新方式为增量更新(类似Binlog)。如订单表,通过事务事实表,还可以建立聚集事实表,为用户提供高性能的分析。
- 周期快照事实表:以具有规律性的、可预见的时间间隔来记录事实,时间间隔如每天、每月、每年等等。每个时间段一条记录(是在事务表上建立聚集表)。如销售日快照表(无论当天是否有销售发生,都记录一条),历史至今、自然年至今、季度至今等。
- 累计快照事实表:周期快照事实表记录的确定的周期的数据,而累积快照事实表记录的不确定的周期的数据。累积快照事实表代表的是完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点。另外,它还会有一个用于指示
最后更新日期的附加日期字段。由于事实表中许多日期在首次加载时是不知道的,所以必须使用代理关键字来处理未定义的日期,而且这类事实表在数据加载完后,是可以对它进行更新的,来补充随后知道的日期信息。如本周,本月,本年累计销售表
维度表(维表)可以看作是用来分析数据的角度,纬度表中包含事实数据表中事实记录的特性。有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息。时间、地域、物体维度。
事实是关注内容(销售额、量);维度表是观察事务的角度(时间、地区)
人物、地点、时间(维度)发生什么事情(事实内容)。
星型模型
星型模是一种多维的数据关系,它由一个事实表和一组维表组成。事实表中包含了大量数据,没有数据冗余;
维表是逆规范化的,包含一定的数据冗余。
雪花模型
雪花模式是星型模型的变种,维表是规范化的,模型类似雪花的形状。如地区维度存的是省市的ID,关联地理基本表。
星型模型存在数据冗余,所以在查询统计时只需要做少量的表连接,查询效率高;在数据冗余可接受的情况下,实际使用星型模型比较多。
事实星座
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
元数据
元数据(Metadata)是关于数据的数据。元数据打通了源数据、数据仓库、数据应用,记录了数据从产生到消费的全过程。元数据就相当于所有数据的地图,有了这张地图就能知道数据仓库中:
- 有哪些数据
- 数据的分布情况
- 数据类型
- 数据之间有什么关系
- 哪些数据经常被使用,哪些数据很少有人光顾
业内通常把元数据分为以下类型:
- 技术元数据:库表结构、数据模型、ETL程序、SQL程序等
- 业务元数据:业务指标、业务代码、业务术语等
- 管理元数据:数据所有者、数据质量、数据安全等
实时数仓
背景
随着互联网的发展,数据的时效性对企业的精细化运营越来越重要, 商场如战场,在每天产生的海量数据中,如何能实时有效的挖掘出有价值的信息, 对企业的决策运营策略调整有很大帮助。此外,随着5G 技术的成熟、广泛应用, 对于互联网、物联网等数据时效性要求非常高的行业,企业就更需要一套完整成熟的实时数据体系来提高自身的行业竞争力。
随着数据时效性在企业运营中的重要性日益凸现,例如:
实时推荐;精准营销;广告投放效果;实时物流。
数据的实时处理能力成为企业提升竞争力的一大因素,最初阶段企业主要采用来一个需求,编写一个实时计算任务的方式来处理实时数据,随着需求的增多,计算任务也相应增多,并且不同任务的开发人员不同,导致开发风格差异化,该阶段的实时数据处理缺乏统一的规划,代码风格差异化严重,在维护成本和开发效率上有很大障碍。
为避免上述问题,人们参照数据仓库的概念和模型来重新规划和设计实时数据处理,在此基础上产生了实时数据仓库(实时数仓)。
简介
实时计算架构
收集层:Binlog(业务日志)、loT(物联网)、后端服务日志(系统日志)
经过日志收集团队和 DB 收集团队的处理,数据将会被收集到 Kafka 中。这些数据不只是参与实时计算,也会参与离线计算。
存储层:Kafka(实时增量数据)、HDFS(状态数据存储和全量数据存储-持久层)、HBASE(维度数据存储)
引擎层:实时处理框架。包含TPframe、Common Utils、组件、Storm、Flink。
平台层:数据、任务和资源三个角度去管理 — 集群资源
应用层:底层架构的应用场景。实时数仓、机器学习、数据同步和事件驱动应用。
流量
流量数据的产生:不同通道的埋点和不同页面的埋点产生数据。
采集:按照业务维度划分不同的业务通道。
应用:1、流的方式提供下游业务使用 2、流量方面的分析。
广告实时效果验证
[ PV、SPV、CPV、CPV曝光、CPV点击 ] —> Kafka —> Flink (join by requestID) —> ClickHouse/Druid/Kudu —> [ 实际CTR、预估CTR、RR、CPC、CR ]
CPV(展示广告) 又称富媒体广告,按展示付费,即按投放广告网站的被展示次数计费,网站被打开一次计一次费,按千次IP计费。(国内CPV广告常见是网页右下角弹窗,例如高仿QQ消息框)
CPC与CTR: 在现在的广告业 CPC 这个指标很难用来跟效果扯上关系,更多的时候是计费单位了。而CTR 有的时候还是会作为效果的工具,大多用来衡量两次投放的不同投放策略、优化策略、创意的好坏。总之这两个指标通常都是必须提供的基础数据;
到达时间预估
商家、骑手和用户等多维度数据评估
作用
广告流量实时统计: 生成动态黑名单
恶意刷单:一旦发现恶意刷单时进行实时告警
基于动态黑名单进行点击行为过滤 计算每隔5分钟统计最近1小时内各广告的点击量 计算每天各省的热门广告 计算每天各广告最近1小时内的点击趋势
订单交易分析:
每隔5分钟统计最近1小时内的订单交易情况,要求显示城市、省份、交易总金额、订单总数
每隔5分钟统计最近1小时各省内交易金额排名前3名的城市,要求显示省份,城市,订单数,交易金额
渠道分析:
点击来源:从不同的维度分析用户是从哪里点进来的
渠道质量:针对用户进行以下几方面分析:
访问时长、是否产生消费、首次产生消费的金额、收藏、访问页面数(PV)
风险控制:
交易支付异常:当检测到交易异常时进行实时告警
实例:每5分钟统计最近1小时内的订单交易情况
每隔5分钟统计最近1小时内的订单交易情况,要求显示城市、省份、交易总金额、订单总数—增量统计。
1、读取数据源(input)
input1:dim_lagou_area(地域宽表) — HBase
input2:lagou_trade_orders — kafka
2、对input进行transformation(转化)
input1:区域id, 区域的名字,城市的id,城市的名字,省份的id,省份的名字。
input2: 数据格式:json。获取区json数据中的如下四个字段的数据data、type、database、table。放到tableObject类。 把dataInfo中的数据拿出我们想要的字段 orderId:59,orderNo:“23a0b124546”,userId:52,status:2,totalMoney:5998.00,areaId:“370211”。把这几个字段包装到TradeOrder样例类中。把订单数据根据areaId进行分组。
3、timeWindow(1小时,5分钟)
ODS : --增量的数据—canal将mysql的bin_log放在kafka的test中。
INSERT INTO `lagou_trade_orders` VALUES ('1', '23a0b124546', '98', '2', '0.12', '10468.00', '2', '0', '370203', '0', '0', '1', '2', '2020-06-28 18:14:01', '2020-06-28 18:14:01', '2020-10-21 22:54:31');
kafka中的json日志:
{"data":[{"productId":"115908","productName":"索尼 xxx10","shopId":"100365","price":"297.80","isSale":"1","status":"0","categoryId" :"10395","createTime":"2020-07-12 13:22:22","modifyTime":"2020-09-27 13:22:22"}],"database":"dwshow","es":1601189647000,"id":458,"isDdl":false,"mysql Type": {"productId":"bigint(11)","productName":"varchar(200)","shopId":"bigint(11)","pr ice":"decimal(11,2)","isSale":"tinyint(4)","status":"tinyint(4)","categoryId":"i nt(11)","createTime":"varchar(25)","modifyTime":"datetime"},"old":null,"pkNames" :null,"sql":"","sqlType": {"productId":-5,"productName":12,"shopId":-5,"price":3,"isSale":-6,"status":-6," categoryId":4,"createTime":12,"modifyTime":93},"table":"lagou_product_info","ts" :1601189647015,"type":"INSERT"}
每隔5秒统计最近1小时内广告的点击量—增量
埋点–>日志文件 -->Kafka
{ "lagou_event": [{ "name": "goods_detail_loading", "json": { "entry": "2", "goodsid": "0", "loading_time": "92", "action": "3", "staytime": "10", "showtype": "0" },"time": 1595265099584 }, {"name": "notification", "json": { "action": "1", "type": "3" },"time": 1595341087663 }, {"name": "ad", "json": { "duration": "10", "ad_action": "0", "shop_id": "23", "event_type": "ad", "ad_type": "1", "show_style": "0", "product_id": "36", "place": "placecampaign2_left", "sort": "1" },"time": 1595276738208 }], "attr": { "area": "东莞", "uid": "2F10092A0", "app_v": "1.1.0", "event_type": "common", "device_id": "1FB872-9A1000", "os_type": "1.1", "channel": "广宣", "language": "chinese", "brand": "iphone-0" } }
10秒钟内连续点击10次–黑名单
.transformation .keyby .map .filter
实时统计各渠道来源用户数量
离线数仓设计
需求分析
电商行业技术特点:技术新;技术范围广;分布式;高并发、集群、负载均衡;海量数据;业务复杂;系统安全。
电商业务简介
- 网站前台。网站首页、商家首页、商品详细页、搜索页、会员中心、订单与支付相关页面、秒杀频道等;
- 运营商后台。运营人员的管理平台, 主要功能包括:商家审核、品牌管理、规格管理、模板管理、商品分类管理、商品审核、广告类型管理、广告管理、订单查询、商家结算等;
- 商家管理后台。入驻的商家进行管理的平台,主要功能包括:商品管理、订单查询统计、资金结算等功能;
数据仓库项目主要分析以下数据:
- 日志数据:启动日志、点击日志(广告点击日志)
- 业务数据库的交易数据:用户下单、提交订单、支付、退款等核心交易数据的分析
数据仓库项目分析任务:
- 会员活跃度分析主题
每日新增会员数;每日、周、月活跃会员数;留存会员数、留存会员率 - 广告业务分析主题
广告点击次数、广告点击购买率、广告曝光次数 - 核心交易分析主题
订单数、成交商品数、支付金额
数据埋点
数据埋点,将用户的浏览、点击事件采集上报的一套数据采集的方法。
通过这套方法,能够记录到用户在App、网页的一些行为,用来跟踪应用使用的状况,后续用来进一步优化产品或是提供运营的数据支撑,包括访问数、访客数、停留时长、浏览数、跳出率。这样的信息收集可以大致分为两种:页面统计、统计操作行为。
主流的埋点实现方法如下,主要区别是前端开发的工作量:
- 手动埋点:开发需要手动写代码实现埋点,比如页面ID、区域ID、按钮ID、按钮位置、事件类型(曝光、浏览、点击)等,一般需要公司自主研发的一套埋点框架
- 优点:埋点数据更加精准
- 缺点:工作量大,容易出错
- 无痕埋点:不用开发写代码实现的,自动将设备号、浏览器型号、设备类型等数据采集。主要使用第三方统计工具,如友盟、百度移动、魔方等
- 优点:简单便捷
- 缺点:埋点数据统一,不够个性化和精准
数据指标体系
指标:对数据的统计值。如:会员数、活跃会员数、会员留存数;广告点击量;订单金额、订单数都是指标。指标构成:基础指标(不可拆分) + [ 修饰词 ] + 时间段
指标体系:将各种指标系统的组织起来,按照业务模型、标准对指标进行分类和分层;
没有数据指标体系的团队内数据需求经常表现为需求膨胀以及非常多的需求变更。每个人都有看数据的视角和诉求,然后以非专业的方式创造维度/指标的数据口径。最终滚雪球似的搭建难以维护的数据仓库
三大原则
在建立指标体系时,要注重三个选取原则:准确、可解释、结构性
- 准确:核心数据一定要理解到位和准确,不能选错;
- 可解释:所有指标都要配上明确、详细的业务解释。如日活的定义是什么,是使用了App、还是在App中停留了一段时间、或是收藏或购买购买了商品;
- 结构性:能够充分对业务进行解读。如新增用户只是一个大数,还需要知道每个渠道的新增用户,每个渠道的新增转化率,每个渠道的新增用户价值等。
四个步骤
1.理清业务阶段及需求
创业期、上升期、成熟发展期,不同阶段关注的核心指标也是不同的。
- 业务前期:最关注用户量,此时指标体系应该紧密围绕用户量的提升来做各种维度拆解
- 业务中期:除了用户量走势,更重要是优化当前的用户量结构,如用户留存。
- 业务后期:关注产品变现能力和市场份额,关注收入指标、各种商业化模式的收入,同时做好市场份额和竞品的监控。
2.确定核心指标
3.核心指标维度拆解
核心指标的波动必然是某种维度的波动引起,要监控核心指标,本质上还是要监控维度核心指标。
在分析“进入APP用户数”指标时,要关注渠道转化率,分析用户从哪里来;同时用户通过哪种方式打开的,如通过点击桌面图标、点击通知栏、点击Push等。停留时长不同用户特征和行为特性。
漏斗模型:每一个环节的关键指标都可以通过公式的形式进行拆解,在根据拆解公式逐个分析对应的影响因素。
4.指标宣贯、存档、落地
宣贯:告知所有相关业务人员。一是为下一步工作做铺垫;二是以防甩锅。
存档:对指标口径的业务逻辑进行详细的描述并存档,只有明确、清晰的定义才能明白指标的具体含义。建立核心指标的相关报表,实际工作中,报表会在埋点前建好的,这样的话一旦版本上线就能立刻看到数据,而且也比较容易发现问题。
落地:搭建主要是由产品经理主导完成的,业务人员需要配合产品经理选择并确认指标,这也是在建立之初最重要的一点。
总体架构设计
1.技术方案选型
框架选型
Apache:完全开源免费;社区活跃;文档、资料详实。
第三方发行版(CDH / HDP / Fusion Insight华为):版本管理清晰;兼容性、安全性、稳定性上有增强;提供了部署、安装、配置工具,大大提高了集群部署的效率;运维简单。提供了管理、监控、诊断、配置修改的工具。
- CDH:最成型的发行版本,拥有最多的部署案例。
- HDP:100%开源,可以进行二次开发,但没有CDH稳定。
- Fusion Insight:华为基于hadoop2.7.2版开发的,坚持分层,解耦,开放的原则,得益于高可靠性,在全国各地政府、运营商、金融系统有较多案例。
软件选型
框架、软件尽量不要选择最新的版本,选择半年前左右稳定的版本
- 数据采集:DataX、Flume、Canal、Sqoop、Logstash、Kafka
- 数据存储:HDFS、HBase、Redis、Kafka
- 数据计算:Hive、MapReduce、Tez、Spark、Flink
- 调度系统:Airflow、azkaban、Oozie
- 元数据管理:Atlas
- 数据质量管理:Griffin
- 即席查询:Impala、Kylin、ClickHouse、Presto、Druid
- 其他:MySQL
Hadoop 、flume、Canal、Kafka、Flink、Mysql、HBase、Zookeeper、ClickHouse
服务器选型
选择物理机还是云主机
- 机器成本考虑:物理机的价格 > 云主机的价格
- 运维成本考虑:物理机需要有专业的运维人员;云主机的运维工作由供应商完成,运维相对容易,成本相对较低
集群规模规划
可以从计算能力(CPU、 内存)、存储量等方面着手考虑集群规模(假设:每台服务器20T硬盘,128G内存)。
假如:日活500w,每人每天100条日志,每条日志1K,不考虑历史数据以及半年不扩容,3个副本。
分析需要多大集群规模:数据=日志数据+业务数据
每天日志数据量:500W * 100 * 1K / 1024 / 1024 = 500G
半年需要的存储量:500G * 3 * 180 / 1024 = 260T
通常要给磁盘预留20-30%的空间(这里取25%): 260 * 1.25 = 325T
数据仓库应用有1-2倍的数据膨胀(这里取1.5):500T
结论:需要大约25个节点
2.系统逻辑架构
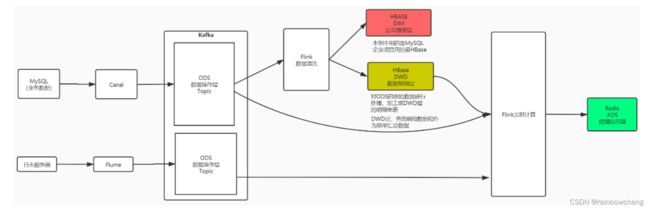 实时
实时
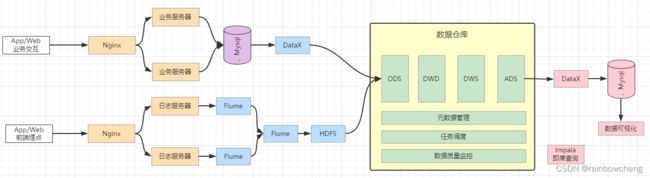 离线
离线
3.开发物理环境
5台物理机;500G数据盘;32G内存;8个core
4.数据仓库命名规范
- 数据库命名:命名规则是数仓对应分层 (命名示例:ods / dwd / dws/ dim / temp / ads)
- 数仓各层对应数据库::ods层 -> ods_{业务线|业务项目}; dw层 -> dwd_{业务线|业务项目} + dws_{业务线|业务项目} ;dim层 -> dim_维表; ads层 -> ads_{业务线|业务项目} (统计指标等) ;临时数据 -> temp_{业务线|业务项目}
- 表命名(数据库表命名规则): * ODS层: 命名规则:ods_{业务线|业务项目}[数据来源类型]{业务} ;* DWD层: 命名规则:dwd_{业务线|业务项目}{主题域}{子业务}; * DWS层: 命名规则:dws_{业务线|业务项目}{主题域}{汇总相关粒度}{汇总时间周 期} ;* ADS层: 命名规则:ads{业务线|业务项目}{统计业务}{报表form|热门排序topN} ;* DIM层: 命名规则:dim_{业务线|业务项目|pub公共}_{维度}
会员活跃度
1.需求分析
计算指标
会员:以设备判断标准,每个独立设备认为一个会员(IMEI号/OpenUDID);或手机号码等。
新增会员:每日新增会员数。第一次使用应用的用户。
活跃会员:每日,每周,每月的活跃会员数。每天打开,自然周启动过应用的会员。
会员留存:1日,2日,3日会员留存数、1日,2日,3日会员留存率。某段时间的新增会员,经过一段时间后,仍然继续使用应用是留存会员;这部分会员占当时新增会员的比例为留存率。
2.日志数据采集
原始日志数据
{“app_active”: {“name”:“app_active”,“json”: {“entry”:“1”,“action”:“1”,“error_code”:“0”},“time”:159611188852 9},“attr”:{“area”:“泰 安”,“uid”:“2F10092A9”,“app_v”:“1.1.13”,“event_type”:“common”,“d evice_id”:“1FB872- 9A1009”,“os_type”:“4.7.3”,“channel”:“DK”,“language”:“chinese”," brand":“iphone-9”}}
taildir source配置(flume 1,8+)
特点:
- 使用正则表达式匹配目录中的文件名
- 监控的文件中,一旦有数据写入,Flume就会将信息写入到指定的Sink
- 高可靠,不会丢失数据
- 不会对跟踪文件有任何处理,不会重命名也不会删除
- 不支持Windows,不能读二进制文件。支持按行读取文本文件
配置:
a1.sources.r1.type = TAILDIR
#配置检查点文件的路径,检查点文件会以 json 格式保存已经读取文件的位置,解决断点续传的问题
a1.sources.r1.positionFile = /data/lagoudw/conf/startlog_position.json
#指定filegroups,可以有多个,以空格分隔(taildir source可同时监控多个目录中的文件)
a1.sources.r1.filegroups = f1
#配置每个filegroup的文件绝对路径,文件名可以用正则表达式匹配
a1.sources.r1.filegroups.f1 = /data/lagoudw/logs/start/.*log
hdfs sink配置
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/start/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# ##配置 文件滚动方式
#基于文件大小。hdfs.rollSize 1024字节
a1.sinks.k1.hdfs.rollSize = 33554432 #文件大小32M
#基于event数量。hdfs.rollCount 10个event
a1.sinks.k1.hdfs.rollCount = 0
#基于时间。hdfs.rollInterval 30秒
a1.sinks.k1.hdfs.rollInterval = 0
#基于文件空闲时间。hdfs.idleTimeout 0 0是禁用
a1.sinks.k1.hdfs.idleTimeout = 0
#默认值与 hdfs 副本数一致。设为1是为了让 Flume 感知不到hdfs的块复制,此时其他的滚动方式配置(时间间隔、文件大小、events数量)才不会受影响
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 100
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp = true
Agent的配置
/data/lagoudw/conf/flume-log2hdfs1.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# taildir source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /data/lagoudw/conf/startlog_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/lagoudw/logs/start/.*log
# memorychannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 2000
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/start/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 1000
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
Flume的优化配置
启动agent:flume-ng agent --conf-file /data/lagoudw/conf/flume- log2hdfs1.conf -name a1 -Dflum e.roog.logger=INFO,console
缺省情况下 Flume jvm堆最大分配20m,这个值太小,需要调整。在 $FLUME_HOME/conf/flume-env.sh 中增加以下内容
export JAVA_OPTS=“-Xms4000m -Xmx4000m - Dcom.sun.management.jmxremote” # 要想使配置文件生效,还要在命令行中指定配置文件目录
flume-ng agent --conf /opt/apps/flume-1.9/conf --conf-file /data/lagoudw/conf/flume-log2hdfs1.conf -name a1 - Dflume.roog.logger=INFO,console
flume-ng agent --conf-file /data/lagoudw/conf/flume- log2hdfs1.conf -name a1 -Dflume.roog.logger=INFO,console
- 根据日志数据量的大小,Jvm堆一般要设置为4G或更高
- -Xms -Xmx 最好设置一致,减少内存抖动带来的性能影响
- 存在的问题:Flume放数据时,使用本地时间;不理会日志的时间戳
自定义拦截器
前面 Flume Agent 的配置使用了本地时间,可能导致数据存放的路径不正确。要解决以上问题需要使用自定义拦截器.
agent用于测试自定义拦截器。netcat source =>logger sink
/data/lagoudw/conf/flumetest1.conf
自定义拦截器的原理:
1、自定义拦截器要集成Flume 的 Interceptor
2、Event 分为header 和 body(接收的字符串)
3、获取header和body
4、从body中获取"time":1596382570539,并将时间戳转换为字符串 “yyyy-MMdd”
5、将转换后的字符串放置header中
将程序打包,放在 flume/lib目录下;
采集启动日志(使用自定义拦截器)
- 给source增加自定义拦截器
- 去掉本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true
- 根据header中的logtime写文件
配置文件不同处/data/lagoudw/conf/flume-log2hdfs2.conf
#新增
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.lagou.dw.flume.interceptor.CustomerInterceptor$Builder
#修改
a1.sinks.k1.hdfs.path = /user/data/logs/start/dt=%{logtime}/
#去掉
# 使用本地时间
# a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 测试 启动
flume-ng agent --conf /opt/apps/flume-1.9/conf --conf-file /data/lagoudw/conf/flume-log2hdfs2.conf -name a1 - Dflume.root.logger=INFO,console
采集启动日志和事件日志
本系统中要采集两种日志:启动日志、事件日志,不同的日志放置在不同的目录下。要想一次拿到全部日志需要监控多个目录。
1、taildir监控多个目录
2、修改自定义拦截器,不同来源的数据加上不同标志
3、hdfs sink 根据标志写文件
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /data/lagoudw/logs/start/.*log
a1.sources.r1.headers.f1.logtype = start
a1.sources.r1.filegroups.f2 = /data/lagoudw/logs/event/.*log
a1.sources.r1.headers.f2.logtype = event
#修改
a1.sinks.k1.hdfs.path = /user/data/logs/%{logtype}/dt=% {logtime}/
自定义拦截器:编码完成后打包上传服务器,放置在$FLUME_HOME/lib 下。
# 生产环境中用以下方式启动Agent
nohup flume-ng agent --conf /opt/apps/flume-1.9/conf --conf- file /data/lagoudw/conf/flume-log2hdfs3.conf -name a1 - Dflume.root.logger=INFO,LOGFILE > /dev/null 2>&1 &
- nohup,该命令允许用户退出帐户/关闭终端之后继续运行相应的进程
- /dev/null,代表linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称黑洞
- 标准输入0,从键盘获得输入 /proc/self/fd/0
- 标准输出1,输出到屏幕(控制台) /proc/self/fd/1
- 错误输出2,输出到屏幕(控制台) /proc/self/fd/2
- ->/dev/null 标准输出1重定向到 /dev/null 中,此时标准输出不存在,没有任何地方能够找到输出的内容
- 2>&1 错误输出将会和标准输出输出到同一个地方
- ->/dev/null 2>&1 不会输出任何信息到控制台,也不会有任何信息输出到文件中
日志数据采集小结
- 使用taildir source 监控指定的多个目录,可以给不同目录的日志加上不同header
- 在每个目录中可以使用正则匹配多个文件
- 使用自定义拦截器,主要功能是从json串中获取时间戳,加到event的header中
- hdfs sink使用event header中的信息写数据(控制写文件的位置)
- hdfs文件的滚动方式(基于文件大小、基于event数量、基于时间)
- 调节flume jvm内存的分配
3.ODS建表和数据加载
ODS层数据与源数据的格式基本相同。
use ODS;
create external table ods.ods_start_log( `str` string)
comment '用户启动日志信息'
partitioned by (`dt` string)
location '/user/data/logs/start';
-- 加载数据的功能(测试时使用)
alter table ods.ods_start_log add partition(dt='2020-08-02');
alter table ods.ods_start_log drop partition (dt='2020-08- 02');
#!/bin/bash
APP=ODS
hive=/opt/apps/hive-2.3.7/bin/hive
# 可以输入日期;如果未输入日期取昨天的时间
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
# 定义要执行的SQL
sql=" alter table "$APP".ods_start_log add partition(dt='$do_date'); "
$hive -e "$sql"
4.json数据处理
数据文件中每行必须是一个完整的 json 串,一个 json串 不能跨越多行。
Hive 处理json数据总体来说有三个办法:
使用内建函数处理
get_json_object(string json_string, string path):返回string。解析json,返回path指定内容;如果无效,返回null;每次只能返回一个数据项;
json_tuple(jsonStr, k1, k2, …):返回所有输入参数、输出参数都是string。该方法比get_json_object高效,因此可以在一次调用中输入多个键;
explode:使用explod将Hive一行中复杂的 array 或 map 结构拆分成多行。
-- {"id": 4,"ids": [401,402,403,304],"total_number": 5}
-- get 单层值
select username, age, sex, get_json_object(json, "$.id") id, get_json_object(json, "$.ids") ids, get_json_object(json, "$.total_number") num from jsont1;
-- get 数组
get_json_object(json, "$.ids[0]") ids0,get_json_object(json, "$.ids[1]") ids1,
-- 使用 json_tuple 一次处理多个字段
select json_tuple(json, 'id', 'ids', 'total_number') from jsont1;
使用UDF处理(hive-exec.pom)
自定义UDF处理json串中的数组。自定义UDF函数:输入json串、数组的key;输出字符串数组。
import org.apache.hadoop.hive.ql.exec.UDF;
public class ParseJsonArray extends UDF {
public ArrayList<String> evaluate(String jsonStr, String arrKey){
if (Strings.isNullOrEmpty(jsonStr)) { return null; }
JSONObject object = JSON.parseObject(jsonStr);
JSONArray jsonArray = object.getJSONArray(arrKey);
ArrayList<String> result = new ArrayList<>();
for (Object o: jsonArray){ result.add(o.toString()); }
return result;
}
}
-- 添加开发的jar包(在Hive命令行中)
add jar /data/lagoudw/jars/cn.lagou.dw-1.0-SNAPSHOT-jar-with- dependencies.jar;
-- 创建临时函数。指定类名一定要完整的路径,即包名加类名
create temporary function lagou_json_array as "cn.lagou.dw.hive.udf.ParseJsonArray";
-- 执行查询 -- 解析json串中的数组
select username, age, sex, lagou_json_array(json, "ids") ids from jsont1;
-- 解析json串中的数组,并展开
select username, age, sex, ids1 from jsont1 lateral view explode(lagou_json_array(json, "ids")) t1 as ids1;
使用SerDe处理
序列化是对象转换为字节序列的过程;反序列化是字节序列恢复为对象的过程;
对象的序列化主要有两种用途:
- 对象的持久化,即把对象转换成字节序列后保存到文件中
- 对象数据的网络传送
SerDe 是Serializer 和 Deserializer 的简写形式。Hive使用Serde进行行对象的序列与反序列化。最后实现把文件内容映射到 hive 表中的字段数据类型。
- Serialize把Hive使用的java object转换成能写入HDFS字节序列,或者其他系统能识别的流文件
- Deserilize把字符串或者二进制流转换成Hive能识别的java object对象
Read : HDFS files => InputFileFormat =>
Write : Row object => Seriallizer =>
对于纯 json 格式的数据,可以使用 JsonSerDe 来处理
1、简单格式的json数据,使用get_json_object、json_tuple处理
2、对于嵌套数据类型,可以使用UDF
3、纯json串可使用JsonSerDe处理更简单
5.DWD层建表和数据加载
json数据解析,丢弃无用数据(数据清洗),保留有效信息,并将数据展开,形成每日启动明细表。(ETL)
创建DWD层表
use DWD;
drop table if exists dwd.dwd_start_log;
CREATE TABLE dwd.dwd_start_log( `device_id` string, `area` string, `uid` string, `app_v` string, `event_type` string, `os_type` string, `channel` string, `language` string, `brand` string, `entry` string, `action` string, `error_code` string)
PARTITIONED BY (dt string) STORED AS parquet;
加载DWD层数据
script/member_active/dwd_load_start.sh
#!/bin/bash
source /etc/profile
# 可以输入日期;如果未输入日期取昨天的时间
if [ -n "$1" ] thendo_date=$1 elsedo_date=`date -d "-1 day" +%F` fi
# 定义要执行的SQL
sql=" with tmp as( select split(str, ' ')[7] line from ods.ods_start_log where dt='$do_date' )insert overwrite table dwd.dwd_start_log partition(dt='$do_date') select get_json_object(line, '$.attr.device_id'), get_json_object(line, '$.attr.area'), get_json_object(line, '$.attr.uid'), get_json_object(line, '$.attr.app_v'), get_json_object(line, '$.attr.event_type'), get_json_object(line, '$.attr.os_type'), get_json_object(line, '$.attr.channel'), get_json_object(line, '$.attr.language'), get_json_object(line, '$.attr.brand'), get_json_object(line, '$.app_active.json.entry'), get_json_object(line, '$.app_active.json.action'), get_json_object(line, '$.app_active.json.error_code') from tmp;"
hive -e "$sql"
日志文件 =》 Flume =》 HDFS =》 ODS =》 DWD (json数据的解析;数据清洗)
下一步任务:DWD(会员的每日启动信息明细) => DWS(如何建表,如何加载数据)
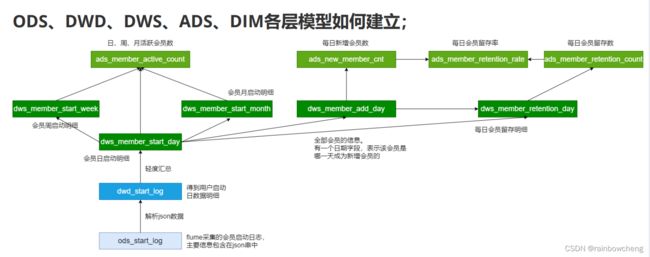
6.活跃会员
活跃会员指标需求:每日、每周(自然周)、每月(自然月)的活跃会员数
ODS:log日志信息{“area”:“绍 兴”,“uid”:“2F10092A10”,“app_v”:“1.1.16”,“event_type”:“common”," device_id":“1FB872- 9A10010”,“os_type”:“3.0”,“channel”:“ML”,“language”:“chinese”,“b rand”:“Huawei-2”}。
DWD:按照json创建表,丢弃无用数据(数据清洗)。(如:device_id、area等)。
DWS:宽表记录。【group by分组】(如:dws_member_start_day:每个会员一天一条记录。dws_member_start_week:会员周记录,一周一条,比上个表多一个week字段)
ADS:计算当天、当周、当月活跃会员数量。【count函数】day_count、week_count、month_count。
sql=" insert overwrite table dws.dws_member_start_day partition(dt='$do_date') select device_id, concat_ws('|', collect_set(uid)), concat_ws('|', collect_set(app_v)), concat_ws('|', collect_set(os_type)), concat_ws('|', collect_set(language)), concat_ws('|', collect_set(channel)), concat_ws('|', collect_set(area)), concat_ws('|', collect_set(brand)) from dwd.dwd_start_log where dt='$do_date' group by device_id;"
7.新增会员
第一次使用应用的用户,定义为新增会员;卸载再次安装的设备,不会被算作一次新增。
dws_member_add_day、
sql=" insert into table dws.dws_member_add_day select t1.device_id, t1.uid, t1.app_v, t1.os_type, t1.language, t1.channel, t1.area, t1.brand, '$do_date' from dws.dws_member_start_day t1 left join dws.dws_member_add_day t2 on t1.device_id=t2.device_id where t1.dt='$do_date' and t2.device_id is null; "
8.留存会员
某段时间的新增会员,经过一段时间后,仍继续使用应用认为是留存会员;这部分会员占当时新增会员的比例为留存率。
9.Datax数据导出
把ADS表的数据导出到Mysql,即Hive->mysql
-- 活跃会员数
create table dwads.ads_member_active_count(
`dt` varchar(10) COMMENT '统计日期',
`day_count` int COMMENT '当日会员数量',
`week_count` int COMMENT '当周会员数量',
`month_count` int COMMENT '当月会员数量',
primary key (dt) );
-- 新增会员数
create table dwads.ads_new_member_cnt (`dt` varchar(10) COMMENT '统计日期', `cnt` string, primary key (dt) );
-- 会员留存数
drop table if exists dwads.ads_member_retention_count; create table dwads.ads_member_retention_count ( `dt` varchar(10) COMMENT '统计日期',`add_date` string comment '新增日期', `retention_day` int comment '截止当前日期留存天数', `retention_count` bigint comment '留存数', primary key (dt) ) COMMENT '会员留存情况';
-- 会员留存率
drop table if exists dwads.ads_member_retention_rate; create table dwads.ads_member_retention_rate ( `dt` varchar(10) COMMENT '统计日期', `add_date` string comment '新增日期', `retention_day` int comment '截止当前日期留存天数', `retention_count` bigint comment '留存数', `new_mid_count` bigint comment '当日会员新增数', `retention_ratio` decimal(10,2) comment '留存率', primary key (dt) ) COMMENT '会员留存率';
导出活跃会员数(ads_member_active_count)
export_member_active_count.json (hdfsreader => mysqlwriter)
{ "job": { "setting": { "speed": { "channel": 1 } },"content": [{ "reader": { "name": "hdfsreader", "parameter": { "path": "/lagou/hive/warehouse/ads.db/ads_member_active_count/dt=$do_d ate/*", "defaultFS": "hdfs://hadoop1:9000", "column": [{ "type": "string", "value": "$do_date" }, { "index": 0, "type": "string" },{ "index": 1, "type": "string" },{ "index": 2, "type": "string" } ],"fileType": "text", "encoding": "UTF-8", "fieldDelimiter": "," } },"writer": { "name": "mysqlwriter", "parameter": { "writeMode": "replace", "username": "hive", "password": "*****", "column": ["dt","day_count","week_count","month_count"], "preSql": [ "" ],"connection": [{ "jdbcUrl": "jdbc:mysql://hadoop2:3306/dwads? useUnicode=true&characterEncoding=utf-8", "table": [ "ads_member_active_count" ] }] } } }] } }
执行命令:python datax.py -p “-Ddo_date=2020-08-02” /data/lagoudw/script/member_active/t1.json
export_member_active_count.sh
#!/bin/bash
JSON=/data/lagoudw/script/member_active
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date"
$JSON/export_member_active_count.json 2020-08-02
10.日启动数据测试
1000W条数据约3.5G+,每条记录约370字节。
1、flume 采集数据:修改flume的参数:1G滚动一次;加大channel缓存;加大刷新 hdfs 的缓存。1个文件大小3.5G,时间4分钟左右。
2、给map、reduce task分配合理的内存;map、reduce task处理合理的数据。解决java heap space问题。每个节点8core/32G;mapred.child.java.opts = 3G
3、Hive on Tez测试
电商分析之 – 广告业务
互联网平台通行的商业模式是利用免费的基础服务吸引凝聚大量用户,并利用这些用户资源开展广告或其他增值业务实现盈利从而反哺支撑免费服务的生存和发展。广告收入不仅成为互联网平台的重要收入之一,更决定了互联网平台的发展程度。
电商平台本身就汇聚了海量的商品、店铺的信息,天然适合进行商品的推广。对于电商和广告主来说,广告投放的目的无非就是吸引更多的用户,最终实现营销转化。因此非常关注不同位置广告的曝光量、点击量、购买量、点击率、购买率。
1.需求分析
{ "lagou_event": [{ "name": "goods_detail_loading", "json": { "entry": "3", "goodsid": "0", "loading_time": "80", "action": "4", "staytime": "68", "showtype": "4" },"time": 1596225273755 }, {"name": "loading", "json": { "loading_time": "18", "action": "1", "loading_type": "2", "type": "3" },"time": 1596231657803 }, {"name": "ad", "json": { "duration": "17", "ad_action": "0", "shop_id": "786", "event_type": "ad", "ad_type": "4", "show_style": "1", "product_id": "2772", "place": "placeindex_left", "sort": "0" },"time": 1596278404415 }, {"name": "favorites", "json": { "course_id": 0, "id": 0, "userid": 0 },"time": 1596239532527 }, {"name": "praise", "json": { "id": 2, "type": 3, "add_time": "1596258672095", "userid": 8, "target": 6 },"time": 1596274343507 }], "attr": { "area": "拉萨", "uid": "2F10092A86", "app_v": "1.1.12", "event_type": "common", "device_id": "1FB872-9A10086", "os_type": "4.1", "channel": "KS", "language": "chinese", "brand": "xiaomi-2" } }
采集的信息包括:商品详情页加载(goods_detail_loading);商品列表(loading);消息通知(notification);商品评论(comment);收藏(favorites);点赞(praise);广告(ad)。
需求指标
1、点击次数统计(分时统计):曝光次数、点击次数、购买次数。
2、转化率-漏斗分析:点击率=点击次数/曝光次数;购买率=购买次数/点击次数
3、活动曝光效果评估:行为(曝光、点击、购买)、时间段、广告位、产品,统计对应的次数。时间段、广告位、商品,曝光次数最多的前N个
2.事件日志采集
3.ODS层建表和数据加载
4.DWD层建表和数据加载
ODS => 解析json,从json串中,提取jsonArray数据;将公共信息从json串中解析出来 => 所有事件的明细。(分区 | 事件JSON串 | 公共信息字段)
CREATE TABLE dwd.dwd_ad
日志 => Flume => ODS => 清洗、转换(DWD) => 广告事件详细信息
5.广告点击次数分析
需求分析
广告:ad
- action。用户行为;0 曝光;1 曝光后点击;2 购买
- duration。停留时长
- shop_id。商家id
- event_type。“ad”
- ad_type。格式类型;1 JPG;2 PNG;3 GIF;4 SWF
- show_style。显示风格,0 静态图;1 动态图
- product_id。产品id
- place。广告位置;首页=1,左侧=2,右侧=3,列表页=4
- sort。排序位置
日志 => Flume => ODS =>DWD => DWS(不需要) => ADS;在某个分析中不是所有的层都会用到。
drop table if exists ads.ads_ad_show;
create table ads.ads_ad_show(
cnt bigint, u_cnt bigint, device_cnt bigint,
ad_action tinyint, hour string
) PARTITIONED BY (`dt` string) row format delimited fields terminated by ',';
insert overwrite table ads.ads_ad_show partition (dt='$do_date')
select count(1), count(distinct uid), count(distinct device_id), ad_action, hour
from dwd.dwd_ad where dt='$do_date' group by ad_action, hour
6.漏斗分析(点击率购买率)
create table ads.ads_ad_show_rate(
hour string, click_rate double, buy_rate double
) PARTITIONED BY (`dt` string) row format delimited fields terminated by ',';
--行转列
select
sum(case when ad_action='0' then cnt end) show_cnt,
sum(case when ad_action='1' then cnt end) click_cnt,
sum(case when ad_action='2' then cnt end) buy_cnt,
hour
from ads.ads_ad_show where dt='2020-08-02' and hour='01' group by hour
7.广告效果分析
create table ads.ads_ad_show_place(
ad_action tinyint, hour string,
place string, product_id int, cnt bigint
)PARTITIONED BY (`dt` string)
insert overwrite table ads.ads_ad_show_place partition (dt='$do_date')
select ad_action, hour,place, product_id, count(1) from dwd.dwd_ad
where dt='$do_date' group by ad_action, hour, place, product_id
create table ads.ads_ad_show_place_window(
hour string, place string, product_id int, cnt bigint, rank int
)PARTITIONED BY (`dt` string)
insert overwrite table ads.ads_ad_show_place_window partition (dt='$do_date')
select * from (
select hour, place, product_id, cnt, row_number() over (partition by hour, place, product_id order by cnt desc) rank
from ads.ads_ad_show_place where dt='$do_date' and ad_action='0'
) t where rank <= 100
小结:分析简单,没有DWS层
8.广告分析小结

9. ADS层数据导出(DataX)
在MySQL创建表
create table dwads.ads_ad_show_place(
ad_action tinyint, hour varchar(2), place varchar(20), product_id int, cnt int, dt varchar(10)
);
创建配置文件json
/data/lagoudw/script/advertisement/ads_ad_show_place.json
{ "job":{ "setting":{ "speed":{ "channel":1 } },"content":[ { "reader":{ "name":"hdfsreader", "parameter":{ "path":"/lagou/hive/warehouse/ads.db/ads_ad_show_place/dt=$do _date/*", "defaultFS":"hdfs://hadoop1:9000", "column":[ { "index":0, "type":"string" },{ "index":1, "type":"string" },{ "index":2, "type":"string" }, { "index":3, "type":"string" },{ "index":4, "type":"string" },{ "type":"string", "value":"$do_date" } ],"fileType":"text", "encoding":"UTF-8", "fieldDelimiter":"," } },"writer":{ "name":"mysqlwriter", "parameter":{ "writeMode":"insert", "username":"hive", "password":"******", "column":[ "ad_action", "hour", "place", "product_id", "cnt", "dt" ],"preSql":[ "delete from ads_ad_show_place where dt='$do_date'" ],"connection":[ { "jdbcUrl":"jdbc:mysql://hadoop2:3306/dwads? useUnicode=true&characterEncoding=utf-8", "table":[ "ads_ad_show_place" ] } ] } } } ] } }
执行命令,使用json配置文件;测试
python /data/modules/datax/bin/datax.py -p “-Ddo_date=2020-08- 02” /data/lagoudw/script/advertisement/ads_ad_show_place.json
编写执行脚本shell
/data/lagoudw/script/advertisement/ads_ad_show_place.sh
#!/bin/bash
source /etc/profile
JSON=/data/lagoudw/script
if [ -n "$1" ] ;then do_date=$1 elsedo_date=`date -d "-1 day" +%F` fi
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date"
$JSON/advertisement/ads_ad_show_place.json
sh /data/lagoudw/script/advertisement/ads_ad_show_place.sh 2020-08-02
10.日志数据测试
1000W左右日活用户;按 30条日志 / 人天,合计3亿条事件日志;每条日志 650字节 左右;总数据量大概在180G;采集数据时间约2.5小时。
日志文件很大,可以将hdfs文件滚动设置为10G甚至更大
电商分析之–核心交易
本主题是电商系统业务中最关键的业务,电商的运营活动都是围绕这个主题展开。
选取的指标包括:订单数、商品数、支付金额。对这些指标按销售区域、商品类型进行分析。
1.业务数据库表结构
交易订单表(trade_orders)
CREATE TABLE `lagou_trade_orders` ( `orderId` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单 id',`orderNo` varchar(20) NOT NULL COMMENT '订单编号', `userId` bigint(11) NOT NULL COMMENT '用户id', `status` tinyint(4) NOT NULL DEFAULT '-2' COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收 货',`productMoney` decimal(11,2) NOT NULL COMMENT '商品金额', `totalMoney` decimal(11,2) NOT NULL COMMENT '订单金额(包括运 费)', `payMethod` tinyint(4) NOT NULL DEFAULT '0' COMMENT '支付方 式,0:未知;1:支付宝,2:微信;3、现金;4、其他', `isPay` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否支付 0:未 支付 1:已支付', `areaId` int(11) NOT NULL COMMENT '区域最低一级', `tradeSrc` tinyint(4) NOT NULL DEFAULT '0' COMMENT '订单来源 0:商城 1:微信 2:手机版 3:安卓App 4:苹果App', `tradeType` int(11) DEFAULT '0' COMMENT '订单类型', `isRefund` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否退款 0:否 1:是', `dataFlag` tinyint(4) NOT NULL DEFAULT '1' COMMENT '订单有效标 志 -1:删除 1:有效', `createTime` varchar(25) NOT NULL COMMENT '下单时间', `payTime` varchar(25) DEFAULT NULL COMMENT '支付时间', `modifiedTime` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '订单更新时间', PRIMARY KEY (`orderId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='交易订单表';
订单产品表(order_product)
CREATE TABLE `lagou_order_product` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `orderId` bigint(11) NOT NULL COMMENT '订单id', `productId` bigint(11) NOT NULL COMMENT '商品id', `productNum` bigint(11) NOT NULL DEFAULT '0' COMMENT '商品数 量',`productPrice` decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '商品价格', `money` decimal(11,2) DEFAULT '0.00' COMMENT '付款金额', `extra` text COMMENT '额外信息', `createTime` varchar(25) DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`id`), KEY `orderId` (`orderId`), KEY `goodsId` (`productId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
产品信息表(product_info)
CREATE TABLE `lagou_product_info` ( `productId` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '商品 id',`productName` varchar(200) NOT NULL COMMENT '商品名称', `shopId` bigint(11) NOT NULL COMMENT '门店ID', `price` decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '门店 价',`isSale` tinyint(4) NOT NULL DEFAULT '1' COMMENT '是否上架 0:不上架 1:上架', `status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否新品 0:否 1:是', `categoryId` int(11) NOT NULL COMMENT 'goodsCatId 最后一级商品 分类ID', `createTime` varchar(25) NOT NULL, `modifyTime` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`productId`), KEY `shopId` (`shopId`) USING BTREE, KEY `goodsStatus` (`isSale`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
产品分类表(product_category)
CREATE TABLE `lagou_product_category` ( `catId` int(11) NOT NULL AUTO_INCREMENT COMMENT '品类ID', `parentId` int(11) NOT NULL COMMENT '父ID', `catName` varchar(20) NOT NULL COMMENT '分类名称', `isShow` tinyint(4) NOT NULL DEFAULT '1' COMMENT '是否显示 0:隐藏 1:显示', `sortNum` int(11) NOT NULL DEFAULT '0' COMMENT '排序号', `isDel` tinyint(4) NOT NULL DEFAULT '1' COMMENT '删除标志 1:有 效 -1:删除', `createTime` varchar(25) NOT NULL COMMENT '建立时间', `level` tinyint(4) DEFAULT '0' COMMENT '分类级别,共3级', PRIMARY KEY (`catId`), KEY `parentId` (`parentId`,`isShow`,`isDel`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
商家店铺表(shops)
CREATE TABLE `lagou_shops` ( `shopId` int(11) NOT NULL AUTO_INCREMENT COMMENT '商铺ID,自 增',`userId` int(11) NOT NULL COMMENT '商铺联系人ID', `areaId` int(11) DEFAULT '0', `shopName` varchar(100) DEFAULT '' COMMENT '商铺名称', `shopLevel` tinyint(4) NOT NULL DEFAULT '1' COMMENT '店铺等 级',`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商铺状态', `createTime` date DEFAULT NULL, `modifyTime` datetime DEFAULT NULL COMMENT '修改时间', PRIMARY KEY (`shopId`), KEY `shopStatus` (`status`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
商家地域组织表(shop_admin_org)
CREATE TABLE `lagou_shop_admin_org` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '组织ID', `parentId` int(11) NOT NULL COMMENT '父ID', `orgName` varchar(100) NOT NULL COMMENT '组织名称', `orgLevel` tinyint(4) NOT NULL DEFAULT '1' COMMENT '组织级别 1;总部及大区级部门;2:总部下属的各个部门及基部门;3:具体工作部门', `isDelete` tinyint(4) NOT NULL DEFAULT '0' COMMENT '删除标 志,1:删除;0:有效', `createTime` varchar(25) DEFAULT NULL COMMENT '创建时间', `updateTime` varchar(25) DEFAULT NULL COMMENT '最后修改时间', `isShow` tinyint(4) NOT NULL DEFAULT '1' COMMENT '是否显示,0: 是 1:否', `orgType` tinyint(4) NOT NULL DEFAULT '1' COMMENT '组织类 型,0:总裁办;1:研发;2:销售;3:运营;4:产品', PRIMARY KEY (`id`), KEY `parentId` (`parentId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
支付方式表(payments)
CREATE TABLE `lagou_payments` ( `id` int(11) NOT NULL, `payMethod` varchar(20) DEFAULT NULL, `payName` varchar(255) DEFAULT NULL, `description` varchar(255) DEFAULT NULL, `payOrder` int(11) DEFAULT '0', `online` tinyint(4) DEFAULT NULL, PRIMARY KEY (`id`), KEY `payCode` (`payMethod`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3.数据导入
业务数据保存在MySQL中,每日凌晨导入上一天的表数据。
- 表数据量少,采用全量方式导出MySQL
- 表数据量大,而且根据字段能区分出每天新增数据,采用增量方式导出MySQL
全量数据导入
产品分类表、商家店铺表、商家地域组织表、支付方式表。
MySQL => HDFS => Hive
lagou_product_category ===> ods.ods_trade_product_category
/data/lagoudw/json/product_category.json
数据量小的表没有必要使用多个channel;使用多个channel会生成多个小文件
执行命令之前要在HDFS上创建对应的目录: /user/data/trade.db/product_category/dt=yyyy-mm-dd
lagou_shops ====> ods.ods_trade_shops
/data/lagoudw/json/shops.json
增量数据导入
订单表、订单产品表、产品信息表
初始数据装载(执行一次);可以将前面的全量加载作为初次装载
每日加载增量数据(每日数据形成分区);
lagou_trade_orders ====> ods.ods_trade_orders
/data/lagoudw/json/orders.json
备注:条件的选择,选择时间字段 modifiedTime
select date_format(createTime, '%Y-%m-%d'), count(*) from lagou_trade_orders
group by date_format(createTime, '%Y-%m-%d');
Canal同步业务数据
Hadoop、HBASE、Flink、ClickHouse、MySQL、Canal、Kafka
Cannal
杭州和美国异地机房的需求,从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,Canal主要支持了MySQL的binlog解析,解析完成后才利用Canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于Canal)。
Canal安装详看附录
1.otter是阿里用于进行异地数据库之间的同步框架,Canal是其中一部分。

2.更新缓存:监控数据库,写入缓存服务器。
3.抓取业务数据新增变化表,用于制作拉链表
| 订单创建日期 | 订单编号 | 订单状态 | dw_begin_date | dw_end_date |
|---|---|---|---|---|
| 2022-06-20 | 001 | 创建订单 | 2022-06-20 | 2022-06-20 |
| 2022-06-20 | 001 | 支付完成 | 2022-06-21 |
9999-12-31 |
| 2022-06-20 | 002 | 创建订单 | 2022-06-20 | 9999-12-31 |
| 2022-06-20 | 003 | 支付完成 | 2022-06-20 | 2022-06-21 |
| 2022-06-20 | 003 | 已发货 | 2022-06-22 | 9999-12-31 |
| 2022-06-21 | 004 | 创建订单 | 2022-06-21 | 9999-12-31 |
| 2022-06-21 | 005 | 创建订单 | 2022-06-21 | 2022-06-21 |
| 2022-06-21 | 005 | 支付完成 | 2022-06-22 | 9999-12-31 |
| 2022-06-22 | 006 | 创建订单 | 2022-06-22 | 9999-12-31 |
- dw_begin_date表示该条记录的生命周期开始时间,dw_end_date表示该条记录的生命周期结束时间;
- dw_end_date = '9999-12-31’表示该条记录目前处于有效状态;
- 如果查询当前所有有效的记录,则select * from order_his where dw_end_date = ‘9999-12-31’
- 如果查询2012-06-21的历史快照,则select * from order_his where dw_begin_date <= ‘2012-06-21’ and end_date >= ‘2012-06-21’,这条语句会查询到以下记录

4.抓取业务表的新增变化数据,用于制作实时统计
- Masterr主库将改变记录写到二进制日志(binary log)中
- Slave从库向MySQL master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
- Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
Canal工作原理就是把自己伪装成Slave,假装从master复制数据。
binlog
记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗。
二进制有两个最重要的使用场景:主从、数据恢复。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
#my.cnf
[mysqld]
# 配置 MySQL replaction 需要定义,不要和 Canal 的 slaveId 重复
server-id=1
#前缀mysql-bin(如mysql-bin.123456)
#每次MySQL重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
log-bin=mysql-bin
#statement:节省空间,但出现数据不一致(update tt set create_date=now())。记录执行操作语句
#row: binlog会记录每次`操作后`每行记录的变化。
binlog_format=row
binlog-do-db=dwshow # dwshow是数据库的名称
授权
show grants for ‘canal’@‘%’;
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal' ;
4.ODS层建表与数据加载
ODS层的表结构与源数据基本类似(列名及数据类型)。
CREATE EXTERNAL TABLE `ods.ods_trade_orders`( `orderid` int, `orderno` string, `userid` bigint, `status` tinyint, `productmoney` decimal(10, 0), `totalmoney` decimal(10, 0), `paymethod` tinyint, `ispay` tinyint, `areaid` int, `tradesrc` tinyint, `tradetype` int, `isrefund` tinyint, `dataflag` tinyint, `createtime` string, `paytime` string, `modifiedtime` string) COMMENT '订单表' PARTITIONED BY (`dt` string) row format delimited fields terminated by ',' location '/user/data/trade.db/orders/';
DataX仅仅是将数据导入到了 HDFS ,数据并没有与Hive表建立关联。执行脚本使数据迁移、数据加载到ODS层。对于增量加载数据而言:初始数据加载;该任务仅执行一次,不在脚本中。
5.缓慢变化维与周期性事实表
缓慢变化维
缓慢变化维(SCD;Slowly Changing Dimensions)。在现实世界中,维度的属性随着时间的流失发生缓慢的变化(缓慢是相对事实表而言,事实表数据变化的速度比维度表快)。【修改历史记录】
保留原始值
维度属性值不做更改,保留原始值。
直接覆盖
修改维度属性为最新值,直接覆盖,不保留历史信息。
增加新属性列
在维度表中增加新的一列,原先属性列存放上一版本的属性值,当前属性列存放当前版本的属性值,还可以增加一列记录变化的时间。
缺点:只能记录最后一次变化的信息。
快照表
每天保留一份全量数据。
简单、高效。缺点是信息重复,浪费磁盘空间。
适用范围:维表不能太大
拉链表(log)
拉链表适合于:表的数据量大,而且数据会发生新增和变化,但是大部分是不变的(数据发生变化的百分比不大),且是缓慢变化的(如电商中用户信息表中的某些用户基本属性不可能每天都变化)。主要目的是节省存储空间。
数据量大、部分字段更新、记录修改比例不高、需要保留历史信息。(log操作日志表) 创建临时表
create table test.tmp as select userid, mobile, regdate, start_date, end_date, '1' as tagfrom test.userhis where end_date < '2020-06-22' union all select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag from test.userhis where start_date <= '2020-06-22' and end_date >= '2020-06- 22';
方案二:保存一段时间的增量数据(userinfo),定期对拉链表做备份(如一个月做一次备份);如需回滚,直接在备份的拉链表上重跑增量数据。处理简单
周期性事实表
订单状态可以采用拉链表保存历史状态数据。
6.DIM层建表加载数据
DIM贯穿DWD和DWS,公共维度层。
商品分类维度表
把多层级变成单层级(递归变成for循环)宽表。
create table if not exists dim.dim_trade_product_cat( firstId int, -- 一级商品分类id firstName string, -- 一级商品分类名称 secondId int, -- 二级商品分类Id secondName string, -- 二级商品分类名称 thirdId int, -- 三级商品分类id thirdName string -- 三级商品分类名称 )partitioned by (dt string) STORED AS PARQUET;
--实现
select T1.catid, T1.catname, T2.catid, T2.catname, T3.catid, T3.catname from (select catid, catname, parentid from ods.ods_trade_product_category where level=3 and dt='2020-07-01') T3 left join (select catid, catname, parentid from ods.ods_trade_product_category where level=2 and dt='2020-07-01') T2 on T3.parentid=T2.catid left join (select catid, catname, parentid from ods.ods_trade_product_category where level=1 and dt='2020-07-01') T1 on T2.parentid=T1.catid;
商品地域组织表
将商家店铺表、商家地域组织表组织成一张表,并拉宽。在一行数据中体现:商家信息、城市信息、地域信息。信息中包括 id 和 name ;
create table dim.dim_trade_shops_org( shopid int, shopName string, cityId int, cityName string , regionId int , regionName string )
--实现
select T1.shopid, T1.shopname, T2.id cityid, T2.orgname cityname, T3.id regionid, T3.orgname regionname from
(select shopid, shopname, areaid from ods.ods_trade_shops where dt='2020-07-01') T1
left join (select id, parentid, orgname, orglevel from ods.ods_trade_shop_admin_org where orglevel=2 and dt='2020-07-01') T2 on T1.areaid=T2.id
left join (select id, orgname, orglevel from ods.ods_trade_shop_admin_org where orglevel=1 and dt='2020-07-01') T3 on T2.parentid=T3.id limit 10
支付方式表
对ODS中表的信息做了裁剪,只保留了必要的信息(paymentId、paymentName)。
商品信息表
使用拉链表对商品信息进行处理:
1、历史数据 => 初始化拉链表(开始日期:当日;结束日期:9999-12-31)【只执行一
次】
2、拉链表的每日处理【每次加载数据时处理】
- 新增数据。每日新增数据(ODS) => 开始日期:当日;结束日期:9999-12-31
- 历史数据。拉链表(DIM) 与 每日新增数据(ODS) 做左连接
- 连接上数据。数据有变化,结束日期:当日;
- 未连接上数据。数据无变化,结束日期保持不变;
7. DWD层建表加载数据
要处理的表有两张:订单表、订单产品表。
- 订单表是周期性事实表;为保留订单状态,可以使用拉链表进行处理;
- 订单产品表普通的事实表,用常规的方法进行处理;
- 如果有数据清洗、数据转换的业务需求,ODS => DWD
- 如果没有数据清洗、数据转换的业务需求,保留在ODS,不做任何变化。这个是本项目的处理方式
订单从创建到最终完成,是有时间限制的;业务上也不允许订单在一个月之后,状态仍然在发生变化.
8.DWS层建表及数据加载
最小粒度天
- 全国所有订单信息
- 全国、一级商品分类订单信息
- 全国、二级商品分类订单信息
- 大区所有订单信息
- 大区、一级商品分类订单信息
- 大区、二级商品分类订单信息
- 城市所有订单信息
- 城市、一级商品分类订单信息
- 城市、二级商品分类订单信息
需要的信息:订单表、订单商品表、商品信息维表、商品分类维表、商家地域维表
订单表 => 订单id、订单状态
订单商品表 => 订单id、商品id、商家id、单价、数量
商品信息维表 => 商品id、三级分类id
商品分类维表 => 一级名称、一级分类id、二级名称、二级分类id、三级名称、三级分类id
商家地域维表 => 商家id、区域名称、区域id、城市名称、城市id
订单表、订单商品表、商品信息维表 => 订单id、商品id、商家id、三级分类id、单价、数量(订单明细表)
订单明细表、商品分类维表、商家地域维表 => 订单id、商品id、商家id、三级分类名称、三级分类名称、三级分类名称、单价、数量、区域、城市 => 订单明细宽表
9.ADS层开发
汇总总数。如:ads.ads_trade_order_analysis
城市名称(cityname)、区域名称(regionname)、商品一级分类名称(category1)、商品二级分类名称(category2)、订单数量(totalcount)、商品数量(total_productnum)、支付金额(totalmoney)
10.数据导出
ads.ads_trade_order_analysis 分区表,使用DataX导出到MySQL
小结

主要技术点:
- 拉链表。创建、使用与回滚;商品信息表、订单表(周期性事实表;分区表+拉链表)
- 宽表(逆规范化):商品分类表、商品地域组织表、订单明细及订单明细宽表(轻度汇总的事实表)
系统实时监控&可视化
普罗米修斯Prometheus
实时数仓的数据质量
流程图描述了一般的实时数据计算流程,接收日志或者MQ到kafka,用Flink进行处理和计算(指标),将最终计算结果(指标)存储在redis中,最后查询出redis中的数据给大屏、看板等展示。
但是在整个过程中,不得不思考一下,最后计算出来的存储在redis中指标数据是不是正确的呢?怎么能给用户或者老板一个信服的理由呢?
【流量、订单、用户、地域】原始数据 —> 【broker】Kafka —> 【Flink】实时数据处理 —> 【HBase实时宽表】保存实时数据 —>【pv、uv、dau日活量、gmv】实时数据处理 —>【redis】结果存储
实时宽表数据可以持久化,就可以与离线数据进行比对。确定是日志丢失、消息发送失败、计算业务逻辑问题。
(1) 实时宽表数据存储至elasticsearch
(2) 实时宽表数据存储至HDFS,通过Hive进行查询。
es对应的sql count、group by语法操作,非常复杂,况且也不是用来做线上服务,而只是用与核对数据质量,所以时效性也不需要完全考虑,这样的话,就可以考虑将数据回写至HDFS了。
写HDFS与es相比,存在非常明显的优点:
a.学习成本低、会sql的基本就可以了,而不需要重新学习es负责的count、group by 等语法操作
b.可以非常方便地和离线表数据进行关联查询(大多数情况下都是和离线数据比对),两张Hive表的关联查询,容易找出两张表的数据差异

实例直播
保障目标
- 直播4,5个小时,业务需要
实时的数据服务,做及时性的决策。 - 参与方众多,各方指标口径需要
一致。 - 玩法非常丰富,指标计算复杂,
准确性保障困难大。 - 数据量巨大,系统压力大,
稳定性保障难度高。
保障策略(前 —中—后)
1、【前】双链路保障(主备方案):

2、【前】流量压测:
HDFS —>Flink —kafka–>多个Flink —kafka–>Druid —>数据集
采用10倍数据,全链路,性能极限测试。
3、【前】指定应急预案
保障纪律、专人专责、应急发布
数据产品、数据加工、基础架构
异常判定、方案选择、信息同步
【进行中】
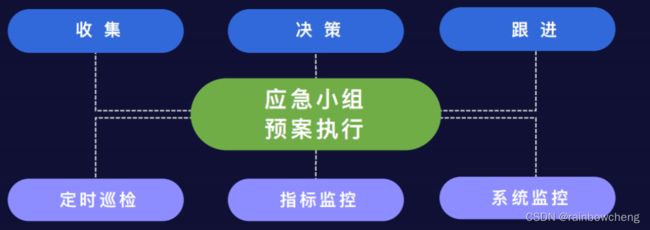
【事后复盘】
保障盲点整理—》数据问题复盘—》应急策略沉淀
任务调度系统Airflow
Airflow将一个工作流制定为一组任务的有向无环图(DAG),并指派到一组计算节点上,根据相互之间的依赖关系,有序执行。Airflow 有以下优势:
- 灵活易用。Airflow 是 Python 编写的,工作流的定义也使用 Python 编写;
- 功能强大。支持多种不同类型的作业,可自定义不同类型的作业。如 Shell、Python、Mysql、Oracle、Hive等;
- 简洁优雅。作业的定义简单明了;
- 易扩展。提供各种基类供扩展,有多种执行器可供选择
Webserver 守护进程。接受 HTTP 请求,通过 Python Flask Web 应用程序与airflow 进行交互。Webserver 提供功能的功能包括:中止、恢复、触发任务;监控正在运行的任务,断点续跑任务;查询任务的状态,日志等详细信息。
Scheduler 守护进程。周期性地轮询任务的调度计划,以确定是否触发任务执行。
Worker 守护进程。Worker负责启动机器上的executor来执行任务。使用celeryExecutor后可以在多个机器上部署worker服务。
元数据管理工具Atlas
Atlas是Hadoop平台元数据框架;
元数据(MetaData)狭义的解释是用来描述数据的数据。广义的来看,除了业务逻辑直接读写处理的那些业务数据,所有其它用来维持整个系统运转所需的信息/数据都可以叫作元数据。如数据库中表的Schema信息,任务的血缘关系,用户和脚本/任务的权限映射关系信息等。
管理元数据的目的,是为了让用户能够更高效的使用数据,也是为了让平台管理人员能更加有效的做好数据的维护管理工作。
数据血缘关系
血缘信息或者叫做Lineage的血统信息是什么,简单的说就是数据之间的上下游来源去向关系,数据从哪里来到哪里去。如果一个数据有问题,可以根据血缘关系往上游排查,看看到底在哪个环节出了问题。此外也可以通过数据的血缘关系,建立起生产这些数据的任务之间的依赖关系,进而辅助调度系统的工作调度,或者用来判断一个失败或错误的任务可能对哪些下游数据造成影响等等。
分析数据的血缘关系看起来简单,但真的要做起来,并不容易,因为数据的来源多种多样,加工数据的手段,所使用的计算框架可能也各不相同,此外也不是所有的系统天生都具备获取相关信息的能力。而针对不同的系统,血缘关系具体能够分析到的粒度可能也不一样,有些能做到表级别,有些甚至可以做到字段级别。
数据的业务属性信息
业务属性信息都有哪些呢?如一张数据表的统计口径信息,这张表干什么用的,各个字段的具体统计方式,业务描述,业务标签,脚本逻辑的历史变迁记录,变迁原因等,此外还包括对应的数据表格是由谁负责开发的,具体数据的业务部门归属等。数据的业务属性信息,首先是为业务服务的,它的采集和展示也就需要尽可能的和业务环境相融合,只有这样才能真正发挥这部分元数据信息的作用。
数据质量监控工具Griffin
为什么要做数据质量监控
1、数据不一致
企业早期没有进行统一规划设计,大部分信息系统是逐步迭代建设的,系统建设时间长短各异,各系统数据标准也不同。企业业务系统更关注业务层面,各个业务系统均有不同的侧重点,各类数据的属性信息设置和要求不统一。另外,由于各系统的相互独立使用,无法及时同步更新相关信息等各种原因造成各系统间的数据不一致,严重影响了各系统间的数据交互和统一识别,基础数据难以共享利用,数据的深层价值也难以体现。
2、数据不完整
由于企业信息系统的孤立使用,各个业务系统或模块按照各自的需要录入数据,没有统一的录入工具和数据出口,业务系统不需要的信息就不录,造成同样的数据在不同的系统有不同的属性信息,数据完整性无法得到保障。
3、数据不合规
没有统一的数据管理平台和数据源头,数据全生命周期管理不完整,同时企业各信息系统的数据录入环节过于简单且手工参与较多,就数据本身而言,缺少是否重复、合法、对错等校验环节,导致各个信息系统的数据不够准确,格式混乱,各类数据难以集成和统一,没有质量控制导致海量数据因质量过低而难以被利用,且没有相应的数管理流程。
4、数据不可控
海量数据多头管理,缺少专门对数据管理进行监督和控制的组织。企业各单位和部门关注数据的角度不一样,缺少一个组织从全局的视角对数据进行管理,导致无法建立统一的数据管理标准、流程等,相应的数据管理制度、办法等无法得到落实。同时,企业基础数据质量考核体系也尚未建立,无法保障一系列数据标准、规范、制度、流程得到长效执行。
5、数据冗余
各个信息系统针对数据的标准规范不一、编码规则不一、校验标准不一,且部分业务系统针对数据的验证标准严重缺失,造成了企业顶层视角的数据出现“一物多码”、“一码多物”等现象。
数据质量监控方法
1、设计思路
数据质量监控的设计要分为4个模块:数据,规则,告警和反馈
①数据:需要被监控的数据,可能存放在不同的存储引擎中
②规则:值如何设计发现异常的规则,一般而言主要是数值的异常和环比等异常监控方式。也会有一些通过算法来发掘异常数据的方法
③告警:告警是指发告警的动作,这里可以通过微信消息,电话或者短信,邮件
④反馈:反馈是指对告警内容的反馈,比如说收到的告警内容,要有人员回应该告警消息是否是真的异常,是否需要忽略该异常,是否已经处理了该异常。有了反馈机制,整个数据监控才能形成闭环
2、技术方案
- 最开始可以先关注核心要监控的内容,比如说准确性,那么就对核心的一些指标做监控即可
- 监控平台尽量不要做太复杂的规则逻辑,尽量只对结果数据进行监控。比如要监控日质量是否波动过大,那么把该计算流程提前,先计算好结果表,最后监控平台只监控结果表是否异常即可
- 多数据源。多数据源的监控有两种方式:针对每个数据源定制实现一部分计算逻辑,也可以通过额外的任务将多数据源中的数据结果通过任务写入一个数据源中,再对该数据源进行监控
- 实时数据监控:区别在于扫描周期的不同,因此在设计的时候可以先以离线为主,但是尽量预留好实时监控的设计
数据可视化
ADS => DataX => MySQL => 浏览器呈现.
常见方式有 ECharts、HighCharts、G2、Chart.js 等
crontab
Linux 系统则是由 cron (crond) 这个系统服务来控制的。
- 日志文件:ll /var/log/cron*
- 编辑文件:vim /etc/crontab
- 进程:ps -ef | grep crond ==> /etc/init.d/crond restart
- 作用:任务(命令)定时调度(如:定时备份,实时备份)
分钟 小时 日期 月份 星期 需要执行命令
*代表所有的取值范围内的数字。如月份字段为*,则表示1到12个月;- / 代表每一定时间间隔的意思。如分钟字段为*/10,表示每10分钟执行1次;
-代表从某个区间范围,是闭区间。如2-5表示2,3,4,5,小时字段中0-23/2表示在0~23点范围内每2个小时执行一次;- , 分散的数字(不连续)。如1,2,3,4,7,9;
注:由于各个地方每周第一天不一样,因此Sunday=0(第1天)或Sunday=7(最后1天)。
配置实例
# 每一分钟执行一次command(因cron默认每1分钟扫描一次,因此全为*即可)
* * * * * command
# 每小时的第3和第15分钟执行command
3,15 * * * * command
# 每天上午8-11点的第3和15分钟执行command
3,15 8-11 * * * command
# 每隔2天的上午8-11点的第3和15分钟执行command
3,15 8-11 */2 * * command
# 每个星期一的上午8点到11点的第3和第15分钟执行command
3,15 8-11 * * 1 command
# 每晚的21:30执行command
30 21 * * * command
# 每月1、10、22日的4:45执行command
45 4 1,10,22 * * command
# 每周六、周日的1 : 10执行command
10 1 * * 6,0 command
# 每小时执行command
0 */1 * * * command
# 晚上11点到早上7点之间,每隔一小时执行command
* 23-7/1 * * * command
项目总结与回顾
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
数据仓库分层:ODS、DWD、DWS、ADS
- 清晰的数据结构
- 将复杂的问题简单化
- 减少重复开发
- 屏蔽原始数据的异常
- 数据血缘的追踪
数据仓库建模:维度建模、ER建模
维度建模的4个步骤:
- 选择业务
- 定义粒度
- 选定维度
- 确定事实
Flume采集日志数据、DataX采集业务数据(数据的全量或增量).
会员活跃度分析、广告业务分析、核心交易分析;
Json数据的处理、动态分区、拉链表、宽表(逆规范化)、Tez引擎(缺点:对资源要求高)

附录
Canal安装
下载:https://github.com/alibaba/canal/releases
把下载的Canal.deployer-1.1.4.tar.gz拷贝到linux,解压缩(路径可自行调整)。包含bin、conf、lib和logs4个文件夹。
[root@linux123 ~]# mkdir /opt/modules/canal
[root@linux123 mysql]# tar -zxf canal.deployer-1.1.4.tar.gz -C /opt/modules/canal
修改Canal配置
修改conf/canal.properties
这个文件是canal的基本通用配置,主要关心一下端口号,不改的话默认就是11111
修改内容如下:(zk和kafka地址根据个人事迹情况调整,以下不再复述)
# 配置zookeeper地址
canal.zkServers =linux121:2181,linux123:2181
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# 配置kafka地址
canal.mq.servers =linux121:9092,linux123:9092
修改conf/example/instance.properties
这个文件是针对要追踪的MySQL的实例配置
# 配置MySQL数据库所在的主机
canal.instance.master.address = linux123:3306
# username/password,配置数据库用户和密码
canal.instance.dbUsername =canal
canal.instance.dbPassword =canal
# mq config,对应Kafka主题:
canal.mq.topic=test
启停:sh bin/startup.sh;sh bin/stop.sh
如果要搭建集群模式,可将Canal目录分发给其他虚拟机,然后在各节点中分别启动Canal。
这种Zookeeper为观察者监控的模式,只能实现高可用,而不是负载均衡,即同一时间点只有一个canal-server节点能够监控某个数据源,只要这个节点能够正常工作,那么其他监控这个数据源的canalserver只能做stand-by,直到工作节点停掉,其他canal-server节点才能抢占
canal.properties完整配置文件:
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
# canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.zkServers =linux121:2181,linux123:2181
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ #############
##################################################
canal.mq.servers =linux121:9092,linux123:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace #canal.mq.namespace =
##################################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"
instance.properties完整配置文件:
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=linux123:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address = #canal.instance.standby.journal.name =
#canal.instance.standby.position = #canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXp VEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company :id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t _company:id/name/contact/ch
# mq config
canal.mq.topic=test
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
DAG(Directed Acyclic Graph)有向无环图