创建线程,Thread类常用方法,线程状态,线程安全问题
目录
1.认识线程
1.1 什么是线程??
1.2 创建线程的五种方式
1.3 对比单线程和多线程的执行效率
1.4 多线程的意义
2.Thread类及常见方法
2.1 Thread的常见构造方法
2.2 Thread的几个常见属性
2.3 启动一个线程-start()
2.4 中断一个线程
2.5 线程等待-join()
2.6 获取当前线程引用
3. 线程的状态
3.1 线程的状态和转移
4.线程安全问题
4.1 操作系统的随机调度/抢占式执行【万恶之源】
4.2 多个线程修改同一变量
4.3 有些修改操作,不是原子性的
4.4 内存可见性,引起的线程安全问题
4.5 指令重排序
1.认识线程
1.1 什么是线程??
public class ThreadDemo {
public static void main(String[] args) {
System.out.println("hello");
}
}
/*虽然上述代码中,我们并没有手动的创建其他线程,
但是 Java 进程在运行的时候,内部也会创建出多个线程*/
即使是一个最简单的 hello world ,其实在运行的时候也涉及到了"线程"。运行这个程序,操作系统就会创建一个 Java 进程,在这个 Java 进程里就会有一个线程调用 main 方法,也叫主线程!!
1.2 创建线程的五种方式
方法1:继承Thread类
1)继承 Thread 来创建一个线程类
class MyThread extends Thread {
@Override
public void run() {
System.out.println("hello thread");
}
}2)创建 MyThread 类的实例
Thread t = new MyThread();3)调用 start 方法启动线程
t.start();以上三个步骤,第一步只是明确了线程要做啥任务,第二步只是把任务交到他手上了,第三步才是真正的开始执行任务!!第三步才是真正的开始创建(在操作系统内核中,创建出对应线程的PCB,然后让这个PCB加入到系统链表中,参与调度) !!
分析这段代码,为啥会出现先打印 hello main,后打印 hello thread??
class MyThread extends Thread {
@Override
public void run() {
System.out.println("hello thread");
}
}
public class ThreadDemo1 {
public static void main(String[] args) {
Thread t = new MyThread();
t.start();
System.out.println("hello main");
}
}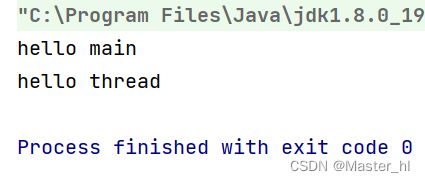
在这段代码中,虽然先启动的线程,后打印的 hello main,但是实际执行的时候,看到的却是先打印 hello mian,后打印 hello thread。原因如下:
1.每个线程是独立的执行流!main对应的线程是一个执行流,MyThread 是另一个执行流,这两个执行流之间是并发 (并发+并行) 的执行关系。
2.这里两线程执行的先后顺序,取决于操作系统调度器的具体实现,我们可以把这里的调度规则视为是"随即调度",因此执行的时候,看到先打印 hello main,还是先打印 hello thread 顺序是不确定的!!
3.此处的先打印 hello main,大概率是受到创建线程自身的开销影响的。
所以编写多线程代码的时候,一定要注意到,默认情况下,多个线程的执行顺序,是"无序"的,是"随机调度"的!!
Process finished with exit code 0另外,此处的 Process 代表的就是进程,exit code 0 就是进程的退出码。操作系统中,用进程的退出码来表示进程的运行结果:
1.使用 0 表示进程执行完毕,结果正确;
2.使用非 0 表示进程执行完毕,结果不正确;
3.还有个情况,main 函数还没返回,进程就崩溃了此时返回的值很可能是一个随机值!!
如何查看程序运行起来我们当前进程里面的线程??
第一步:让我们的线程无限循环起来。
class MyThread extends Thread {
@Override
public void run() {
while(true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("hello thread");
}
}
}
public class ThreadDemo1 {
public static void main(String[] args) throws InterruptedException {
Thread t = new MyThread();
t.start();
while(true) {
Thread.sleep(1000);
System.out.println("hello main");
}
}
}第二步:找到我们的 JDK 下面的 bin 目录,然后找到 jconsole.exe,双击运行(或者右键,以管理员身份运行),然后出现以下界面:

选择我们当前的类,然后连接:
只要我们的电脑上没有什么值钱的东西,就没有关系,直接选择不安全连接:
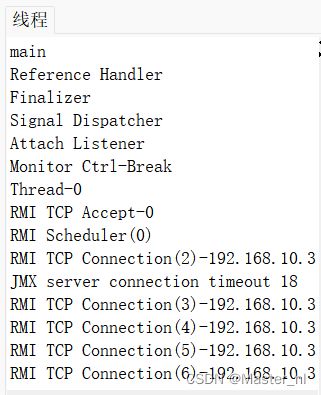
点击线程,就可以看到当前进程里的线程详情:


【面试问题】
谈谈 Thread 的 run() 和 start() 的区别!
对于刚刚的代码,使用 start() ,两个线程并发的执行,两组打印交替出现。直接调用 run() ,只打印 thread,不打印 main 。(可以下来测试一下)
1.直接调用 run(),并没有创建新的线程,而只是在之前的线程中,执行了 run() 里的内容。
2.使用 start() ,则是创建新的线程,新的线程里面会调用 run() ,新线程和旧线程之间是并发执行的关系!!
方法2:实现 Runnable 接口
class MyRunnable implements Runnable {
@Override
public void run() {
while(true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//我们使用的 Runnable,Thread,InterruptedException这些都处在java.lang包下,被默认导入了
public class ThreadDemo2 {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start();
}
}这种写法,线程和任务是分离开来的,更好的解耦合!!
方法3:继承 Thread, 重写 run, 使用匿名内部类
public class ThreadDemo3 {
public static void main(String[] args) {
Thread t = new Thread() {
@Override
public void run() {
while(true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t.start();
}
}匿名内部类的写法,直接代替了(继承,方法重写,实例化)这一套操作,但是调用 start() 才是真正在操作系统中创建了线程!!(操作系统:1.创建PCB;2.把PCB加入到链表)
方法4:实现 Runnable, 重写 run, 使用匿名内部类
public class ThreadDemo4 {
public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while(true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t.start();
}
}
方法5:使用 lambda 表达式(推荐做法)
public class ThreadDemo5 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while(true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}java中创建线程的方式不止这五种,这里只介绍这五种。
1.3 对比单线程和多线程的执行效率
使用多线程能够充分的利用 CPU 多核资源!!
【举例】
观察下述两个例子的执行时间
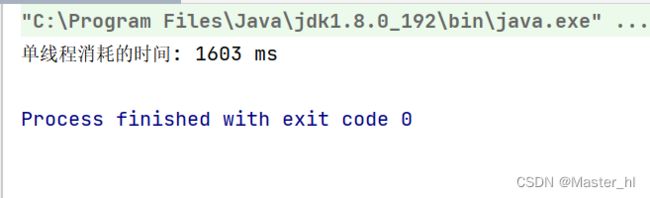
1.单个线程,串行执行,完成 20 亿次自增。
private static final long COUNT = 20_0000_0000;
private static void serial() {
long begin = System.currentTimeMillis();
int a = 0;
for(long i = 0; i < COUNT; i++) {
a++;
}
a = 0;
for(long i = 0; i < COUNT; i++) {
a++;
}
long end = System.currentTimeMillis();
System.out.println("单线程消耗的时间: " + (end - begin) + " ms");
}
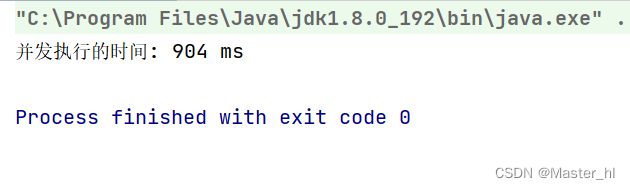
2.两个线程,并发的,完成 20 亿次自增
private static void concurrency() {
long begin = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
int a = 0;
for(long i = 0; i < COUNT; i++) {
a++;
}
});
Thread t2 = new Thread(() -> {
int a = 0;
for(long i = 0; i < COUNT; i++) {
a++;
}
});
t1.start();
t2.start();
try {
//等待 t1,t2执行完,才能结束计时
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("并发执行的时间: " + (end - begin) + " ms");
} 
【思考与问题】
这两个代码的执行效率,相比之下,效率确实提升了不少!!为啥串行执行的执行时间不是并发执行的执行时间的两倍呢??
1.创建线程自身,也是有开销的;
2.两个线程在 CPU 上不一定纯并行,也可能是并发,一部分时间里并行了,一部分时间里并发了;
3.线程的调用,也是有开销的(当前场景中开销还是非常小的)。
1.4 多线程的意义
1.在 CPU 密集型场景。
代码大部分工作,都是在使用 CPU 进行运算,使用多线程,就可以更好的利用 CPU 多核计算资源,从而提高效率!!
2.在 IO 密集型场景。
读写硬盘,读写网卡...等等 IO 操作,都是几乎不消耗 CPU 就能完成快速读写数据的操作,既然 CPU 在摸鱼,就可以给他找点活干,避免 CPU 过于闲置!!
2.Thread类及常见方法
2.1 Thread的常见构造方法
|
方法
|
说明 |
| Thread() | 创建线程对象 |
| Thread(Runnable target) | 使用 Runnable 对象创建线程对象 |
| Thread(String name) | 创建线程对象,并命名 |
| Thread(Runnable target, String name) | 使用 Runnable 对象创建线程对象,并命名 |
|
【了解】 Thread(ThreadGroup group, Runnable target)
|
线程可以被用来分组管理,分好的组即为线程组,这
个目前我们了解即可
|
前两个前面演示过,接下来看一下 Thread(Runnable target , String name) 方法:
public class ThreadDemo5 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while(true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"我的线程");
//去jconsole里可以找到这个名字的线程
t.start();
while(true) {
System.out.println("hello main");
Thread.sleep(1000);
}
}
}线程在操作系统内核里,是没有名字的,只有一个身份标识 pid,但是在 Java 中,为了让程序猿调试的时候方便理解,这个是线程是谁,就在 JVM 里给对应的 Thread 对象加了个名字。
2.2 Thread的几个常见属性
|
属性
|
获取方法 |
|
ID
|
getId() |
|
名称
|
getName() |
|
状态
|
getState() |
|
优先级
|
getPriority() |
|
是否后台线程
|
isDaemon() |
|
是否存活
|
isAlive() |
|
是否被中断
|
isInterrupted() |
- ID 是线程的唯一标识,线程的身份标识是有好几个的(内核的 PCB 上有标识,用户态线程库里,也有标识,JVM 里又有一个标识),三个标识各不相同,但目的都是一样的,都是作为身份的区分!!
- getName,获取线程名字,在构造方法里传入线程名字,方便调试!
- getState,获取状态,此处的状态,是 JVM 里面设立的状态体系!
- getPriority(),获取线程的优先级,优先级高的线程理论上来说更容易被调度到!
- isDaemon(),daemon称为"守护线程",也就是后台线程。一个线程创建出来默认是前台线程,前台线程会阻止程序结束,进程会保证所有的前台线程都执行完了,才会退出;后台线程不会阻止进程结束,进程退出的时候,不管后台线程时候执行完!!main这个线程就是一个前台线程!!(设在 thread.start() 之前)
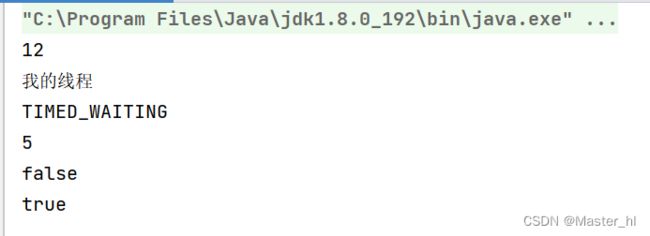
public class ThreadDemo8 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while(true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"我的线程");
t.start();
System.out.println(t.getId());
System.out.println(t.getName());
System.out.println(t.getState());
System.out.println(t.getPriority());
System.out.println(t.isDaemon());
System.out.println(t.isAlive());
}
}
2.3 启动一个线程-start()
- 1.覆写 run 方法,是提供给线程要做的事情的指令清单;
- 2.创建线程的实例化,已经分配好任务了,但还没执行;
- 3.调用 start() 方法,才是真正的在操作系统的底层创建出一个线程。
2.4 中断一个线程
在了解中断一个线程之前,我们先要知道线程什么时候执行结束:只要让线程的入口方法(main方法)执行完了,线程就随之结束了。对应的,所谓的"中断线程"就是让线程尽快把入口方法执行结束!!
第一种方式:直接使用自己手动创建的标志位来区分线程是否要结束:
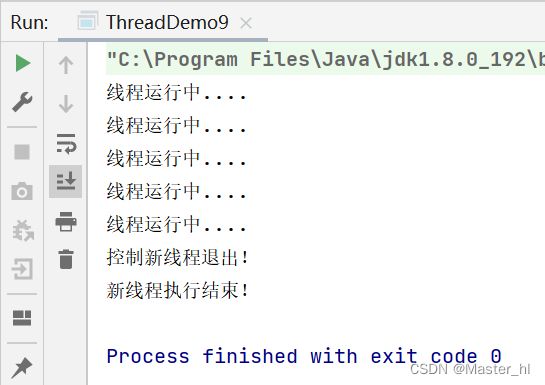
public class ThreadDemo9 {
private static boolean isQuit = false;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while (!isQuit) {
System.out.println("线程运行中....");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("新线程执行结束!");
});
t.start();
Thread.sleep(5000);
System.out.println("控制新线程退出!");
isQuit = true;
}
}
第二种方式:使用 Thread 自带的标志位
public class ThreadDemo10 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while(!Thread.currentThread().isInterrupted()) {
System.out.println("线程运行中....");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
Thread.sleep(1000);
System.out.println("控制新线程退出!");
t.interrupt();
}
}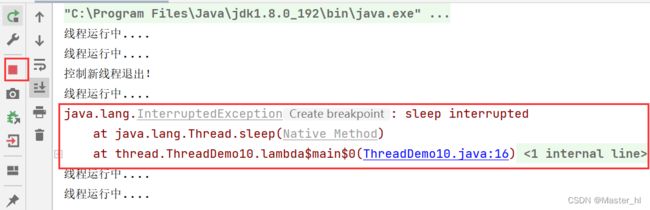
从运行结果来看,调用 interrupt 方法,控制 sleep() 产生了一个异常 (此处异常被捕获到了之后,啥也没干,就只是打印个调用堆栈),并且线程还在继续运行!!
注意理解 interrupt() 的行为:
.如果 t 线程没有处在阻塞状态,此时 interrupt() 就会修改内置的标志位
2.如果 t 线程正在处于阻塞状态,此时 interrupt() 就会中断阻塞,并抛出异常,并且改变中断标志位,当下次遇到阻塞就不会被中断,就不会抛出异常。
解释行为1:
如果线程 t 没有处于阻塞状态(例如没有 sleep),我们的进程可能一次都没有执行(概率较小,受操作系统的随机调度的影响),就退出了,也可能执行了一部分。
public class ThreadDemo10 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while(!Thread.currentThread().isInterrupted()) {
System.out.println("线程运行中....");
}
});
t.start();
Thread.sleep(1000);
System.out.println("控制新线程退出!");
t.interrupt();
}
}
上图对应这样的例子,如果一个医生正在对一个病人做手术,手术做到一半,突然接到一个紧急电话,他并会立马放下手头的手术,他会做些简单的处理,至少缝好伤口,然后再出去。那么前面打印的线程运行中,就对应接到紧急电话之前做的手术,接到紧急电话对应控制新线程退出,接到电话后,打印的线程运行中对应最后的简单缝伤口处理!!当然上图运行结果只是一种情况,也可能没有做最后的简单处理,这就取决于操作系统的随机调度了!
解释行为2:
public class ThreadDemo10 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while(!Thread.currentThread().isInterrupted()) {
System.out.println("线程运行中....");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
//e.printStackTrace();
//break;[1]立即退出
//[2]稍后退出
System.out.println("新线程即将退出!");
try {
Thread.sleep(2000);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
break;
}
}
System.out.println("新线程已退出!")
});
t.start();
Thread.sleep(1000);
System.out.println("控制新线程退出!");
t.interrupt();
}
}此处正因为这样的异常捕获操作,我们就可以自行控制线程的退出行为了:
1.可以立即退出:捕获异常后,直接 break;
2.也可以等一会退出:捕获到异常后,提示稍后退出,用 sleep() 控制退出时间,到时间后break;
3.还可以不退出:啥也不做就是不退出,程序继续执行。
这就相当于主线程向新线程发出"退出"的命令,新线程自己来决定,如何处理这个退出的行为!!
2.5 线程等待-join()
有时,我们需要等待一个线程完成它的工作后,才能进行自己的下一步工作。例如,公司下班之前,,还有两个员工在加班,老板就要等到这两个员工走了之后,才能走,这时候就需要用到 join() 了。join() 虽然不能控制两个线程的开始执行顺序,但是可以控制两个线程的结束顺序!
还是之前那个"两个线程,,完成20亿次自增"的代码:
public class ThreadDemo1 {
private static final long COUNT = 20_0000_0000;
private static void concurrency() {
long begin = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
int a = 0;
for(long i = 0; i < COUNT; i++) {
a++;
}
});
Thread t2 = new Thread(() -> {
int a = 0;
for(long i = 0; i < COUNT; i++) {
a++;
}
});
t1.start();
t2.start();
try {
//等待 t1,t2执行完,才能结束计时
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("并发执行的时间: " + (end - begin) + " ms");
}
public static void main(String[] args) {
concurrency();
}
}这里把 t1,t2 线程比作公司的两个员工,那么 main 线程就比作老板,两个员工下班了,老板才能下班,所以要 在主线程中 join() t1,t2。而 main 线程此时的等待时间就是 t1,t2中的执行时间的最大值。我们也可以控制,t1 先结束,然后 t2 结束,最后 main 结束,只要在 main 线程里调用 t2,t2 线程里调用 t1 就可以做到了。
join() 还有带参数的版本:
|
方法
|
说明 |
|
public void join()
|
等待线程结束(死等) |
|
public void join(long millis)
|
等待线程结束,最多等 millis 毫秒 |
|
public void join(long millis, int nanos)
|
同理,但可以更高精度 |
2.6 获取当前线程引用(获取线程实例)
为了对线程进行上面说的线程等待,线程中断,获取各种线程的属性,就需要获取到线程的引用。
1.如果是继承 Thread ,然后重写 run 方法,可以直接在 run 中使用 this 关键字即可获取到线程的实例。
2.如果是 Runnable 或者 lambda,this 就行不通了,更通用的办法是 Thread.currentThread()。
3. 线程的状态
- NEW :创建了 Thread 对象,但是还没调用 start() 方法,系统内核里还没有线程。
- RUNNABLE:就绪状态(1.正在 CPU 上运行;2.还没在 CPU 运行,但是已经准备好了)
- BLOCKED:阻塞状态(等待锁,后面讲)
- WAITING:阻塞状态(线程中调用了 wait() ,后面讲)
- TIMED_WAITING:阻塞状态(线程中通过 sleep 进入的阻塞状态)
- TERMINATED:系统里面的线程已经执行完毕,销毁了,但是 Thread 对象还在。
public class ThreadDemo2 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
//在 start 之前获取,获取到的是线程还未创建的状态 -- NEW
System.out.println(t.getState());
t.start();
Thread.sleep(500);
//start 之后 ,join 之前, sleep 一下,获取到的是 TIMED_WAITING
System.out.println(t.getState());
// start 之后,join 之前,没有 sleep ,获取到的则是就绪状态 -- RUNNABLE
t.join();
//join之后,线程结束 -- TERMINATED
System.out.println(t.getState());
}
}3.1 线程的状态和转移

4.线程安全问题
线程安全问题的万恶之源,罪魁祸首,正是调度器随即调度/抢占式执行这个过程
线程安全:在随即调度之下,程序执行有多种可能,其中的某种可能导致代码出现了 bug!!
4.1 线程不安全的典型例子
创建两个线程,让这俩线程同时并发对一个变量自增 5w 次,最终预期能够一共自增 10w 次。
class Counter {
//用来保存计数的变量
public int count;
public void increase() {
count++;
}
}
public class ThreadDemo3 {
public static Counter counter = new Counter();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
for(int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for(int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("count: " + counter.count);
}
}
经过多次运行,每次的运行的结果都不太意一样,就像是一个 随机数 ,处在 5w 至 10w 之间!
出现这种问题的原因是什么??
站在硬件的角度来理解,执行一段代码,就是需要让 CPU 把对应的指令从内存读取出来,然后再执行。(CPU 自身包含了一些寄存器,也能存储少量的数据)
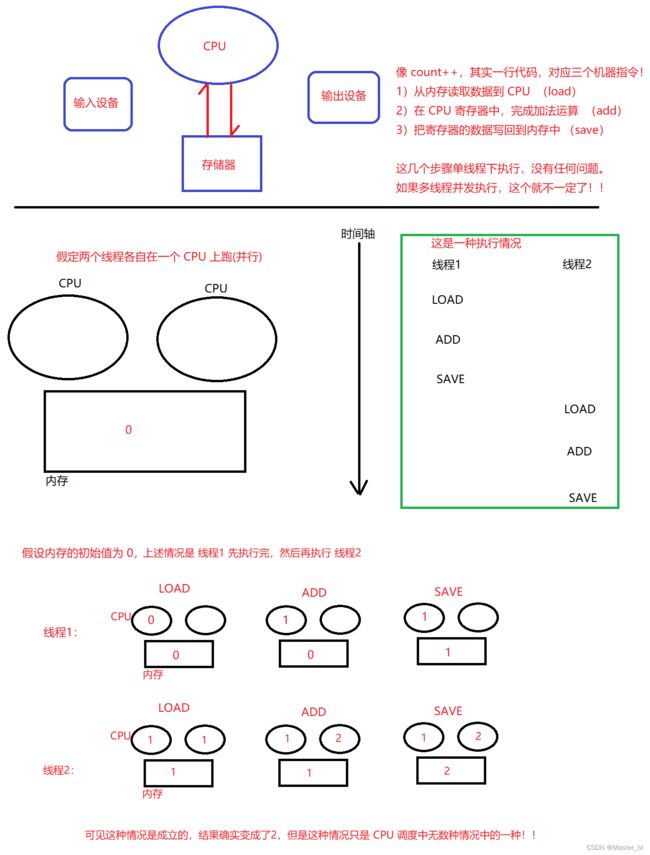
两线程执行 1+ 1 = 2 的操作,由于操作系统的随机调度,执行情况有无数种,但只有两种情况的计算结果是正确的!!
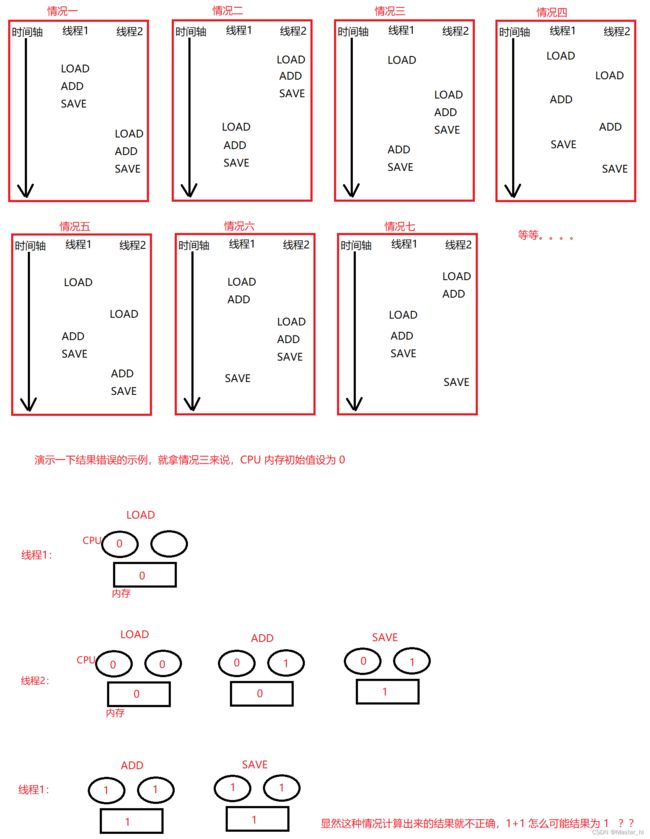
首先我们要知道操作系统随即调度让两线程的执行情况产生无数种,上图演示了一个正确结果和一个错误结果,得出结论,只有两种情况计算出来的结果是正确的(前两种),其他的情况均不正确
回到我们前面的那个两线程针对同一变量各自自增 5w 次,预期结果为 10w 次。为什么前面得出结论运行结果是处在 5w 至 10w 之间呢??经过上图一些演示,我们发现俩线程在计算 1+1 = 2 的时候,出现了两种结果,要么为 2,要么为 1,极端情况下,假如都为 1,此时总和就是 5w,如果都为 2,此时总和就是 10w,所以结果会处在 5w 至 10w 之间!!
4.2 造成线程不安全五大原因(前三个更普遍)
- 操作系统的随机调度/抢占式执行【万恶之源】
- 多个线程修改同一变量
1.如果只是一个线程修改变量,没事!
2.如果是多个线程读同一个变量,也没事!
3.如果是多个线程修改不同的变量,还没事!
所以我们在写代码的时候,就可以针对这个要点进行控制了。可以通过调整程序的设计,破坏条件来规避线程不安全!![这种方法适合范围也是有限的,不是所有的场景都能规避掉]
- 有些修改操作,不是原子性的
原子:代指不可拆分的最小单位。
通过 "="(赋值) 来修改,"=" 只对应一条指令,这就视为是原子性的操作 !!
而刚刚的通过 "++" 来修改,"++" 对应三条机器指令,则不是原子性的操作!!
不保证原子性会给多线程带来什么问题:如果一个线程正在对一个变量操作,中途其他线程插入进来了,如果这个操作被打断了,结果就可能是错误的。
- 内存可见性,引起的线程安全问题
一个线程修改,一个线程读的场景,就特别容易因为内存可见性引发问题!
例如 线程1 进行反复的 读和判断,线程2 在中途突然 写 了一下。
如果是正常情况下,线程1 在读和判断,线程 2 突然写了一下不会出现问题,在 线程2 写完之后,线程1 就能立即读到内存的变化,从而让判断出现变化!!
但是,在程序运行过程中,可能涉及到"优化",可能是编译器 (javac) 的优化,也可能是 JVM java ,还可能是操作系统的优化!!就可能导致出现问题:

但是 线程1 这样 "优化" 之后,线程2 突然写了一个数据,此时 线程2 的修改,线程1 感知不到!!就导致了 线程1 没有读取到内存最新数据,这就是内存可见性问题!!
上述场景的优化,在单线程环境下,没问题;多线程情况下就可能出问题。由于多线程环境太复杂了,编译器/JVM/操作系统进行优化的时候就可能产生误判!!
- 指令重排序
指令重排序,也是 操作系统/编译器/JVM 的一个优化操作,通过调整代码的顺序,从而达到加快速度的效果!!这种优化操作,在单线程情况下同样没有问题,而多线程就可能引发问题:

本篇博客就到这了,下次接着这里继续!!